SQUEEZE 2 Admin-Handbuch
Handbuch zur Administration von Squeeze 2
Dieses Handbuch richtet sich an Consultants, Supporter, Partner und technisch afine User, die Funktionen von Squeeze konfigurieren möchten.
- Systemvoraussetzungen
- Installation
- Update/Upgrade
- Update auf Linux
- Update auf Windows
- Datenbankmigration nach Update
- Suchindex nach Update reindizieren
- PHP Update unter Windows
- Apache Update unter Windows
- Logging & Debugging
- Stapelklassen
- Stapelklassen
- Stapelklassen anlegen
- Stapelklassen-Eigenschaften
- Stapelklasseneigenschaften OCR-Texterkennung
- Dokumentenklassen
- Dokumentenklassen
- Dokumenten- und Tabellenfelder
- Dokumentenklassen-Eigenschaften
- Dokumentenklassen - Löschgründe
- E-Mail-Import
- Allgemeine Konfiguration
- Verarbeitung von Anlagen
- Verarbeitung unter Windows konfigurieren
- Filterung mittels Black- und Whitelisting
- Leitfaden: Zugriff auf Exchange Online Postfächer einschränken
- Konfiguration Client Credentials Flow (application) MS Graph API
- Konfiguration Authentication Code Flow (delegated) MS Graph API
- Configuration Client Credentials Flow (application) MS Graph API [ENG]
- Configuration Authentication Code Flow (delegated) MS Graph API [ENG]
- Übernahme von E-Mail-Feldern in Squeeze-Felder
- Unterstützung von S/MIME
- Dokumentverarbeitung
- Lokatoren
- Lokatoren
- Testen von Lokatoren
- Lokator: Document Date
- Lokator: Invoice Amounts
- Lokator: KeyWord
- Lokator: KeyWord to Value
- Lokator: Regular Expression
- Lokator: Search for DB linked data
- Lokator: Search for line items
- Lokator: Value next to KeyWord
- Lokator: Value from Regular Expression
- Unterschiede zu Squeeze 1
- Swiss QR-Code
- Validierung
- Stammdaten
- Stammdaten
- Anlegen einer neuen Stammdatentabelle im Webclient
- Konfiguration und Initialisieren einer neuen Stammdatentabelle via CSV-Upload
- Export von Stammdaten als CSV
- Stammdaten ab Squeeze 2.5
- Jobs
- Exportschnittstellen
- Otris Documents SOAP
- SharePoint API
- Navision Soap
- Freeze EAS Export
- Pull Export
- SharePoint Export via Graph API
- Kontrolle der exportierten Dokumente
- Benutzer und Rollen
- Rollenfilter & Feldbedingungen (bis Squeeze 2.5)
- Rollenfilter & Feldbedingungen (ab & inkl. Squeeze 2.5)
- Rollen
- Benutzer anlegen
- Standard-Rollen von SQUEEZE
- SSO / OAuth / OpenID Connect
- Digitale Formate (XML, XRechnung, ZUGFeRD)
- Einführung Digitale Formate: XML, XRechnung und ZUGFeRD in der Software Squeeze
- XML-Pipeline
- XRechnung und ZUGFeRD
- Auswertungstabellen XRechnung und ZUGFeRD
- Konfiguration XML-Auswertung
- XML Formate in Squeeze
- XML-Prüfbericht KoSIT
- Mandanten- und Lieferanten- Erkennung
- Umschlüsselung von Codes eines elektronischen Beleges
- Mehrsprachigkeit
- Mandanten-Verwaltung
- Squeezer CLI
- SQUEEZE Admin FAQ
- Email-Verarbeitung (Windows)
- Datenbank Backup und Restore (Windows)
- Aufgabe: Periodischer Worker Neustart
- ElasticSearch Speicher erweitern
- KI Integration
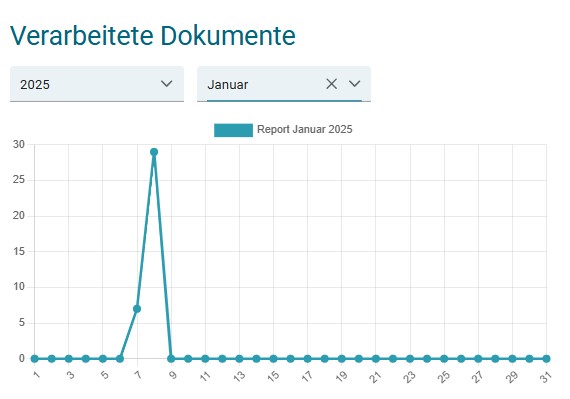
- Reporting
Systemvoraussetzungen
Systemvoraussetzungen für Server und Clients
Systemvoraussetzungen des Servers
Hardware / Virtual Maschine
Die Hardwarevoraussetzungen von Squeeze richten sich stark nach dem Verwendungszweck. Die Anzahl der täglich zu verarbeitenden Dokumente, der Menge an vorgehaltenen Daten vor endgültiger Lösung und eventuelle Kundenanpassungen haben alle Einfluss auf die Vorraussetzungen an die Hardware.
Grundsätzlich gilt:
- Die Anzahl gleichzeitig zu verarbeitender Dokumente hängt davon ab wie viele Worker eingesetzt werden.
- Für jeden Worker sollte 1 CPU Kern und 2 GB RAM reserviert werden.
Die Verwendung von Squeeze mit unausreichender Hardware (insbesondere CPU und RAM) kann zu Performance-Problemen führen.
| Minimum | Empfehlung | |
|---|---|---|
| Betriebssystem | Linux/Windows | Linux/Windows |
| CPU Takt | 2.2 GHz | 3.0 GHz |
| CPU Kerne | 6 Cores | 8 Cores |
| RAM | 8 GB | 16 GB |
| Festplatte | HDD 7200 rpm | SSD |
| Festplattenspeicher | 200 GB | 500 GB |
| Netzwerk | 100 Mbit | 1000 Mbit |
Betriebssysteme
Windows
| OS | Version | Anmerkung |
|---|---|---|
| Windows | 7 | Uneingeschränkt unterstützt |
| Windows | 10 | Uneingeschränkt unterstützt |
| Windows | 11 | Uneingeschränkt unterstützt |
| Windows | Server 2008 R2 | Uneingeschränkt unterstützt |
| Windows | Server 2012 | Uneingeschränkt unterstützt |
| Windows | Server 2012 R2 | Uneingeschränkt unterstützt |
| Windows | Server 2016 | Uneingeschränkt unterstützt |
| Windows | Server 2019 | Uneingeschränkt unterstützt |
| Windows | Server 2022 | Uneingeschränkt unterstützt |
| Windows | Server 2025 | Uneingeschränkt unterstützt |
Linux
| OS | Version | Anmerkung |
|---|---|---|
| Ubuntu | 14.04 | |
| Ubuntu | 16.04 | Uneingeschränkt unterstützt |
| Ubuntu | 18.04 | Uneingeschränkt unterstützt |
| Ubuntu | 20.04 | Uneingeschränkt unterstützt |
| Ubuntu | 22.04 | Uneingeschränkt unterstützt |
| Debian | 8 | |
| Debian | 9 | Uneingeschränkt unterstützt |
| Debian | 10 |
Uneingeschränkt unterstützt |
| Debian | 11 |
Uneingeschränkt unterstützt |
| Debian | 12 |
Uneingeschränkt unterstützt |
Wir empfehlen die Verwendung von Docker. Zu diesem Zweck können wir Images und Konfigurationen auf Anfrage bereitstellen, falls Sie diese für On-Premise Installationen einsetzen möchten.
Diese Verwenden wir bereits für eine Vielzahl an Kundensystemen.
Datenbanksysteme
Squeeze wird primär auf Basis von MariaDB eingesetzt und getestet.
Microsoft SQL Server wird ebenfalls unterstützt und durch die selben Test-Automatisierungen getestet wie MariaDB und MySQL, allerdings empfehlen wir aufgrund des höheren Betriebsaufwandes eher die Verwendung einer MariaDB.
| Hersteller | Version |
|---|---|
| Microsoft | SQL Server 2012 |
| Microsoft | SQL Server 2014 |
| Microsoft | SQL Server 2016 |
| Microsoft | SQL Server 2019 |
| Microsoft | SQL Server 2022 |
| MySQL | 5.5 - 5.7 |
| MariaDB | 5.5.7 |
| MariaDB | 10.0 - 10.11 |
Network
Eingehender Netzwerkverkehr
| Port | Beschreibung |
|---|---|
| 80 | HTML Frontend und API |
| 443 | HTML Frontend und API (mit SSL) |
Ausgehender Netzwerkverkehr
| Port | Beshreibung |
|---|---|
| 25 | SMTP für das versenden von Emails |
| 587 | SMTP für das versenden von Emails (mit Verschlüsselung) |
| 143 | IMAP um Email abzuholen |
| 993 | IMAP um Email abzuholen (mit Verschlüsselung) |
| 443 | EWS um Email abzuholen (mit Verschlüsselung) |
| 33?? | SAP RFC Verbindung (?? = SAP Instanznummer) |
Runtimes
Squeeze und dessen Komponenten benötigen einige Bibliotheken und Anwendungen die installiert sein müssen. Sollten Sie den Windows installer nutzen, so befinden sich alle erforderlichen Anwendungen und Bibliotheken bereits im Setup und werden mit installiert und grundsätzlich eingerichtet. Der Installer ist so erstellt worden, dass ein Out-of-the-Box System installiert wird, welches sofort nutzbar ist.
Die Anwendungen und Bibliotheken werden dabei unterteilt. Es gibt direkte und indirekte Abhängigkeiten Ein Beispiel ist das Message Queue System (RabbitMQ).
In Komplexeren Umgebungen kann es erforderlich sein, diese Komponenten auf verschiedene Systeme zu verteilen. In diesem Fall müssen Sie sich selber um die Bereitstellung der Anwendungen kümmern.
Direkte Abhängigkeiten
| Runtime | Version | Benötigt von |
|---|---|---|
| PHP | 7.4.x | Server, Worker |
| PHP | 8.1.x | Server, Worker |
| Java | 8 | Server, Worker |
"Server" meint den Squeeze Server.
Indirekte Abhängigkeiten
| Runtime | Version | Benötigt von |
|---|---|---|
| Erlang | 10.5 | RabbitMQ |
| Erlang | 25.3 | RabbitMQ |
| Java | In Abhängigkeit der Elasticsearch Version | Elasticsearch |
Systemvoraussetzungen des Webclients
Betriebssystem
Grundsätzlich werden alle gängigen Betriebssysteme unterstützt.
Das Betriebssystem selbst ist nicht sonderlich entscheidend, da es sich bei Squeeze um eine reine Webanwendung handelt.
Browser
Grundsätzlich werden alle gängigen Browser unterstützt, jedoch sind nicht immer alle unsererseits aktuell mit allen Funktionen getestet. Folgend eine Übersicht der aktuell getesteten Browser.
Der Webclient wird in der Entwicklung auf Microsoft, Google Chrome und Safari eingesetzt.
| Hersteller | Version | Anmerkung |
|---|---|---|
| Microsoft | Internet Explorer 11 | Uneingeschränkt unterstützt (bis Squeeze Version 1.12.9) |
| Microsoft | Edge | Uneingeschränkt unterstützt |
| Mozilla | Firefox | Uneingeschränkt unterstützt |
| Chrome | Uneingeschränkt unterstützt | |
| Apple | Safari | Uneingeschränkt unterstützt |
Installation
Installation von Squeeze auf Windows und Linux & Aufsetzen eines nutzbaren Mandanten.
Serverinstallation Linux
Wir haben die Dokumentation für die Installation unter Linux temporär entfernt, weil sie veraltet war.
Falls Sie Squeeze auf Linux installlieren möchten, was wir sehr begrüßen, dann melden Sie sich bitte bei support@squeeze.one oder im Forum, um Hilfe. Dabei möchten Wir Sie gern unterstützen.
Serverinstallation Windows
Der für die Squeeze-Server Installation notwendige Installer wird von der Firma Dexpro-Solutions GmbH auf Anfrage zur Verfügung gestellt.
In Zukunft wird es ein entsprechendes Download-Portal geben, wo sowohl der Server - Installer als auch die Dateien für das Update auf die neueste Squeeze - Version heruntergeladen werden können.
Installation Squeeze - Server
Squeeze kann auf jeder Partition eines Rechners installiert werden. Im Setup sind einige Pfade voreingestellt (D:.\Squeeze).
Für die Installations-Dokumentation wird die Server-Installation mit Version 2.0.0 auf der C:\ Partition durchgeführt.
Nachdem der Server-Installer die erforderlichen Dateien in das angegebene Verzeichnis (C:\Squeeze) entpackt hat, startet die Installation automatisch.
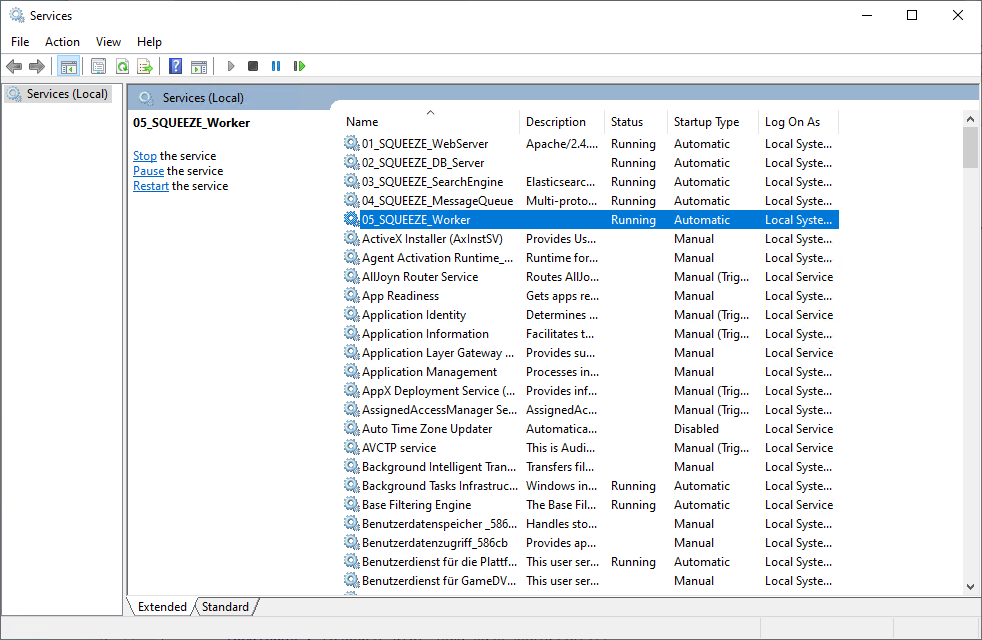
Nachdem das initiale Setup abgeschlossen ist, sollten geprüft werden ob alle Dienste installiert worden sind und diese bereits gestartet wurden.
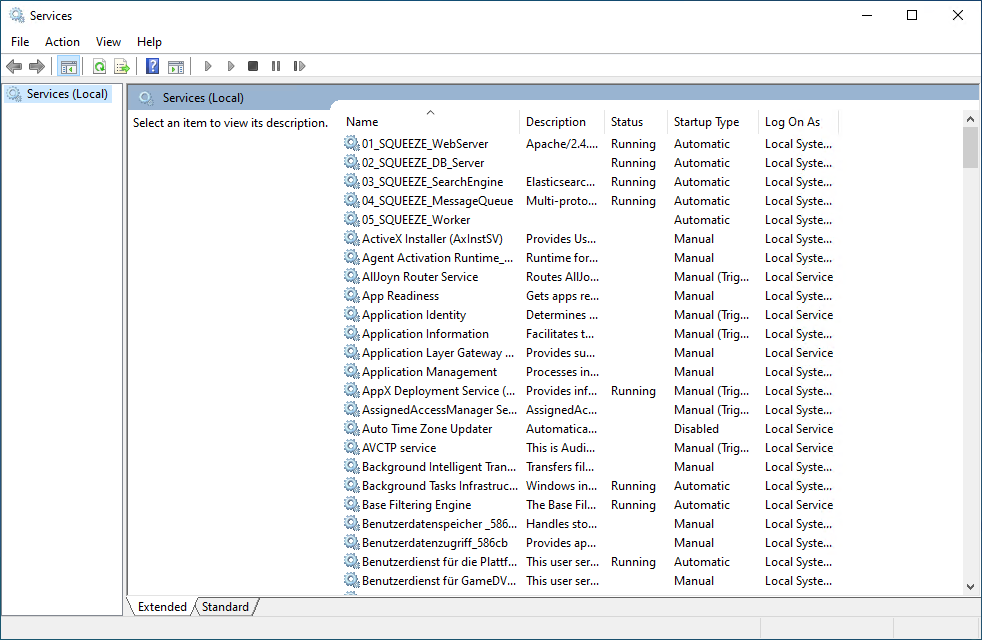
| Dienstname | Staus |
| 01_SQUEEZE_WebServer | Wird ausgeführt |
| 02_SQUEEZE_DB_Server | Wird ausgeführt |
| 03_SQUEEZE_SearchEngine | Wird ausgeführt |
| 04_SQUEEZE_MessageQueue | Wird ausgeführt |
| 05_SQUEEZE_Worker | nicht gestartet |
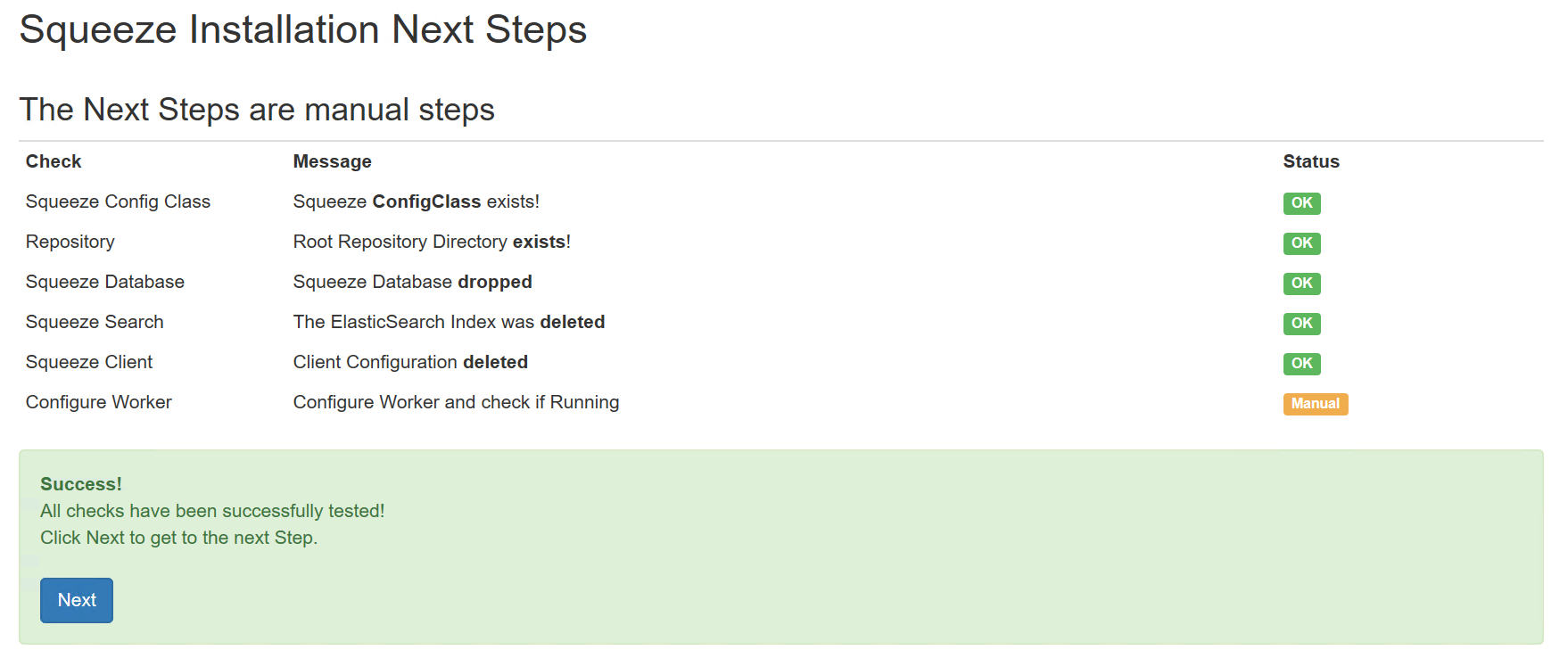
Die Dienste 01 bis 04 sollten gestartet sein. Der Dienst 05 ist zu diesem Zeitpunkt nicht gestartet, dieser Dienst muss nach Abschluss der Server und - Mandanten-Konfiguration erst konfiguriert werden bis er gestartet werden kann.
Konfiguration Squeeze - Server
Nachdem das eigentliche Server-Setup abgeschlossen ist, wird der Server konfiguriert. Dazu wird der Browser gestartet und in der Adresszeile des Browsers der gewünschte Mandanten-Name eingegeben.
Es können mehrere technische Mandanten auf einem Squeeze Server konfiguriert werden. Jeder Mandant hat sein eigenes Repository und eine eigene Datenbank.
Im ausgelieferten Server-Setup ist bereits eine Lizenz für 300 Dokumente für den Mandanten localhost enthalten.
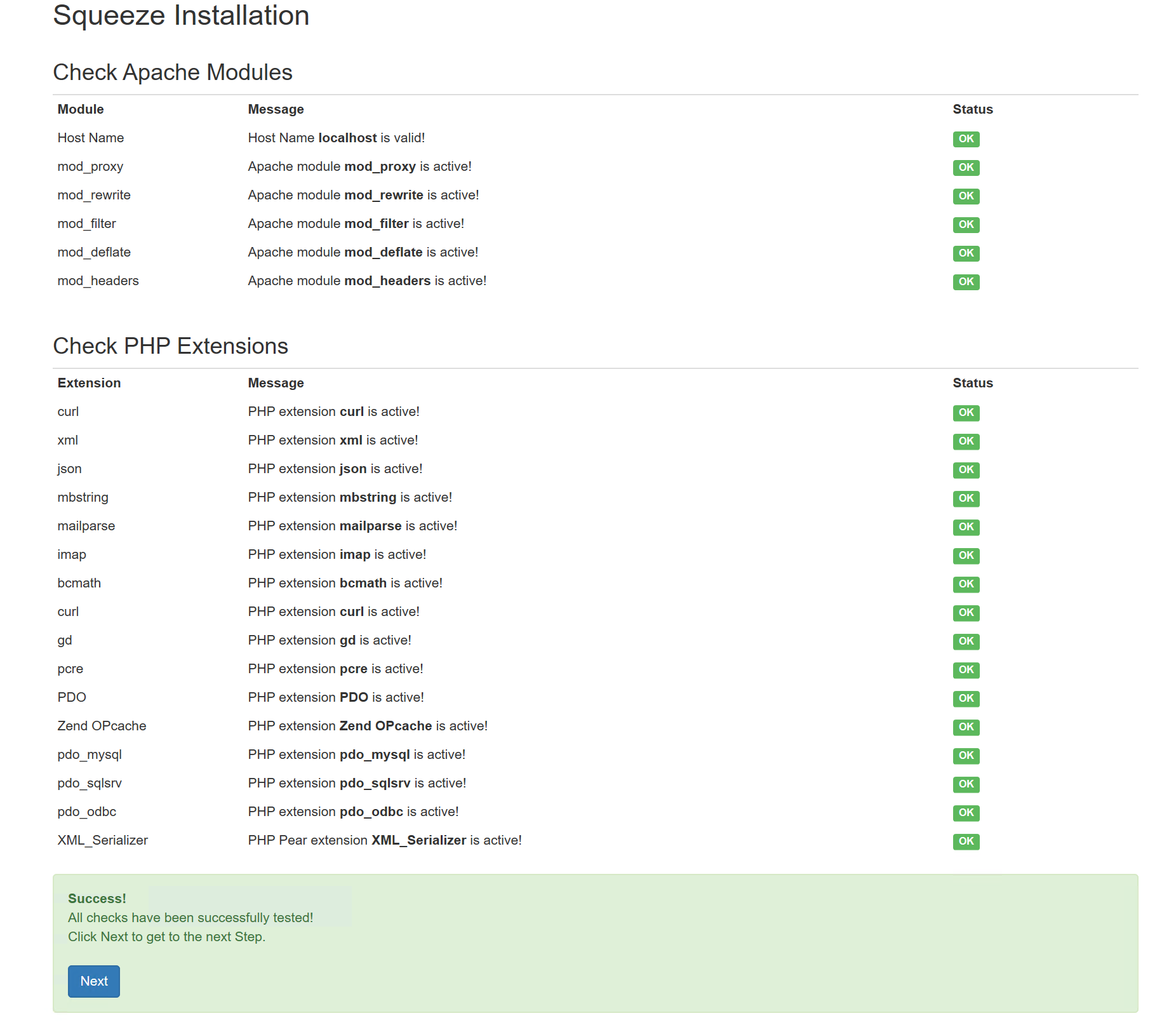
Wenn MS SQL gewählt wird dann ist der Port 1433, sollte eine Instanz von MS SQL genutzt werden, dann muss der Port leer bleiben (dynamischer Port), bei MYSQL ist der Port 3306.
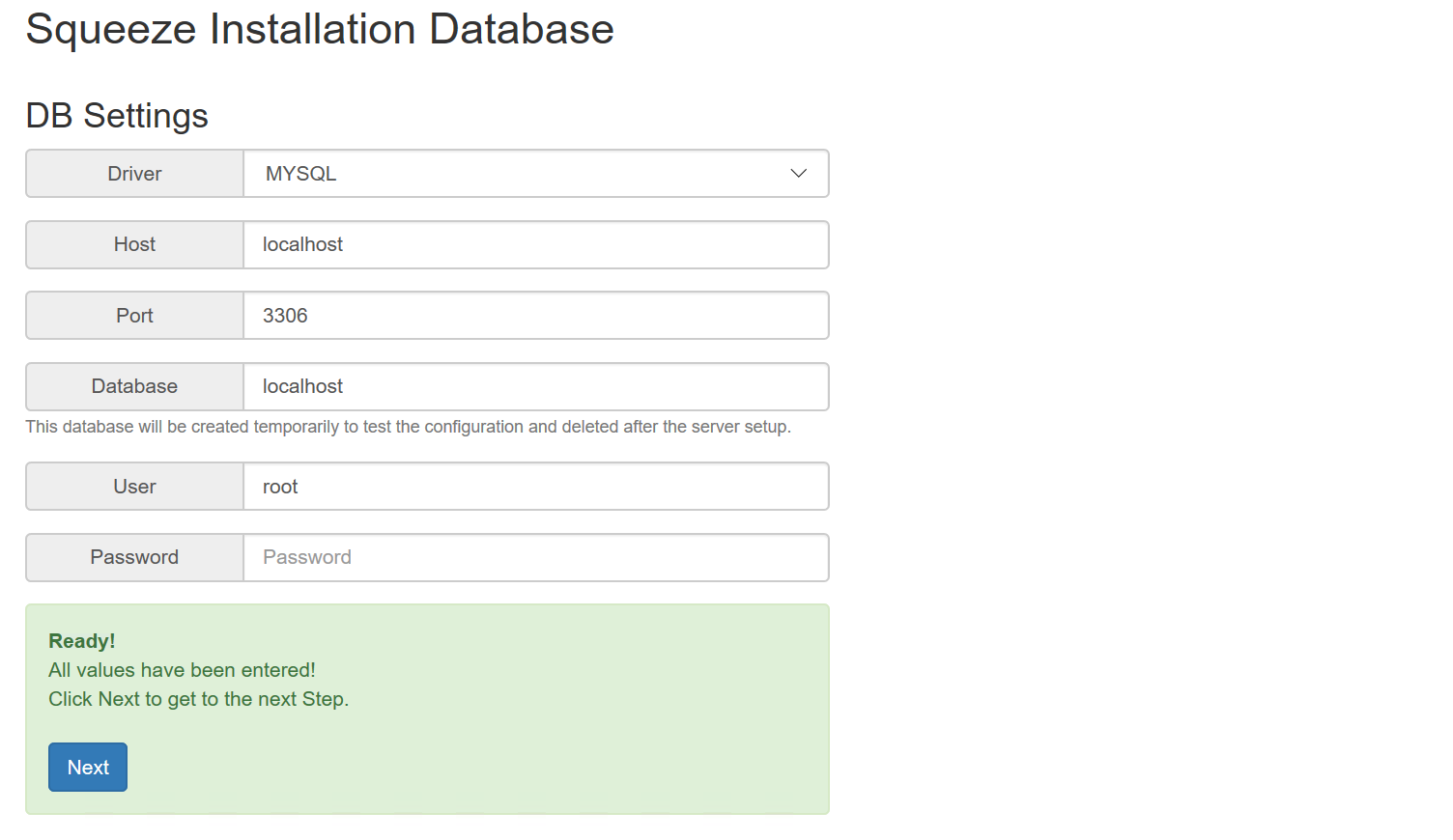
In diesem Beispiel wird die ausgelieferte MariaDB genutzt. Die Felder können entsprechend angepasst werden. Mit dem Button Next öffnet sich der nächste Dialog:
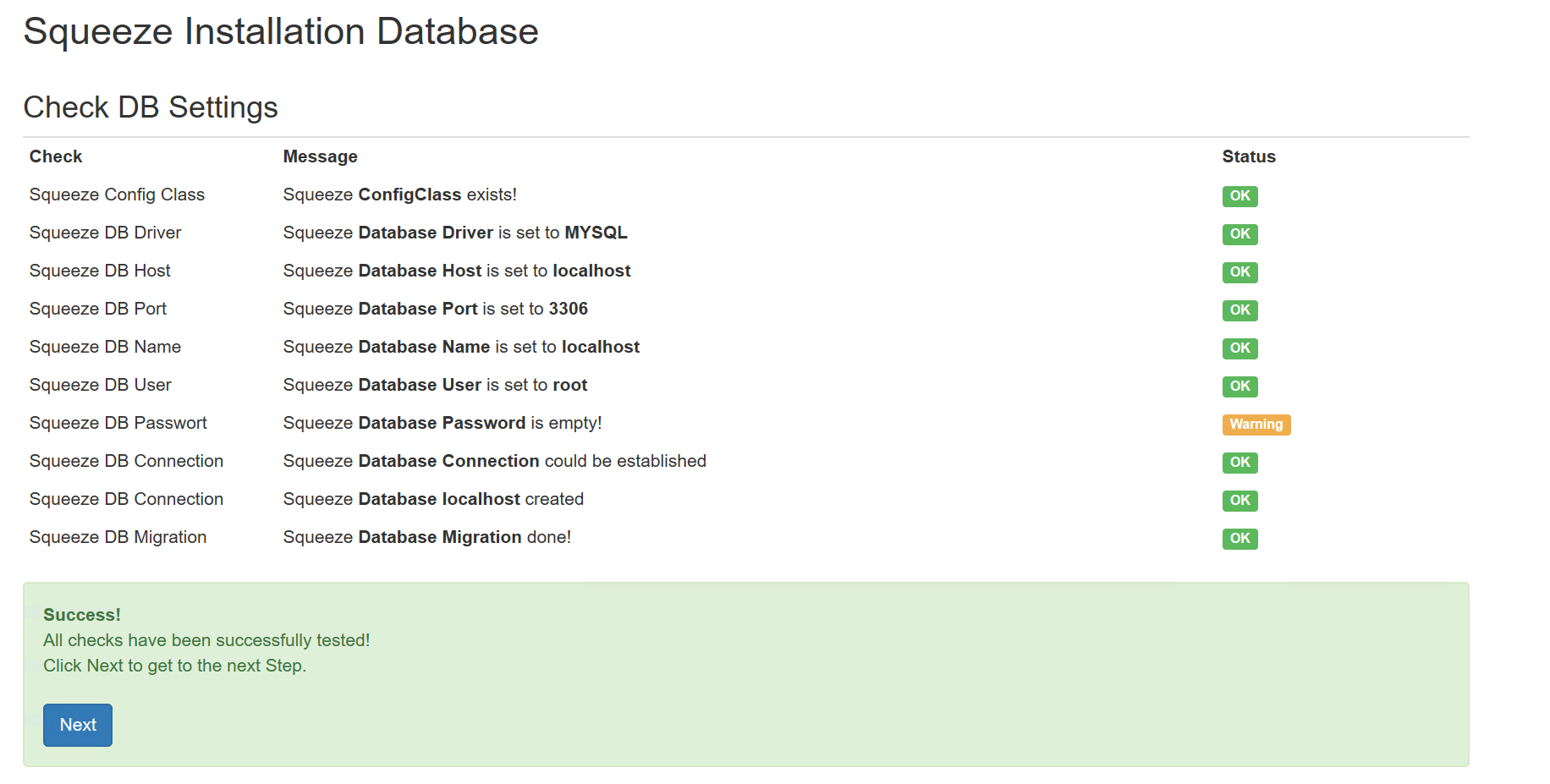
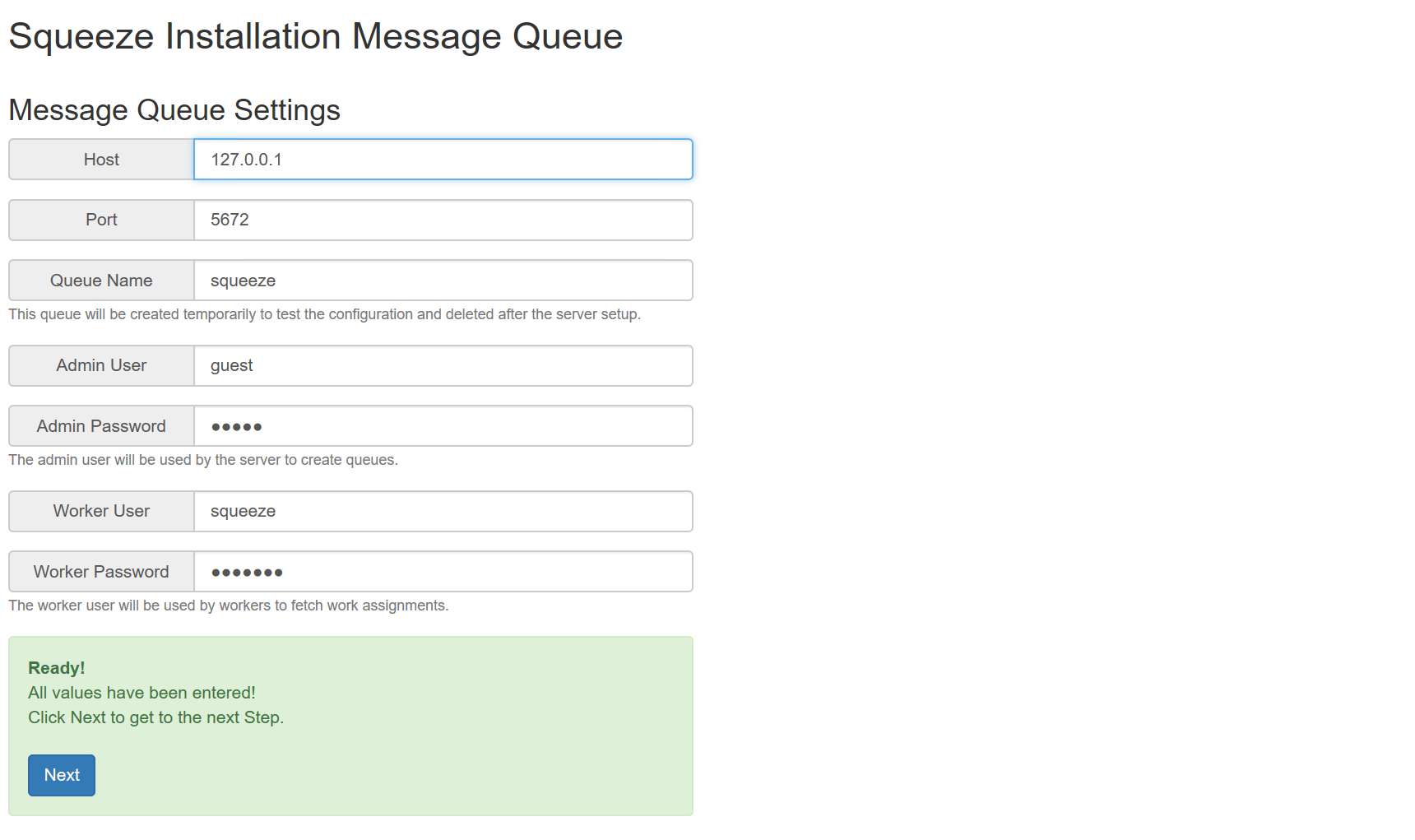
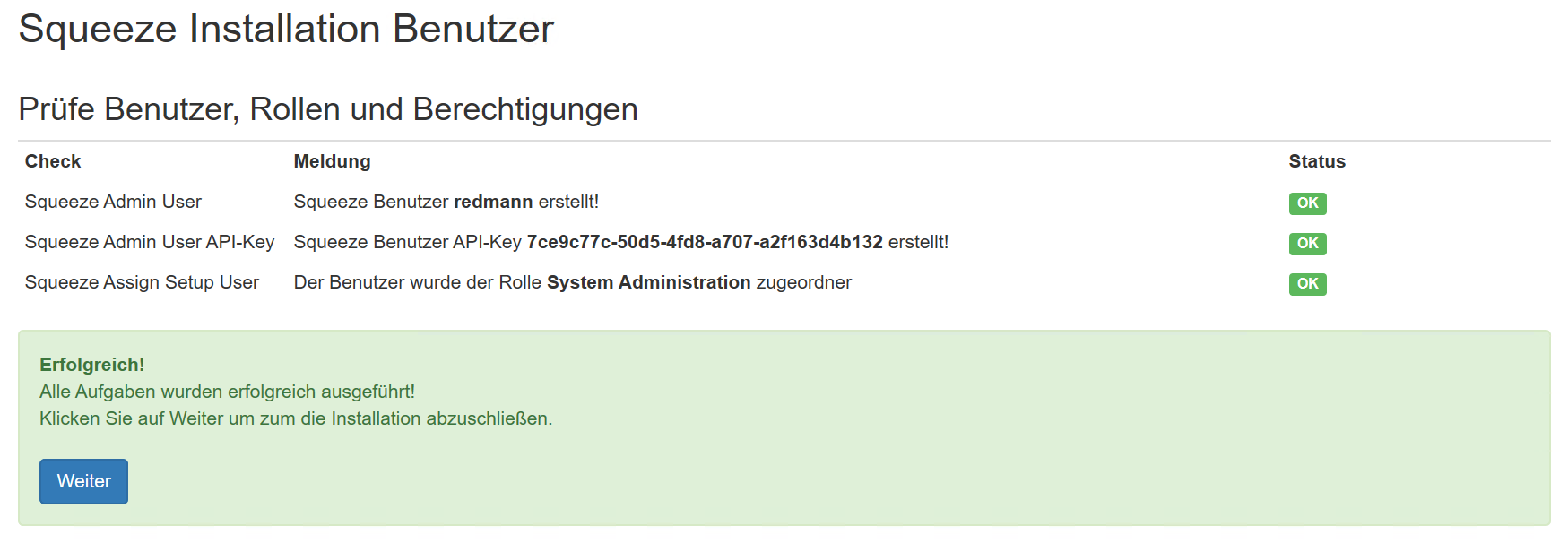
- Admin Password: guest
- Worker Password: squeeze
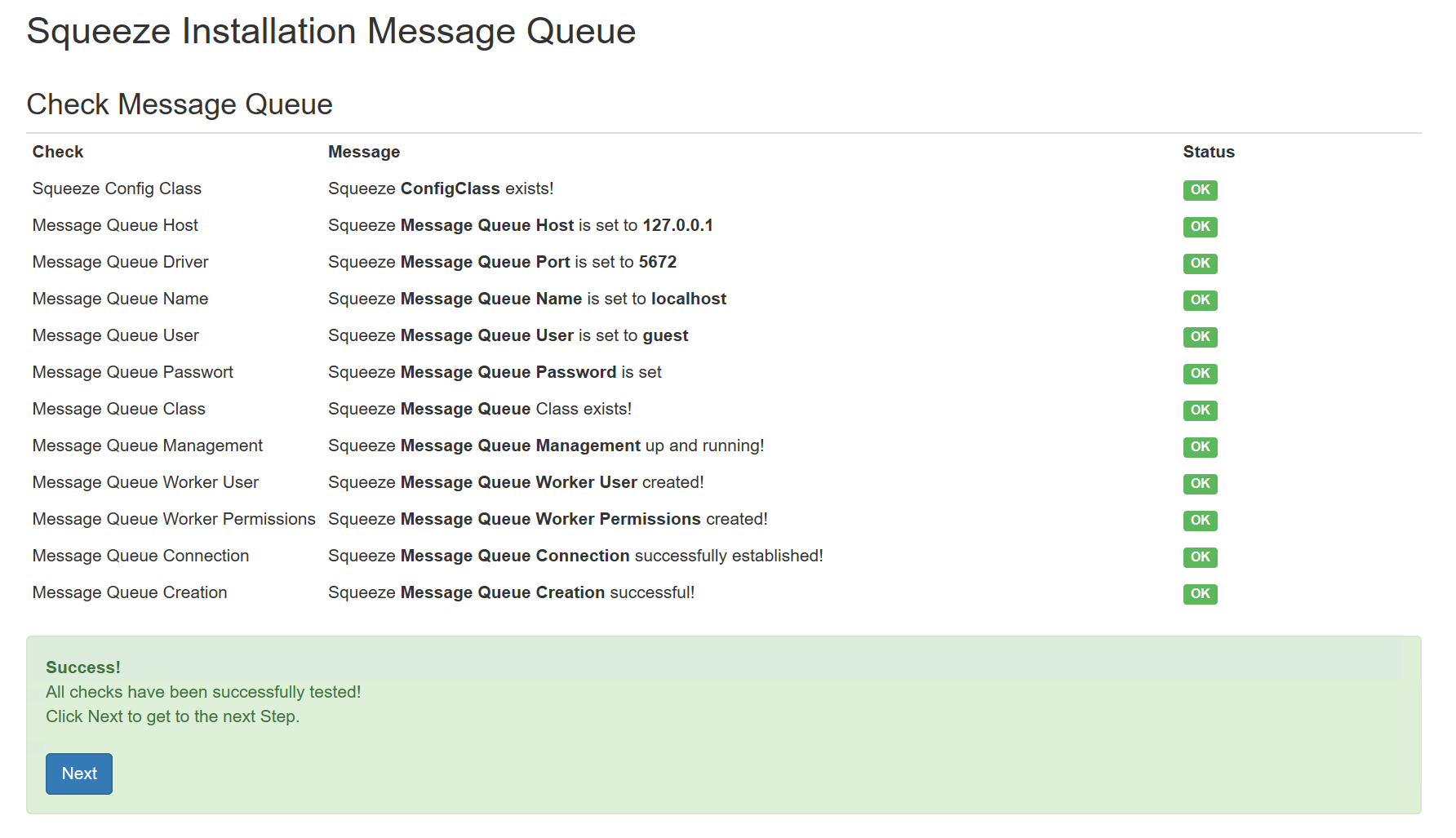
- Password: squeeze
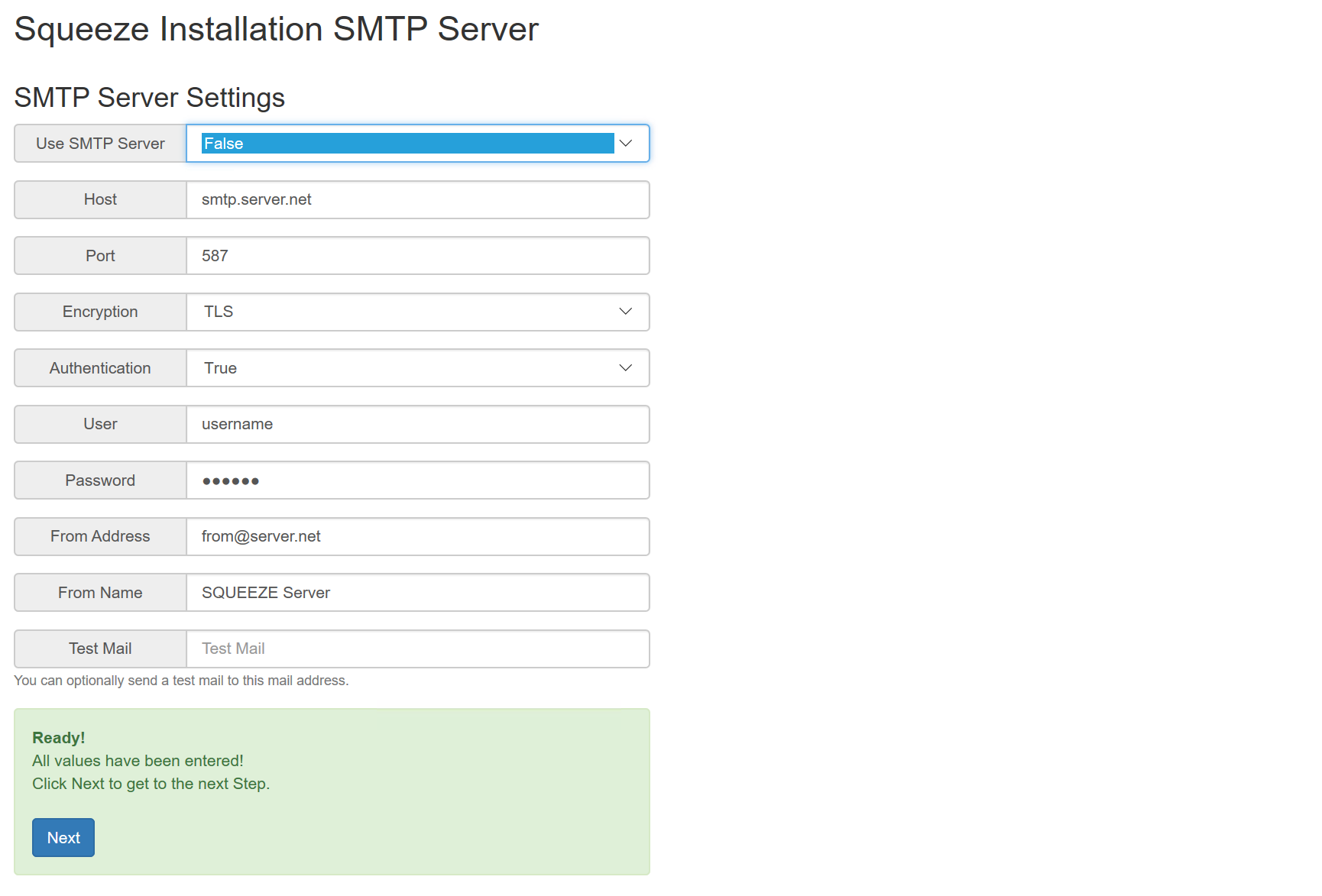
Für die Demo-Installation wird kein SMTP Versand konfiguriert, da die verwendete Sandbox für die Installation keinen Internetzugang hat. Dazu wird im Feld "Use SMTP Zugang" der Wert auf False gesetzt
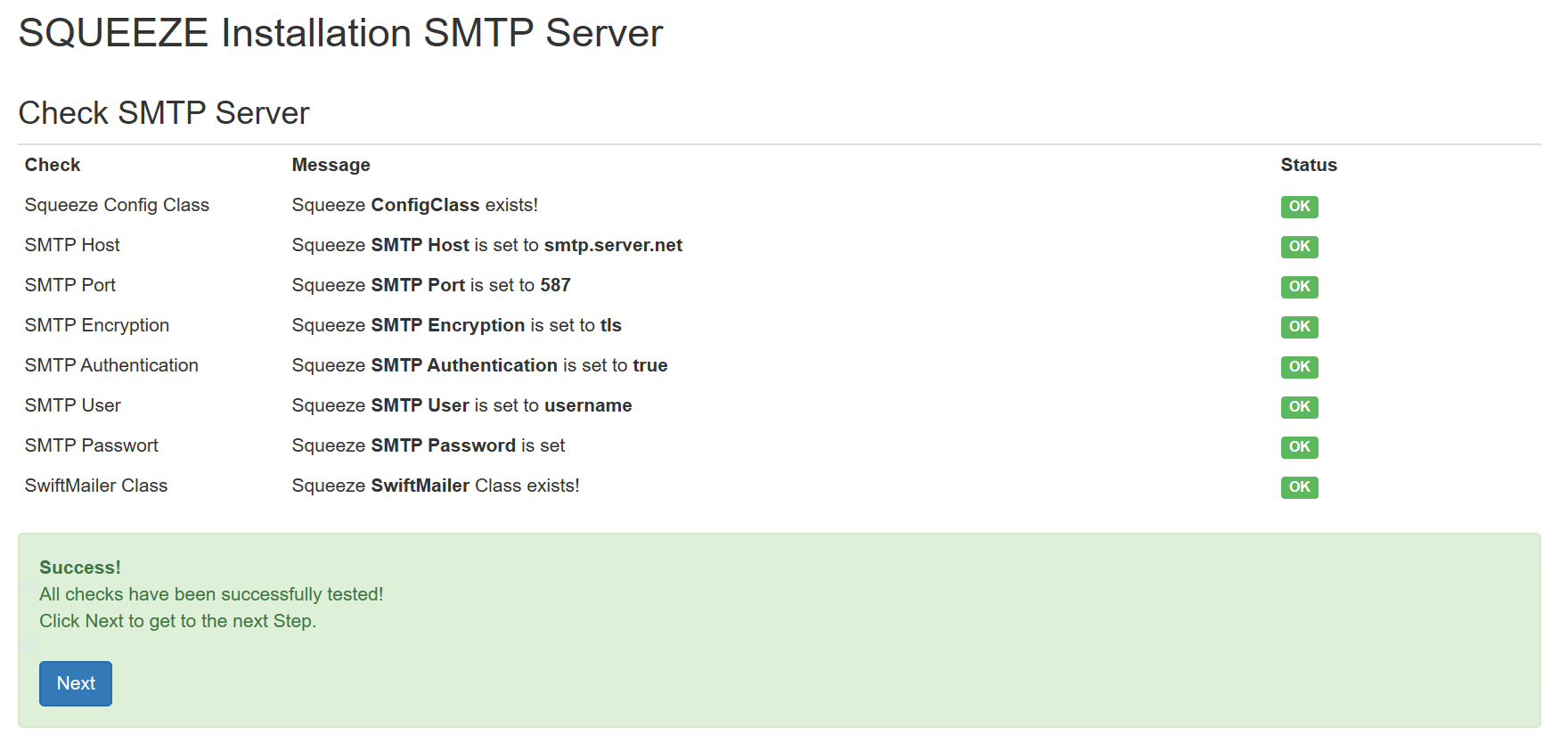

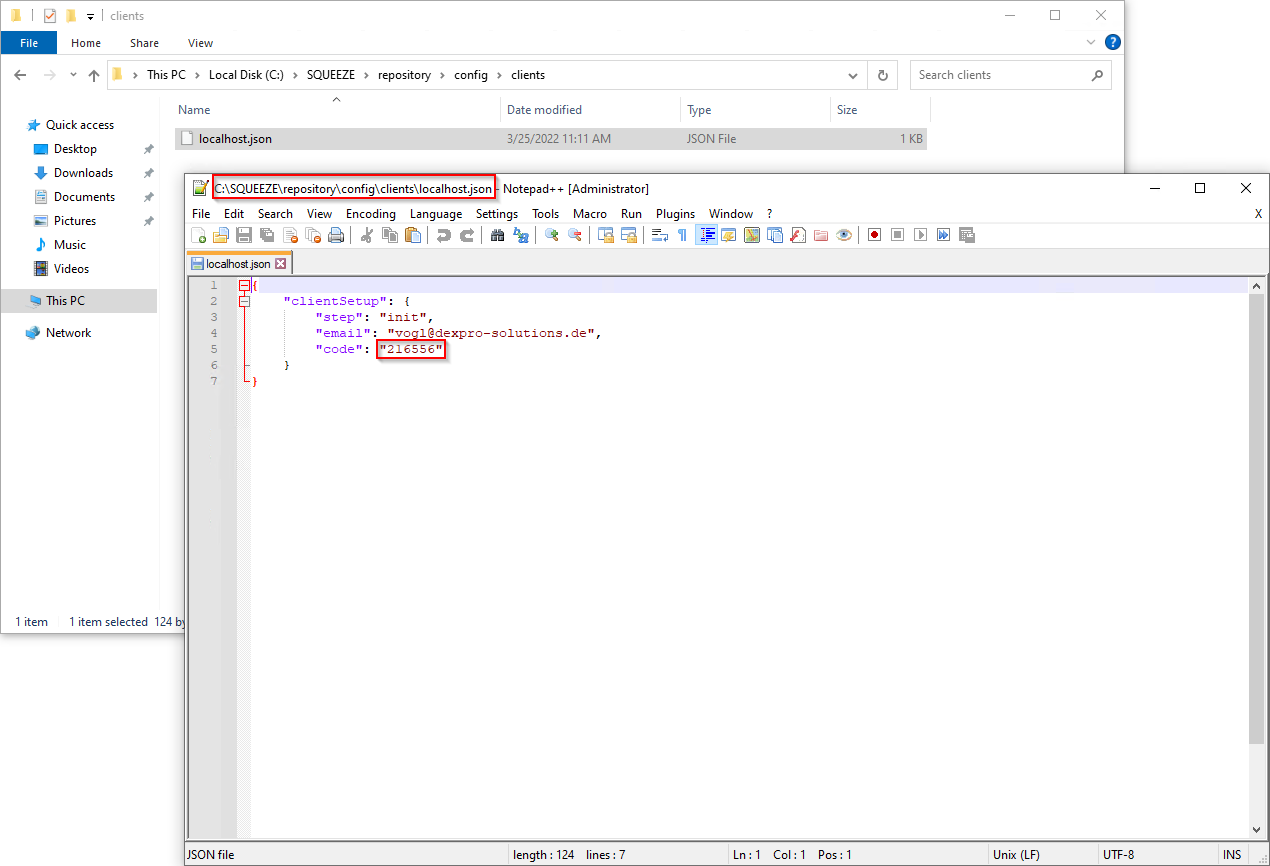
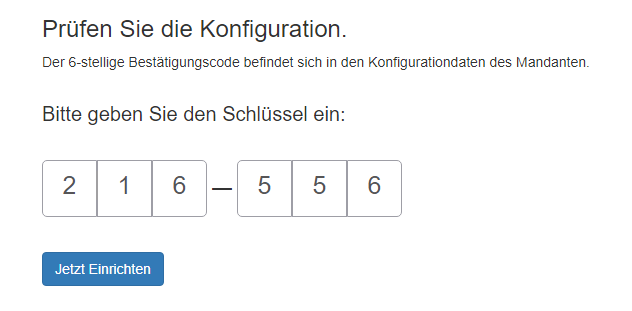
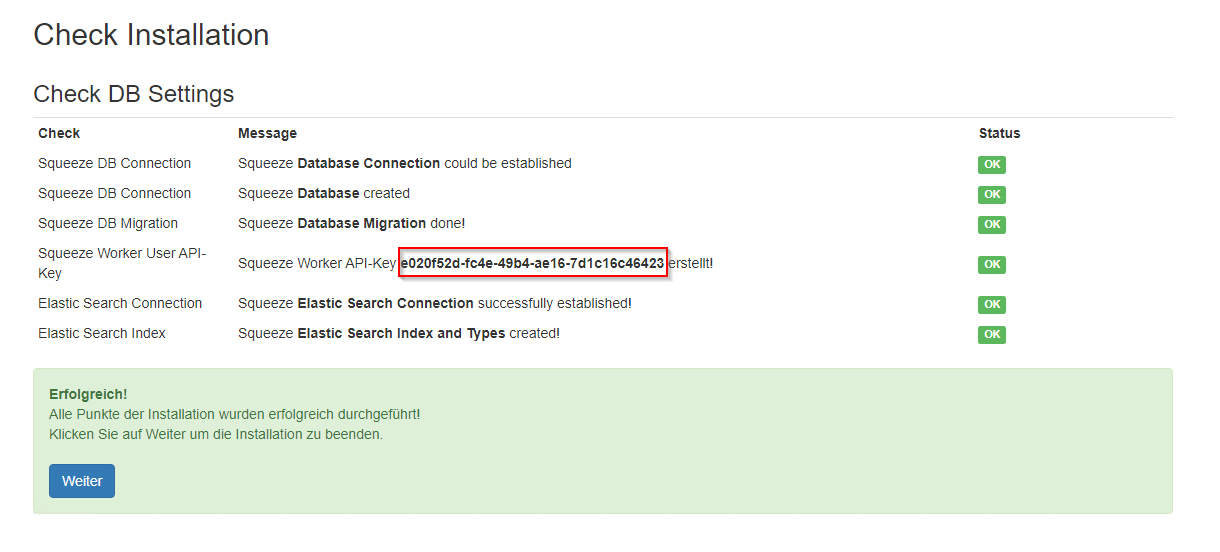
Den Worker-API-Key aufschreiben bzw. Kopieren.
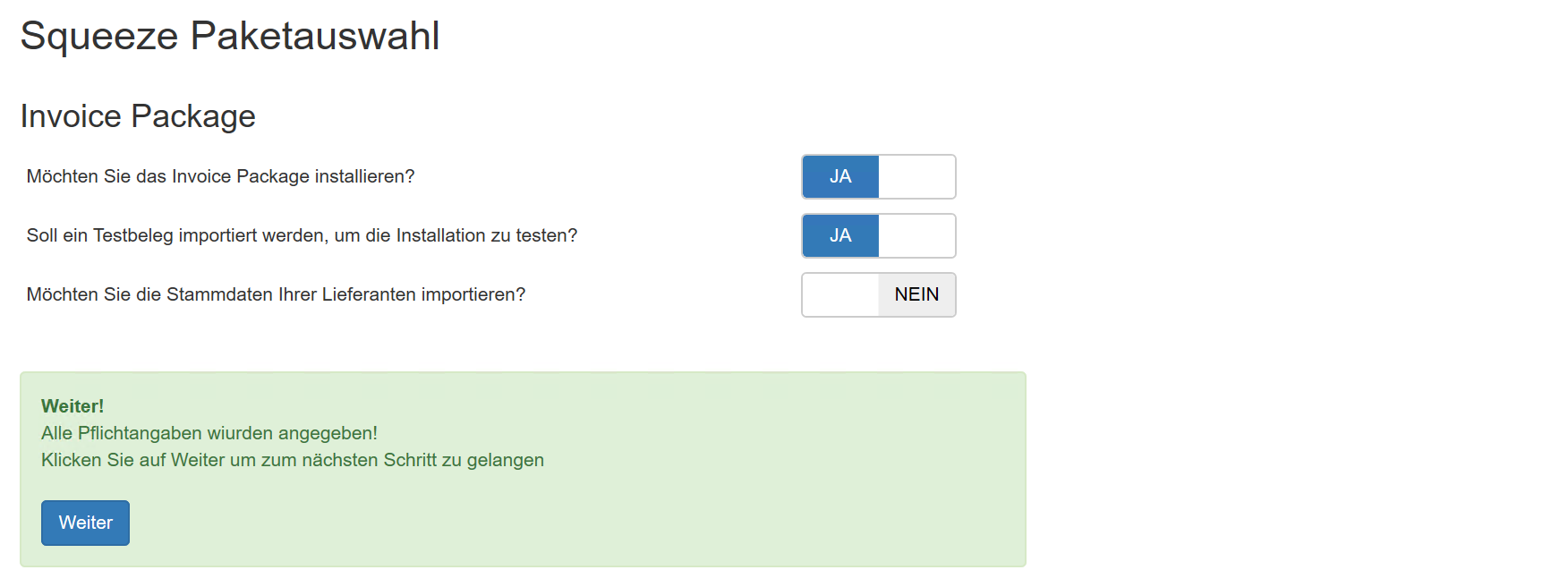
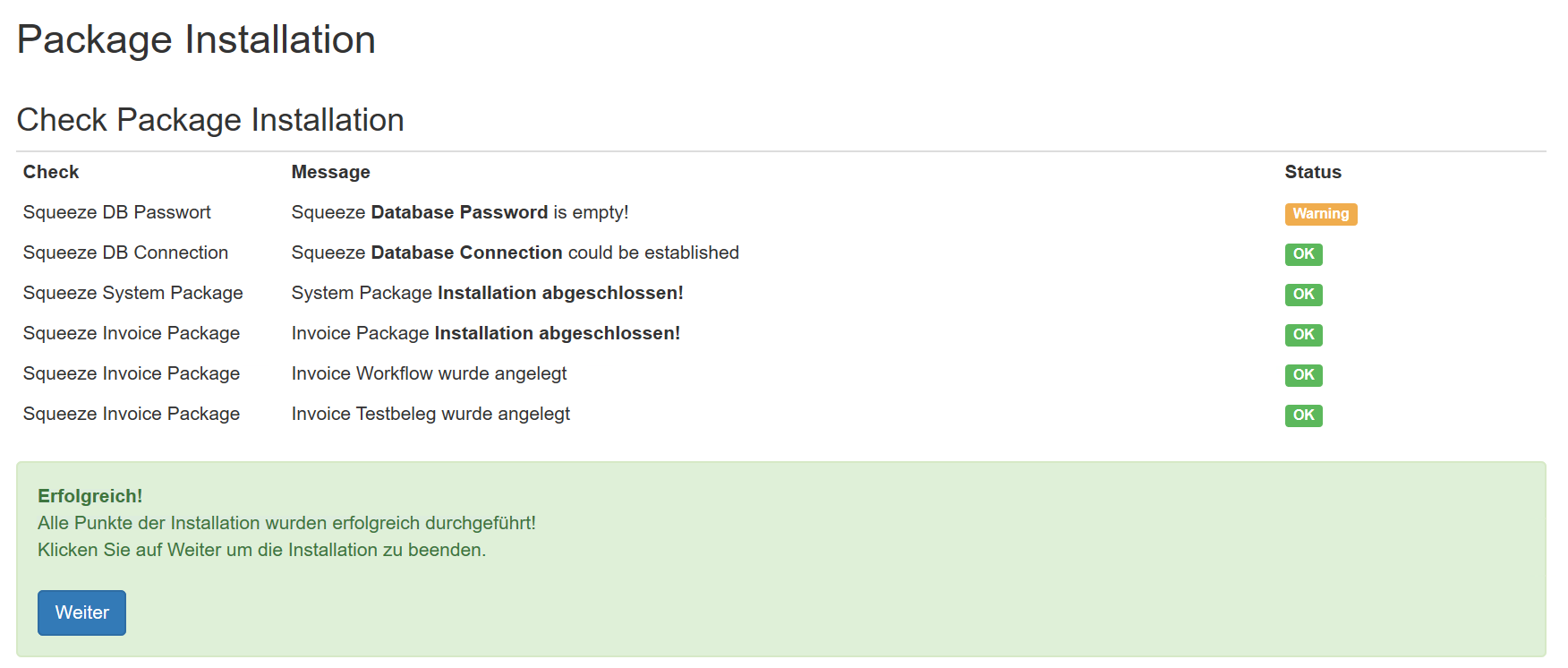
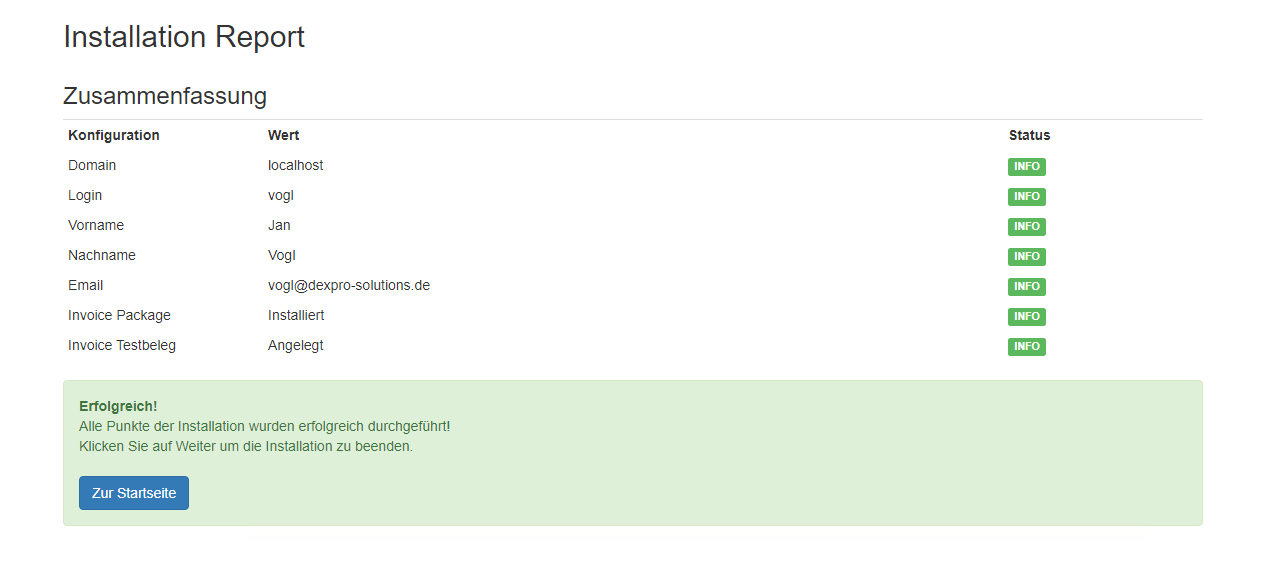
Konfiguration des Workers
C:\SQUEEZE\htdocs\worker\config
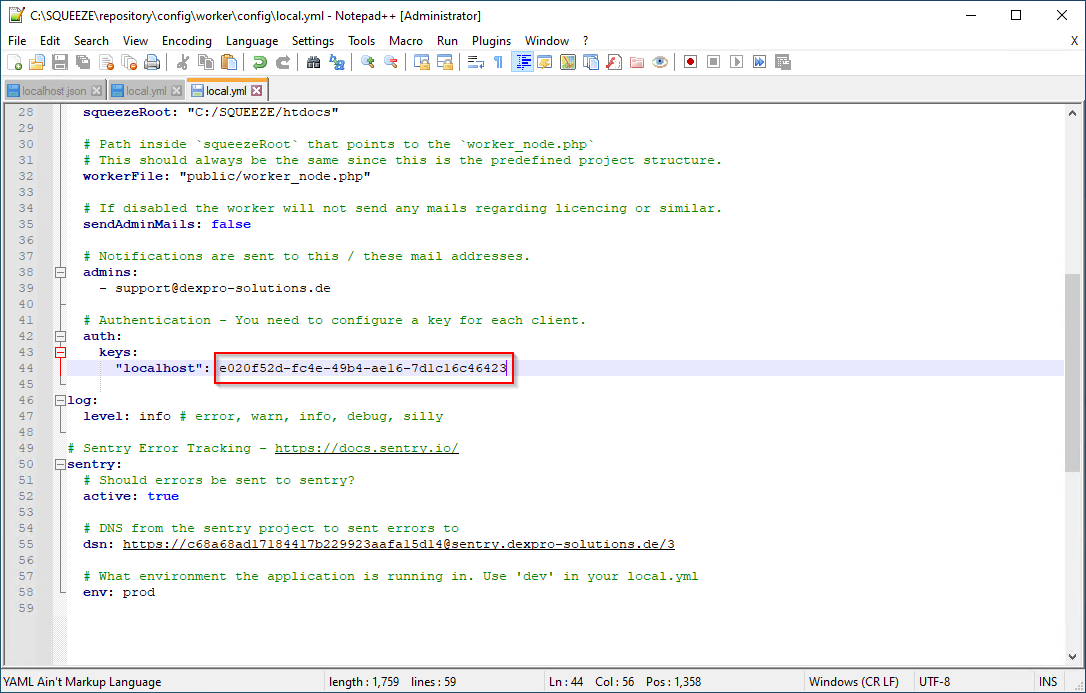
Im markierten Feld den kopierten Worker-Api-Key eintragen und speichern.
In den oben markierten Feldern wird "localhost" durch den "FQDN" des Servers ersetzt.
Die Angabe des Servernames (FQDN) ist Case-Sensitiv.
Wir empfehlen den Servernamen generell in Kleinbuchstaben zu schreiben.
Windows Systeme: Pfad zur PHP.exe wie hier im Screenshot anpassen.
Ggf. das squeezeRoot anpassen.
Nun muss der Worker-Dienst gestartet werden um Dokumente verarbeiten zu können.
Mandanten hinzufügen
Der Mandant benötigt einen Mandantennamen. Abweichend vom bisherigen Namen der bei der initialen Installation verwendet worden ist. Beispiel :
suqeeze.kunde.local neuer Name squeeze-test.kunde.local
Dieser DNS-Name muss auf dem Squeeze-Server, auf dem der neue Mandant eingerichtet werden soll, aufgelöst werden können. Dazu sollte entweder der Kunde diese URL in seinem DNS-Server mit der IP-Adresse des Squeeze-Servers einrichten oder wenn man die Installation des neuen Mandanten durchführen möchte (bevor dieser DNS-Eintrag vom Kunden bereitgestellt worden ist) könnte man in der Host-Datei des Windows-Servers einen neuen Eintrag für diese URL mit der IP-Adresse des Squeeze-Servers setzen. Dann würde man die Installation durchführen können, aber die URL wäre nur lokal (auf dem Squeeze-Server) erreichbar.
Um den neuen Mandanten anzulegen geben Sie in der im Browser die gewünschte URL ein um in die Mandanteneinrichtung zu gelangen.

Danach befolgen Sie bitte die Anweisungen zum Anlegen eines neuen Mandanten auf der Seite "Serverinstallation-Windows" im Kapitel "Installation".
Lizenzierung
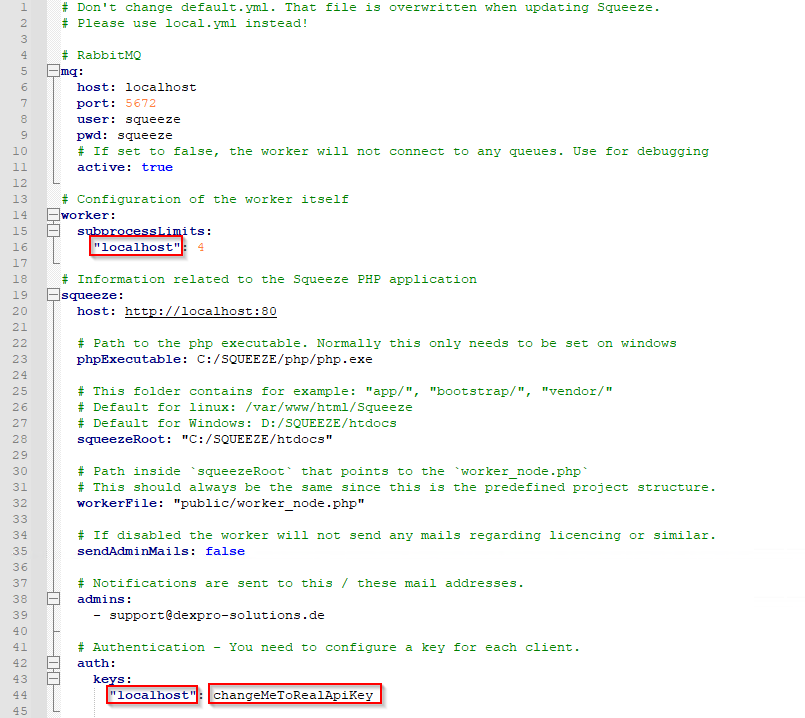
Bitten Sie das Dexpro-Team um die Erstellung einer Lizenz für einen neuen Mandanten. Sobald Sie diese erhalten haben kopieren Sie die Dateien in das Verzeichnis "C:\DEXPRO\SQUEEZE\repository\config\worker\data\licences".

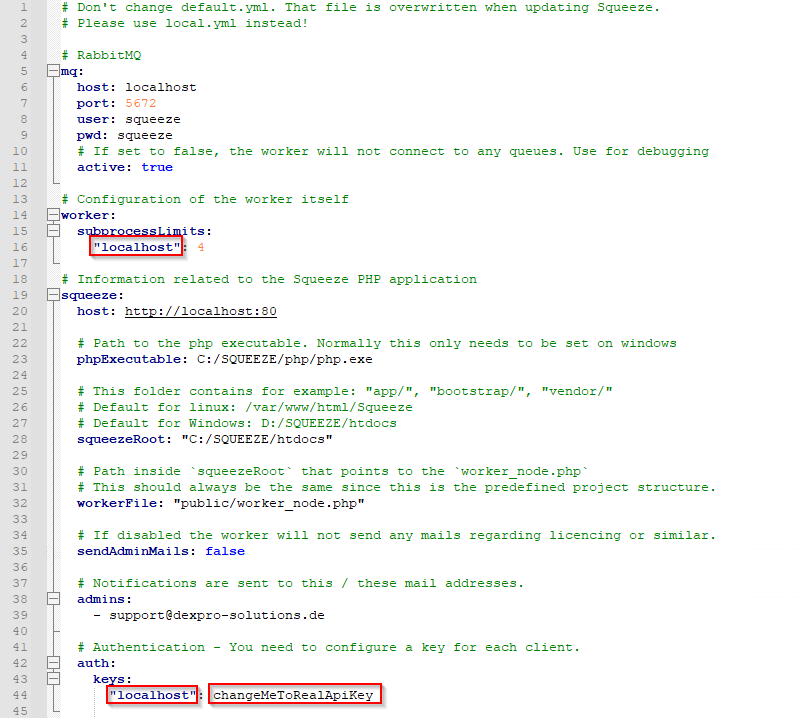
Im Anschluss muss die local.yml-Datei im Verzeichnis "C:\DEXPRO\SQUEEZE\repository\config\worker\config" modifiziert werden.

In der local.yml müssen nun die markierten Werte angepasst werden. Im Bereich Worker muss der Wert "localhost" (wie hier im Beispiel) durch den Mandantennamen ersetzt werden. Das Gleiche gilt für den Eintrag unter "Authentication -> keys". Zum Schluss wird im letzten markierten Feld der Api-Key eingetragen.
Update/Upgrade
Anleitungen zum Durchführen von Updates und damit verbundenen Tätigkeiten.
Update auf Linux
Um Squeeze auf einem Linux System upzudaten kann wie folgt vorgegangen werden:
Datenbanksicherung durchführen
# Alle Datenbanken
mysqldump --user=root -p --host=127.0.0.1 --protocol=tcp --port=3306 --default-character-set=utf8 --routines --events --all-databases --result-file="/var/www/html/2021-01-01_all_databases.bak"
# Eine bestimmte Datenbank
mysqldump --user=root -p --host=127.0.0.1 --protocol=tcp --port=3306 --default-character-set=utf8 --routines --events "databasename" --result-file="/var/www/html/2021-01-01_databasename.bak"Cronjobs stoppen
# Liste der Cronjobs öffnen
crontab -e -u www-data
# z.B. folgenden cronjob mit einen vorangestellten # deaktivieren
#*/5 * * * * php /var/www/html/Squeeze/jobs/EmailProcessing.php client.server.netServices stoppen
systemctl stop squeeze-worker@1.timer
systemctl stop squeeze-worker@1.service
systemctl stop rabbitmq-server.service
systemctl stop elasticsearch.service
systemctl stop mariadb.service
systemctl stop apache2.serviceAb Version 1.10.0 Repository verschieben
Ab der Version 1.10.0 muss das Repository verschoben werden. Wenn eine Version kleiner 1.10.0 ein Update erhalten soll, kann das Repository mit folgendem Befehl verschoben werden:
mv /var/www/html/Squeeze/repository/ /var/www/html/
mkdir /var/www/html/repository/config
mkdir /var/www/html/repository/config/clients
mv /var/www/html/Squeeze/config/server.json /var/www/html/repository/config/server.json
mv /var/www/html/Squeeze/config/server.installed /var/www/html/repository/config/server.installed
mv /var/www/html/Squeeze/config/clients/*.json /var/www/html/repository/config/clients/
mv /var/www/html/Squeeze/config/clients/*.installed /var/www/html/repository/config/clients/
Die *.json Konfigurationsdateien müssen editiert werden, da das Repository der Mandanten verschoben wurde.
Backup der aktuellen Squeeze Version
Um eventuell wieder auf die letzte aktive Version zurückzukommen muss der aktuelle Stand gesichert werden.
cd /var/www/html
tar cfvz "$(date '+%Y-%m-%d')_Squeeze.tar.gz" Squeeze/Update per git fetch und pull
# enter the Squeeze directory
cd /var/www/html/Squeeze
# ggf. git clone
git clone https://langer@dev.azure.com/DEXPRO/DEXPRO%20Platform/_git/SQUEEZE .
# fetch the available branches
git fetch
# pull the branch (hard reset)
git reset --hard origin/develop_or_another_branch
Worker Konfiguration übernehmen
Rechte aktualisieren
cd /var/www/html
chown -R www-data Squeeze/
chmod -R 755 Squeeze/Services starten
systemctl start mariadb.service
systemctl start apache2.service
systemctl start rabbitmq-server.service
systemctl start elasticsearch.service
systemctl start squeeze-worker@1.timer
systemctl start squeeze-worker@1.service System Migration per API ausführen
Die Datenbank Migrationen müssen noch manuell über die API geprüft bzw. ausgeführt werden. http://client.server.net/api/migrationStatus
Update auf Windows
Diese Seite dokumentiert, wie Updates von Squeeze auf Windows durchzuführen sind.
Die Update-Schritte sind i. d. R. gleich, je nach Produktversion können allerdings einzelne Sonder-Tätigkeiten wie z. B. das aktivieren einer PHP-Extension notwendig sein.
Grundsätzliches Vorgehen
1. Update des htdocs Ordners
Der htdocs enthält den Programmcode von Squeeze und stellt i. d. R. die einzige zu aktualisierende Komponente dar.
Schritte
- Datenbankbackup erstellen!
- SQUEEZE Dienste beenden
- htdocs Verzeichnis sichern
- neues htdocs Verzeichnis im SQUEEZE Verzeichnis entpacken / SQUEEZE-Update-2.xx.x.exe als Administrator auf dem Server ausführen
- Im htdocs\Worker-Verzeichnis muss die umzug.json enthalten sein, sie muss aus dem gesicherten htdocs Verzeichnis kopiert werden.

- Ggf. sicherstellen ob Jobs aus dem alten htdocs\jobs Verzeichnis in das neue htdocs\jobs Verzeichnis kopiert werden müssen.
- SQUEEZE Dienste wieder starten
- Datenbankmigration über die Web-Oberfläche ausführen:

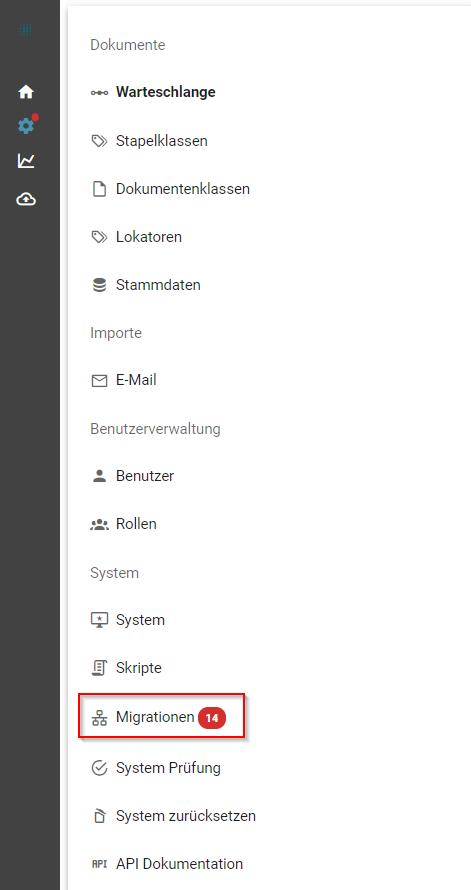
Zur Durchführung einer Datenbankmigration muss unter dem Reiter Migrationen das Symbol "Migration Ausführen" angeklickt werden.
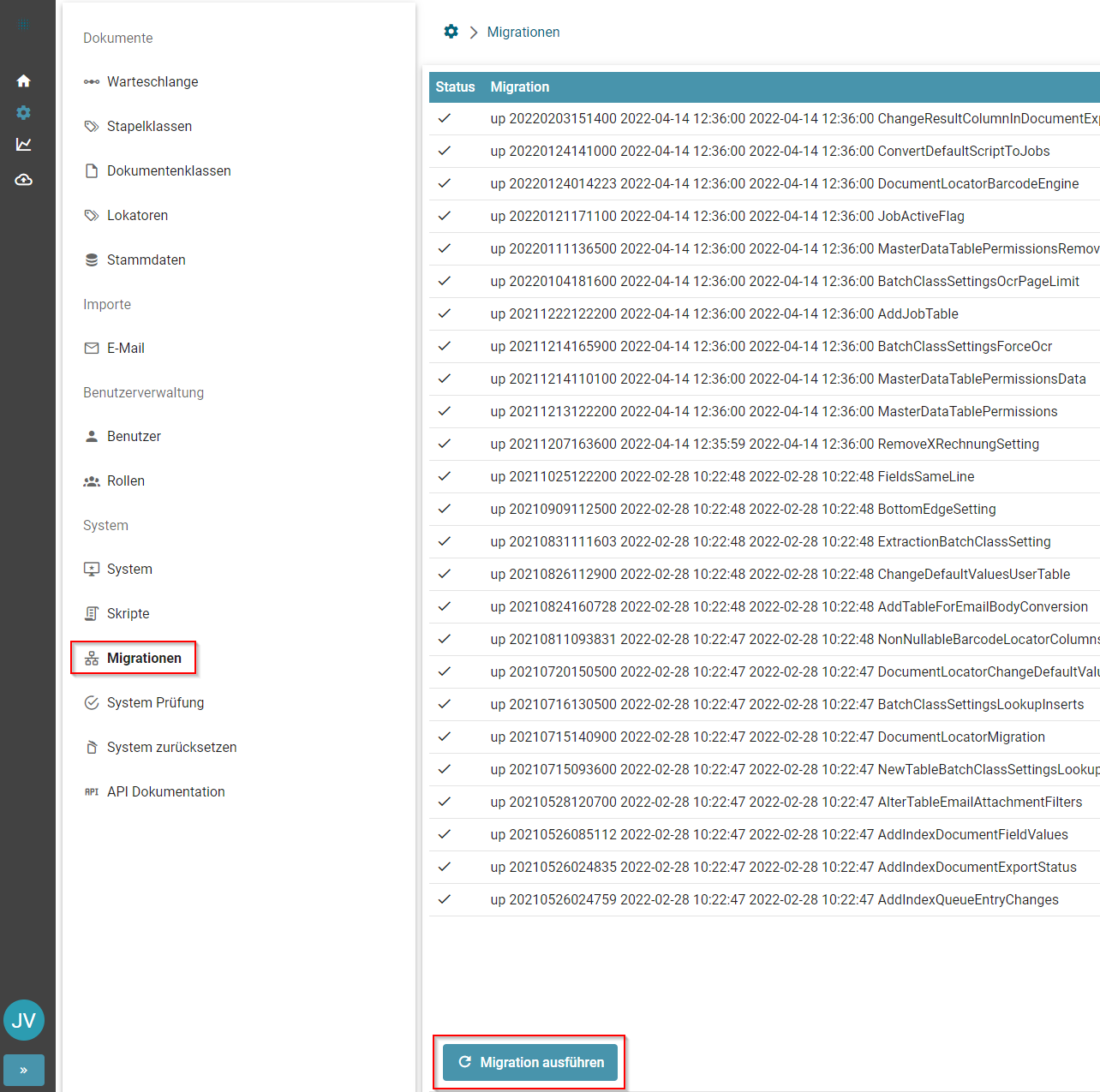
Tragen Sie nun den Mandantennamen in das angegebene Feld ein und klicken Sie auf "Speichern" um die Migration auszuführen.
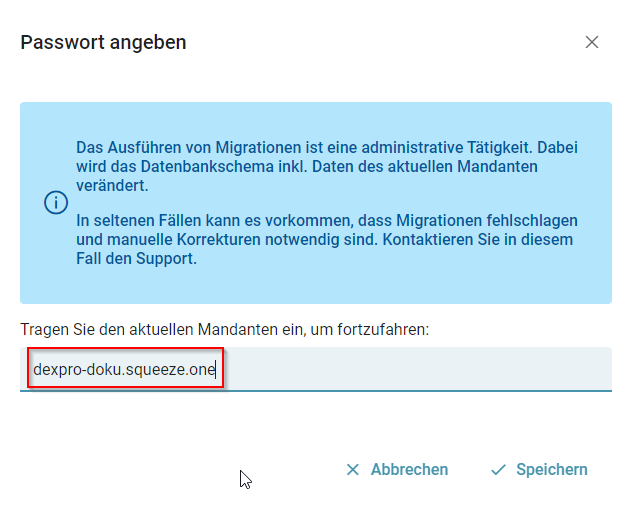
Nun kann über den Reiter "System" die aktuelle Version des Systems angezeigt werden.
2. Update von anderen Komponenten
Die folgenden Schritte sind nicht bei jedem Update notwendig. Sie müssen nur beachtet werden, falls eine der vermerkten Versionen zum Einsatz kommt und die notwendigen Voraussetzen nicht erfüllt sind.
PHP Extension - sodium (ab Squeeze Version 2.3.0)
Ab Squeeze 2.3.0 wird die PHP Extension Sodium benötigt.
Die Datei kann unter \Squeeze\php\php.ini gefunden werden. In der Datei nach "Sodium" suchen und in der entsprechenden Zeile das Semikolon entfernen:

Auf manchen Windows Systemen reicht es nicht aus die sodium Extension hinzuzufügen. In diesem Fall muss zusätzlich das PHP Verzeichnis z.B. D:\SQUEEZE\php in die PATH Umgebungsvariable aufgenommen werden.
Anschließend muss der Webserver einmal neu gestartet werden.
OpCache deaktivieren (jede Squeeze Version)
- opcache für CLI Prozesse deaktivieren (opcache.enable_cli=0 in der php.ini)
Chromium (ab Squeeze Version 1.7.0)
Ab Squeeze 1.7.0 wird Chromium für das PDF-Rendering von E-Mails verwendet. [Download]
Der Inhalt des Downloads muss in den Ordner htdocs\lib\chromium kopiert werden. Hierbei handelt es sich um eine "google-freie" Version von Chromium in der Version 111.0.5563.71. Die Funktionalität wurde mit dieser Chromium-Version getestet und nur in dieser Version kann eine fehlerfreie Ausführung gewährleistet werden.
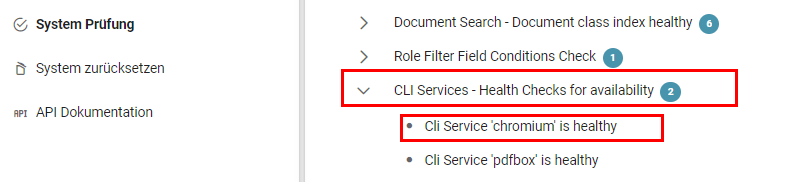
Ab Squeeze 2.4.0: Wenn Chromium erfolgreich eingebunden ist, kann dies in der in der Systemprüfung unter dem Punkt "CLI Services - Health Checks for availability" eingesehen werden. Ansonsten wird hier ein Fehler angezeigt.
Datenbankmigration nach Update
Migration eines einzelnes Mandanten via UI
Zur Durchführung einer Datenbankmigration muss unter dem Reiter Migrationen das Symbol "Migration Ausführen" angeklickt werden.
Tragen Sie nun den Mandantennamen in das angegebene Feld ein und klicken Sie auf "Speichern" um die Migration auszuführen.
Migration aller Mandanten via CLI
Im Squeeze-Ordner (htdocs unter Windows) befindet sich ein Ordner cli mit Skripten für die Administration. Hier kann das PHP-Skript migrate-tenant.php ausgeführt werden um einen einzelnen Mandanten zu aktualisieren.
Mit dem Skript migrate-server.php werden alle Kommandozeilenbefehle gelistete, die benötigt sind, um alle Mandanten eines Servers zu aktualisieren.
Beispiele
php migrate-tenant.php mein-mandant.local.intern führt die Migrationen für einene Mandanten aus.
php migrate-server.php listet alle Befehle auf, die alle installierten Mandanten migrieren würden.
(Linux) php migrate-server.php | bash migriert sequentiell alle Mandanten.
Suchindex nach Update reindizieren
Reindizierung einer einzelnen Dokumentenklasse
Um den Suchindex einer einzelnen Dokumentenklasse wiederzuerstellen, kann dieser Button genutzt werden:
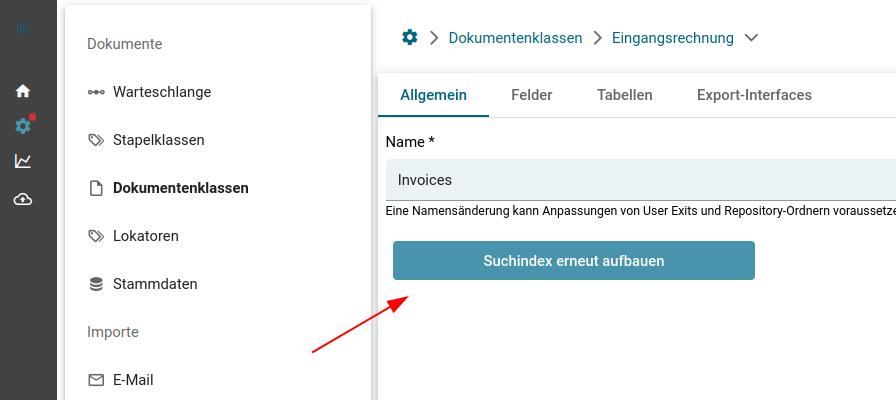
Aktuell Q2 2023 ist diese Funktion noch synchron. D. h., dass bei einer Dokumentenklasse mit vielen Dokumenten eine lange Wartezeit entsteht und der User, der diesen Knopf drückt, entsprechend lang warten muss.
Migration via CLI / Konsole
Ab Squeeze 2.5
Mit dem Squeezer CLI ist die Indizierung eines einzelnen Mandanten mittels tenant:reindex und des gesamten Servers mittels server:reindex möglich.
# Hilfe für Mandanten-Reindizierung anzeigen:
./squeezer tenant:reindex --help
Description:
Reindex documents of all document classes
Usage:
tenant:reindex <tenant>
Arguments:
tenant Tenant identifier (host / domain) of the tenant to run the command for.
Options:
-h, --help Display help for the given command. When no command is given display help for the list command
-q, --quiet Do not output any message
-V, --version Display this application version
--ansi|--no-ansi Force (or disable --no-ansi) ANSI output
-n, --no-interaction Do not ask any interactive question
-v|vv|vvv, --verbose Increase the verbosity of messages: 1 for normal output, 2 for more verbose output and 3 for debugVor Squeeze 2.5
Im Squeeze-Ordner (htdocs unter Windows) befindet sich ein Ordner cli mit Skripten für die Administration. Hier kann das PHP-Skript reindex-tenant.php ausgeführt werden um alle Dokumentenklassen eines einzelnen Mandanten zu aktualisieren.
Mit dem Skript reindex-server.php werden alle Kommandozeilenbefehle gelistete, die benötigt sind, um dies für alle Mandanten eines Servers durchzuführen.
Diese Migrationsskripte reindizieren Dokumente aller Dokumentenklassen.
Beispiele
php reindex-tenant.php mein-mandant.local.intern reindiziert einen Mandanten.
php reindex-server.php listet alle Befehle auf, die alle installierten Mandanten reindizieren würden.
(Linux) php reindex-server.php | bash reindiziert sequentiell alle Mandanten.
PHP Update unter Windows
Aktuell wird von Squeeze nur die PHP Version 7.4.x unterstützt. Da in regelmäßigen Abständen neue Hotfixes für PHP erscheinen wird hier der Updateprozess beschrieben.
Aktuell prüfen wir die Umstellung auf die php Version 8.1.x. Im Moment sind die Versionen 8.x.x jedoch noch nicht freigegeben.
Was ist zu tun?
-
Herunterladen der aktuellen PHP Version aus unserem Forum (Anmeldung erforderlich)
-
Stoppen der Dienste 01_SQUEEZE_WebServer und 05_SQUEEZE_Worker
-
Backup des aktuellen PHP Verzeichnisses
C:\SQUEEZE\php verschieben nach C:\SQUEEZE\backup\php -
Entpacken der heruntergeladenen Zip-Datei in das Squeeze Basisverzeichnis

-
Squeeze Basisverzeichnis auswählen
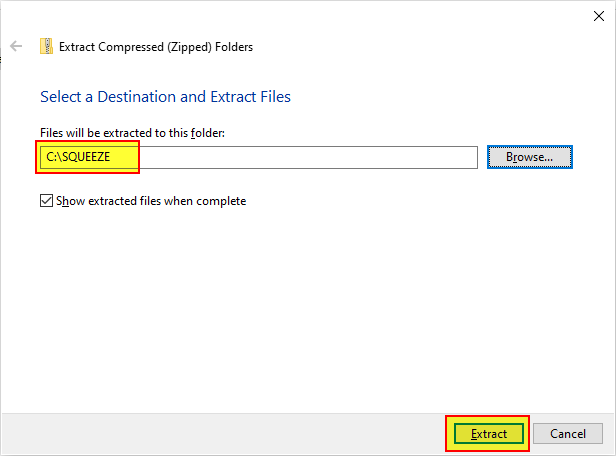
- Anschließend die php.ini aus dem Ursprungsverzeichnis in das neue Verzeichnis kopieren
C:\SQUEEZE\backup\php\php.ini kopieren nach C:\SQUEEZE\php\php.ini -
Dienst 01_SQUEEZE_WebServer starten
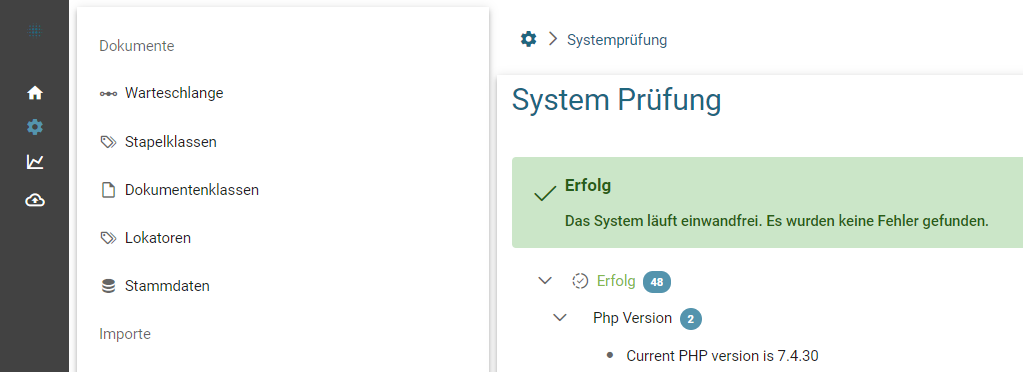
- In SQUEEZE anmelden und unter System Prüfung die PHP Version kontrollieren

- Dienst 05_SQUEEZE_Worker starten
Apache Update unter Windows
Aktuell wird von Squeeze nur die Apache/2.4.x unterstützt. Da in regelmäßigen Abständen neue Hotfixes für Apache erscheinen wird hier der Updateprozess beschrieben.
Was ist zu tun?
-
Herunterladen der aktuellen Apache Version aus unserem Forum (Anmeldung erforderlich)
-
Stoppen der Dienste 01_SQUEEZE_WebServer und 05_SQUEEZE_Worker
-
Backup der aktuellen Version für einen eventuellen Rollback z.B. C:\SQUEEZE\apache verschieben nach C:\SQUEEZE\backup\apache
-
Entpacken der Zip-Datei in das Squeeze Basisverzeichnis (z.B. C:\Squeeze\)

-
Squeeze Basisverzeichnis auswählen
- Anschließend den Ordner conf aus dem Ursprungsverzeichnis in das neue Verzeichnis kopieren
C:\SQUEEZE\backup\apache\conf kopieren nach C:\SQUEEZE\apache\conf - Eventuell konfigurierte SSL Zertifikate müssen ebenfalls übernommen werden.
In der Regel liegen diese Zertifikate unter D:\SQUEEZE\apache\conf\ssl* und werden daher schon durch den vorherigen Schritt berücksichtigt. -
Dienst 01_SQUEEZE_WebServer starten
Logging & Debugging
Anleitungen zur Konfiguration und Verwendung von Logging & Debugging-Möglichkeiten.
System-Information und -Prüfungen
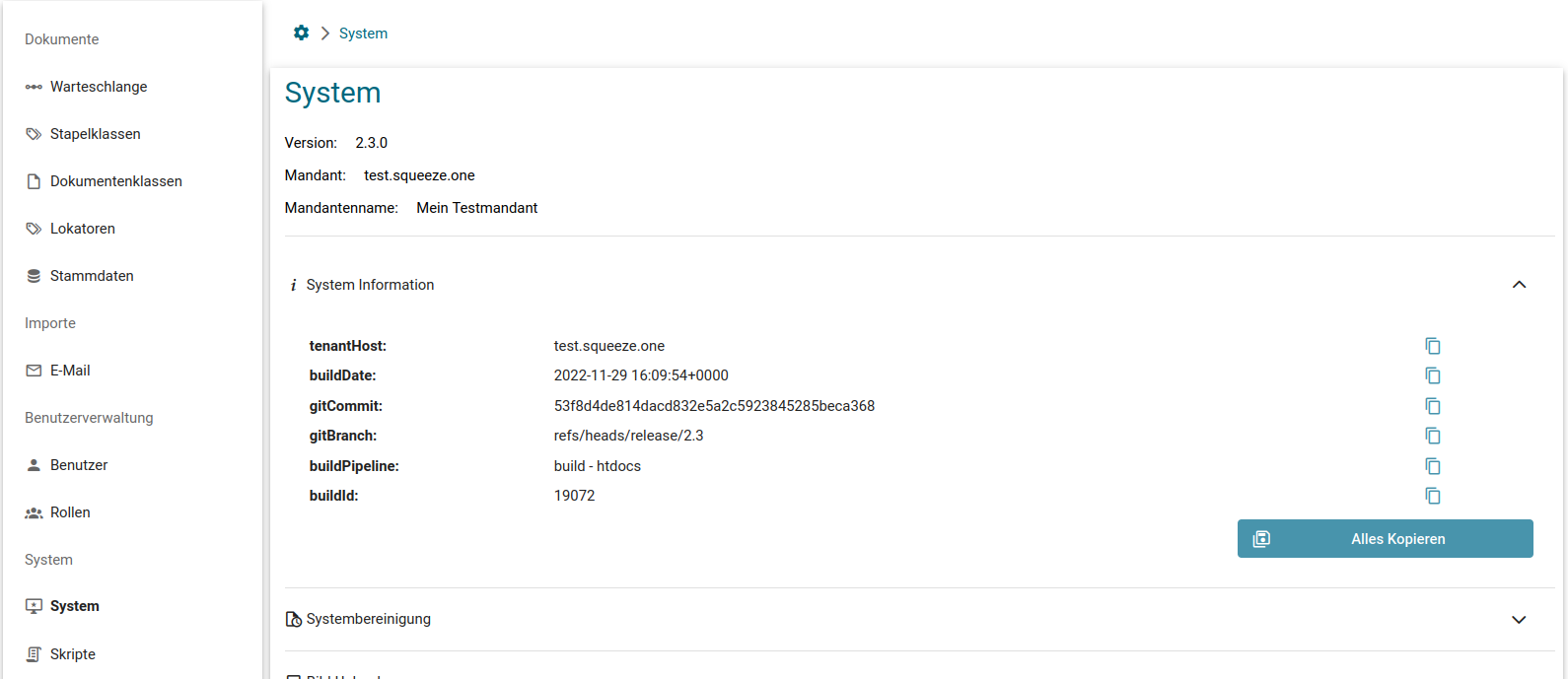
System-Information
In der Administration können Sie sich in dem dargestellten Bereich Informationen über Ihr System anzeigen lassen. Dazu gehören bspw. die Produktversion, Build-Informationen, Informationen über das Betriebssystem des Servers usw.
Zudem können die System-Informationen über den Einstellungen-Dialog aufgerufen werden.
Mit einem Klick auf "Alles Kopieren" können Sie die System-Informationen gesammelt in ihre Zwischenablage kopieren und bei Support-Tickets mitsenden, um die Bearbeitung von Support-Fällen zu unterstützen.
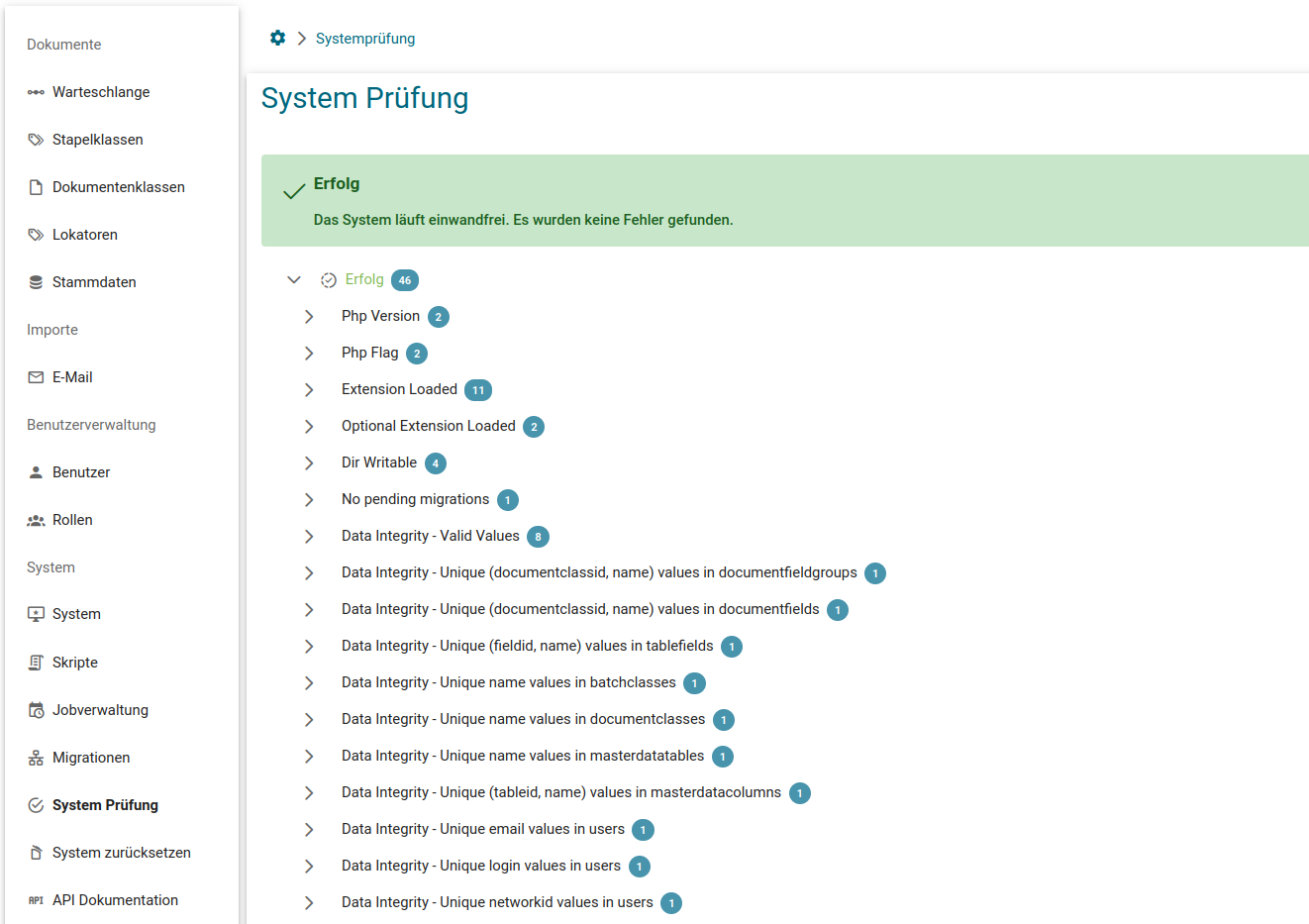
System-Prüfungen
Die System-Prüfungen sind ein Mittel um schnell zu testen, ob sich eine Installation in einem korrekten Zustand befindet. Bei diesen Prüfungen werden diverse Dinge getestet wie z. B. die installierte PHP Version, Schreibberechtigungen auf dem Dateisystem, aber auch inhaltliche Prüfungen der Konfigurationen von Squeeze.
Die Prüfung kann 3 Ergebnisse haben:
- Grün - Das System ist in einem fehlerfreien Zustand und kann genutzt werden.
- Gelb - Das System ist nutzbar, hat allerdings Warnungen, die behoben werden sollten. Es könnte bei Behebung dieser Fehler langfristig zu Problemen kommen.
- Rot - Das System ist in einem fehlerhaften Zustand und sollte nicht genutzt werden, bevor die Fehler behoben sind.
Der Support eines Systems mit Fehlern (rotes Prüfungsergebnis) kann je nach Wartungsvereinbarung unterschiedlich ausfallen. Grundsätzlich ist es ratsam Fehler in dieser Prüfung so schnell wie möglich zu lösen.
Stapelklassen
Konfigurations-Anleitungen im Kontext von Stapelklassen.
Stapelklassen
Stapelklassen erfüllen in Squeeze mehrere Funktionen.
1. Stapelklassen sind Gruppierungen von Dokumentenklassen
In einer Stapelklasse können mehrere Dokumentenklassen eingerichtet werden und für die Klassifizierung zusammengefasst werden. Z.B bei der Einrichtung eines Mailrooms.
2. Stapelklassen für Barcode-Erkennung
Die Barcode-Erkennung wird zum Trennen nach Barcode oder zur Erkennung von Anhängen nach Barcode verwendet. Die Definition der Barcodes und ihrer Eigenschaften finden Sie auf der Seite Stapelklassen-Eigenschaften.
3. Stapelklasse für OCR-Sprache
Im Standard werden Deutsch und Englisch verwendet. Dies kann erweitert werden, da es in manchen Sprachen bestimmte Sonderzeichen bzw. andere Buchstabensätze gibt. Die Definition der OCR-Sprachen und ihrer Eigenschaften finden Sie auf der Seite Stapelklassen-Eigenschaften.
Stapelklassen anlegen
Nach der Anmeldung in Squeeze können Benutzer mit administrativen Berechtigungen die Konfiguration für Stapelklassen aufrufen.
Liste der Stapelklassen
Nach dem Klick auf den Reiter Stapelklassen öffnet sich die Stapelklassenübersicht. Hier werden alle aktuell konfigurierten Stapelklassen angezeigt. Die Stapelklasse Invoice wird zusammen mit dem Invoice Template ausgeliefert.
In der Liste der Stapelklassen kann man die Konfiguration mit einem Klick auf den Eintrag öffnen.

Neue Stapelklasse anlegen
Neue Stapelklassen können mithilfe des Symbols "Neuer Eintrag" angelegt werden. Daraufhin öffnet sich ein Dialog in dem der technische Namen und der Anzeigenamen eingegeben werden kann.

Ab hier können folgende Konfigurationen durchgeführt werden:
- OCR
- Klassifikationen
- Eigenschaften
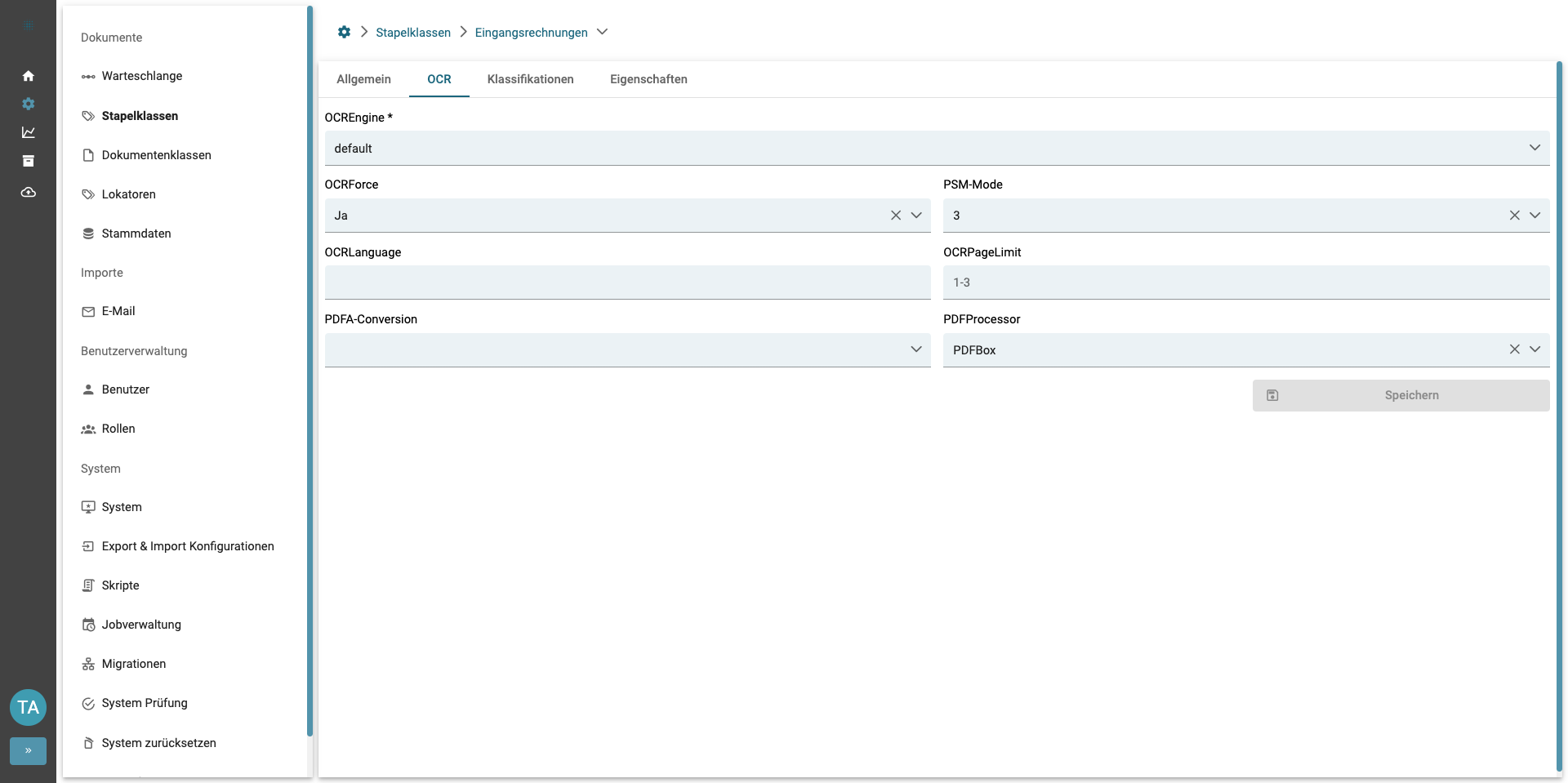
OCR
Eine Stapelklasse enthält eine OCR-Konfigurationsoberfläche, welche spezifische Eigenschaften enthält, die konfiguriert werden können. Die vorhandenen Einstellungen der OCR werden ebenfalls unter den Eigenschaften einer Stapelklasse aufgelistet.
Klassifikationen
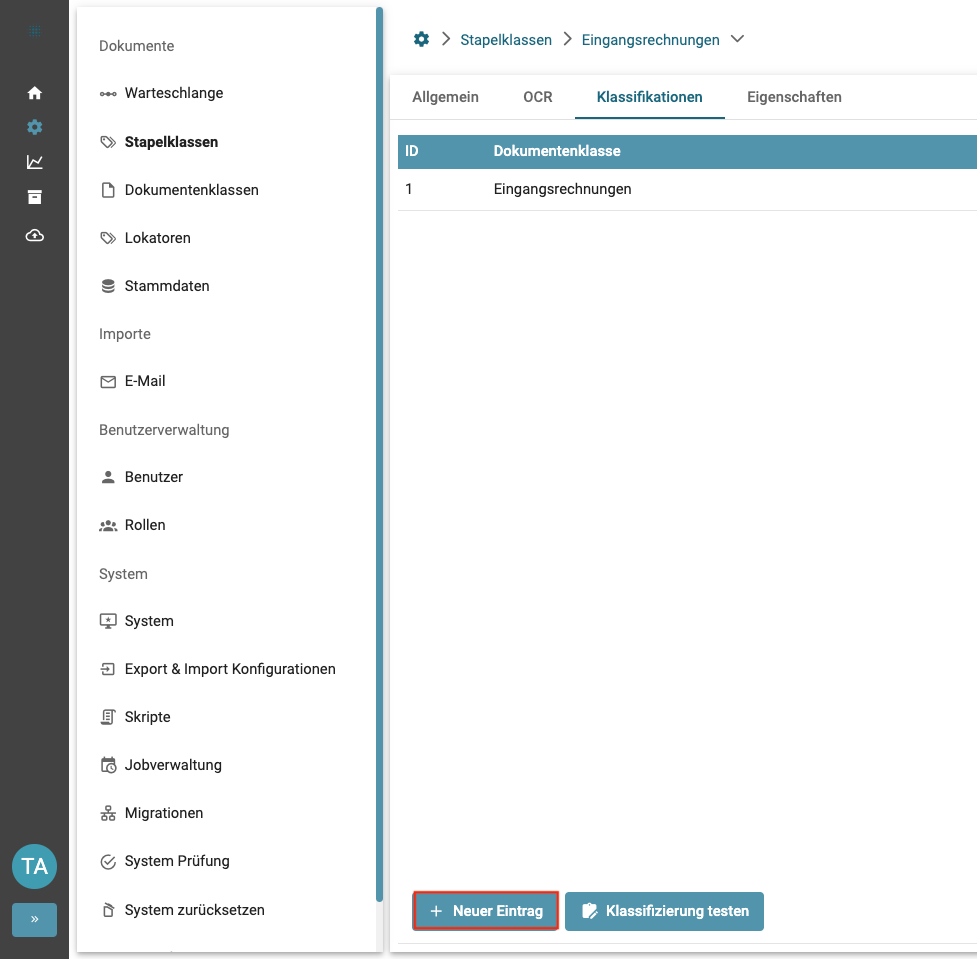
Mit einem Klick auf "Neuer Eintrag" können der Stapelklasse Dokumentenklassen zugeordnet werden.
Eigenschaften
Über das Symbol " Neuer Eintrag" können der Stapelklasse spezifische Eigenschaften hinzugefügt werden.

Stapelklassen-Eigenschaften
Mit Stapelklasseneigenschaften lassen sich allgemeine Konfigurationen pflegen, welche sich auf die Verarbeitung der Dokumente auswirken, die zu der jeweiligen Stapelklasseneigenschaft gehören.
Eigenschaften
AttachmentBarcodePattern und SplitBarcodePattern
RegEx zum Erkennen von Barcodenummern für Folgendes Beispiel:

Hier wäre ein RegEx zum Erkennen von 10 Nummern nötig. ([0-9]{10})
Folgen die Nummern jedoch einem bestimmten Muster kann man die Suche eingrenzen. Z.B. 0000012345, 0000012346, 00000123457, etc... (00000[0-9]{5})
AttachmentBarcodeType
Unter AttachmentBarcodeType versteht man die möglichen Barcode-Typen, die verwendet werden können um Anhänge zu erkennen. Z.B. : Typ CODE_128
Die unterstützen Barcode-Typen werden in der UI angezeigt. Für ältere Systeme finden Sie weiter unten eine Liste.
BarcodeEngine
Informationen zur Datenverarbeitung mit Barcodes
| ZXING | Wird als Standard verwendet. Liefert aktuell die Besten Ergebnisse. |
| ZBAR | Kann als Alternative benutzt werden, falls ZXING kein Ergebnis liefert. |
| SOFTEK | Engine, die ab Squeeze 2.4 verfügbar ist und eine separate gültiger Lizenz erfordert. |
| ALL | Es werden beide Engines nacheinander verwendet (führt zu längerer Laufzeit). Verfügbar ab Version 2.0 |
BarcodeImageColor
| original | Das Originalbild wird unverändert verwendet. |
| grayscale | Das Bild wird in Graustufen konvertiert. |
| black | Das Bild wird in Schwarz/Weiß konvertiert. |
EasAllowDocumentWithoutAttachment
Im Regelfall wird die Archivierung nur zugelassen, wenn am Vorgang auch ein Dokument vorhanden ist. Sollten auch Dokumente archiviert werden können muss diese Eigenschaft auf true gesetzt werden. Standard ist hier der Wert false.
ExportAfterExtraction
Hier kann festgelegt werden ob Dokumente in die Validierung gelangen oder direkt exportiert werden sollen. Für den direkten Export wird true eingetragen. Soll das nicht passieren tragen Sie false ein. Standard ist hier der Wert false.
FilterDuplicateEmailAttachments
Beim Import wird für jedes Vorgangsdokument ein Hashwert erstellt und geprüft.
Sollte in einer neuen Email das exakt gleiche Dokument erneut importiert werden, wird geprüft ob es diesen Hash bereits gibt. Wenn ja und die Stapelklasseneigenschaft gesetzt ist wird dieses Dokument nicht importiert.
Wert true gilt als Standard für aktiviert und false für Deaktiviert.
FilterDublicateEmails
Beim Import wird für jede EML-Datei ein Hashwert erstellt und geprüft.
Sollte eine neue exakt gleiche Email erneut importiert werden, wird geprüft ob es diesen Hash bereits gibt. Wenn ja und die Stapelklasseneigenschaft ist gesetzt, wird diese Email nicht importiert.
Wert true gilt als Standard für aktiviert und false für Deaktiviert.
IgnoreMandatoryFieldCheckForExport
Wenn der Automatische Export konfiguriert worden ist ( ExportAfterExtraction ) und diese Stapelklasseneigenschaft ist gesetzt, dann wird beim automatischen Export die Pflichtfeldprüfung ignoriert. Im Standard ist das Ignorieren der Felder deaktiviert. (Wert false). Um die Pflichtfeldprüfung beim automatischen Export zu deaktivieren ist diese Eigenschaft auf true zu setzen.
OCR
Einstellungen bzgl. der OCR / Texterkennung werden hier näher dokumentiert: OCR-Stapelklasseneigenschaften in Squeeze
SoapAllowIncomingDocumentWithoutAttachment
Ist diese Eigenschaft auf "true" gesetzt können über den Soap-Server Dokumente angelegt werden ohne das ein Bild übergeben werden muss.
SoapIncomingFileTypeFilter
Mit dieser Eigenschaft kann entschieden werden welche Dateitypen (PDF,TIF,JPEG,etc...) zugelassen werden. Ist diese Eigenschaft nicht gesetzt, werden nur PDF-Dateien zugelassen. Die Trennung erfolgt durch Semikolon. Die Dateiendungen sind Case-Insensitiv.
SpaceMaxWidth
Bis zu welcher Anzahl an Pixeln soll ein Leerzeichen erkannt werden. Ein Beispiel im Standard wären 55 Pixel. Als Wert ist hier die Anzahl an Pixeln einzutragen.
SplitBarcodeType
Unter SplitBarcodeType versteht man die möglichen Barcode-Typen, die verwendet werden können um ein neues Dokument zu erkennen. Z.B. : Typ CODE_128
Die unterstützen Barcode-Typen werden in der UI angezeigt. Für ältere Systeme finden Sie weiter unten eine Liste.
SplitFixPages
Hierbei wird eine fixe Seitentrennung nach der angegebenen Seite konfiguriert. Z.B.: Trenne Jedes Dokument nach der zweiten (2) Seite.
SkipXmlExtraction
Diese Stapelklasseneigenschaft kann mit true oder false bzw. mit ja oder nein konfiguriert werden. Diese Eigenschaft steuert das Überspringen der Werte-Extraktion von XML-Information. Ist diese Eigenschaft mit true belegt so überspringt der Extraktions-Schritt die Verarbeitung der XML-Information. Ist diese Eigenschaft mit false belegt, wird die Verarbeitung wie gewohnt durchgeführt. Ist die Eigenschaft nicht konfiguriert so geht der Extraktions-Schritt davon aus, dass alle XML-Informationen nach Möglichkeit ausgewertet werden.
Diese Eigenschaft hat einen Effekt wenn das Dokument ein reines XML-Dokument ist. Sollte die Eigenschaft auf "ja"/"false" stehen, so werden reine XML-Dokumente wie XRechnung mit einer entsprechenden Fehlermeldung im 1. Verarbeitungschritt abgelegt.
XmlValidationReport
Diese Einstellung steuert ob im ersten Schritt der Dokumentenverarbeitung(Initsialisierung-Schritt) ein KoSIT-Validierungs-Report erzeugt werden soll und kann mit true oder false bzw. mit ja oder nein konfiguriert werden.
Erfordert die Server/Mandanten-Konfiguration des Digivoice-Dienstes
AI-Extraction
Mit dieser Stapelklasseneigenschaft kann die KI gestützte Extraktion und OCR aktiviert werden.
Diese Stapelklasseneigenschaft kann mit true oder false bzw. mit ja oder nein konfiguriert werden.
Zusätzlich zu dieser Eigenschaft muss noch das AI-Extraction-Model angegeben werden, mit der die Extraktion und OCR durchgeführt werden soll.
Diese Eigenschaft benötigt gültige Zugangsdaten zur Autorisierung. Diese können bei der DEXPRO beauftragt werden.
AI-Extraction-Model
Mit dieser Stapelklasseneigenschaft kann das Model der KI gestützten Extraktion und OCR ausgewählt werden.
Zur Auswahl stehen:
invoice
Dieses Modell ist speziell für Eingangsrechnungen trainiert. Dabei kann ein vom Standard abweichendes Mapping in dem UserExit BeforeAiMapping angegeben werden. Dieses Modell überspringt den OCR Schritt und liefert all seine Ergebnisse im Extraktionsschritt. Die OCR wird jedoch nur übersprungen, wenn die Dokumentenklasse bereits feststeht. Andernfalls wird erst die standardmäßig hinterlegte OCR genutzt um den Vorgang als Eingangsrechnung zu klassifizieren.
legacy
Dieses Modell kann mehrere Dokumententypen auslesen. Dazu gehören neben Eingangsrechnungen auch Liefer- und Bestellscheine.
Diese Eigenschaft benötigt gültige Zugangsdaten zur Autorisierung. Diese können bei der DEXPRO beauftragt werden.
AsyncExportAfterValidation
Wenn diese Eigenschaft aktiviert wird, werden Dokumente nach der manuellen Validierung im Hintergrund exportiert.
Dieses Feature ist nützlich bei Export-Schnittstellen, die sehr langsam sind und erlaubt es Validierern das nächste Dokument zu validieren, während im Hintergrund das vorher validierte exportiert wird.
Fehler, die während des Exports auftreten, sorgen dafür, dass das Dokument erneut im Validierungs-Schritt angezeigt wird, damit eine manuelle Fehlerbehandlung / Support möglich ist.
ValidateDocumentOnChange
Hier kann festgelegt werden ob Dokumente in die Validierung wie gehabt durch Feldänderungen validiert werden oder die Validierung durch einen separaten Button ausgelöst werden soll. Für die manuelle Validierung wird false eingetragen. Soll das nicht passieren tragen Sie true ein. Standard ist hier der Wert true.
Barcodetypen
Der Wert für den Barcode Typ ist case-sensitiv (Groß-Kleinschreibung beachten!).
- AZTEC
- CODABAR
- CODE_39
- CODE_93
- CODE_128
- COMPOSITE
- DATABAR
- DATA_MATRIX
- DATABAR_EXP
- EAN_2
- EAN_5
- EAN_8
- EAN_13
- ITF
- ISBN_10
- ISBN_13
- MAXICODE
- PDF_417
- QR_CODE
- RSS_14
- RSS_EXPANDED
- UPC_A
- UPC_E
- UPC_EAN_EXTENSION
Stapelklasseneigenschaften OCR-Texterkennung
Allgemeines
Die OCR Extraktion ist ein elementarer Teil der Squeeze Software. Dieser Kernbereich der Software ist mit verschiedenen Einstellungen versehen, die das Ergebnis der Extraktion tangieren. Im folgenden Artikel gehen wir auf die Besonderheiten und die Anforderungen der unterschiedlichen Eigenschaften ein.
Welche Arten der OCR unterstützt Squeeze?
Grundsätzlich unterscheiden wir im Kontext von Squeeze zwischen dem Einsatz einer OCR basierend auf den Ressourcen der lokalen Maschine und dem Einsatz eines Remote-OCR-Dienstes.
Was beinhaltet meine Standardversion von Squeeze?
Im Auslieferungszustand ist Squeeze mit einer lokal verfügbaren OCR-Engine ausgestattet. Auf Kundenwunsch können unsere Berater bei einer Squeeze Installation ab der Version 2.4 eine Remote-OCR aktivieren, die mithilfe von AI bessere Ergebnisse liefern kann.
Allgemeine Stapelklassen-Eigenschaften
OCREngine (ab Squeeze 2.4)
Wird diese Stapelklassen-Eigenschaft nicht konfiguriert greift automatisch die lokale OCR-Engine ocrmypdf.
Je nach Spezifikation und Lizensierung ihres Squeeze-Systems können folgende Optionen für die OCREngine verwendet werden:
| Squeeze Version | Optionen |
| ab 2.4.0 | default |
| ab 2.4.0 | ai-ocr |
| ab 2.5.0 | maxocr |
| ab 2.6.0 | proxy-ocr |
Voraussetzungen:
- default:
- keine
- ai-ocr:
- um die Remote-AI-OCR zu verwenden ist es notwendig dass eine Internetverbindung auf dem System existiert und dass die Anmeldedaten von Ihrem Squeeze Berater konfiguriert werden.
- maxocr
- die konfigurierte Mandanten-Konfiguration/Server-Konfiguration für die Dexpro Platform Integration.
- die MaxOCR konfiguration.
- proxy-ocr
Stapelklassen-Eigenschaften für die lokale OCR Engine
OCRForce
Im Standard wird bei digitalen PDF´s der Textlayer genutzt und die Felderkennung darauf angewendet (false). Um aber eine OCR zu erzwingen ist dieser Schalter auf true zu setzen.
OCRLanguage
Im Standard werden die Sprachpakete Deutsch und Englisch verwendet. Für die deutsche Detektion wird der Wert deu eingetragen und für die englische Detektion der Wert eng eingetragen.
Hier können projektspezifisch auch weitere Sprachen oder abgewandelte Sprachpaket-Varianten angegeben werden, bei denen die OCR schneller/langsamer bzw. mit niedriger/höherer Qualität Ergebnisse liefert. Im folgenden eine Übersicht über die im Standard enthaltenen Sprachpakete:
| Squeeze Version | Optionen |
| vor 2.4.0 |
|
| ab 2.4.0 |
|
OCRPageLimit
Anzahl der auszulesenden Seiten im Dokument. Syntax n-m
Beispiel für Auslesung der ersten 3 Seiten: 1-3
PDFA-Conversion
Es wird ein PDFA kompatibles Dokument erzeugt. Eingabe 1|0 (true|false)
PDFProcessor
Hier gilt PDFBox als Standard. PDFMiner ist die Alternative .
PSM-Modes
Im Project bietet es sich an, die Modi 3, 4, 6 und 11 zu verwenden. Dabei gilt 3 als Standard.
| 3 | Standardeinstellung liefert gute Ergebnisse. |
| 4 | Wortweise Segmentierung. Es wird nicht nach Zeilen geschaut sondern Worten. (verfügbar ab Version 2.0) |
| 6 | Gut für Positionsdaten. Hat aber Probleme bei Linien die sehr dicht am Text sind. |
| 11 | Gut bei vielen Grafiken auf den Dokumenten. |
OCRRotationThreshold
Mit dieser Eigenschaft können Sie beeinflussen wie agressiv Seiten in der OCR gedreht werden. Nutzen Sie diesen Wert, wenn Dokumente falsch gedreht werden.
Geringe Werte führen dazu, dass mehr Dokumente gedreht werden. Die Software muss sich also nicht sehr sicher sein, dass eine Seite rotiert werden muss.
Hohe Werte führen dazu, dass Dokumente seltener gedreht werden, also nur wenn sich die Software sehr sicher ist, dass eine Seite rotiert werden muss.
Im Standard ist dieser Wert 9.0
Stapelklassen-Eigenschaften für die Remote-AI-OCR/MaxOCR/KI-Proxy Engine
Aktuell gibt es keine Möglichkeiten die Remote-AI-OCR zu beeinflussen.
Fragen und Antworten?
- Ich habe die
ai-ocr/maxocrals OCREngine Eigenschaft ausgewählt, jedoch funktioniert die Texterkennung nicht mehr ?- Gehen Sie bitte Sicher das Ihr Squeeze Berater die notwendigen Anmeldedaten zur Aktivierung der Remote OCR hinterlegt hat.
- Ich habe mit der Remote-AI-OCR ein Dokument verarbeitet, mehrere Dokumente liefen erfolgreich durch, jedoch bleibt dieses Dokument hängen.
- Aufgrund der begrenzten Ressourcen kann die AI-Remote-OCR maximal 100 Seiten pro Dokument verarbeiten. Überprüfen Sie daher die Anzahl der Seiten und nutzen bei nicht erfolgreicher Verarbeitung die lokale OCR.
- Ich nutze die Remote-AI-OCR und und mein Dokument hat mehrere Seiten jedoch nicht mehr als 100 Seiten trotzdem hängt das Dokument in der Verarbeitungskette fest.
- Squeeze wartet insgesamt 3 Minuten auf die Verarbeitung des Dokumentes. Konnte der entfernte Dienst innerhalb dieser 3 Minuten das Dokument nicht verarbeiten, wird Squeeze eine Fehlermeldung mit einem Timeout Hinweis liefern. Schieben Sie das Dokument erneut über die technische Warteschlange in den Schritt "Texterkennung" Squeeze prüft in dem Fall ob das bereits hochgeladene Dokument verarbeitet wurde.
Dokumentenklassen
Konfigurations-Anleitungen im Kontext von Dokumentenklassen.
Dokumentenklassen
Einführung
Dokumentenklassen beschreiben jeweils einen spezifischen Dokumententyp.
Innerhalb einer Dokumentenklasse können für den jeweiligen Dokumententyp, spezifische Konfigurationen angelegt werden:
1. Felder und Tabellen
- Lieferantennummer
- Lieferanten-Name
- Bestellnummer
- ID im ERP
- ...
2. Feldgruppen (auf getrennten Reitern befindliche Felder)
- Kopfdaten
- Metadaten
- ...
3. Verlinkung zu Lokatoren (Wie werden Werte für ein Feld gefunden?)
- reguläre Ausdrücke
- Datenbank-Link,
- Key-Value
- ...
4. Export-Schnittstellen (Wie werden validierte Dokumente in das Folgesystem gebracht?)
- Documents Soap
- XML-Datei
- Webservice
- ...
5. Eigenschaften (allgemeine Konfigurationen für eine Dokumentenklasse)
Alle möglichen Eigenschaften sind unter der Dokumentationseite der Stapelklassen-Eigenschaften aufgelistet.
Die Eigenschaften an einer Dokumentenklasse überschreiben die Eigenschaften an einer Stapelklasse.
Dokumentenklasse anlegen
Dokumentenklassen können mit einem Klick auf den Reiter Dokumentenklassen konfiguriert werden
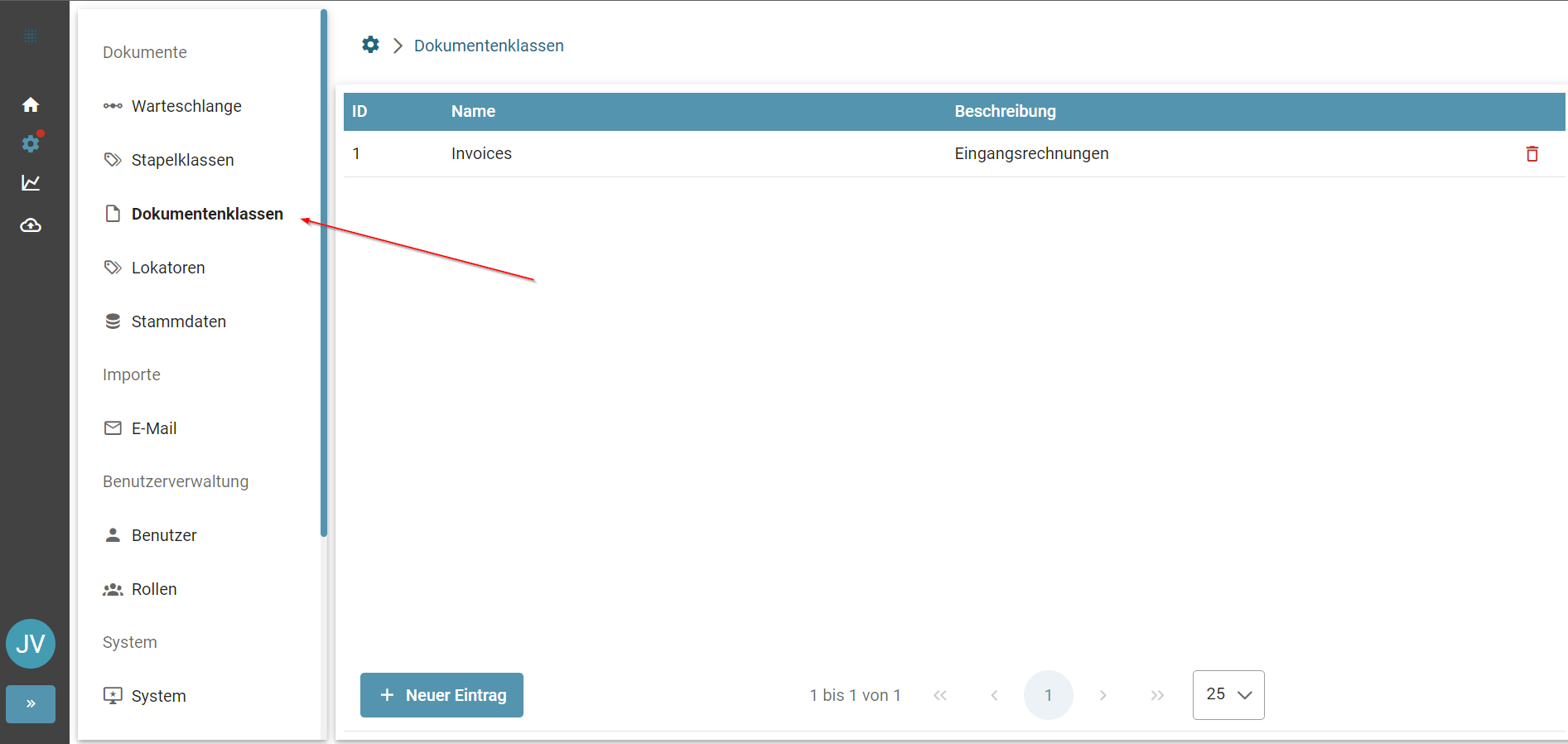
Die Invoice Dokumentenklasse wird mit dem Invoice Template ausgeliefert.
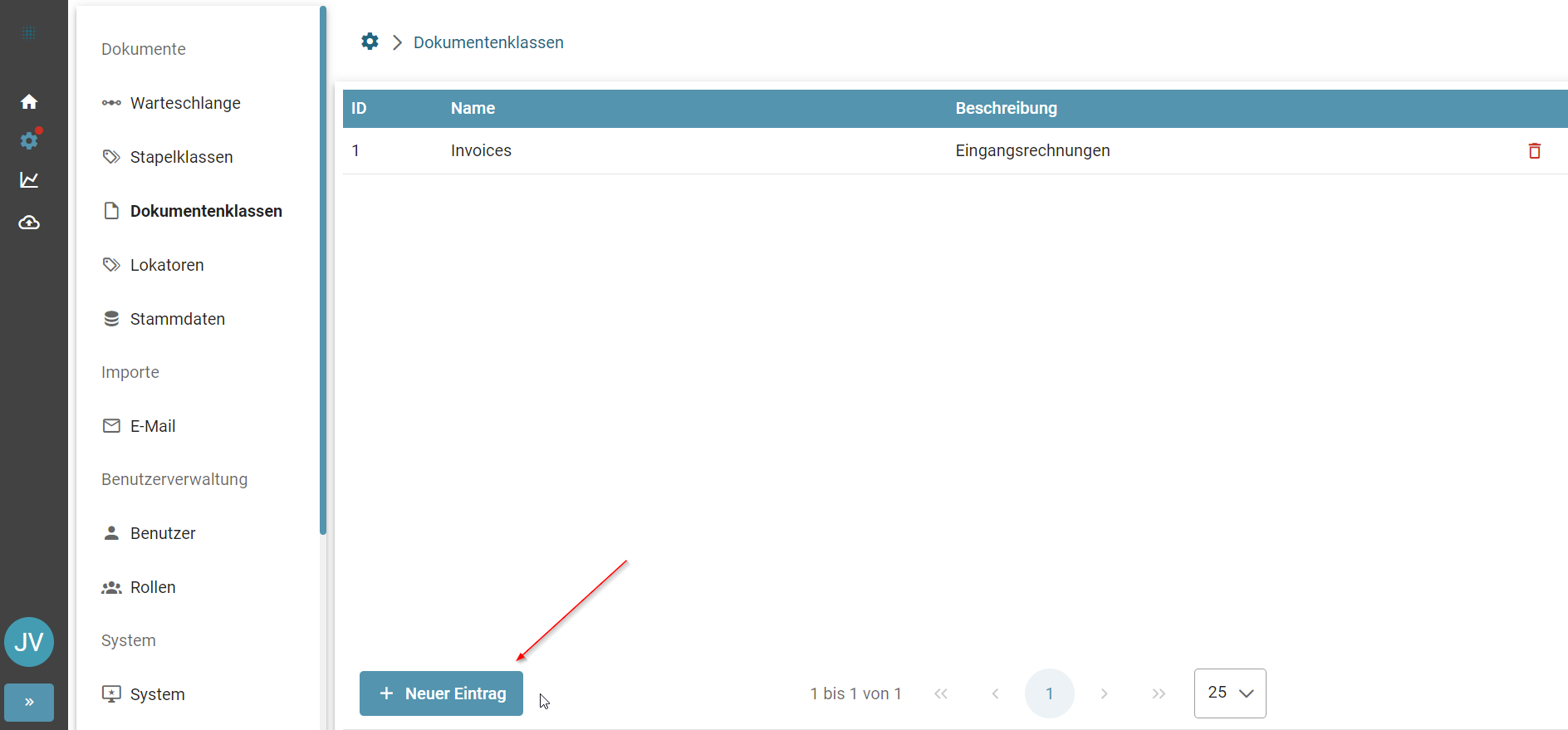
Mit dem + Symbol können neuen Dokumentenklassen angelegt werden. Hier wird der technische Name und die Beschreibung der Dokumentenklasse gefüllt.
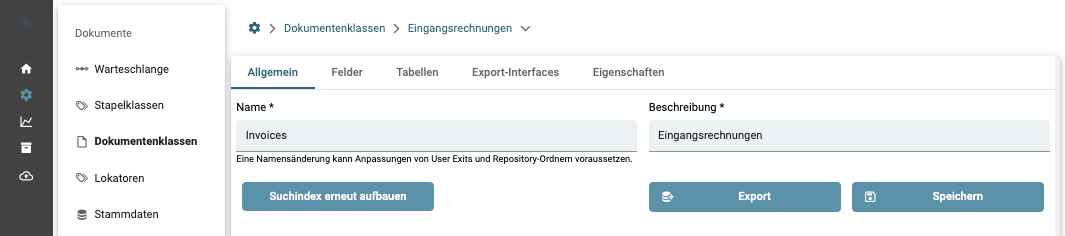
Mit einem Klick auf den Eintrag in der Liste öffnet sich der Konfigurationsdialog für die Dokumentenklasse.
Dokumenten- und Tabellenfelder
Allgemeines
Dokumentenfelder werden in Squeeze für unterschiedliche Funktionen benötigt:
- Informationen aus der Extraktion aufnehmen
- Für die Dokumentensuche indiziert werden
- Informationen aus der Extraktion im Validierungsclient darstellen
- Validierte Extraktionsergebnisse in den Exportschnittstellen bereitstellen
Felder und Tabellen sind als Teil einer Dokumentenklasse zu konfigurieren:
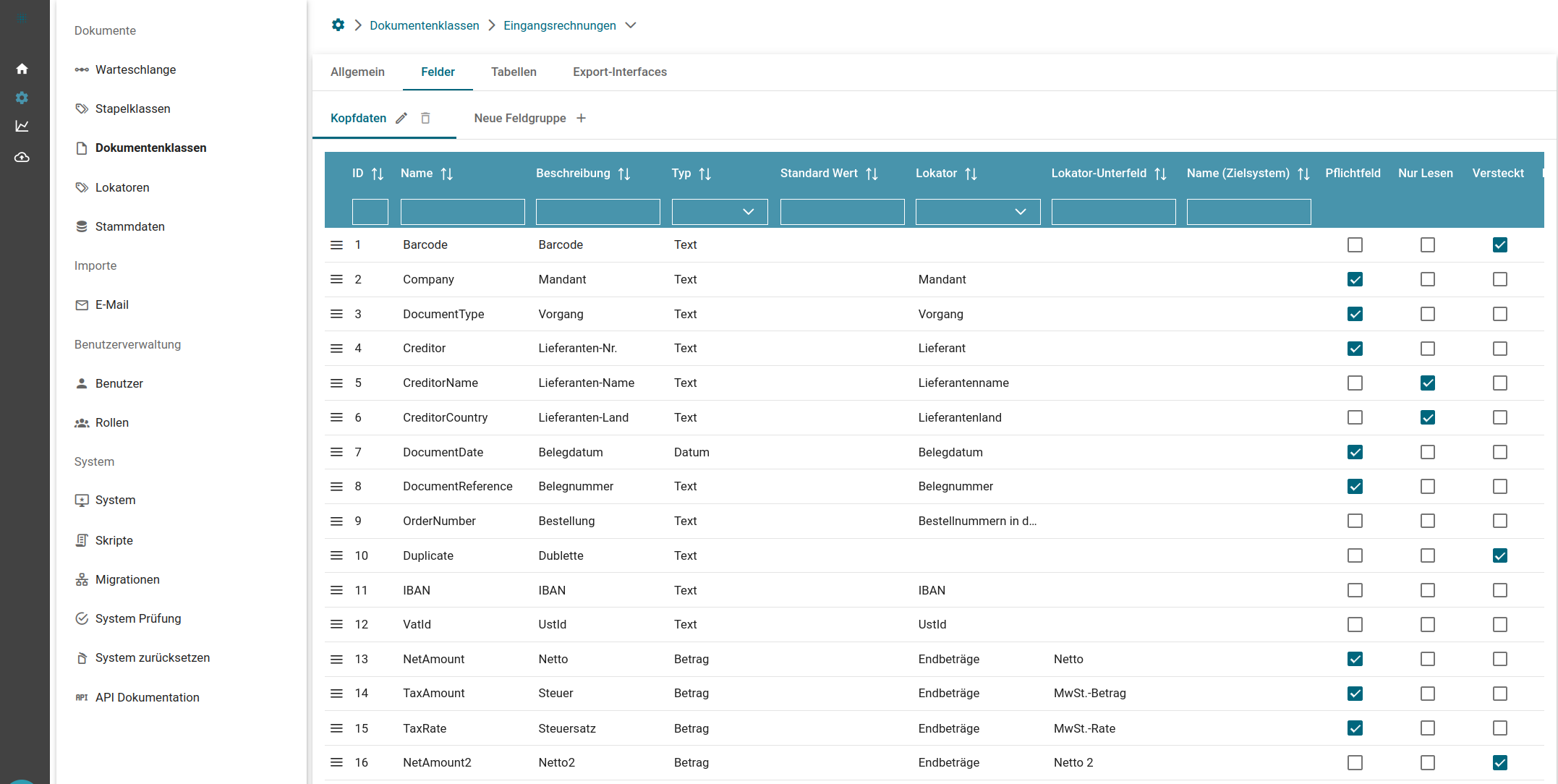
Validierungsspezifische Eigenschaften
Diese Einstellungen steuern, wie sich ein Feld in der Validierung verhält.
| Feld-Eigenschaft | Bedeutung |
| Pflichtfeld | leere Felder werden im Webclient rot dargestellt, die Validierung ist nicht möglich solange das Feld nicht gefüllt ist |
| Nur Lesen | Im Webclient kann das Feld nicht bearbeitet werden, Lokatoren können das Feld im Hintergrund füllen |
| Versteckt | das Feld wird im Webclient nicht dargestellt |
| Bestätigen | das Feld wird im Webclient blau dargestellt und muss vor der Validierung mit Enter bestätigt werden |
Tabellenfelder (kurz "Tabellen")
Für Tabellenfelder, in der UI nur als "Tabellen" bezeichnet, gelten die selben Kriterien, die auch für Dokumentenfelder gelten. Mit einer Ausnahme:
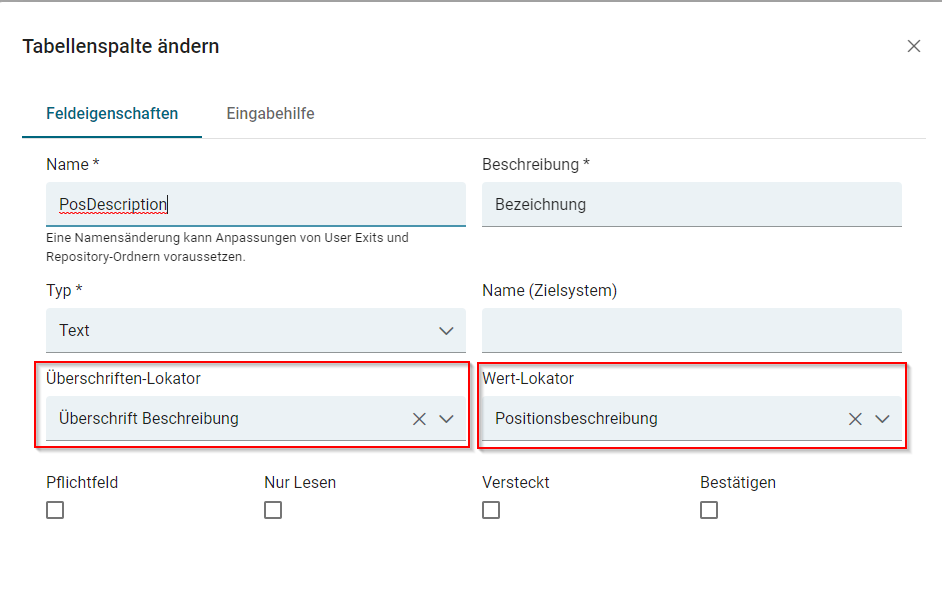
Für die Tabellenfelder ist es wichtig, dass sowohl ein Überschrift- als auch ein Wert-Lokator definiert werden. Mit Hilfe des Überschrift-Lokators wird die Spalte definiert in der per Wert-Lokator, wie im oberen Beispiel, der zu suchende Wert pro Zeile ausgelesen wird.
Eingabehilfen
Konfiguration
Eingabehilfen auf Feldern oder Tabellenspalten untersützen Validierer beim Auswählen von vordefinierten Werten auf Basis von Stammdatentabellen.
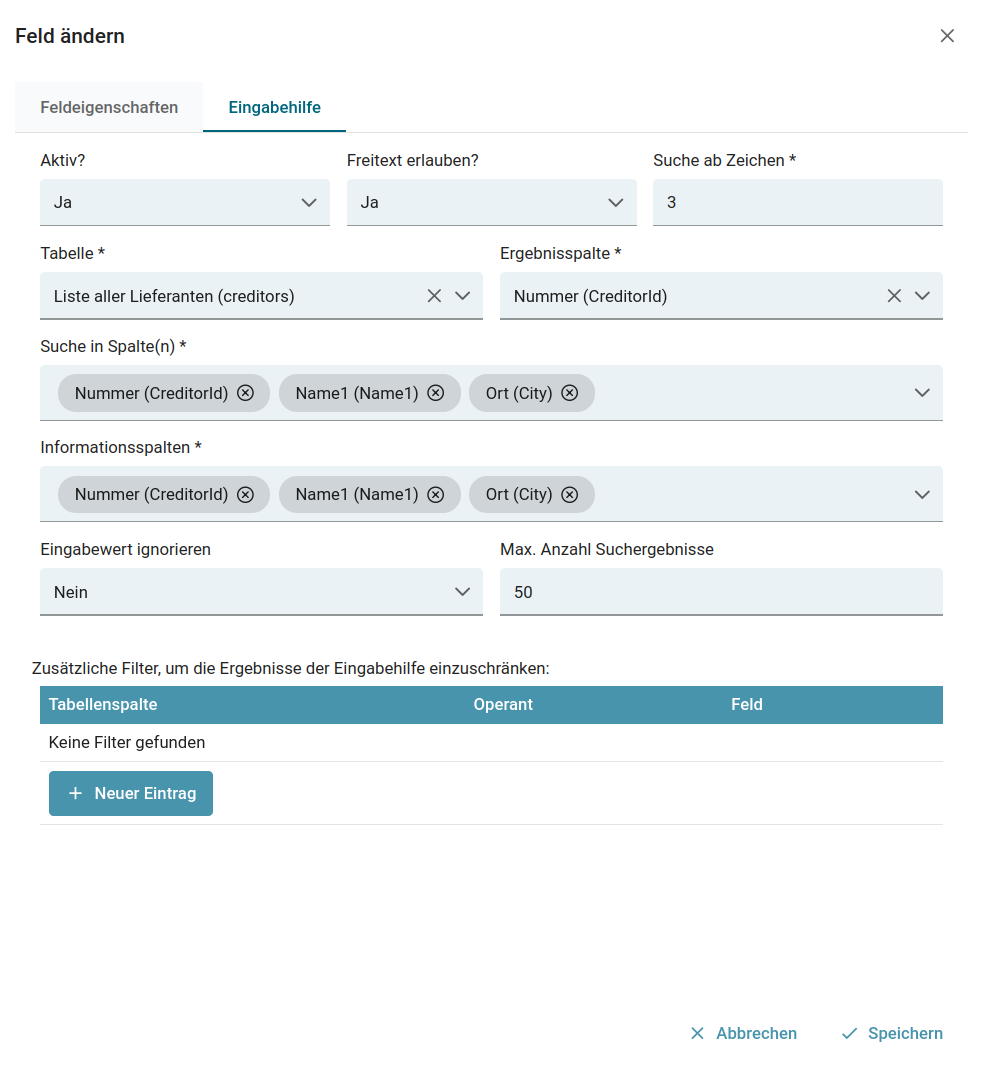
| Feld-Konfiguration | Bedeutung |
| Aktiv? | Hier kann ausgewählt werden, ob die Eingabehilfe aktiviert oder deaktiviert werden soll |
| Freitext erlauben? | Wenn Freitext erlauben aktiviert ist, dann können auch Werte in dem Feld eingetragen werden, die nicht in der Datenbank stehen. |
| Suche ab Zeichen | Hier kann eingetragen werden, ab welcher Anzahl an Zeichen gesucht werden soll. |
| Tabelle | Hier kann ausgewählt werden, welche Stammdatentabelle als Grundlage für eine Suche dienen soll. |
| Ergebnisspalte | Hier kann angegeben werden, aus welcher Spalte der Stammdatentabelle das Ergebnis ausgegeben werden soll. |
| Suche in Spalte(n) | Hier wird angegeben in welchen Datenbankspalten der eingegebene Wert gesucht werden soll. |
| Informationsspalten | Sollten ein oder mehrere Treffer gefunden werden, wird hier angegeben welche Spalteninformationen zur Anzeige der Treffer verwendet werden sollen. |
| Eingabewert ignorieren | Falls aktiv, wird bei der Eingabehilfe der aktuelle Feldwert ignoriert. Das führt dazu, dass mehr Ergebnisse angezeigt werden. |
| Max. Anzahl Suchergebnisse | Steuert, wie viele Ergebnisse gesucht und angezeigt werden sollen. |
| Zusätzliche Filter, um die Ergebnisse der Eingabehilfe einzuschränken | s. unten |
Die Ergebnisse der Eingabehilfe können mit weiteren zur Verfügung stehenden Kopffeldern gefiltert werden. Filter anlegen.:
| Tabellenspalte | Hier wird die Tabellenspalte angegeben, mit der der Feldwert verglichen werden soll. |
| Operant | Hier wird der Operator angegeben mit dessen Hilfe der Datenbankwert und Feldwert verglichen werden sollen. |
| Feld | Hier wird das Fed ausgewählt in dem der Wert steht, der mit dem Datenbankwert verglichen werden soll. |
Verhalten
Die Eingabehilfe wird beeinflusst durch den aktuellen Feldwerte. Auch die Extraktions-Alternativen werden bei der Eingabehilfe berücksichtigt.
Die Dokumentation der Eingabehilfe ist noch nicht vollständig, da ihre Funktion aktiv erweitert wird. Wir bitten diese Dokumentation zukünftig erneut aufzusuchen und um Feedback.
- Wenn das Feld ein vor erkannten Wert durch die Extraktion erhalten (gilt auch für Alternativen) hat und das Feld aber durch den Nutzer geleert wurde um eine listen artige Selektion der Stammdaten-Werte zu erzeugen
- dann wird die Eingabehilfe dennoch durch den vor erkannten Wert gefiltert (auch wenn das Feld geleert wurde), das bedeutet das man nie ein anderes Ergebnis erhält bis man den ersten Buchstaben in das Feld eintippt.
Dokumentenklassen-Eigenschaften
Mit Dokumentenklasseneigenschaften lassen sich allgemeine Konfigurationen pflegen, welche sich auf die Verarbeitung der Dokumente auswirken, die zu der jeweiligen Dokumentenklasseneigenschaft gehören.
Eigenschaften
Siehe Auflistung der Eigenschaften unter Stapelklassen-Eigenschaften
Die Dokumentenklasseneigenschaften werden höher priorisiert als die Stapelklasseneigenschaften. Demnach überschreiben die Dokumentenklasseneigenschaften die Stapelklasseneigenschaften.
Dokumentenklassen - Löschgründe
E-Mail-Import
Anleitungen zur Konfiguration von Mail-Importen und der Integration mit anderen Features.
Allgemeine Konfiguration
Je Stapelklasse ist es möglich 1-n Emailkonten zu konfigurieren, um Emails automatisiert aus den konfigurierten Postfächern abzurufen und die angehängten Dokumente zu verarbeiten.
Es werden drei Verfahren unterstützt, um Emails aus den Postfächern abzuholen.
- Abruf via EWS (Exchange Web Services)
- Abruf via IMAP (Internet Message Access Protocol)
- Abruf via Microsoft Graph API (Graph API mit OAuth2.0)
Allgemeine Konfiguration
Über Importe -> E-Mail gelangen Sie zur Übersicht der Email-Konten. Über das Feld Stapelklasse kann die Stapelklasse ausgewählt werden für die ein neues Email-Konto eingerichtet werden soll. Über "+ Neuer Eintrag kann nun ein neues Konto angelegt werden.
Das Password ist nach dem Speichern nicht mehr einsehbar.
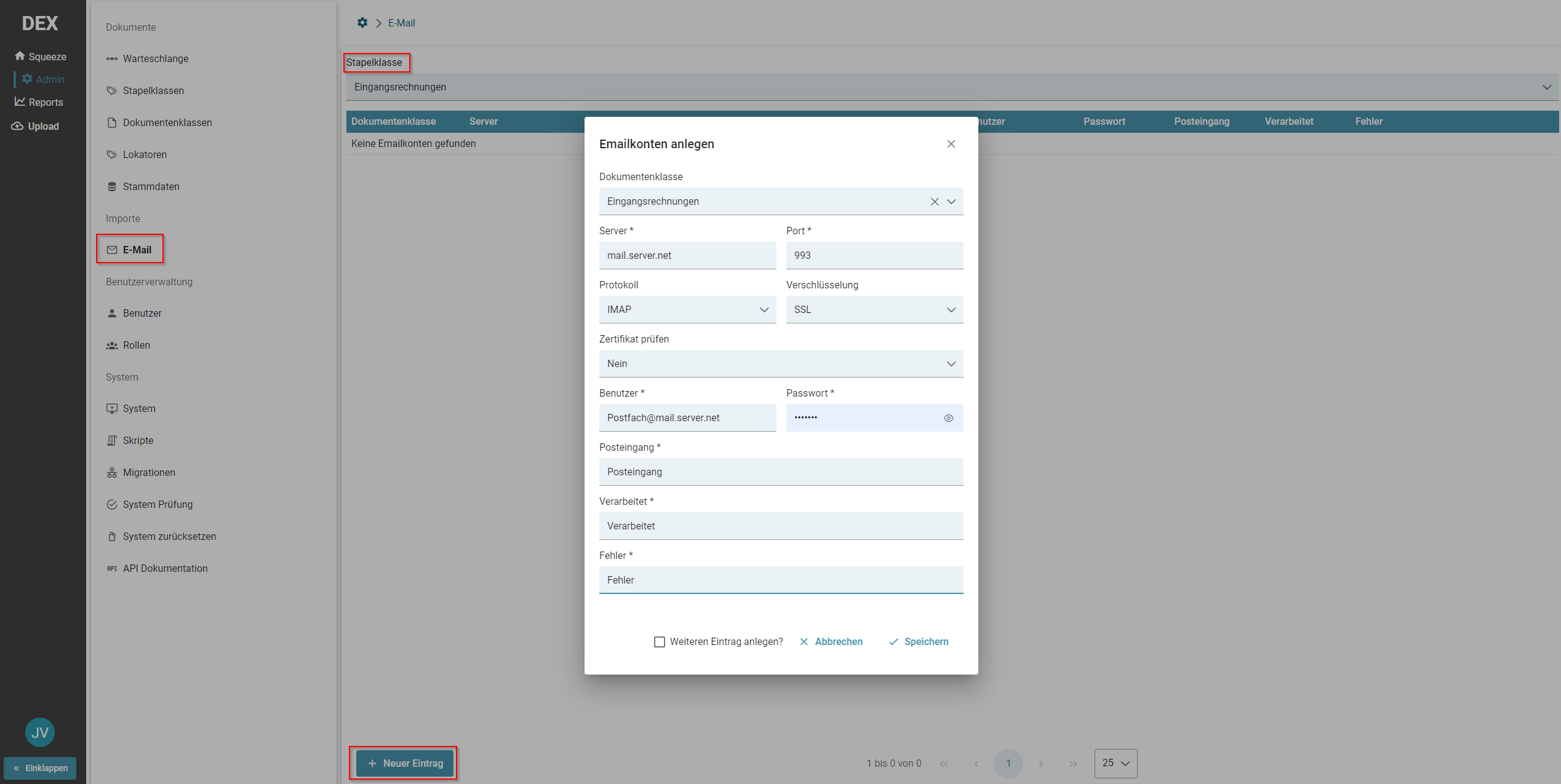
Ordner konfigurieren
Die drei Ordner "Posteingang", "Verarbeitet" und "Fehler" sind die Postfach-Ordner, mit welchen SQUEEZE interagiert.
Warnung: Diese Ordner müssen sich auf oberster Ebene des Postfachs befinden. Das Abgreifen von Unterordnern (welches vereinzelt bei Kunden im Einsatz war/ist) ist eine Projektlösung. Bei Updates bitten wir das zu berücksichtigen und darum, die Ordner entsprechend zu verschieben.
Shared Mailboxes abfragen
Besonderheit EWS / Graph API
Wenn Sie mit einem Benutzer auf ein geteiltes Postfach zuzugreifen, tragen sie im Feld Benutzer zuerst den User ein, mit dem sie zugreifen und danach den Benutzer des geteilten Postfachs, getrennt durch /:
Beispiel: benutzername@domain.de/shared-benutzername@domain.de
Beispiel mit NTLM Anmeldung: local.domain.net\benutzername/mailbox@domain.de
Verbindung Testen


Mit einem Klick auf dieses Symbol kann die Mail-Verbindung getestet werden.
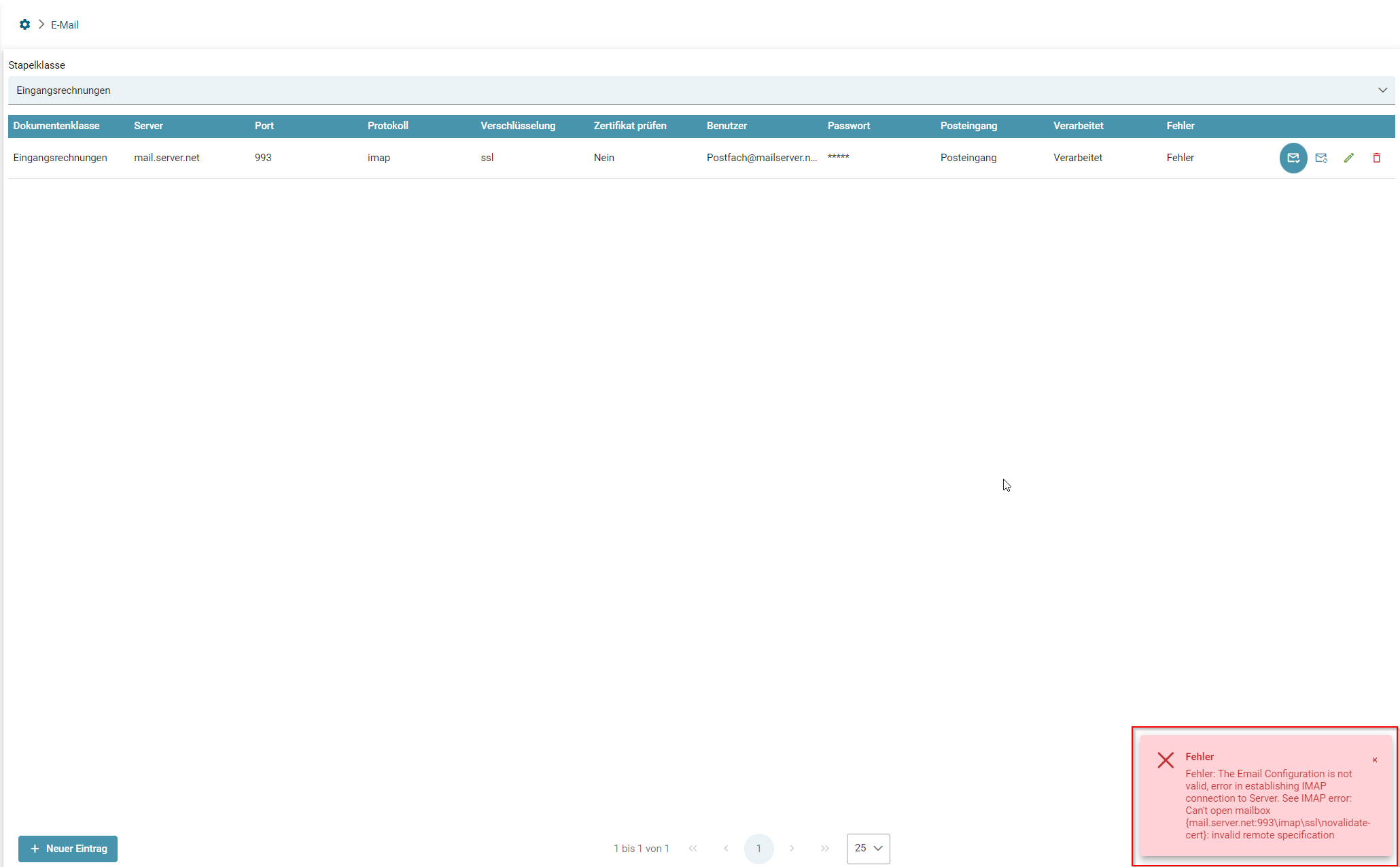
Sollte es zu einem Problem bei der Verbindung gekommen sein, wird in der linken unteren Ecke eine Fehlermeldung angezeigt in der der Fehler beschrieben wird.

Mit einem Klick auf dieses Symbol wird der Email-Abruf getriggert.
Provider - EWS
Im Oktober 2022 wird durch Microsoft die Authentifizierung mittels Basic-Auth bei Exchange Online flächendeckend abgeschaltet. Für die Anbindung von Exchange Online Postfächern empfehlen wir die Verwendung der Graph API.
Die BasicAuth für die Exchange Web Services wird im Oktober 2022 abgeschaltet. Wenn der zu einrichtende Dienst nur noch OAuth2.0 mit Verbindung zur Microsoft Graph API unterstütz dann siehe Abschnitt Besonderheit Microsoft Graph API. Um zu prüfen, ob die BasicAuth für ein System noch verfügbar ist, kann die folgende URL (ggf. Server durch den eigenen Exchange Server ersetzen) genutzt werden:
https://outlook.office365.com/EWS/Exchange.asmxNach dem Aufruf dieser URL erscheint ein Dialog zur Eingabe des Benutzernamens und des Passworts.
Sofern diese Anmeldung erfolgreich ist und eine entsprechende Webseite angezeigt wird, ist BasicAuth verfügbar.
EWS Verbindungstest
Im Falle einer EWS Verbindung kann es hilfreich sein vorab einen Verbindungstest durchzuführen. Das gilt besonders dann, wenn es sich um einen eignen Exchange Server handelt. Der Verbindungstest kann mit der folgenden Seite durchgeführt werden:
https://testconnectivity.microsoft.com/tests/EwsTask/input
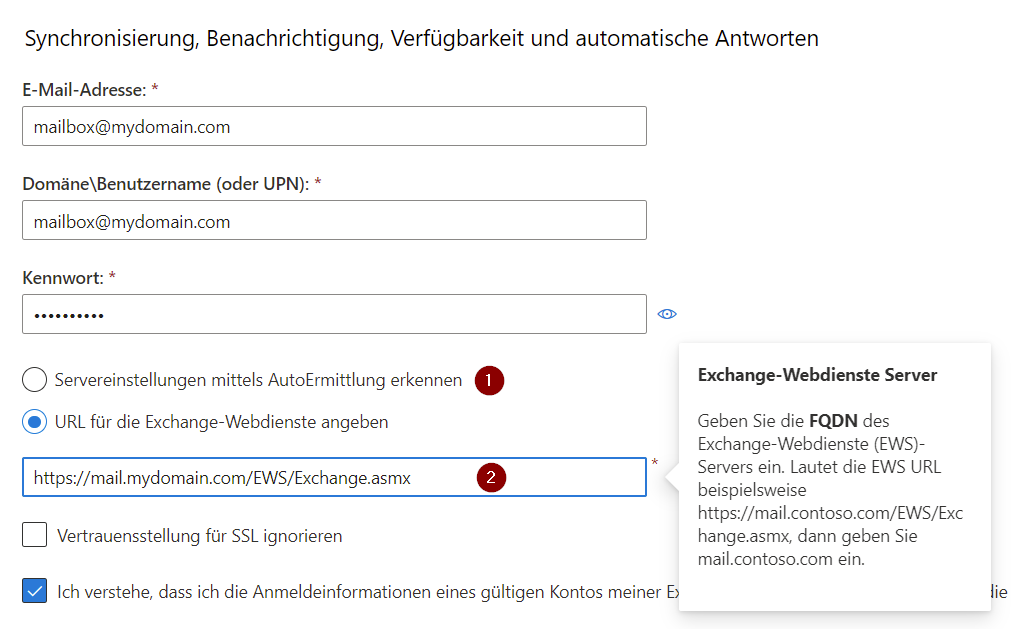
Sollte es sich um einen eignen Exchange Server handeln für den kein AutoDiscover eingerichtet ist, dann muss die EWS Adresse manuell angegeben werden (2).
Provider - Microsoft Graph API
Die Anmeldung durch Squeeze geschieht unter Verwendung von OAuth.
Microsoft unterstützt zwar mehrere OAuth-Flows, aktuell unterstützt Squeeze nur den Client Credential Flow und den Authentication Code Flow.
Diese unterscheiden sich darin, welche Permissions Squeeze erhält.
Die Graph API wird seit Squeeze 2.1 unterstützt.
Authentication Code Flow
(Microsoft delegated)
Client Credentials Flow
(Microsoft application)
Verarbeitung von Anlagen
Diese Dokumentation beschreibt, wie Anlagen ("Attachments") bei Mail-Importen gehandhabt werden. Das dokumentierte Verhalten ist unabhängig vom verwendeten Mail-Protokoll, es spielt also keine Rolle, ob Mails mittels IMAP, EWS, usw. importiert werden sollen.
Anlagen mit Passwörtern
Im täglichen Geschäft können über die digitalen Eingangskanäle ihres Unternehmens, eine Vielzahl von verschlüsselten Anlagen erreichen. In folgenden Abschnitt gehen wir auf die zur Verfügung stehenden Möglichkeiten in Squeeze ein.
Komprimierte Archive(.zip)
Erhalten Sie verschlüsselte ZIP-Archive von ihren Absendern so bietet Squeeze Ihnen ab der Version >=2.4.1 eine Möglichkeit Passwörter für die eindeutigen Email-Adressen zu hinterlegen.
Für die Konfiguration müssen Sie als Admin die Email-Registerkarte öffnen:
im nächsten Schritt gibt es nun eine weitere Registerkarte innerhalb der Email-Konfigurationsoberfläche. Dort können sie die Registerkarte Passwörter auswählen.
im Unteren Teil der Oberfläche finden Sie nun ein Button um ein neuen Eintrag hinzuzufügen.

Nun können Sie mit der Verwendung einer eindeutigen E-Mail und durch die Eingabe eines Passwort die Daten speichern.
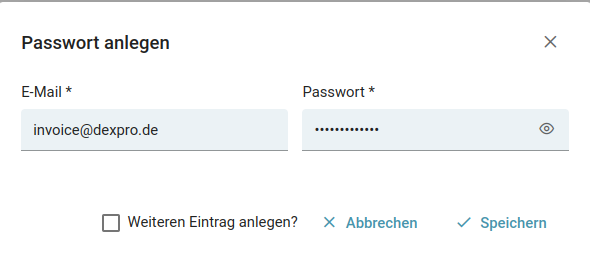
Achten Sie bitte auf folgende Hinweise in der Handhabung dieser Funktionalität:
- Sie müssen vollwertige E-Mails angeben, dass bedeutet Sie müssen immer ganze Email-Adressen angeben ansonsten schlägt der Speichervorgang fehl
- Um eventuell mehrere Passwörter einer E-Mail zuzuordnen legen Sie einfach mehrere Einträge an.
- Wenn Emails Anhänge enthalten die nicht entschlüsselt werden können, werden diese Emails in den spezifizierten Error E-Mail Ordner verschoben.
Die hinterlegten Passwörter werden nicht für passwortgeschützte PDF-Datein verwendet.
Eine eindeutige E-Mail Adresse ist zum Beispiel: dexpro@test.com und nicht Konstrukte wie: *pro@test.com
Anlagen-Filter
Funktionsweise
Für jede Mail werden die Anlagen auf Basis von Import-Regeln geprüft. Die erste Regel deren Sender und Dateimuster zu einem Anhang passen entscheidet was mit dem Anhang geschieht. Dabei erhalten die Regeln die am nicht global sind die höchste Priorität.
Beispiel:
| Prioritäten | Beispiel |
| Erste Priorität | spezifscher Sender(support@dexpro.de) + spezifisches Dateimuster(Rechnung.pdf) |
| Zweite Priorität | spezifische Domäne(dexpro.de) + unspezifisches Dateimuster (*.pdf) |
| usw. | - |
Wenn keine der Regeln passen, wird die Anlage ignoriert.
Für die Ausführung der PDF-Zusammenführung oder PDF-Trennung verwendet Squeeze die Software-Bibliothek "PDFBox". Die Verfügbarkeit der Bibliothek ist für die Anlagen-Filterung dringend notwendig. Ab der Squeeze Version 2.3.4 wird diese Bibliothek mit in die System-Prüfungen aufgenommen. Dies ermöglicht Ihnen eine schnelle Identifikation von möglichen Fehlerursachen.
Die Stammdatentabelle emailattachmentfilters wird verwendet um SQUEEZE mitzuteilen, ob und wie Anlagen für die Erkennung relevant sind.
Die Tabelle hat folgende Struktur:
| Name | Beschreibung | Bedeutung |
| id | ID | Eindeutige technische ID |
|
batchclassid |
Stapelklassen ID | ID der Stapelklasse für die die Regel definiert wird |
| sender | Sender | Absender der Email (Wildcards erlaubt) |
| filenamepattern | Dateimuster | Dateinamenfilter (Wildcards erlaubt) |
| type | Typ | Relevantes Dokument für die Extraktion oder begleitende Anlage |
| singledocument | Einzeldokument | Kennzeichen, ob die Datei ein eigenständiges Dokument werden soll (X) |
| newbatchclassid | Neue Stapelklassen ID | Sofern das Dokument in eine andere Stapelklasse verschoben werden soll, ist hier die Stapelklassen-ID der neuen Stapelklasse anzugeben. |
| newdocumentclassid | Neue Dokumentenklassen ID |
Sofern auch eine neue Dokumentenklasse gesetzt werden soll, ist hier die ID der Dokumentenklasse anzugeben. |
Beispiel-Konfigurationen
Beispiel
| ID | Stapel-klasse | Sender | Muster | Typ | Einzel-Dokument | neue Stapelklasse |
neue Dokumentenklasse |
| 1 | 1 | * | D | ||||
| 2 | 1 | * | AGB.pdf | A | |||
| 3 | 1 | dexpro.de | INV*.pdf | D | X | ||
| 4 | 1 | payment@dexpro.de | Avis*.pdf | D | X | 2 | 2 |
| 5 | 1 | dexpro.de | *.xml | A | |||
| 6 | 1 | invoice@squeeze.one | *.xml | D | |||
| 7 | 1 | invoice@squeeze.one | A |
Erklärung der Regeln
Regel ID 1:
Diese Regel bedeutet, dass für jeden Absender jedes PDF einer Email als Dokument für die Extraktion behandelt wird und alle PDFs zu einem Dokument zusammengefasst werden.
Regel ID 2:
Diese Regel bedeutet dass für jeden Absender die PDF mit dem Namen AGB.pdf als Anlage beibehalten wird.
Regel ID 3:
Diese Regel greift nur bei Absendern der Domain dexpro.de und bedeutet, dass PDFs die dem Dateinamenmuster INV*.pdf entsprechen als Dokument erhalten bleiben. Dabei gilt zusätzlich, dass jede Datei, die diesem Muster entspricht, zu einem eigenständigen Dokument werden.
Regel ID 4:
Diese Regel greift nur bei dem Absender payment@dexpro.de und bedeutet, dass PDFs die dem Dateinamenmuster Avis*.pdf entsprechen als Dokument erhalten bleiben. Dabei gilt zusätzlich, dass jede Datei, die diesem Muster entspricht, zu einem eigenständigen Dokument einer neuen Stapel- und Dokumentenklasse werden.
Regel ID 5:
Diese Regel greift nur bei Absendern der Domain dexpro.de und bedeutet, dass XML Dateien (bspw. eine XRechnungen) als Anlagen beibehalten werden. Dabei wird vorausgesetzt, dass es eine gültige PDF in der E-Mail gibt (z.B. aus Regel ID 3), die den Hauptvorgang bildet.
Regel ID 6 & 7:
Diese Regel greift nur bei dem Absender invoice@squeeze.one und bedeutet, dass XML Dateien (bspw. eine XRechnung) als Dokument erhalten bleibt. Alle zusätzlich angehangenen PDF-Dokumente werden als Anlagen weitergeführt.
Für die Steuerung der Verarbeitung von E-Mails, die sowohl XRechnungs-Dokumente als auch ZUGFeRD Belege enthalten,
können entsprechende Regeln definiert werden.
Update-Hinweis
Trennung von Anlagen und Dokument ab Squeeze 1.10
In den Squeeze 1.9 (und älter) wurden Dokumente und Anlagen beim Import zwar unterschiedlich behandelt, allerdings in den Folge-Schritten der Verarbeitung als eine Datei behandelt. Ergebniss war, dass primär zu verarbeitendes Dokument und die Anlagen als eine PDF zusammengeführt und dann auch so extrahiert wurden, als wäre eine einzelne Datei importiert worden.
Ab Squeeze 1.10 werden die Anlagen getrennt behandelt und sind somit nicht Teil des Dokumentes, welches extrahiert wird. Zusätzlich kann dies Export-Schnittstellen betreffen, die nur eine Datei pro Dokument exportieren können (Bspw. NavisionSoap). Diese exportieren in der neueren Version nur noch das Hauptdokument, Anlagen werden nicht exportiert.
Falls das Verhalten vor Squeeze 1.10 beibehalten werden soll, dann sind in den Anlagenfiltern alle Anlagen als Dokument zu markieren.
Priorisierung von XML-Rechnungen gegenüber PDF-Dateien ab Squeeze 2.17
Mit der Einführung der Version 2.17 wird das Standardverhalten von Squeeze dahingehend angepasst, dass Rechnungen im XML-Format gegenüber PDF-Dateien bevorzugt werden. Der Hintergrund dieser Änderung ist, dass zunehmend Kunden und Partner darauf hingewiesen haben, dass Rechnungssteller häufig sowohl Belege im XML- als auch im PDF-Format übermitteln. Je nach Konfiguration kann dies zu Dubletten oder Fehlern in der Verarbeitung führen.
Um eine einheitliche Handhabung der Belege im Standard zu gewährleisten, wird in der Version 2.17 festgelegt, dass Belege im XML-Format vorrangig behandelt werden. Dieses Verhalten kann jedoch durch die oben beschriebenen Regeln an individuelle Anforderungen angepasst werden. Eine generelle Priorisierung der PDF-Dateien ist derzeit nicht vorgesehen.
Verarbeitung unter Windows konfigurieren
Um regelmäßig auf neue Emails zu prüfen, muss eine geplante Aufgabe eingerichtet werden.
Unter Windows können dafür die geplanten Tasks genutzt werden.
Unter Linux erfolgt die Einrichtung mit Hilfe von cron Jobs.
Einrichtung unter Windows
Unter Windows kann ein geplanter Task zur Regelmäßigen Prüfung der konfigurierten Postfächer genutzt werden.
Um einen neuen Task einzurichten müssen folgende Schritte durchgeführt werden:
1. Aufgabenplanung öffnen
Es kann eine eigener Unterordner für Squeeze aufgaben erstellt werden, wenn dies gewünscht ist
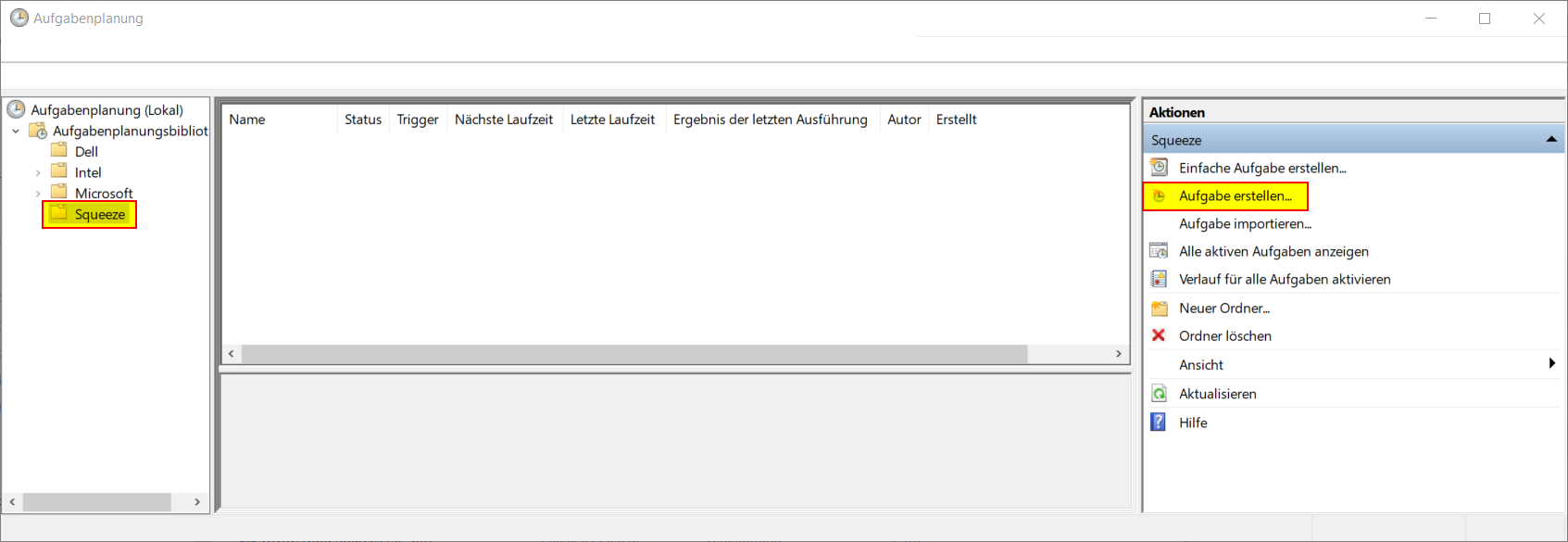
Auf der rechten Seite kann über den Menüpunkt "Aufgabe erstellen..." die Aufgabe für den Import der Emails angelegt werden.
2. Aufgabe erstellen
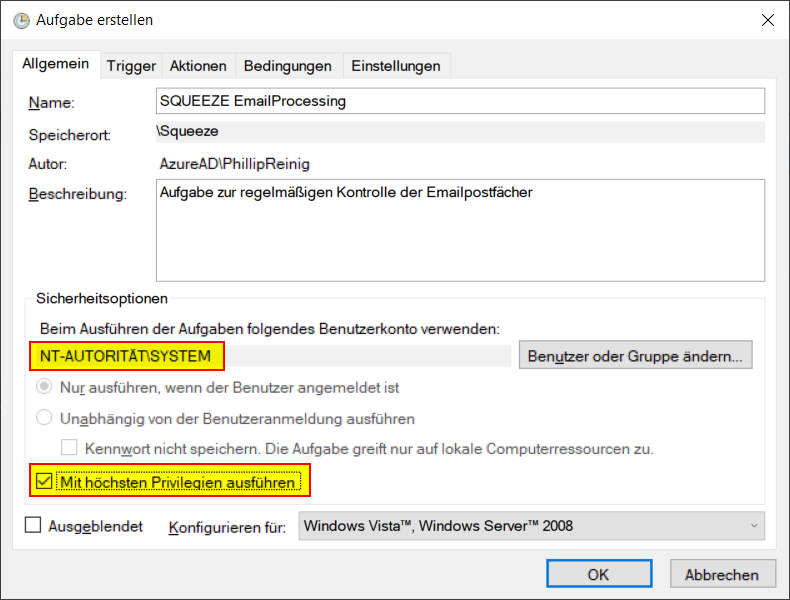
Der Name und die Beschreibung ist natürlich frei wählbar.
Damit die Aufgabe unabhängig von der Anmeldung eines Benutzers ausgeführt wird und auch unabhängig von eventuellen Passwortänderungen ist, hat sich bewährt, das System Konto auszuwählen.
Die Aufgabe "mit höchsten Privilegien" zu starten hat sich ebenfalls bewährt.
3. Trigger/Zeitpunkt festlegen
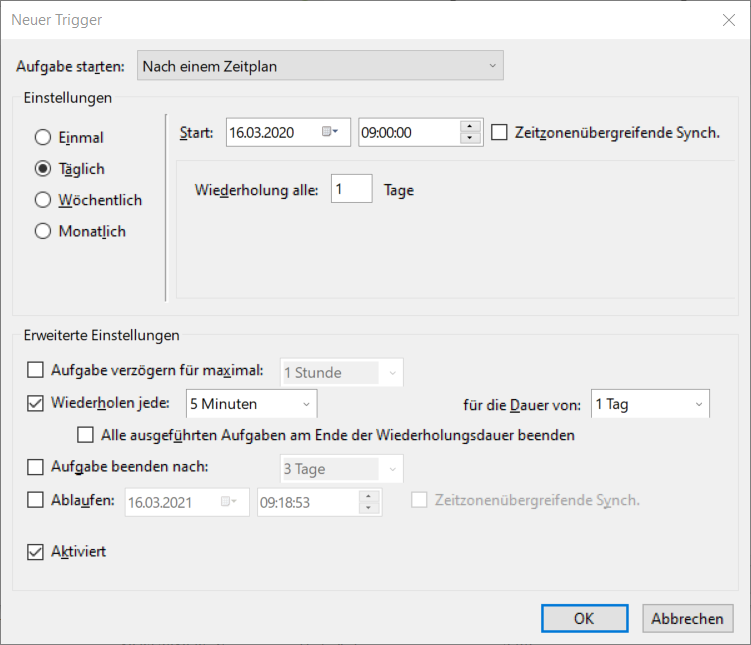
Das Intervall in dem die Emails abgerufen werden sollen ist ebenfalls frei definierbar.
Bewährt hat sich ein Intervall von 5 Minuten im Produktivsystem. Für Testsysteme kann dieser Intervall natürlich auch kleiner gewählt werden, wenn schnell und viel getestet werden soll.
4. Aktion festlegen
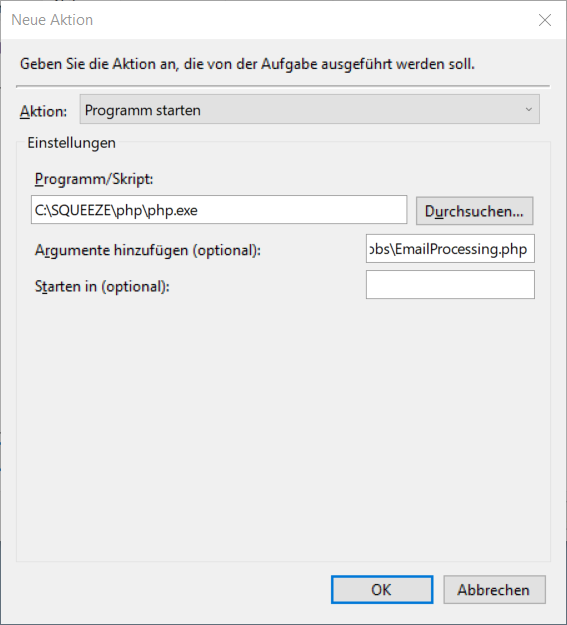
Als Programm muss die php.exe der Squeeze Installation ausgewählt werden.
Als Argumente müssen zwei Werte angegeben werden:
- - Pfad zur EmailProcessing.php z.B. C:\SQUEEZE\htdocs\jobs\EmailProcessing.php
- - Mandant für den die Emails abgerufen werden sollen z.B. client.squeeze.net
C:\SQUEEZE\htdocs\jobs\EmailProcessing.php client.squeeze.net
Filterung mittels Black- und Whitelisting
Whitelist und Blacklist sind nacheinander geschalten und stehen daher in Verbindung.
Bei aktiver Whitelist muss der Absender erst auf der Whitelist stehen, damit eine aktive Blacklist geprüft wird!
Validierung eintreffender E-Mails
Kurzgesagt (TLDR):
- Whitelist Prüfung: Absender der E-Mail wird mittels Whitelist geprüft.
- Blacklist Prüfung: Betreff der E-Mail des Absenders wird mittels Blacklist geprüft.
Fall 1 - Absender nicht auf der Whitelist
Ist eine Whitelist gepflegt und der Absender nicht auf dieser enthalten sein, dann wird der Betreff gar nicht erst geprüft und die E-Mail nicht importiert.
Fall 2 - Absender ist auf der Whitelist
Ist eine Whitelist gepflegt und der Absender ist auf dieser enthalten, dann wird anschließend der Betreff des Absenders per Blacklist geprüft.
Fall 2a - Absender Betreff ist nicht auf der Blacklist
Ist der Betreff nicht auf der Blacklist, so wird die E-Mail anschließend importiert.
Fall 2b - Absender Betreff ist auf der Blacklist
Ist der Betreff "blacklisted", dann wird die E-Mail nicht importiert.
Whitelisting
Im folgenden Abschnitt wird die Einrichtung der Whitelist beschrieben.
Eine aktive Blacklist wird nach der Whitelist-Prüfung ausgeführt.
Steht der Betreff des Absenders in der Blacklist und gilt als gesperrt, wird die E-Mail nicht importiert, obwohl der Absender in der Whitelist steht!
Whitelist erstellen
Die Whitelist Tabelle emailsenderwhitelist ist unter den Stammdaten zu finden:
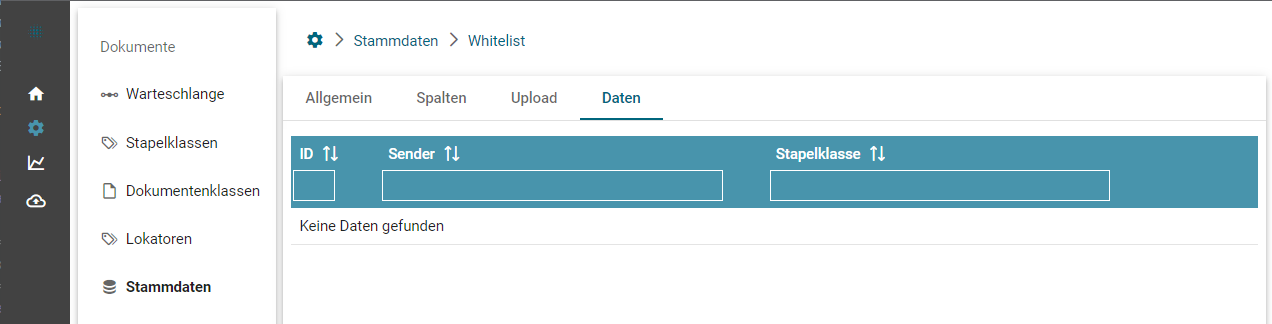
Unter der Spalte "Sender" können Absenderadressen (auch mit Wildcard *) eingetragen werden. Eine Stapelklasse ist notwendig.
Beispielsweise:
*@dexpro.defürhans@dexpro.deoderhanna@dexpro.desomeone@dexpro.*.defürsomeone@dexpro.beispiel.deodersomeone@dexpro.anderes.beispiel.dedepartment.*@dexpro.defürdepartment.vertrieb@dexpro.deoderdepartment.entwicklung@dexpro.de*@dexpro.*fürhans@dexpro.deoderhans.mustermann@dexpro.beispiel.de
Ungültige Einträge mit Sonderzeichen werden bei der Validierung der E-Mail nicht berücksichtigt - ungültige Einträge werden geloggt.
Whitelist aktivieren
Die Whitelist ist aktiv, sobald die Whitelist Tabelle existiert und mindestens ein Eintrag vorhanden ist. Wenn die Tabelle fehlt oder leer ist, ist die Whitelist Funktion inaktiv. Wenn die Whitelist inaktiv ist, wird direkt zur Blacklist-Prüfung gesprungen.
Voraussetzung ist außerdem die SQUEEZE Version 2.X.X
E-Mails von Absendern die nicht gelistet sind
E-Mails von nicht gelisteten Absenderadressen, werden nicht importiert. Dies wird geloggt.
Blacklisting
Im folgenden Abschnitt wird die Einrichtung der Blacklist beschrieben.
Eine aktive Whitelist wird vor der Blacklist-Prüfung ausgeführt. Steht der Absender nicht auf der Whitelist, wird die E-Mail bereits nicht importiert und entsprechend nicht weiter geprüft.
Blacklist erstellen
Die Blacklist Tabelle emailsubjectsblacklist ist unter den Stammdaten zu finden:
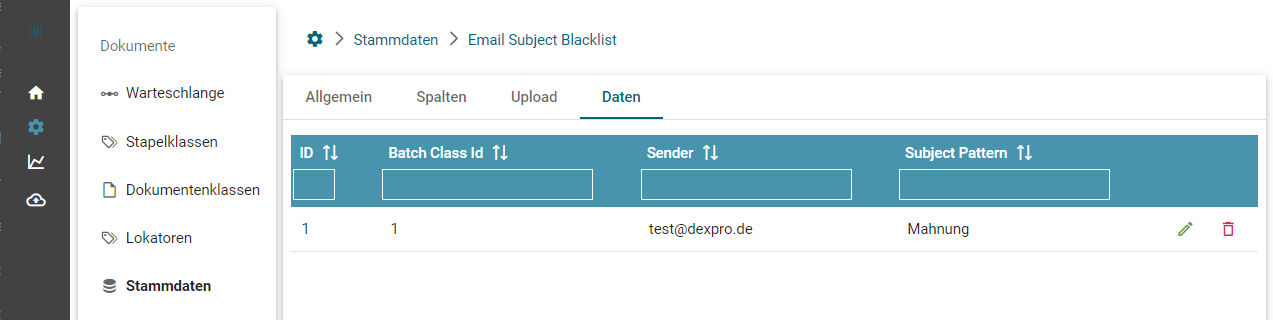
Unter der Spalte "Sender" können Absenderadressen eingetragen und unter der Spalte "Subject Pattern" der Wert im Betreff der E-Mail angegeben werden, welche nicht importiert werden sollen. Eine Stapelklasse ist notwendig.
Blacklist aktivieren
Die Blacklist ist aktiv, sobald die Blacklist Tabelle existiert und mindestens ein Eintrag vorhanden ist. Wenn die Tabelle fehlt oder leer ist, ist die Blacklist Funktion inaktiv.
Voraussetzung ist außerdem die SQUEEZE Version 1.X.X
E-Mails mit Betreffen von Absendern die gelistet sind
E-Mails von Absendern, deren Betreff als gesperrt (bzw. "blacklisted") eingetragen wurden, werden nicht importiert. Dies wird geloggt.
Leitfaden: Zugriff auf Exchange Online Postfächer einschränken
Dieser Leitfaden wurde bisher mit der Azure-Active-Directory-Cloud getestet.
Dieser Leitfaden bezieht ausschließlich auf die Verwendung der Microsoft Graph-API.
Welches Problem lösen wir ?
Wir verhindern, dass die Graph API zu viele Berechtigungen auf die Azure-Active-Directory Postfächer der verschiedenen Abteilungen erhält.
Was benötigen wir ?
Um diese Anforderung zu erfüllen benötigen wir folgende softwareseitig -Komponenten:
- Eine Powershell +7.0.0
- Azure-Active-Directory(AAD)
- das EXO-V2 Moduler Powershell 7 in der Version 2.0.4 oder höher.
Vorwort
Diese Dokumentation umfasst nicht die Einrichtung der Graph API für das Abholen der Emails durch Squeeze.
Die Anleitung der Einrichtung des Email-Import findest du hier.
Zudem dient dieser Artikel zur Unterstützung der Admins, die Informationen können sich im laufe der Zeit auf den referenzierten Beiträgen ändern.
Das ausführen der nachfolgenden Schritte muss unbedingt von einem Admin des AAD´s durchgeführt werden.
Was muss ich jetzt als nächstes tun ?
Um eine App in seinen Berechtigungen zu beschränken, bietet die Azure-Active-Directory das Anlegen von E-Mail-aktivierten Sicherheitsgruppen. Diese Sicherheitsgruppen können je nach Verwendung zum restriktiven Zugriff auf eine App genutzt werden. Desweiteren sind diese Gruppen in der AAD-Admin-Oberfläche im Standart nicht zu einer App hinzugefügt. Diese Einstellungen kann man nur durch die Verwendung durch die Powershell in Verbindung mit dem EXO-V2 Modul und eines Admin AAD Accounts tätigen.
Erstellen einer E-Mail aktivierten Sicherheitsgruppe
Wenn du bereits eine Sicherheitsgruppe erstellt hast springe zu: Verbinden der App mit der E-Mail Sicherheitsgruppe
Um eine E Mail Aktivierte Sicherheitsgruppe zu erstellen wollen wir erst einmal auf die Admin-Oberfläche des AAD´s. Dort klicken wir auf die drei angegebenen Punkte (s. Screenshot) :
 Im nachfolgenden sind diese weiteren dokumentierten Schritte auszuführen.
Im nachfolgenden sind diese weiteren dokumentierten Schritte auszuführen.
 Name und Beschreibung festlegen:
Name und Beschreibung festlegen:
 Wähle den Besitzer (Admin-Account):
Wähle den Besitzer (Admin-Account):
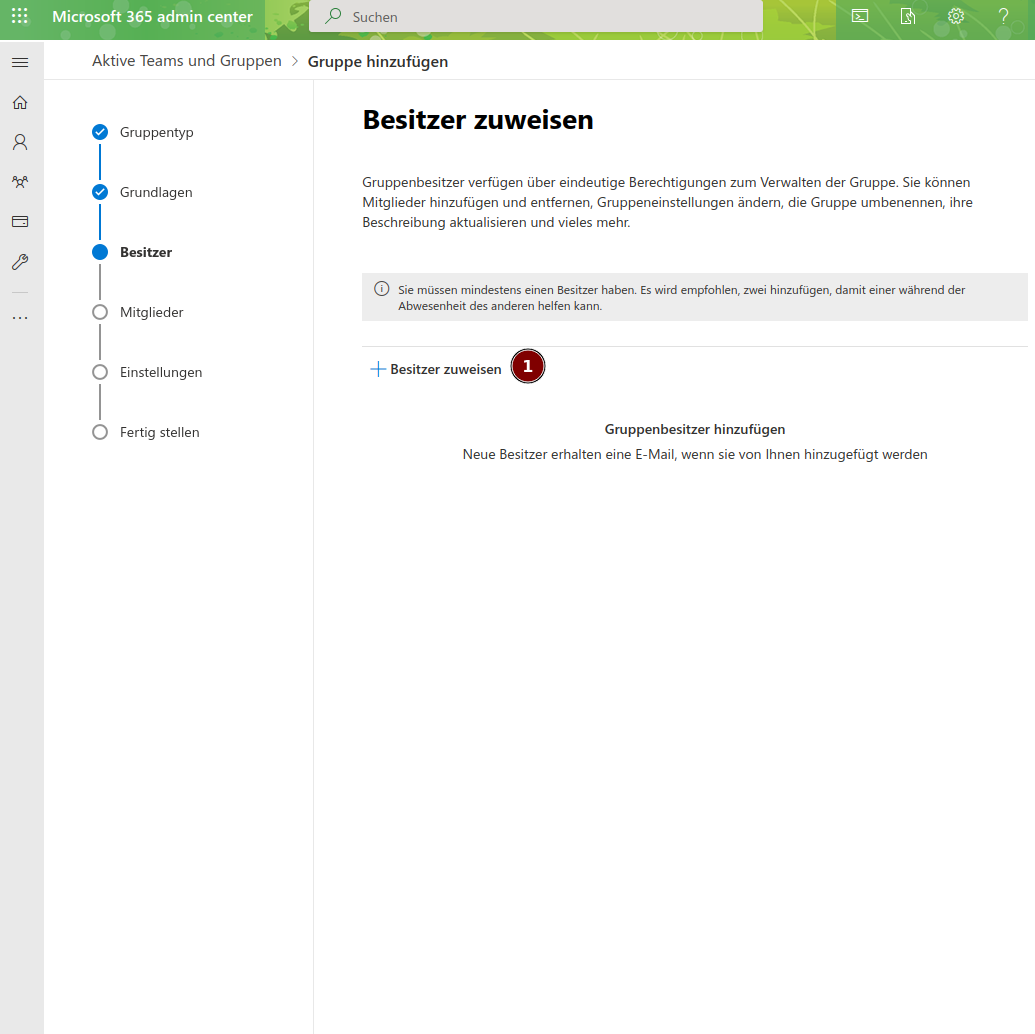 Wähle nun Mitglieder/Email-Accounts die auf die App durch diese Gruppe berechtigt werden soll:
Wähle nun Mitglieder/Email-Accounts die auf die App durch diese Gruppe berechtigt werden soll:
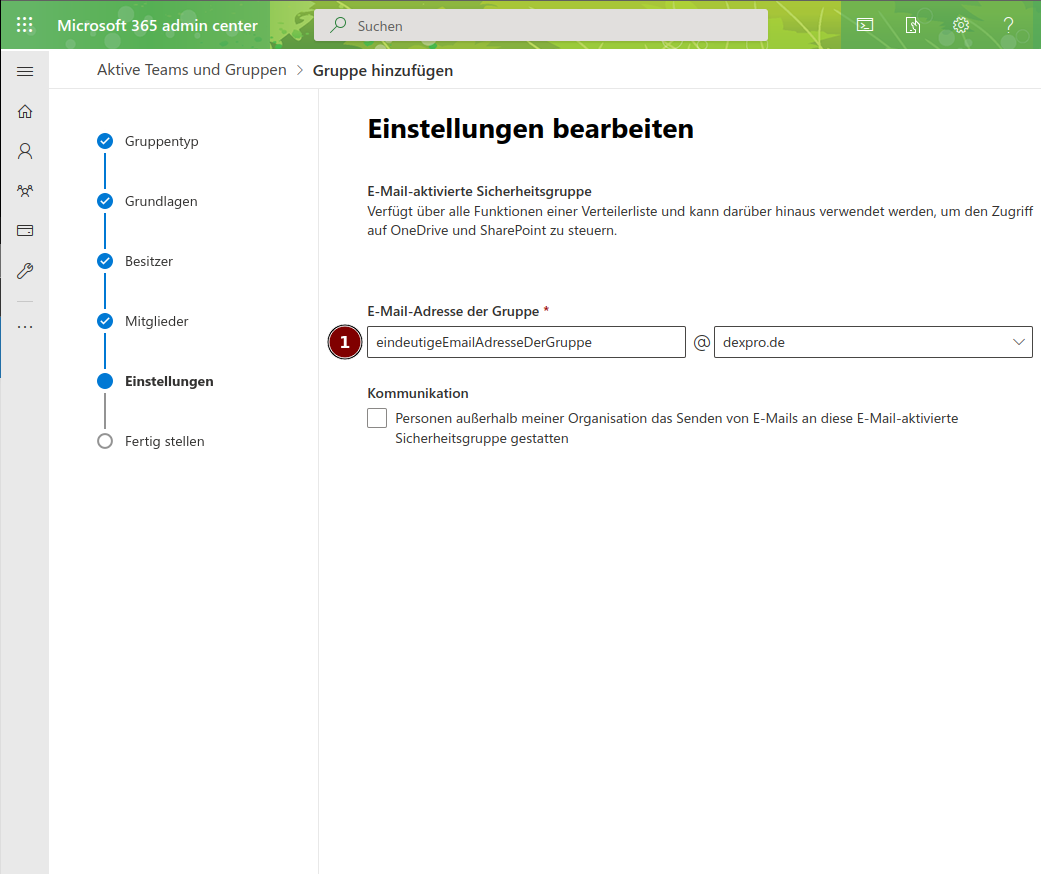
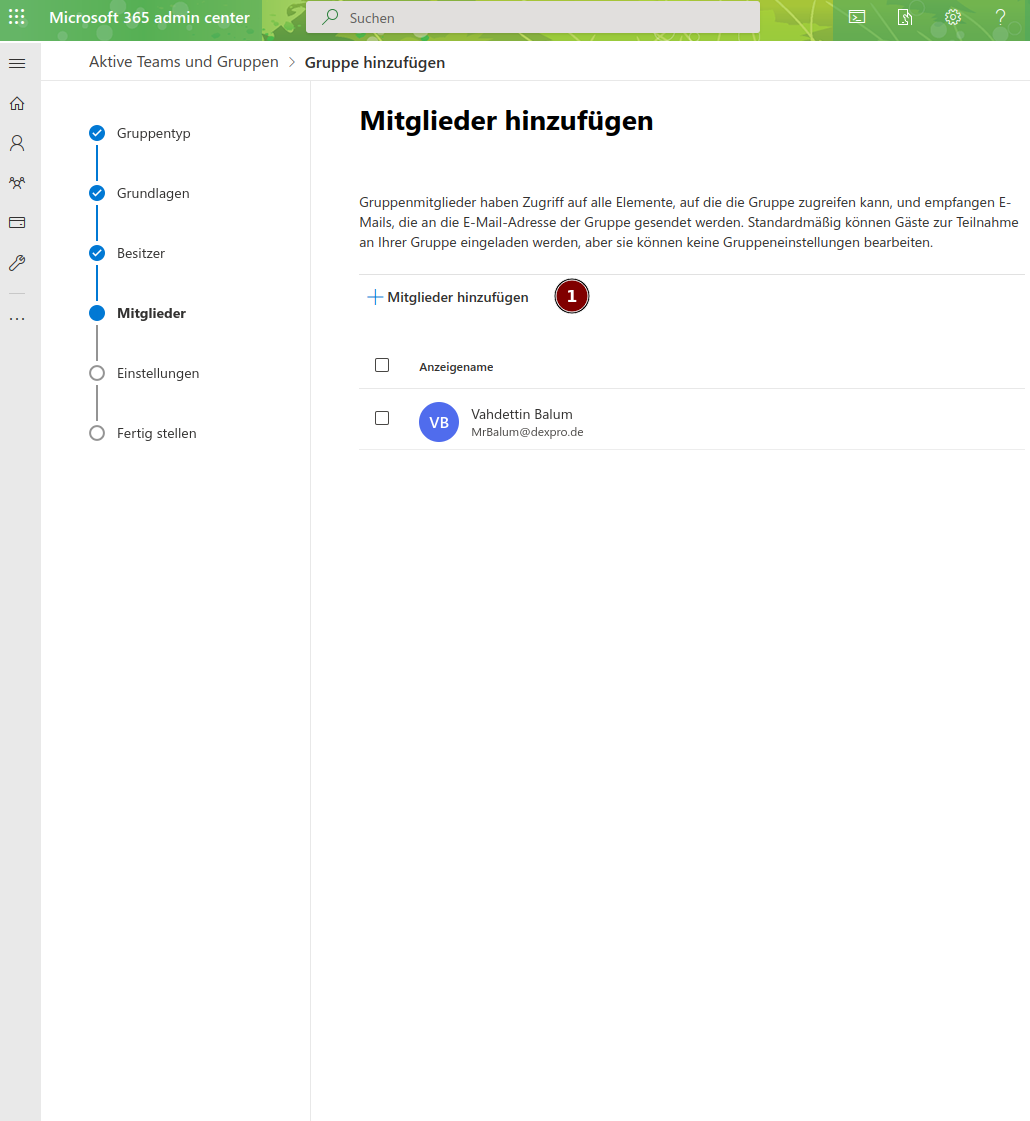 Nun vergeben wir der Gruppe eine eigene Email-Address:
Nun vergeben wir der Gruppe eine eigene Email-Address:
Die Gruppen-Email Adresse wird für später verwendet, daher sollte man sich diese Email ablegen.
Im letzen Fenster bestätigt ihr eure Einstellung und erstellt die Gruppe.
Verbinde Sicherheitsgruppe mit Application durch Powershell
Da wir nun eine E-Mail aktivierte Sicherheitsgruppe besitzen, müssen wir diese Gruppe der Application (die zuvor erstellt wurde) zuordnen. Aktuell haben wir nur die Möglichkeit über die Powershell in Verbindung mit EXO-V2 eine Gruppe, einer App hinzu zufügen.
Im ersten Schritt verbinden wir uns mit unserem AAD-Remote Cmdlet, dafür öffnen wir unsere Powershell als Administrator und geben folgenden Befehl ein. Für weitere Information...
Connect-ExchangeOnline -UserPrincipalName <admin@company.com>Nun sollte sich ein Pop-Up öffnen, dass einen durch die Authentifizierung bei Microsoft führt.
Unter manchen Linux oder MacOS Distributionen wird kein Pop-Up geöffnet.
Um das Problem zu lösen muss über den Device-Code Flow die Authentifizierung durchgeführt werden.
Der folgende Befehl muss für den Device-Code Flow ausgeführt werden:
Connect-ExchangeOnline -deviceNach der erfolgreichen Authentifizierung, erhält man alle Remote-Cmdlets des Exchange-Servers auf die man Berechtigungen hat. Um nun eine App-Berechtigungsgruppe einer App zu zuordnen muss folgender Befehl ausgeführt werden.
New-ApplicationAccessPolicy -AppId <Deine Application ID / Client ID> -PolicyScopeGroupId deineGruppenEmail@deineFirma.com -AccessRight RestrictAccess -Description "Restrict this app to members of distribution group ...."Ist der Befehl erfolgreich ausgeführt worden, dann kann mann seine Anpassungen mit diesem Befehl testen:
Test-ApplicationAccessPolicy -Identity deineGruppenEmail@deineFirma.com -AppId <deine Application ID / Client ID>Das Ergebnis des Befehls sollte so aussehen:
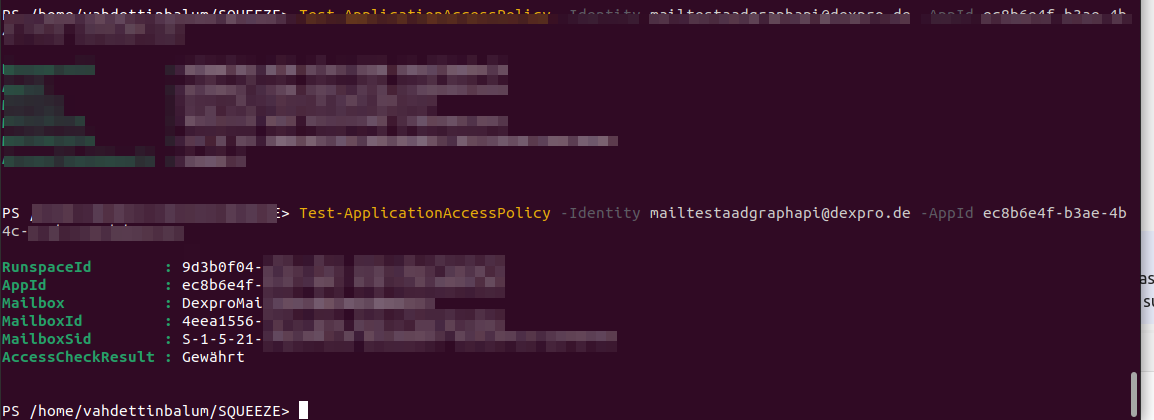
Nun solltest du die App auf die ausgewählten Nutzer der E-Mail aktivierten Sicherheitsgruppe beschränkt haben.
Bis die Änderungen im AAD greifen, kann es bis zu einer Stunde laut Microsoft dauern.
Konfiguration Client Credentials Flow (application) MS Graph API
Client Credential Flow Microsoft Graph API
Konfiguration in Squeeze
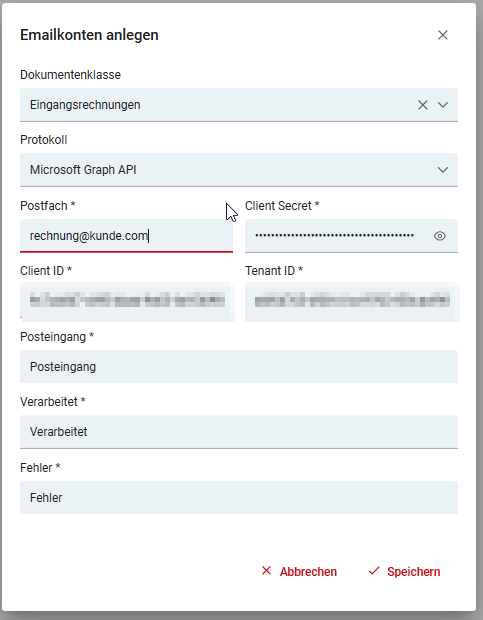
Bei den ersten Versionen dieses Features musste die Konfiguration mittels der Felder "Benutzername" und "Passwort" gepflegt werden. Wir empfehlen ein Update.
Erwarteter Wert im Feld Benutzername: maxMustermann@mustermann.de/{client_id}/{tenant_id}
Erwarteter Wert im Feld Passwort: {client_secret}
Ordner - Konfiguration
Bei der Ordnerkonfiguration müssen Sie drei Ordner angeben
- Posteingang
Dieser Ordner wird regelmäßig überprüft, um die enthaltenen Emails zu importieren. - Verarbeitet
In diesen Ordner werden die erfolgreich importieren Emails verschoben. - Fehler
In diesen Ordner werden, die Emails abgelegt, die nicht importiert werden konnten (z.B. fehlende Anlagen)

Bei der Definition der Ordner achten Sie bitte darauf, dass die Namen der Ordner eindeutig sein müssen, da die Ordner in der Verzeichnisstruktur des Postfachs gesucht werden.
Ist ein konfigurierter Ordner nicht eindeutig kann es dies dazu führen, dass ein anderer Ordner genutzt wird, als der gewünschte.
Konfiguration in Entra ID (vormals Azure Active Directory)
Weitere notwendige Schritte für ein reibungslosen Ablauf sind die Einrichtung einer Entra ID Application
mit einem Client Secret. Die Globale Registrierung eines Mail-Dienstes der "Dexpro" im Entra ID-Directory des Kunden, wird vorerst nicht angeboten.
Zudem muss darauf geachtet werden dass die Applikation folgende Scopes besitzt.
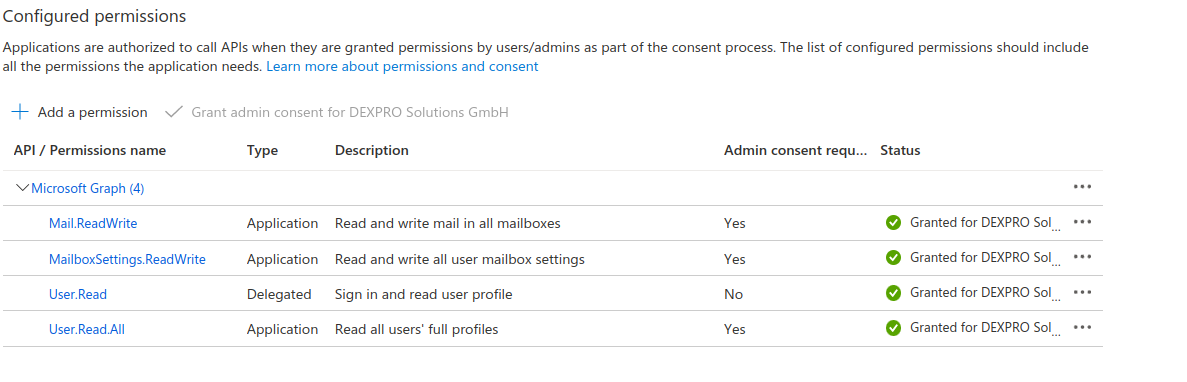
Im Standard hat diese Application nun Zugriff auf alle Postfächer.
Falls Sie diesen Zugriff auf einzelne Postfächer beschränken möchten, müssen zusätzliche Konfigurationen in Exchange Online, in Entra ID und mittels PowerShell getätigt werden.
In dieser Dokumentation von Microsoft wird beschrieben, wie Sie dies mittels Gruppenrichtlinien einrichten: Verwaltung der Gruppenrichtlinien in der Azure-AD
Wenn der Microsoft Artikel nicht ausreichend unterstützend ist, haben wir ein Leitfaden angefertigt der genauer beschrieben ist.
Konfiguration Authentication Code Flow (delegated) MS Graph API
Konfiguration in Squeeze
Diese Konfigurationsoberfläche wird ab der Version 2.3.0 bereitgestellt.
Wenn Sie diese Authentifizierungsmethode nutzen möchten, stellen Sie sicher, dass der Interne Job refresh-tokens aktiviert ist. Dies ist weiter unten im Artikel dokumentiert.
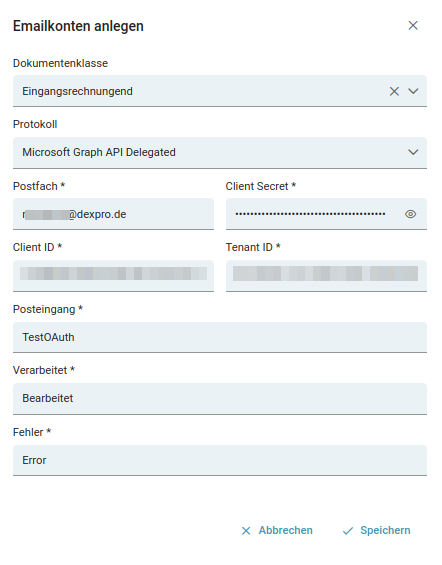
Wie man nun erkennt, kann man in der Konfigurations-Oberfläche unter Protokoll zwei Arten der Anbindung zu Microsoft(MS) Graph API wählen:
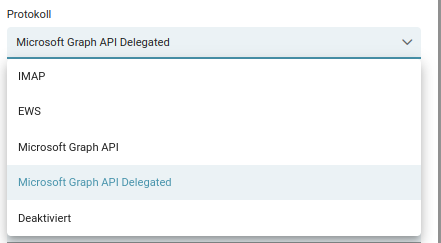
Für den delegierten Autorisierungsprozess wählen wir Microsoft Graph API Delegated. Im nächsten Schritt füllen wir die Felder Client ID, Client Secret die Tenant ID und die restlichen Felder.
Ordner - Konfiguration
Bei der Ordnerkonfiguration müssen Sie drei Ordner angeben
- Posteingang
Dieser Ordner wird regelmäßig überprüft, um die enthaltenen Emails zu importieren. - Verarbeitet
In diesen Ordner werden die erfolgreich importieren Emails verschoben. - Fehler
In diesen Ordner werden, die Emails abgelegt, die nicht importiert werden konnten (z.B. fehlende Anlagen)
Bei der Definition der Ordner achten Sie bitte darauf, dass die Namen der Ordner eindeutig sein müssen, da die Ordner in der Verzeichnisstruktur des Postfachs gesucht werden.
Ist ein konfigurierter Ordner nicht eindeutig kann es dies dazu führen, dass ein anderer Ordner genutzt wird, als der gewünschte.
Konfiguration in Entra ID (vormals Azure Active Directory)
Weitere notwendige Schritte für ein reibungslosen Ablauf sind die Einrichtung einer Entra ID Application
mit einem Client Secret. Die Globale Registrierung eines Mail-Dienstes der "Dexpro" im Entra ID-Directory des Kunden, wird vorerst nicht angeboten.
Zudem muss darauf geachtet werden dass die Applikation folgende Scopes besitzt.
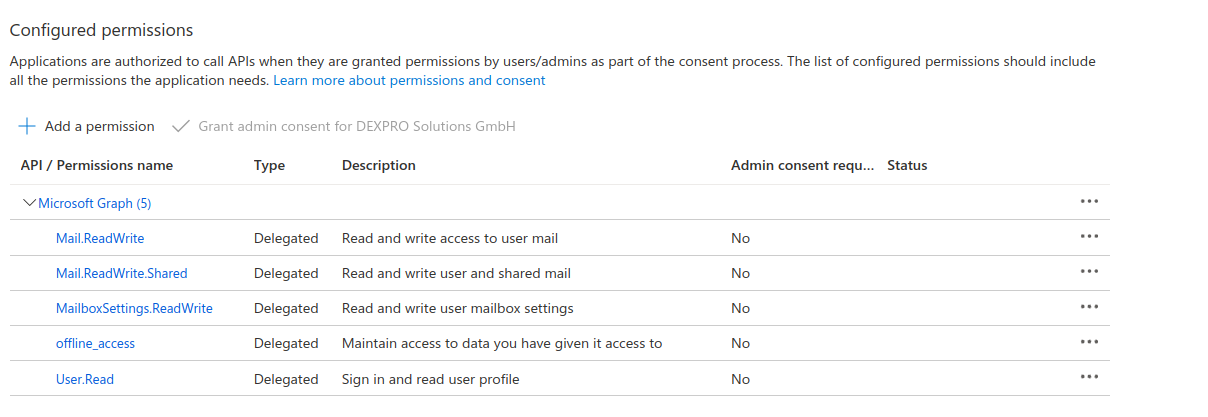
Anders als in den Permission für den Client Credential Flow ist jegliche Permission hier beschränkt auf den autorisierenden User.
Merke: Wenn auf ein Shared-Mailbox Postfach zugegriffen werden soll, muss das Shared-Mailbox Postfach unter Postfach eingetragen werden und die Application Permission Mail.Read.Write.Shared muss konfiguriert werden.
Denken Sie daran, dass die Shared-Mailbox auch Ihrer Email-Aktivierten Sicherheitsgruppe hinzugefügt wird, wenn Sie eine eingerichtet haben.
Ebenfalls ein maßgebender Unterschied zum Client Credential Flow ist hier die Verwendung einer Redirect URI.
Diese Redirect URI wird in der Entra ID unter der Applikation im Reiter Authentication angelegt:
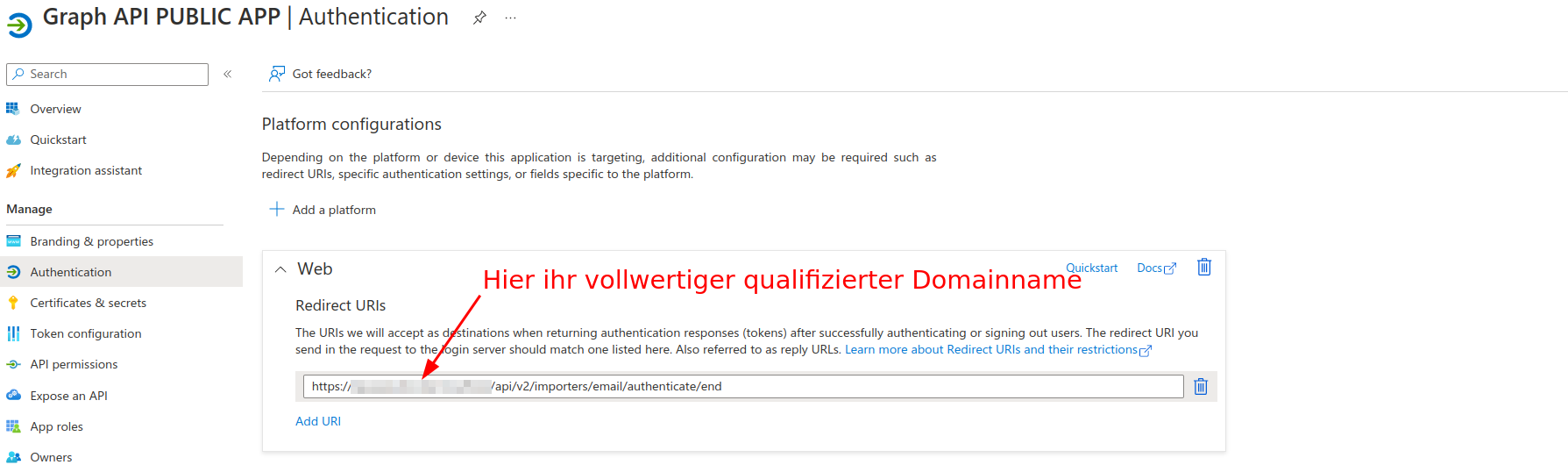
Schema Redirect URI: https://Ihr.vollwertiger.DomainName/api/v2/importers/email/authenticate/end
Merke: Ein Squeeze Mandant benötigt immer eine Entra ID Applikation mit einer Redirect URI.
Das bedeutet Sie müssen für jeden Mandanten eine Applikation anlegen.
Autorisierungsprozess Authentication Code Flow
hat man nun seine Application in Entra ID konfiguriert und alle notwendigen Daten in die Konfigurationsoberfläche getippt kann man nun seine Konfiguration abspeichern.
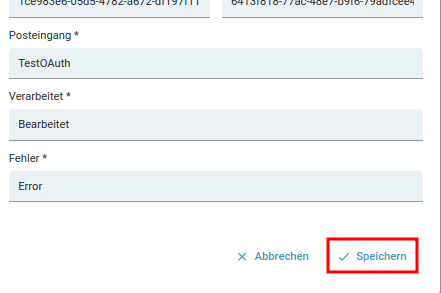
Nun öffnet sich ein weiteres Dialog Feld :

Das System hat Ihre Konfiguration gespeichert, den Prozess der Authentifizierung müssen Sie jedoch separat über einen Button in der Email Konfiguration starten. Hierfür wählen Sie bitte den folgenden Button:
Nach einem Klick auf diesen Button werden Sie nun zur Oberfläche von Microsoft weitergeleitet. Dort beginnt der Authentifizierungsprozess befolgen Sie die Anweisungen von Microsoft:
Geben Sie ihre Email-Adresse an.
Geben Sie Ihr Passwort ein:

Je nach Unternehmen werden Sie ebenfalls aufgefordert eine 2-Faktor-Authentifizierung durchzuführen.:
Sobald Sie Authentifiziert sind, werden die Berechtigungen abgefragt und Sie werden aufgefordert diese Berechtigungen zu bestätigen. Nach Ihrer Bestätigung leitet Microsoft umgehend zurück zur Squeeze-Oberfläche.
Die Oberfläche wird Ihnen nun anzeigen ob Squeeze nun Autorisiert ist oder ob ein Fehler aufgetreten ist:

Nun können Sie die Mail Verbindung testen Indem Sie den Mail Verbindungstest Button in der Oberfläche bedienen.
Job-Konfiguration
Die Verwendung dieses Authentifizierungsverfahrens erfordert, dass ein seperater Job aktiviert ist, welcher im Hintergrund die Zugriffsdaten für die Graph API aktuell hält.
Hierfür finden wir in der Administration unter "Skripte" das neue Skript mit den Namen refresh-tokens:
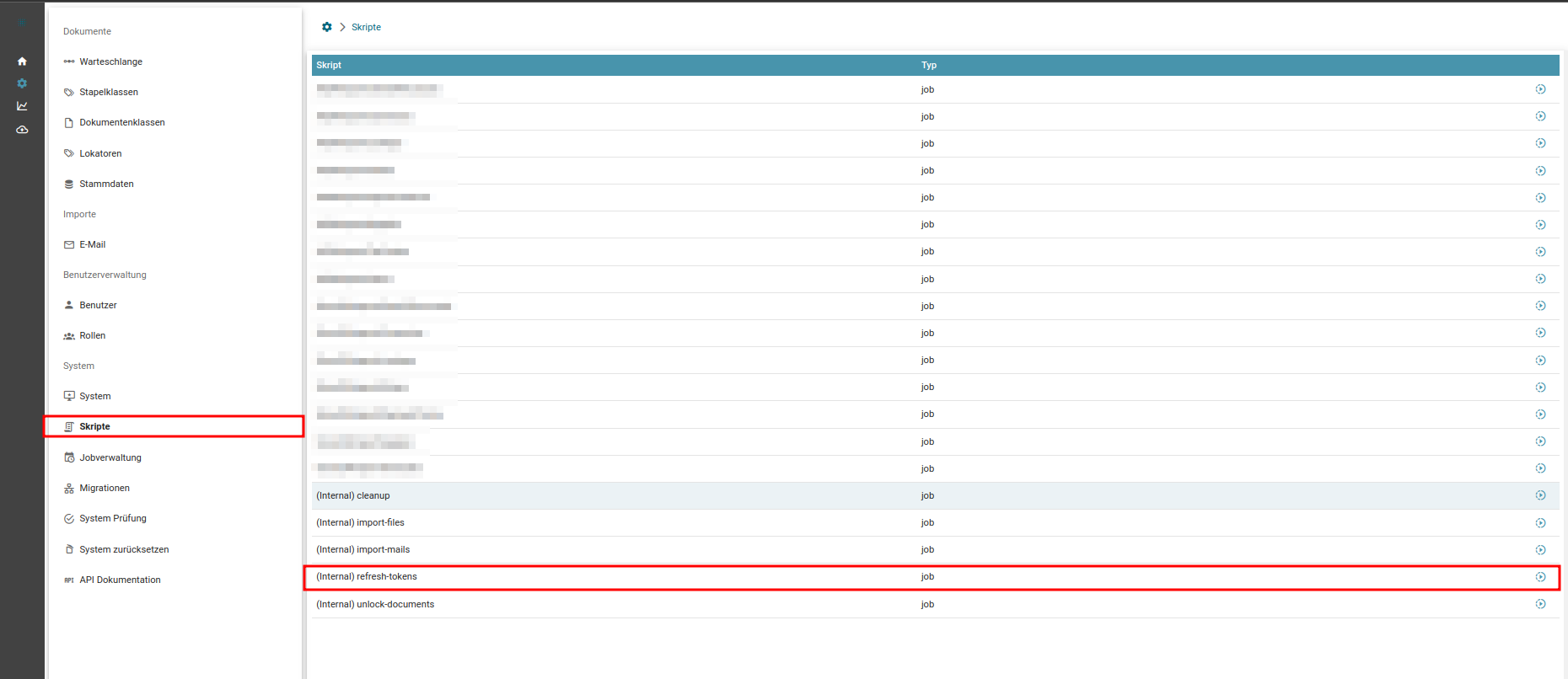
Dieses Skript kann man zu jedem Zeitpunkt manuell ausführen.
Sie müssen für dieses Skript einen Job einrichten, der häufig genug ausgeführt wird, um ein Ablaufen der Zugriffsdaten zu verhindern. Im Standard sind Refresh-Token von Microsoft 1 Tag lang gültig, es sollte also mehrmals am Tag versucht werden die Zugriffsdaten zu aktualisieren.
Bei geringerer Gültigkeit als 12 Std. muss per Projekt Change Request die Erneuerung eines Tokens auf eine passende kürzere Zeit von einem Consultant angepasst werden.
Wir empfehlen den Job jede Stunde auszuführen:
Cron-Ausdruck für den Job: */50 * * * *
Wie Jobs zu konfigurieren sind, ist hier dokumentiert:
Fragen und Antworten
Was passiert wenn der Job ausfällt ? |
Ist der Job durch unvorhersehbare Gründe nicht gelaufen so müssen Sie sich neu Authentifizieren mit dem Authentifizierung-Button in der Email-Konfiguration |
Kann ich einfach meine Postfach in der Konfiguration ändern und muss ich danach was tun ? |
Sobald Sie die Konfiguration ändern oder abspeichern, weist die Anwendung Sie darauf hin, ein neuen Authentifizierungsprozess einzuleiten. Lehnen Sie dieses Aufforderung ab, haben Sie immer noch die Möglichkeit den Authentifizierungsbutton zu betätigen. |
Kann ich meine Entra ID Applikation für mehrere Squeeze Mandanten nutzen ? |
Nein, die Verwendung einer Entra ID Applikation für mehrere Mandanten ist nicht Möglich, solange die Mandanten unter anderen Domänen erreichbar sind. test.mandant.squeeze.one
2 Mandant: test2.mandant.squeeze.one
In diesem Beispiel kann man keine Application verwenden, da wir pro Application nur einen Mandanten ansprechen können. Ein Authentifizierung bei Microsoft würde ggf. immer nur auf einen Mandanten laufen.
Du hast die Möglichkeit mehrere Postfächer mit der selben Applikation zu nutzen, dort gibt es keine Begrenzungen.
|
Meine Zugriff durch die AzureTokens laufen ständig ab, obwohl ich den Job richtig konfiguriert habe. |
Es kann vorkommen, dass die Server Zeit und die konfigurierte Zeit der Squeeze Applikation sich unterscheiden. Squeeze Zeit: UTC (UTC +0)
In diesem Fall werden die Tokens, die erzeugt wurden, in CEST abgespeichert. Wenn in diesem Fall die Squeeze Applikation nun prüft, ob ein Token erneuert werden muss, dann wird diese in diesem Fall den Token als noch nicht abgelaufen ansehen, da der Token in der Annahme von Squeeze gültig ist.
Sollten Sie diese Version noch nicht besitzen, versuchen Sie die Serverzeit mit der Applikationszeit zu synchronisieren. |
Configuration Client Credentials Flow (application) MS Graph API [ENG]
Client Credential Flow Microsoft Graph API
Configuration in Squeeze
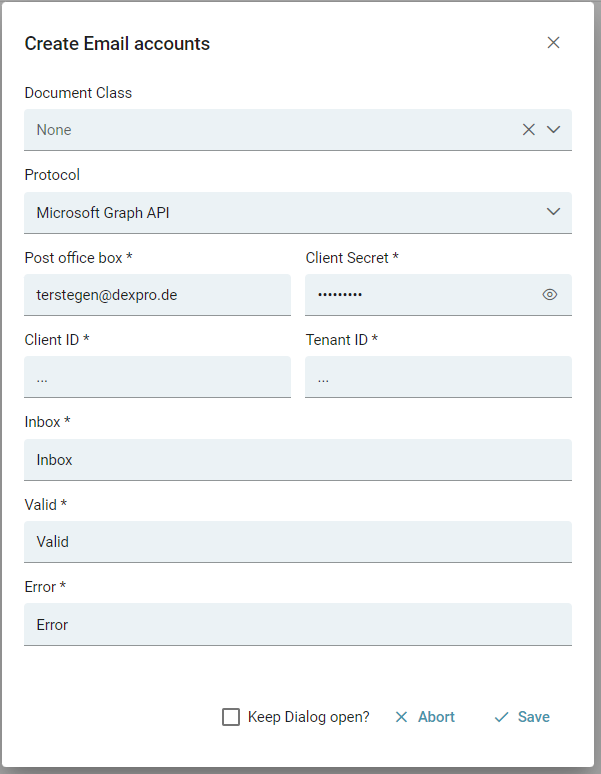
In the first versions of this feature, the configuration had to be maintained using the "Username" and "Password" fields. We recommend an update.
Expected value in the Username field: maxMustermann@mustermann.de/{client_id}/{tenant_id}
Expected value in the Password field: {client_secret}
Ordner - Konfiguration
In the folder configuration you need to specify three folders
- Inbox
This folder is regularly checked to import the emails it contains. - Done
The successfully imported emails will be moved to this folder. - Error
The emails that could not be imported (e.g. missing attachments) are stored in this folder.
When defining the folders, please make sure that the names of the folders must be unique, since the folders are searched for in the directory structure of the mailbox.
If a configured folder is not unique, this can lead to a different folder being used than the desired one.
Configuration in AAD (Azure Active Directory)
Other necessary steps for a smooth process are the setup of an Azure Active Directory Application
with a Client Secret. The global registration of a mail service of "Dexpro" in the Azure Active Directory of the customer is not offered for the time being.
In addition, it must be ensured that the application has the following scopes.
By default, this application now has access to all mailboxes.
If you want to restrict this access to individual mailboxes, additional configurations must be made in Exchange Online, the AAD and using PowerShell.
This documentation from Microsoft describes how to set this up using Group Policy: Managing Group Policy in Azure AAD.
If the Microsoft article is not sufficiently supportive, we have made a guide that is more detailed.
Configuration Authentication Code Flow (delegated) MS Graph API [ENG]
Configuration in Squeeze
This configuration interface is provided as of version 2.3.0.
If you want to use this authentication method, make sure that the Internal job refresh-tokens is enabled. This is documented further down in the article.
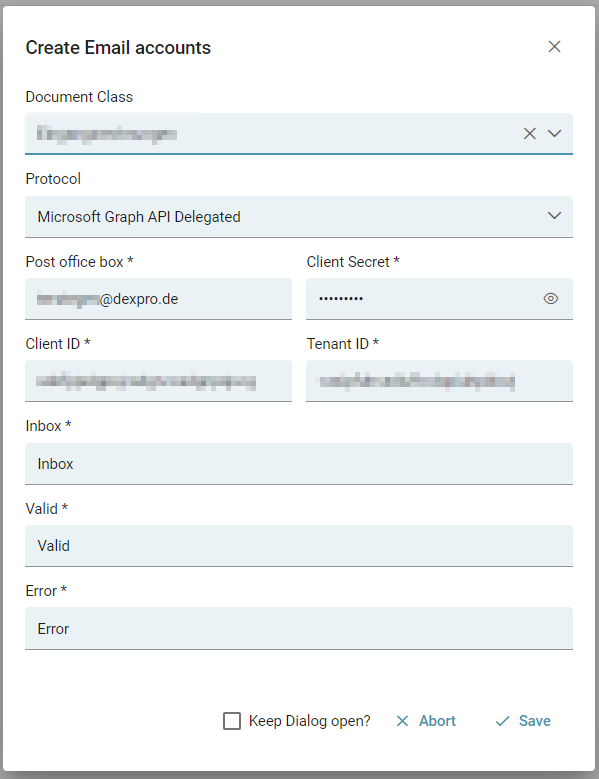
As you can see now, in the configuration interface under Protocol you can choose two types of connection to Microsoft(MS) Graph API:
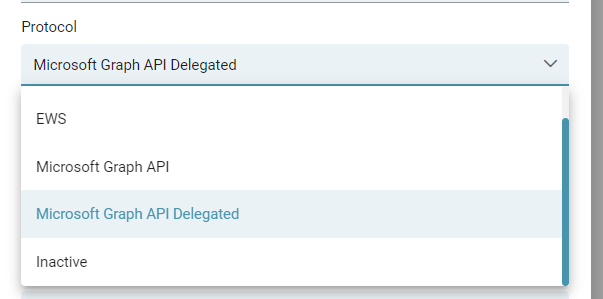
For the delegated authorization process we select Microsoft Graph API Delegated. In the next step we fill in the Client ID, Client Secret, Tenant ID and the rest of the fields.
Folder - Configuration
In the folder configuration you need to specify three folders

- Inbox
This folder is regularly checked to import the emails it contains. - Exported
The successfully imported emails are moved to this folder. - Error
The emails that could not be imported (e.g. missing attachments) are moved to this folder.
When defining the folders, please make sure that the names of the folders must be unique, because the folders are searched in the directory structure of the mailbox.
If a configured folder is not unique, this can lead to a different folder being used than the desired one.
Configuration in AAD (Azure Active Directory)
Other necessary steps for a smooth process are the setup of an Azure Active Directory Application
with a Client Secret. The global registration of a mail service of "Dexpro" in the Azure Active Directory of the customer is not offered for the time being.
In addition, it must be ensured that the application has the following scopes.
Unlike in the Permission for Client Credential Flow, any permission here is limited to the authorizing user.
Note: If a shared mailbox is to be accessed, the shared mailbox must be entered under Mailbox and the Application Permission Mail.Read.Write.Shared must be configured.
Remember that the shared mailbox will also be added to your Email Enabled security group if you have one set up.
Another significant difference to the Client Credential Flow is the use of a Redirect URI.
This Redirect URI is created in the AzureActive directory under the Application in the Authentication tab:
Scheme Redirect URI: https://Ihr.vollwertiger.DomainName/api/v2/importers/email/authenticate/end
Note: A Squeeze client always requires an Azure Active Directory application with a redirect URI.
This means that you must create an application for each client.
Authorization Process Authentication Code Flow
Once you have configured your application in the AAD and entered all the necessary data in the configuration interface, you can save your configuration.
Now another dialog box opens:
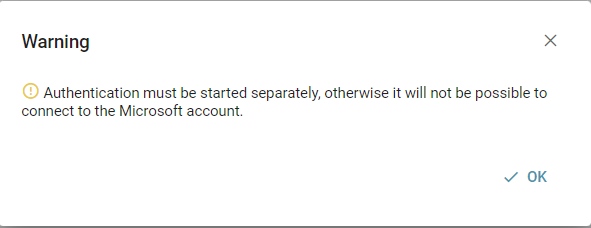
The system has saved your configuration, but you need to start the process of authentication separately using a button in the email configuration. For this purpose please select the following button:

After clicking this button, you will now be redirected to the Microsoft interface. There, the authentication process begins. Follow Microsoft's instructions:
Enter your email address.
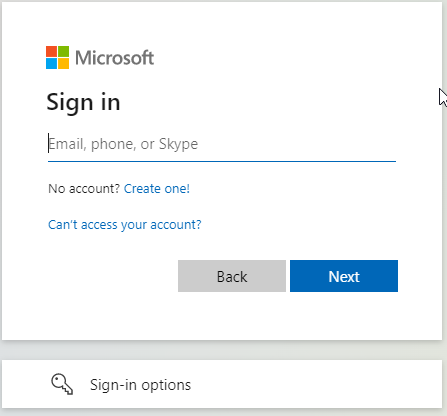
Enter your password:
Depending on the company, you may also be asked to perform 2-factor authentication:
Once you are authenticated, you will be prompted for permissions and asked to confirm those permissions. After your confirmation, Microsoft will immediately redirect you back to the Squeeze interface.
The interface will now show you if Squeeze is now authorized or if an error has occurred:
Now you can test the mail connection by clicking the Mail Connection Test button in the interface.
Job-Configuration
The use of this authentication method requires that a separate job is activated, which keeps the access data for the Graph API up-to-date in the background.
For this purpose, we find the new script named refresh-tokens in the administration under "Scripts":
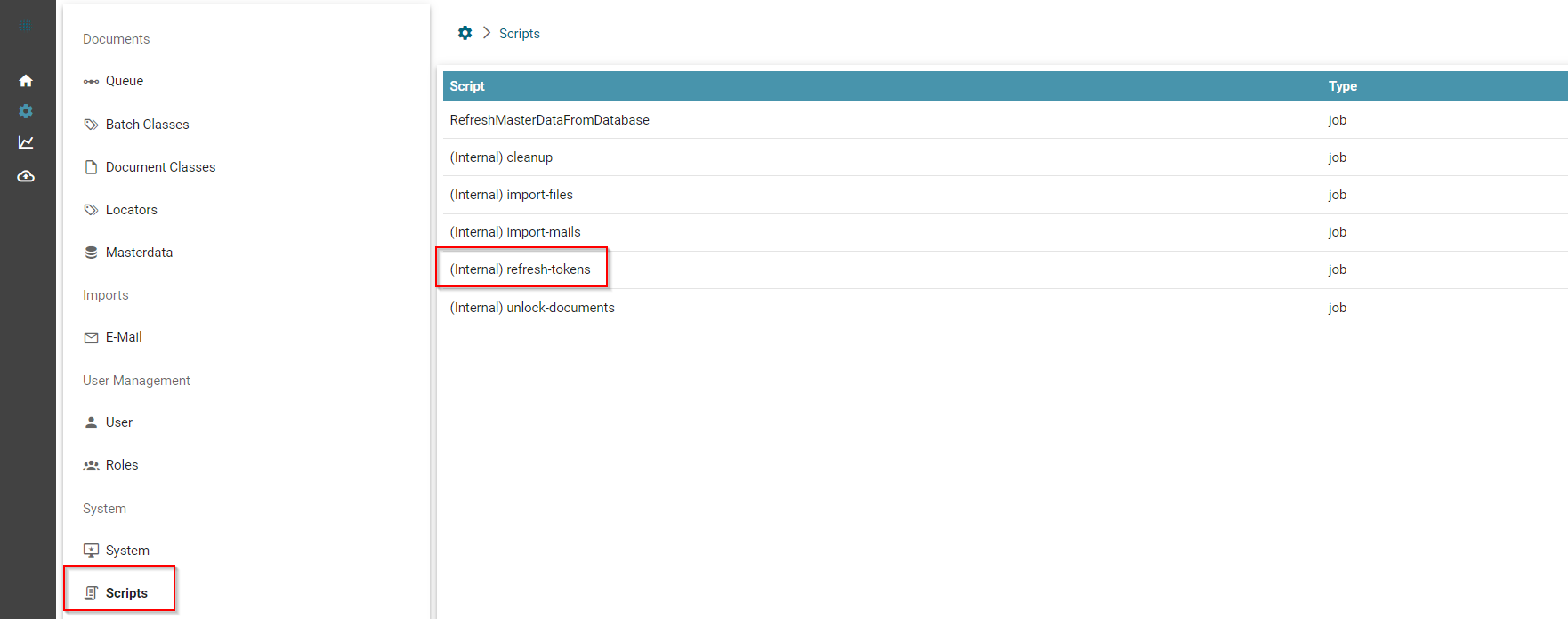
You can run this script manually at any time.
You need to set up a job for this script that runs frequently enough to prevent the access data from expiring. By default, refresh tokens from Microsoft are valid for 1 day, so you should try to refresh the access data several times a day.
We recommend running the job every hour:
Cron expression for the job: */50 * * * *.
How to configure jobs is documented here:
FAQ
What happens if the job fails? |
If the job did not run due to unforeseen reasons you have to re-authenticate using the authentication button in the email configuration. |
Can I just change my mailbox in the configuration and do I have to do anything after that? |
As soon as you change or save the configuration, the application prompts you to initiate a new authentication process. Reject this request. You still have the option to press the authentication button. |
Can I use my Azure Active Directory Application for multiple Squeeze clients? |
No, using one Application (AAD) for multiple clients is not possible as long as the clients are accessible under other domains. test.client.squeeze.one
test2.client.squeeze.one
In this example we cannot use an application, because we can only address one client per application. Authentication with Microsoft would only run on one client at a time.
You have the possibility to use multiple mailboxes with the same application (AAD), there are no limits.
|
My access through AzureTokens constantly expires, even though I have configured the job correctly. |
In this case the server time configuration and the time configuration of the Squeeze application might differ.
Example: Server Time: CEST (UTC +2) Squeeze Time: UTC (UTC +0)
In this case, the tokens that were generated are stored in CEST. If, in this scenario, the Squeeze application checks whether a token needs to be refreshed, the application will consider the token as not yet expired because it assumes the token is valid in the context of Squeeze.
This is because Squeeze checks the token in the past with UTC +0, but the token was issued with CEST (UTC +2). Therefore, the token has already expired in CEST but not in UTC, which Squeeze checks for.
The problem has been fixed in version 2.5. if you don't have this version yet, try to synchronize the server time with the application time.
This can be done by configuring the date.timezone in the php.ini.
See: https://www.php.net/manual/en/datetime.configuration.php
|
Übernahme von E-Mail-Feldern in Squeeze-Felder
Sofern beim Import einer E-Mail Informationen wie Absender, Empfänger, Betreff usw. ausgelesen werden sollen, müssen die entsprechenden folgenden Squeeze-Felder an der betroffenen Dokumentenklasse vorhanden sein:
| Name des anzulegenden Squeeze-Feldes | Information der Mail |
|
EmailReceivedDate |
Empfangsdatum |
|
EmailFromAddress |
Absender-Mail-Adresse |
|
EmailFromName |
Absender-Name |
|
EmailToAddress |
Empfänger |
| EmailMailBoxUser | Postfach (aus dem die Mail abgeholt wurde) |
|
EmailSubject |
Betreff |
|
EmailMessageId |
ID der Nachricht |
|
EmailImportFolder |
Import-Ordner |
|
EmailProcessedFolder |
Verarbeitet-Ordner |
|
EmailInvalidFolder |
Fehler-Ordner |
Unterstützung von S/MIME
Mails können optional signiert und/oder verschlüsselt werden. Das wird üblicherweise mittels S/MIME umgesetzt.
Signaturen
Es ist aktuell nicht möglich, dass Squeeze die Signature von S/MIME-signierten Mails verifiziert.
Die Verarbeitung solcher Mails ist allerdings dennoch möglich, dabei wird die Signatur allerdings nicht verifiziert.
Zum aktuellen Zeitpunkt (August 2024 / Squeeze 2.12) ist nicht garantiert, dass alle Mails im S/MIME-Format unterstützt werden. Sollten Sie diese intensiv nutzen, melden Sie sich beim Support oder ihrem Partner, um eine Erweiterung der Unterstützung von S/MIME anzustoßen.
Verschlüsselung
Es ist aktuell nicht möglich, dass SMIME verschlüsselte Mails durch Squeeze entschlüsselt werden.
Dokumentverarbeitung
Dokumentation zu Features, die bei der Hintergrundverarbeitung von Dokumenten zum Einsatz kommen.
Lokatoren
Anleitungen zur Extraktion mittels Lokatoren.
Lokatoren
Lokatoren sind in Squeeze Werkzeuge mit deren Hilfe Textinformationen aus Dokumenten ermittelt werden.
Lokatoren können in Squeeze Feldern zugewiesen werden, in diesem Fall wird das Lokatorergebnis in das jeweilige Dokumentenfeld übernommen.
In Squeeze sind verschiedene Lokatorentypen verfügbar:
| Lokatortyp | Bedeutung |
| Regular Expression | Lokator für reguläre Ausdrücke z.B. (RG[0-9]{5,6}) |
| KeyWord | Lokator für Schlüsselbegriffe. Diese Schlüsselbegriffe werden für den Fall, dass z.B. ein Buchstabe im Wort nicht richtig erkennbar ist, mit einer Fuzziness von einem Zeichen gesucht. |
| Invoice Amounts | Lokator für Endbeträge und Steuersatz einer Rechnung (Nettobetrag, Bruttobetrag, Steuerbetrag und Steuersatz) |
| Document Date | Lokator für Datumsangaben |
| Keyword to Value |
Lokator für Werte (reguläre Ausdrücke) die auf einen Schlüsselbegriff umgesetzt werden. Z.B: Das Wort "Schlussrechnung" soll auf den Schlüsselbegriff "Rechnung" umgesetzt werden. |
| Value next to Keyword | Lokator für Werte (reguläre Ausdrücke) die in der Nähe eines bestimmten Schlüsselbegriffes |
| Search for line items | Lokator für die Positionszeilenfindung |
| Search for DB linked data | Lokator für Datenbanksuche (andere Lokatoren können als Source-Lokator angegeben werden) |
| Barcode | Lokator für Barcodeerkennung |
| Value from Regular Expression | Datenbanklokator für reguläre Ausdrücke (regex, result) |
Lokatoreigenschaften:
| Eigenschaft | Bedeutung |
| Name | technischer Lokatorname |
| Beschreibung | Anzeigenamen für den Lokator |
| Lokator Typ | Auswahlfeld für Lokatortypen |
| Datentyp | Auswahlfeld für Lokatorwerte (Text, Date, Amount) |
| Seiten | Auswahlfeld für welche Seiten des Dokumentes der Lokator ausgeführt werden soll (Jede Seite, Erste Seite, Letzte Seite) |
| ggf. Quelle | Auswahlfeld für Lokatoren, deren Ergebnismenge für diesen Lokator genutzt werden soll |
| Aktiv | Auswahlfeld für die Aktivierung des Lokators (ja, nein) |
| ignoriere Leerzeichen | das Suchmuster des Lokators ignoriert Leerzeichen |
Wichtig: Lokatoren können Ihr Suchmuster nur pro Textzeile finden, es gibt keine Möglichkeit mit Zeilenumbrüchen zu arbeiten.
Mit dem Squeeze Invoice Template werden bereits verschiedene Lokatoren ausgeliefert:
Wichtig: Diese Lokatoren können in jeder anderen Dokumentenklasse genutzt werden.
Für jeden Lokator können entsprechende Ersetzungen konfiguriert werden:
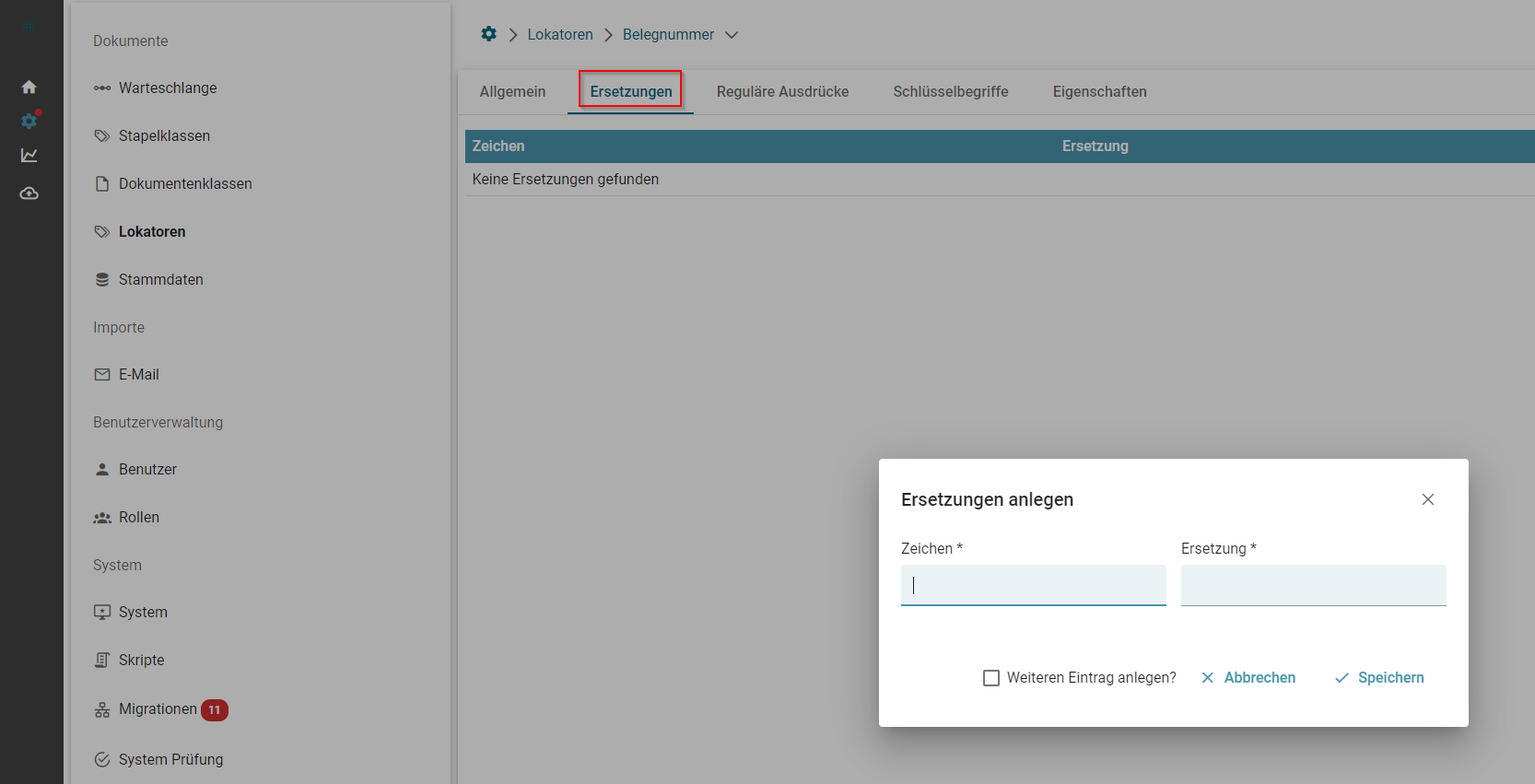
Beispiele für Ersetzungen im Phone (Telefonnummer) - Lokator:

Wichtig: Ersetzungen können immer nur für die Ersetzung eines Zeichens durch ein oder ein Leerzeichen konfiguriert werden.
Testen von Lokatoren
Lokatoren können getestet werden, indem in der Validierung über das Optionsmenü "Lokatoren testen" ausgewählt wird.
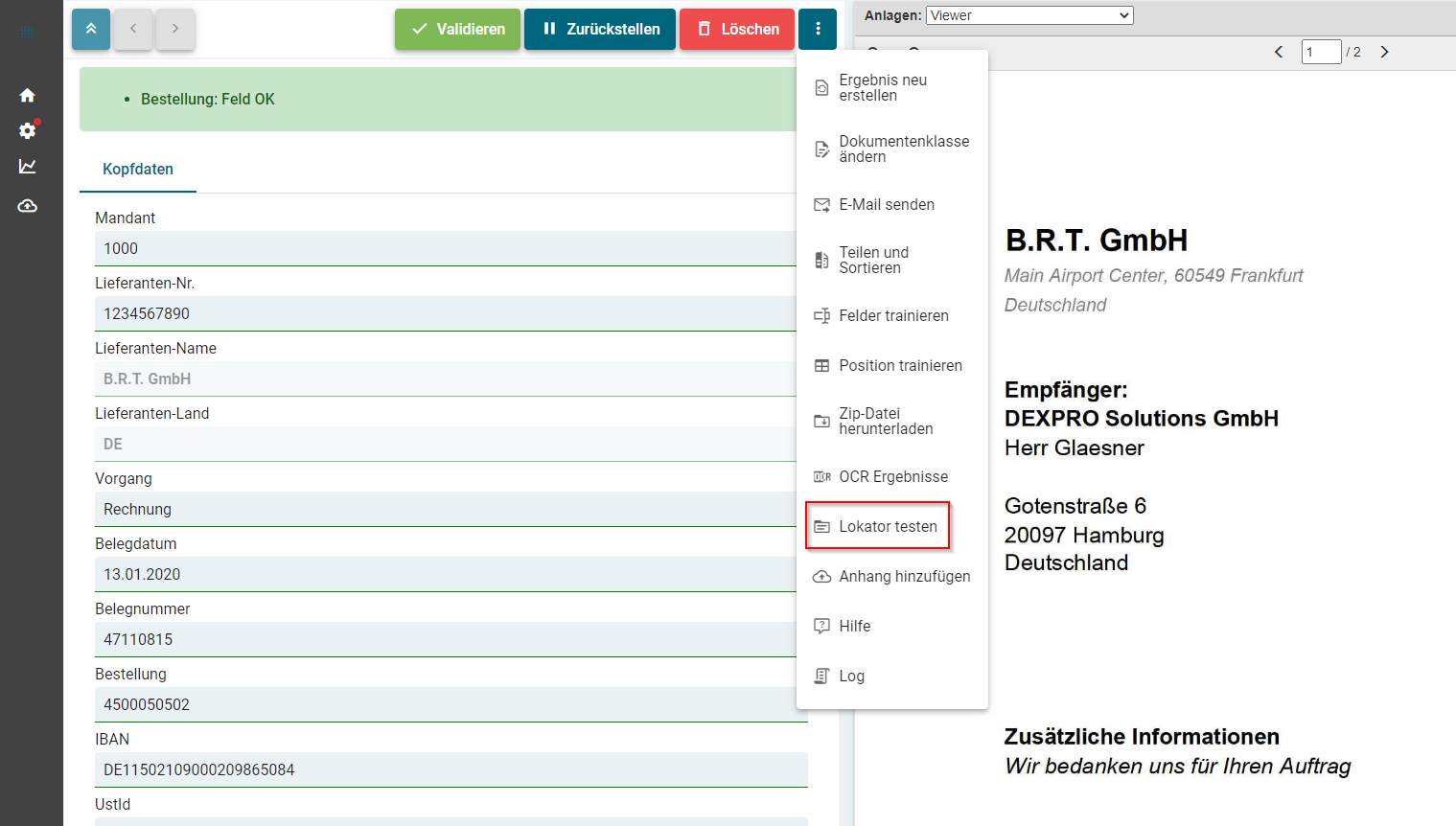
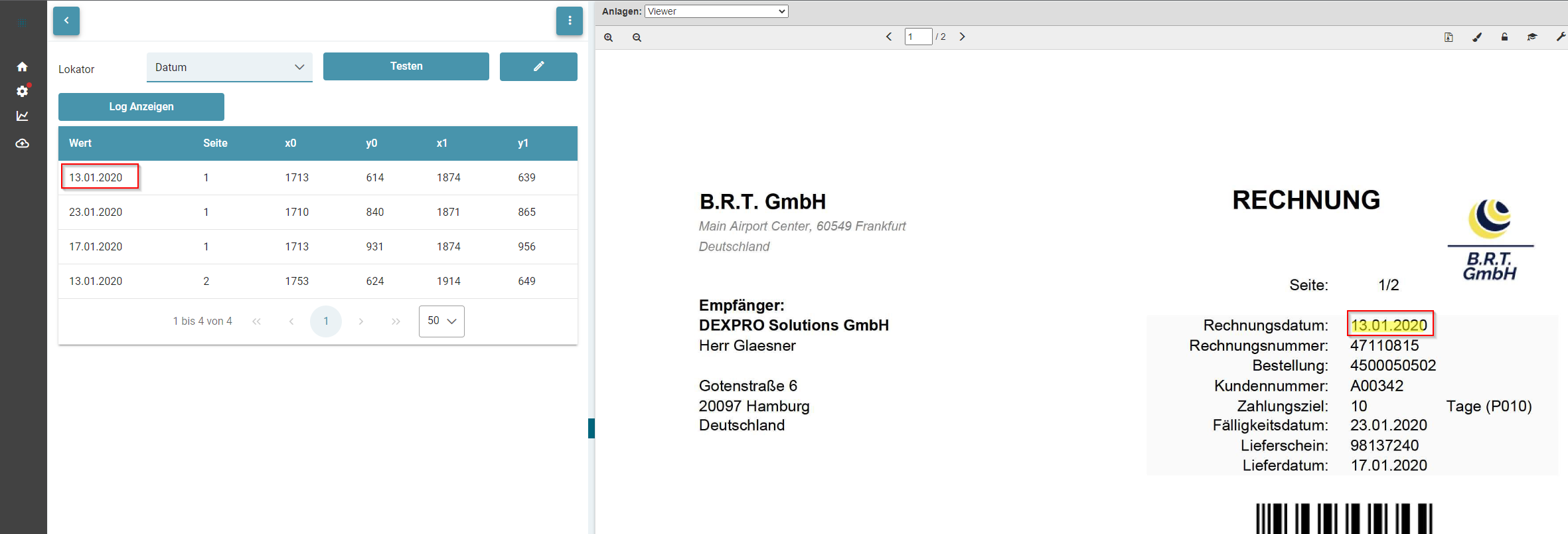
In dem Auswahlfenster kann der Lokator den der Benutzer testen möchte ausgewählt werden:
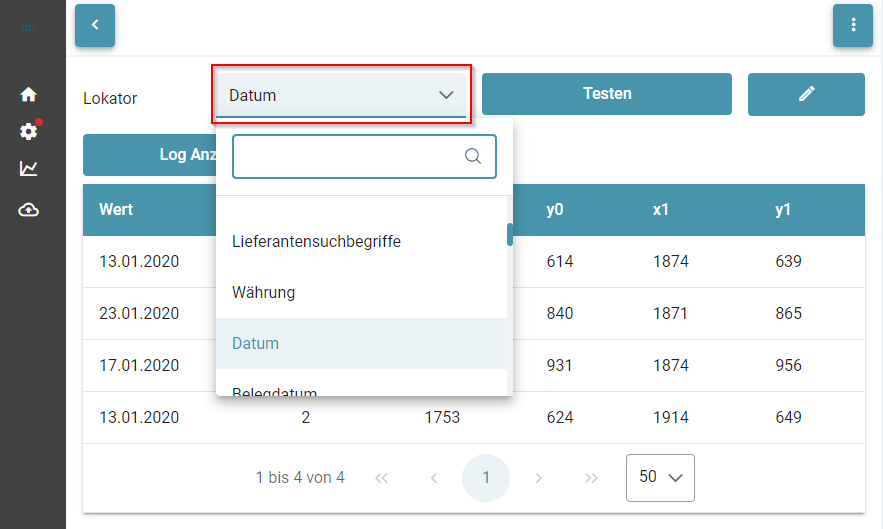
Beim Klick auf den Button Testen wird der ausgewählte Lokator ausgeführt.
Auf der linken Seite werden jetzt die erkannten Werte in einer Liste dargestellt. Auf der rechten Seite ist wieder das Dokument zu sehen. Wenn der Benutzer nun mit der Maus über einen der Werte zeigt, wird auf der rechten Seite die Fundstelle dieses Wertes markiert.
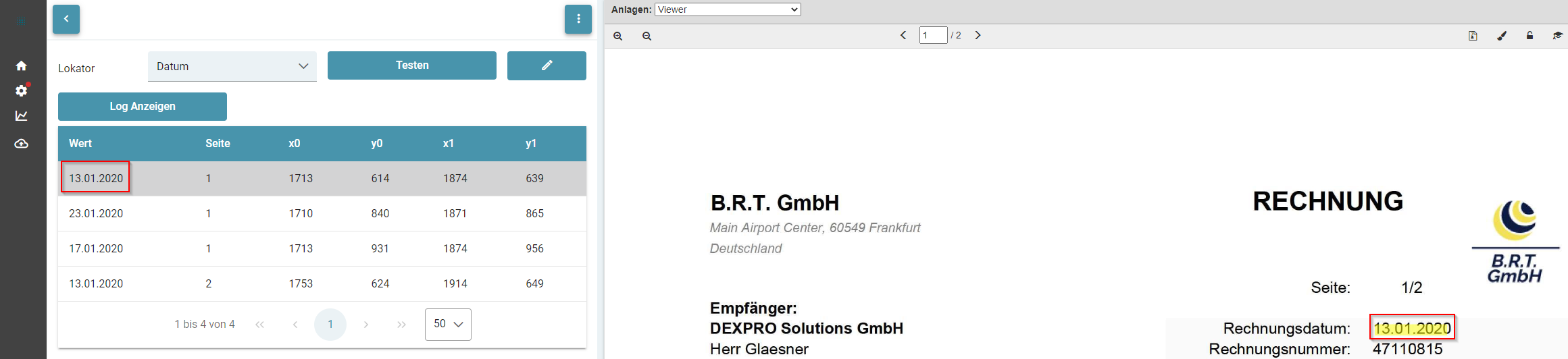
Der Benutzer kann nun wahlweise den Button Bearbeiten klicken, dann erscheint der Konfigurationsdialog für den Lokator, hier kann die Konfiguration angepasst werden und der Test erneut ausgeführt werden.
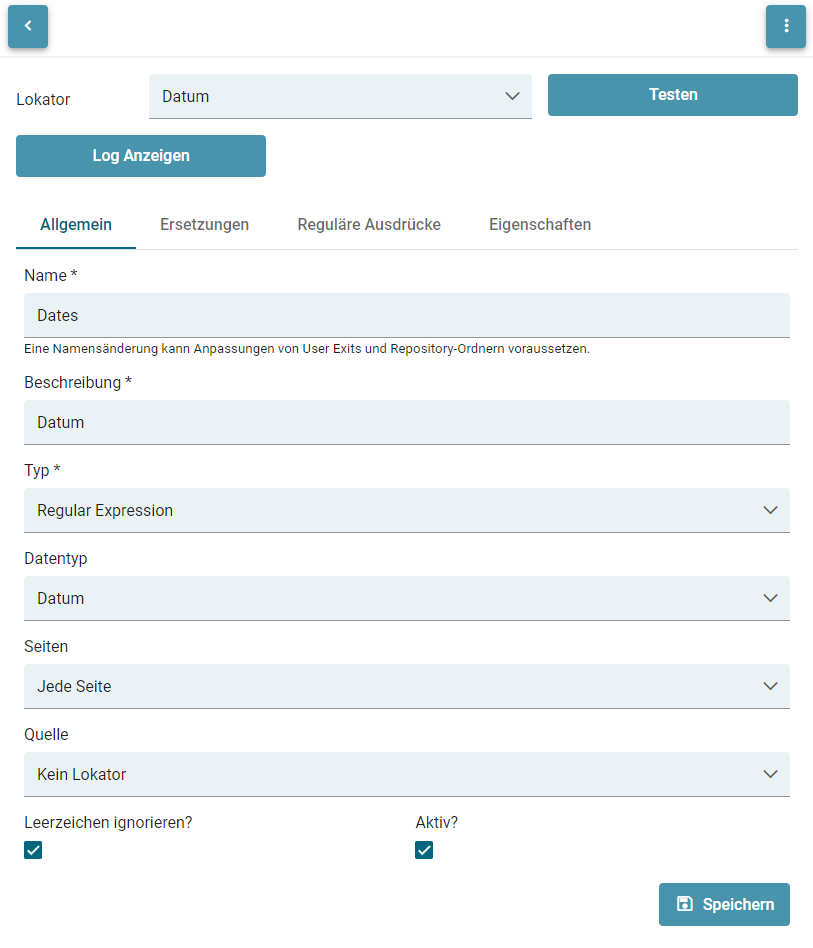
Besonders bei der Konfiguration eines Lokators für reguläre Ausdrücke, Schlüsselworte oder auch Positionen ist der Testmodus empfehlenswert.
Nachdem der Benutzer einen neuen Lokator erfolgreich getestet hat, kann über den Reiter Optionen und den Menüpunkt Ergebnis neu erstellen, das Dokument erneut verarbeitet werden, dabei wird nur die Lokatoren-Konfiguration mit den aktuellen Einstellungen angewendet.
Hinweis: Bei Ergebnis neu erstellen, wird keine neue OCR-Erkennung durchgeführt, es wird lediglich die Lokatoren-Logik auf das OCR-Ergebnis neu angewendet.
Lokator: Document Date
Der Lokator Document Date findet das erste Datum auf einer Dokumentenseite, von oben beginnend.
Dieser Lokator kann nur mittels eines weiteren Lokators basierend auf der Suche nach regulären Ausdrücken genutzt werden. Für diesen Lokator sollten entsprechende reguläre Ausdrücke konfiguriert sein.
Im Squeeze Invoice-Template wird ein Lokator mit verschiedenen regulären Ausdrücken zur Datums-Suche ausgeliefert.
Dieser Lokator (Dates) wird dann als Quelle für den Beleg-Datums-Lokator genutzt.
Konfiguration des Dates-Lokators:
Allgemeine Eigenschaften:
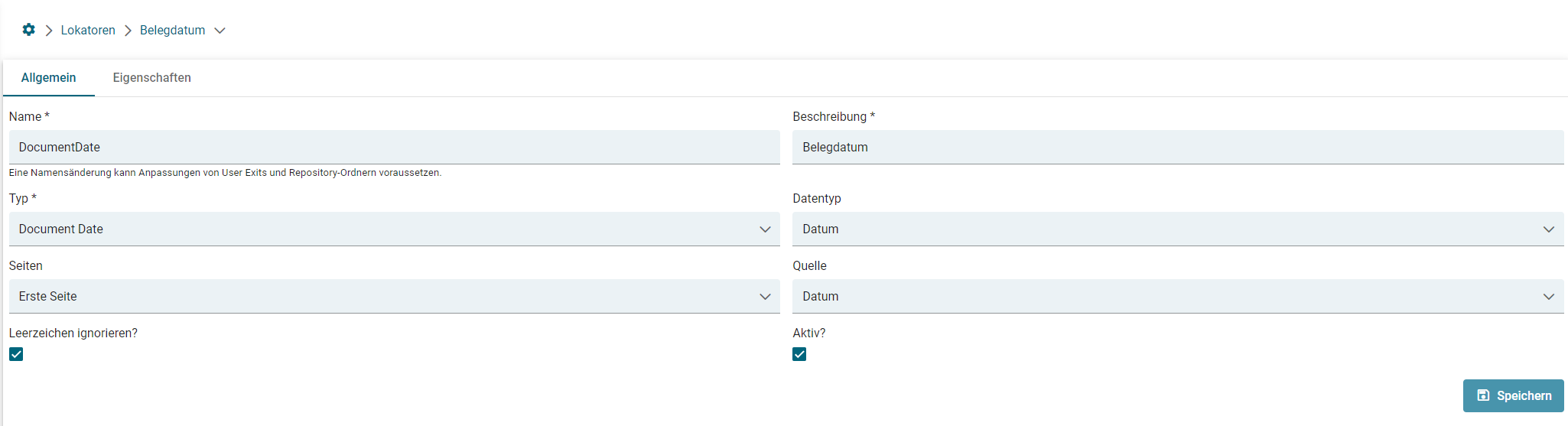
Reguläre Ausdrücke für den Date-Lokator:
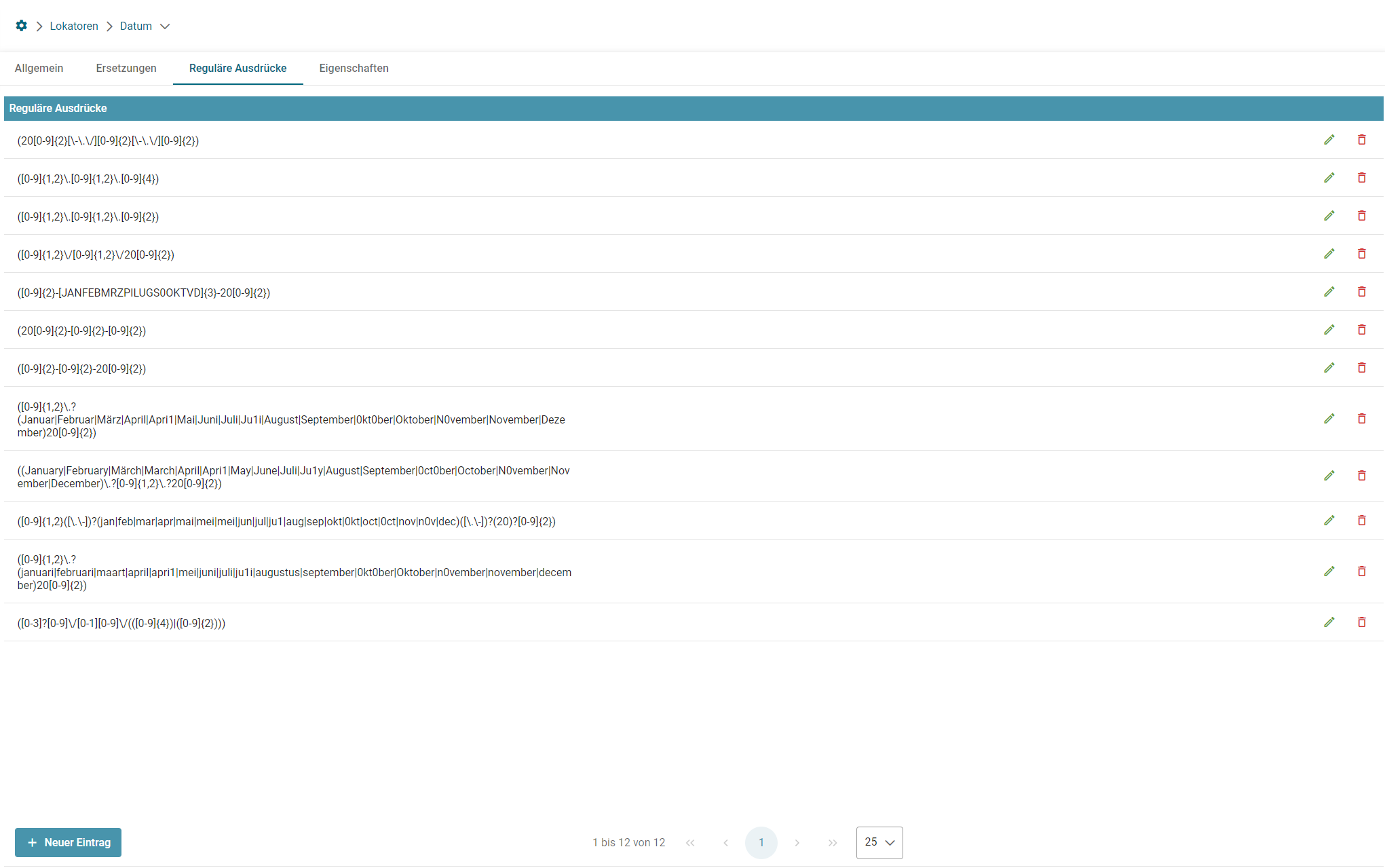
Konfiguration des Beleg-Datum-Lokators:
Der Datums-Lokator wird als Quelle für den Beleg-Datums Lokator eingetragen.
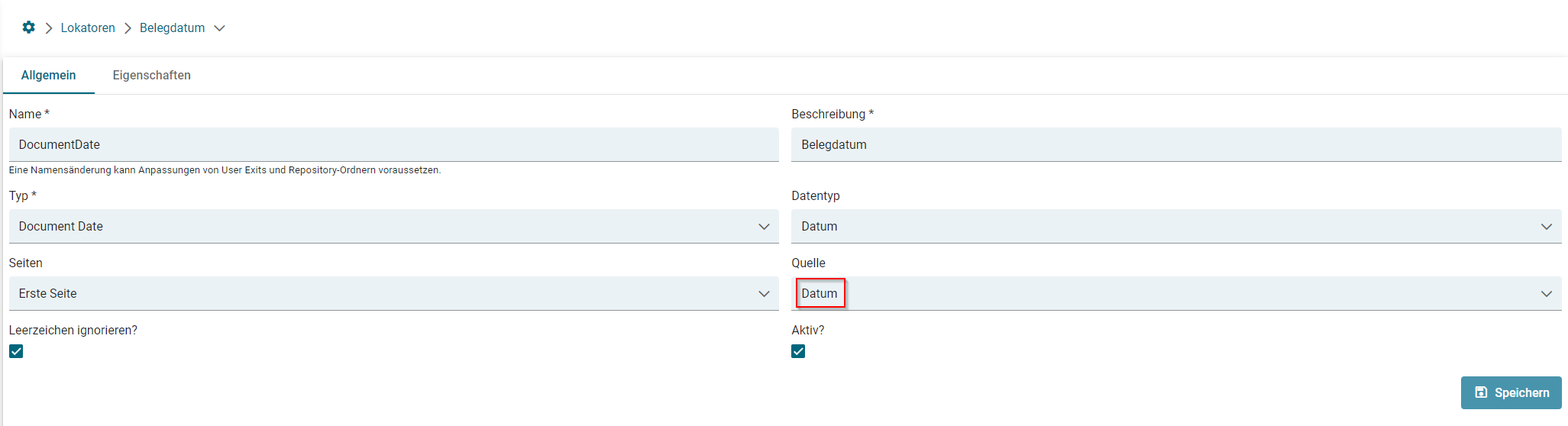
Lokator: Invoice Amounts
Der Lokator Invoice Amounts findet die Endbeträge (Nettobetrag, Bruttobetrag und Steuerbetrag) und den Steuersatz einer Rechnung.
Dieser Lokator funktioniert nur in Kombination mit einem Betrags-Lokator der auf Basis regulärer Ausdrücke, numerische Werte mit 2 Nachkommastellen ermittelt. Darüber hinaus werden Stammdateninformationen zum gültigen Steuersatz benötigt.
Die Funktionsweise dieses Lokators kann wie folgt beschrieben werden.
- Mittels des Betrags-Lokators werden zuerst alle Beträge der Rechnung gefunden
- Auf der letzten Seite der Rechnung wird beginnend von unten nach oben der höchste Betrag ermittelt
- In der Stammdaten-Tabelle taxrates (Steuersätze) werden mit dem Invoice Template alle europäischen Steuersätze landesspezifisch ausgeliefert
- In der Stammdaten-Tabelle creditors (Bestandteil des ausgelieferten Invoice Templates) können kreditorspezifische Länderkennzeichen hinterlegt werden
- Mittels des zum ermittelten Kreditor, passenden Länderkennzeichens, werden die für diese Rechnung gültigen Steuersätze ermittelt
- Der Lokator Invoice Amount verwendet diese Informationen um zum höchsten gefundenen Bruttobetrag, mittels der gültigen Steuersätze, entsprechende passende Netto und Steuerbeträge zu finden.
Wichtig: Diese Konfiguration funktioniert nur für einen Steuersatz. Für Rechnungen mit mehreren Steuersätzen wird es in zukünftigen Versionen entsprechende Funktionen geben. Aktuell gibt es für diese Rechnungen die Möglichkeit Endbeträge für mehrere Steuersätze kreditorspezifisch zu trainieren.
Konfiguration des Invoice Amounts Lokators:
Voraussetzung für die Verwendung dieses Lokators ist ein Lokator für die Betragsfindung aufgrund regulärer Ausdrücke. Dieser Lokator wird mit dem Invoice Template ausgeliefert.
weitere Voraussetzungen sind die Stammdatentabellen taxrates und creditors. Beide Stammdatentabellen werden mit dem Invoice Template ausgeliefert.
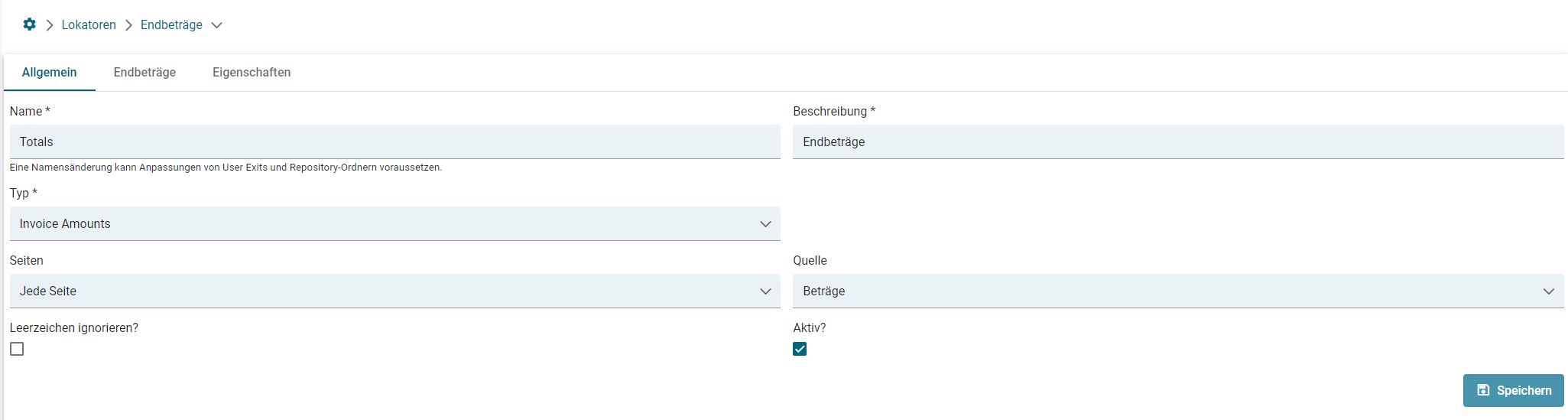
Im Feld ggf. Quelle wird der konfigurierte Betragslokator hinterlegt.
Alternative Endbetragsermittllung für Rechnungen:
Da es vorkommen kann das einige Rechnungen die für die Endbetrags-Ermittlung notwendigen Werte (Brutto, Netto und Steuerbetrag) nicht enthalten (z.B. Rechnungen im Baugewerbe), kann für diese Rechnungen alternativ, die Endbetrags-Ermittlung nach dem Prinzip der Keyword-Suche konfiguriert werden.
Für diese Konfiguration sind 3 weitere Keyword-Lokatoren (Nettobetrag, Bruttobetrag und Steuerbetrag) anzulegen. Diese Lokatoren sollten die gewünschten Schlüsselworte für die gesuchten Beträge finden.
Diese Lokatoren können dann im Reiter Endbeträge entsprechend hinterlegt werden.
Konfigurierbare Steuersätze je Land
Seit der SQUEEZE Version 1.8.0 existiert eine weitere Möglichkeit zur Konfiguration dieses Lokators. Auf Grund der Mehrwertsteueranpassung zum 01.07.2020 wurde die Möglichkeit geschaffen, die gültigen Mehrwertsteuersätze je Land in der Stammdatentabelle (taxrates) zu hinterlegen.
Hinzu kommt die Möglichkeit, der Betragserkennung mitzugeben, für welches Land gerade eine Betragserkennung durchgeführt werden soll bzw. welche Mehrwertsteuersätze zu nutzen sind. Das Land bzw. die Mehrwertsteuersätze können je Beleg variieren, daher kann unter dem neuen Reiter Eigenschaften hinterlegt werden, in welchem Feld (TaxCountryField) das Länderkürzel steht, welches zur Ermittlung der Steuersätze genutzt werden soll.
Sollte kein Land ermittelt worden sein, kann ein Standard Ländercode festgelegt werden (DefaultTaxCountry), welcher verwendet wird, um die Steuersätze zu ermitteln.
Hier ein Beispiel:
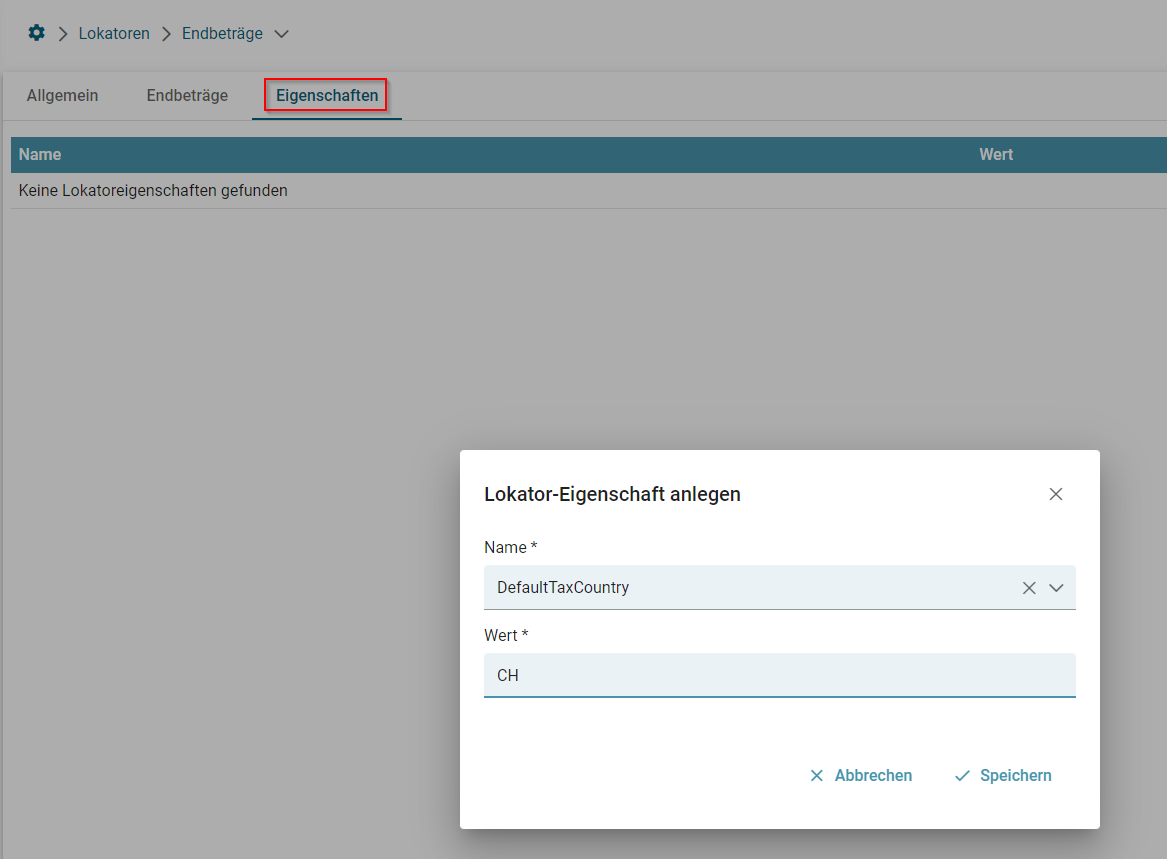
Lokator: KeyWord
Der Lokator KeyWord findet Schlüsselwörter in den OCR-Textzeilen des Dokumentes.
Das Ergebnis dieses Lokators ist das konfigurierte Schlüsselwort.
Wichtig: die Suche nach Schlüsselwörtern berücksichtigt immer nur ein Schlüsselwort.
Wichtig: Es können beliebig viele Schlüsselwörter konfiguriert werden, diese werden dann automatisch oder verknüpft gesucht.
Wichtig: Die Suche nach Schlüsselwörtern berücksichtigt eine gewisse Unschärfe. Im Detail bedeutet unscharf in diesem Lokator, das ein Zeichen des Schlüsselwortes abweichen kann und dennoch zu einem positiven Suchergebnis führen wird.
Wichtig: Schlüsselwörter werden in Squeeze case insensitive gesucht, das bedeutet, Groß-Klein Schreibung muss nicht extra berücksichtigt werden.
Die Anlage eines neuen Lokators für die Suche nach einem neuen Schlüsselwort, funktioniert analog zur Anlage eines regulären Ausdrucks, der Lokator Typ für die Schlüsselwortsuche ist KeyWord.
Lokator: KeyWord to Value
Der Lokator KeyWord to Value findet Schlüsselwörter in den OCR-Textzeilen des Dokumentes.
Der Unterschied zum normalen KeyWord Lokator besteht darin, das dem Schlüsselwort ein weiterer konfigurierbarer Wert zugewiesen werden muss.
Das Ergebnis dieses Lokators ist der konfigurierte Wert der dem Schlüsselwort zugeordnet ist.
Darüber hinaus gelten für die KeyWord to Value Suche alle Merkmale der normalen KeyWord Suche (siehe Lokator: KeyWord)
Ein geeignetes Beispiel für die KeyWord to Value Suche ist z.B. die Rechnungsart.
| zugewiesener Wert | mögliche Schlüsselwörter |
| Rechnung | Rechnung, Anzahlungsrechnung, Invoice, Faktura, Dauerrechnung etc. |
| Gutschrift | Gutschrift, Debit Note etc. |
Anlegen eines KeyWord to Value Lokators:
Das Vorgehen zum Anlegen eines KeyWord to Value Lokators ist analog zum KeyWord Lokator.
Wenn der Lokator Typ KeyWord to Value ausgewählt wird, erscheint im Konfigurationsdialog neben dem Reiter Suchbegriffe für die Schlüsselwörter, ein weiterer Reiter für die Konfiguration der Werte.
Zuerst konfiguriert man den gewünschten Wert mit einem Klick auf den Reiter Werteliste.
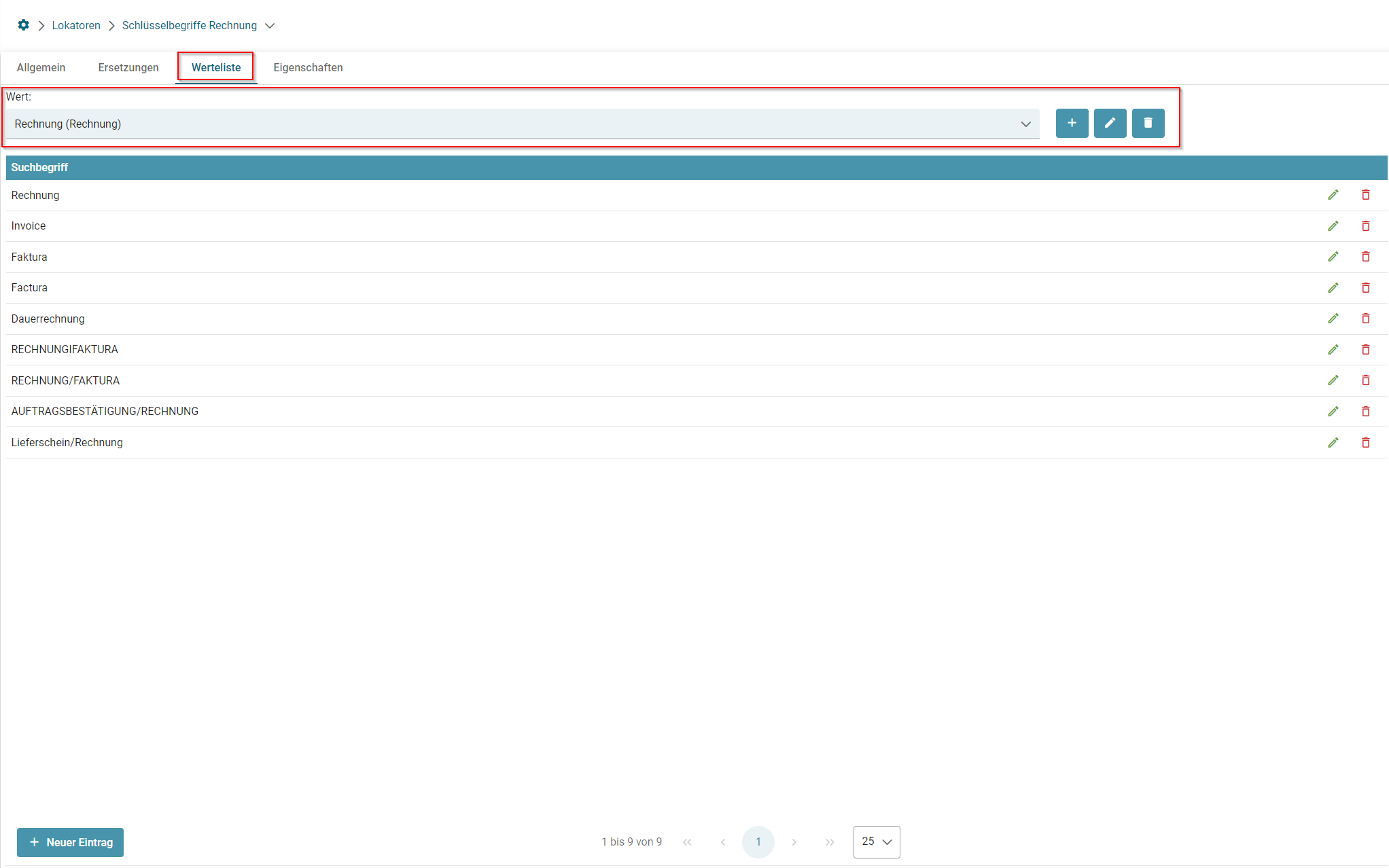
Mit einem Klick auf das + Symbol wird ein neuer Wert hinzugefügt. Daraufhin öffnet sich ein neues Fenster mit den beiden Feldern Wert und Beschreibung, diese beiden Felder werden im folgenden Beispiel jeweils mit dem Wert Rechnung gefüllt und mit einem Klick auf den Speichern Button bestätigt.
Direkt unter den Werten können Suchbegriffe über das Symbol "Neuer Eintrag" gepflegt werden.
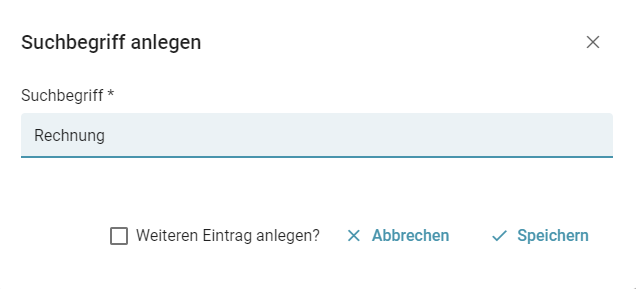
Mit dieser Konfiguration werden das Schlüsselwort Rechnung auf dem Dokument gesucht und das Ergebnis dieses Lokators ist der Wert Rechnung.
Diese Konfiguration kann beliebig erweitert werden. Zum Beispiel kann ein weiterer Wert Gutschrift hinzugefügt werden.
Diesem Wert können wieder beliebig viele Suchbegriffe zugewiesen werden.
Wichtig: Jedem Suchbegriff sollte ein Wert zugewiesen werden, da andernfalls das Lokator-Ergebnis für den Suchbegriff leer bleibt.
Lokator: Regular Expression
Der Lokator Regular Expression findet reguläre Ausdrücke in den OCR-Textzeilen des Dokumentes.
Das Ergebnis dieses Lokators ist das gefundene Suchmuster.
Wie reguläre Ausdrücke funktionieren, ist nicht Bestandteil dieser Dokumentation, dafür gibt es im Internet sehr viele gute Beispiele und Möglichkeiten zum Testen von regulären Ausdrücken, z.B. https://regex101.com/
Wichtig: Es können beliebig viele reguläre Ausdrücke konfiguriert werden, diese werden dann automatisch oder verknüpft gesucht.
Wichtig: reguläre Ausdrücke werden in Squeeze case insensitive gesucht, das bedeutet, Groß-Klein Schreibung muss nicht extra berücksichtigt werden.
Wichtig: Die regulären Ausdrücke werden in der Reihenfolge in der diese angelegt sind gesucht, das bedeutet für einen regulären Ausdruck der bereits gefunden wurde, kann kein weiterer, in der Liste nachfolgender regulärer Ausdruck gefunden werden.
Klassische Beispiele für den Einsatz von Lokatoren für reguläre Ausdrücke:
Wichtig: für einige dieser regulären Ausdrücke müssen Ersetzungen konfiguriert werden
| Beispiel | Wert | regulärer Ausdruck | Leerzeichen ignorieren |
| IBAN | DExx xxxx xxxx xxxx xxxx xx | (DE\d{20}) | ja |
| Ust-ID | DE xxxxxxxx | ((DE)([1-9]\d{8})) | ja |
| Beträge | 100,00 oder 1.000,00 | ([-\+]?[0-9]{1,3}([ ]?[,\.]?[ ]?[0-9]{3})*[ ]?[,\.][ ]?[0-9]{2}[-\+]?(?![0-9.,])) | nein |
| Datum | 01.01.2020 | ([0-9]{1,2}\.[0-9]{1,2}\.[0-9]{4})|([0-9]{1,2}\.[0-9]{1,2}\.[0-9]{2}) | ja |
| Namen | Max Mustermann | (Max Mustermann) | nein |
| Telefonnr. |
+4940359840001 |
([+]?[0-9]{8,15}) | ja |
| Emailadresse | info@dexpro-solutions.de | ([a-zA-Z0-9_\-.]{2,30}@[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3}) | nein |
| URL | www.dexpro-solutions.de | (www\.[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3}) | nein |
beispielhafte Einrichtung eines neuen Lokators zur Erkennung einer Bestellnummer anhand eines regulären Ausdrucks
Im folgenden Beispiel soll eine auf dem Dokument befindliche 10-stellige numerische Bestellnummer erkannt werden.
Dazu bietet sich der Lokator für reguläre Ausdrücke sehr gut an.
Um ins Lokatoren-Menü zu gelangen Klicken Sie auf Admin und danach auf Lokatoren.
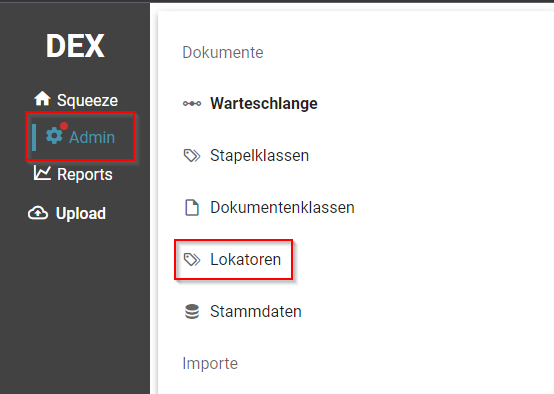
In der unteren Bildschirmleiste das Symbol "Neuer Eintrag" klicken um einen neuen Lokator anzulegen.
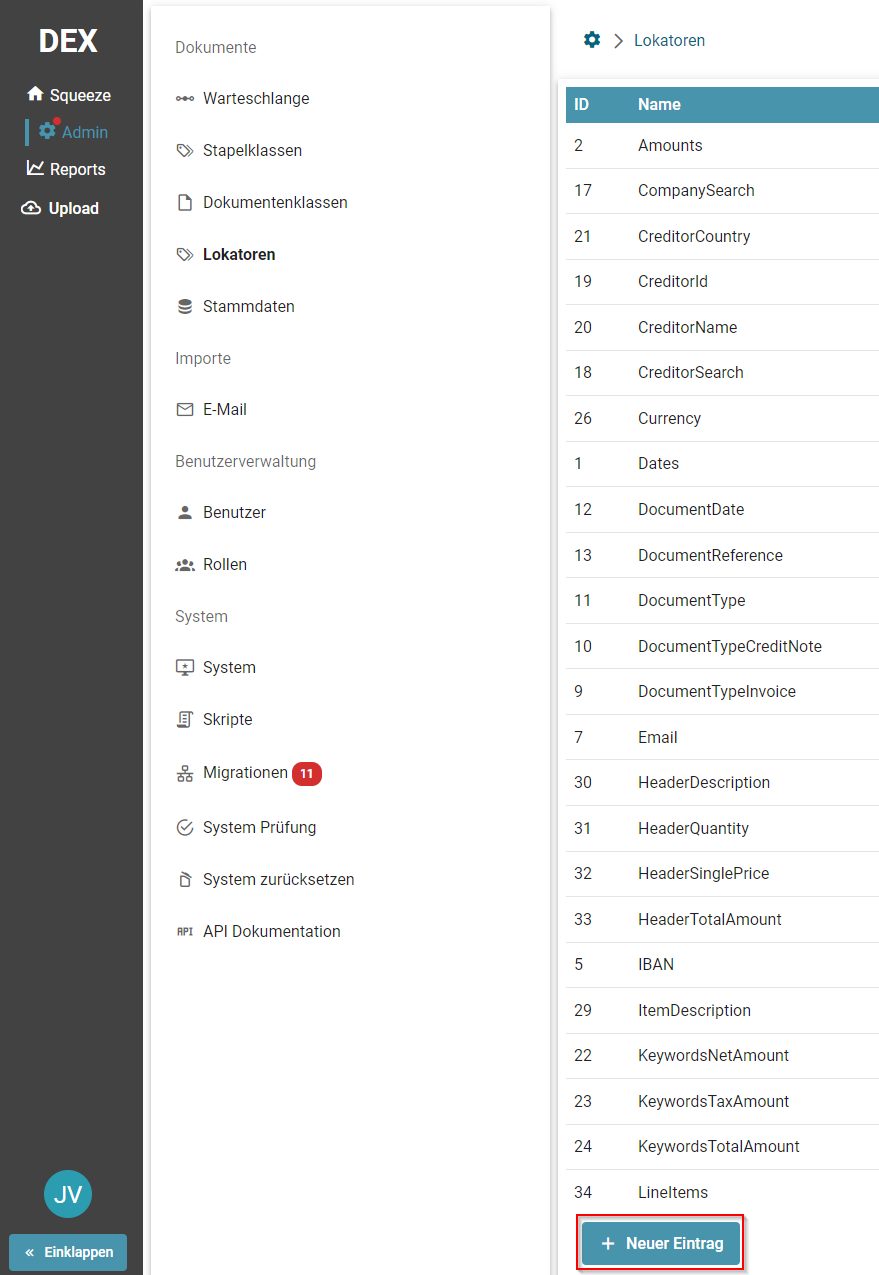
Im sich daraufhin öffnenden Dialog den technischen Namen, den Anzeige-Namen des neuen Lokators angeben und den Lokator auf Aktiv setzen. Der Lokator-Typ Regular Expression ist bereits vorausgewählt. Die Erkennung der Bestellnummer soll auf jeder Seite durchgeführt werden und der Wert Typ den wir erkennen wollen ist Text. Danach wird der Lokator gespeichert.
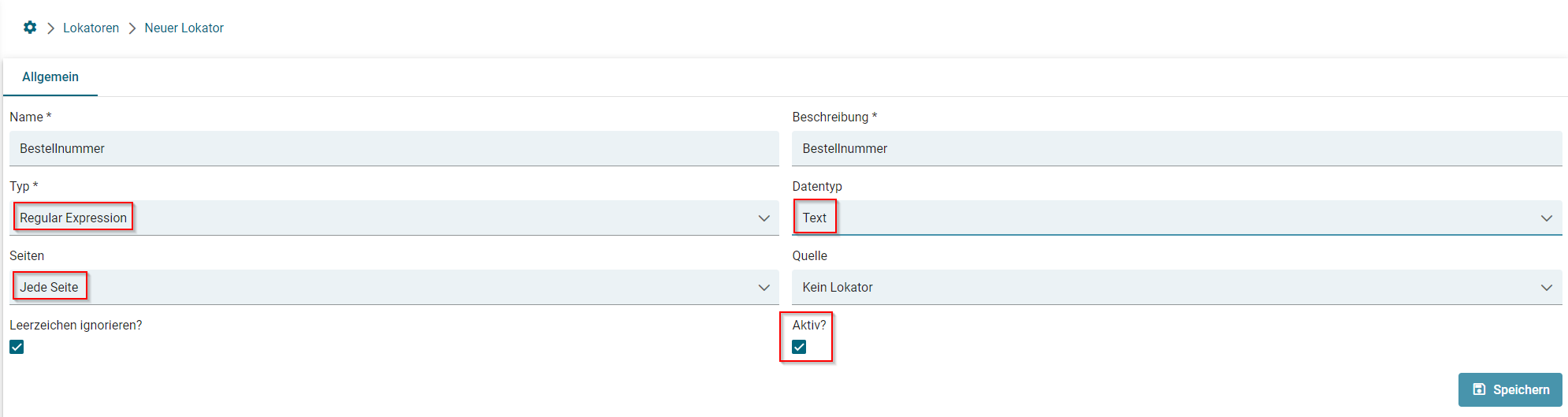
In der danach erscheinenden Ansicht klicken wir auf den Reiter Reguläre Ausdrücke um den Reg-Ex für den Lokator zu konfigurieren. Hier wieder das Symbol "Neuer Eintrag" klicken um einen neuen regulären Ausdruck zu konfigurieren.
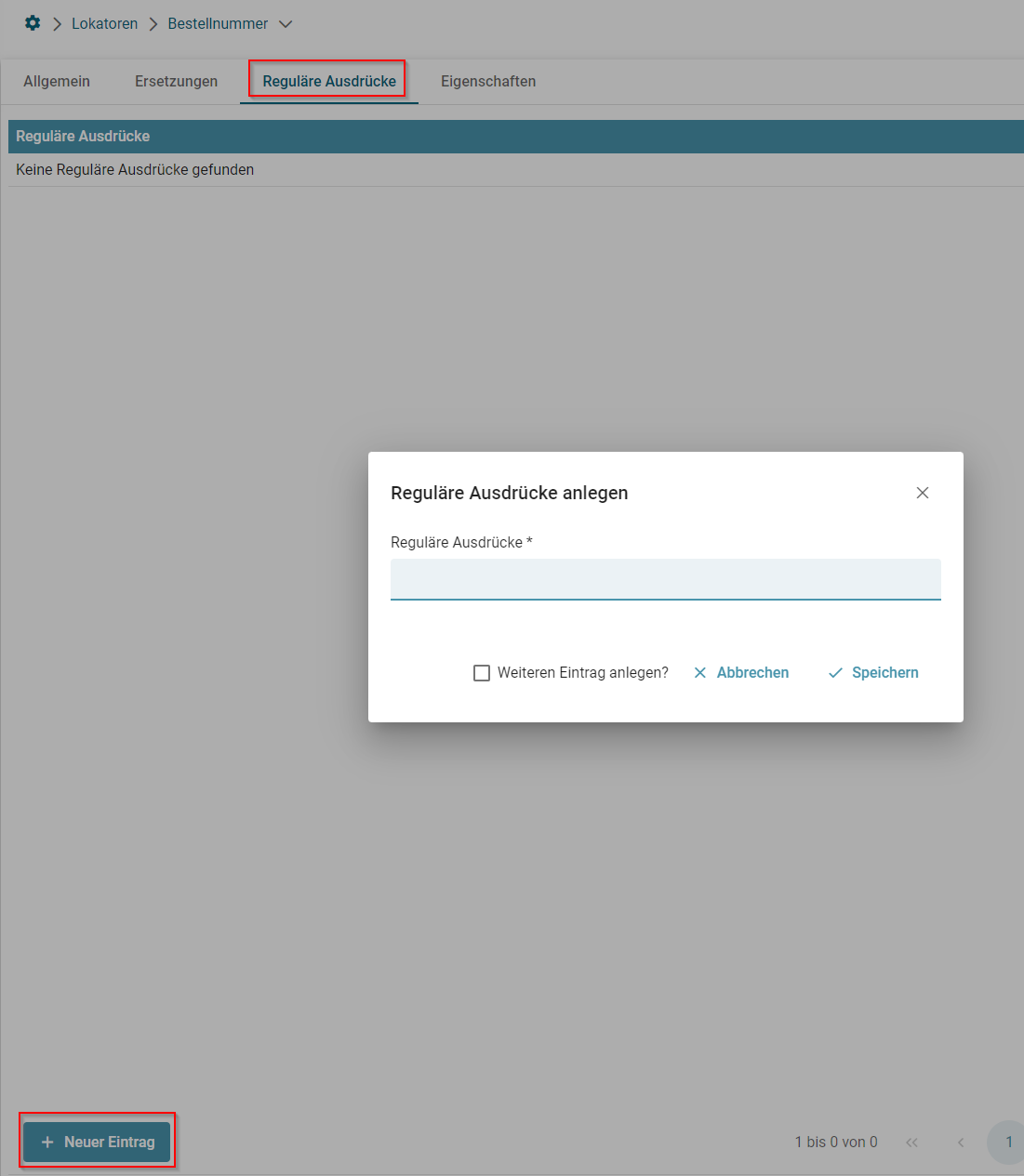
Der reguläre Ausdruck für eine freistehende 10 stellige Nummer könnte folgend konfiguriert werden: \b([0-9]{10})\b dann auf Speichern klicken.
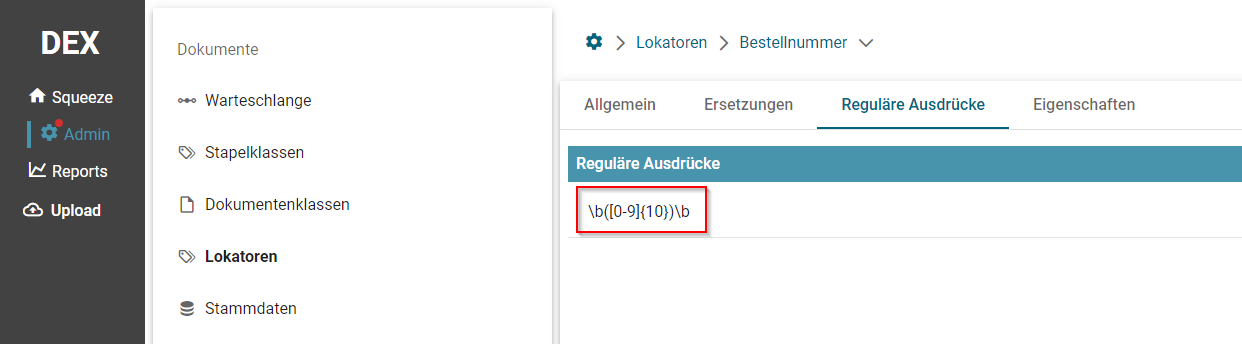
Wie dieser Lokator getestet werden kann finden Sie auf der Seite "Testen von Lokatoren".
Lokator: Search for DB linked data
Der Lokator DB-Link-Lokator (Search for DB linked data) findet auf Basis von konfigurierbaren Filtermerkmalen den Wert der für das entsprechende Feld vorgesehen ist. Mittels entsprechender Lokatoren für die Suche nach IBAN-Nummern, Umsatzsteuer-IDs, Steuernummern, Telefon - und Fax-Nummern, Email-Adressen oder Internet-Adressen wird in einer entsprechenden Datenbank nach passenden Einträgen gesucht und zu diesen Einträgen die Kreditor-Nummer zurückgegeben.
Konfiguration des DB-Link-Locators
Im folgenden gehen wir auf die beispielhafte Konfiguration eines Lokators ein, der zur Ermittlung von Kreditorennummern eingesetzt wird.
Der Lokator für die Suche nach Kreditorennummern mittels der Datenbank-Suche ist Bestandteil des ausgelieferten "Invoice Templates" und ist ein klassisches Beispiel für die Verwendung dieses Lokators bei Eingangsrechnungs-Erkennung.
Die Konfiguration wird analog zu allen anderen Lokatoren durchgeführt. Der Lokator Typ für den Db-Link-Lokator ist "Search for DB linked data" und muss über das Auswahlfeld innerhalb der Lokatoren-Konfiguration im Tab "Allgemein" ausgewählt werden.
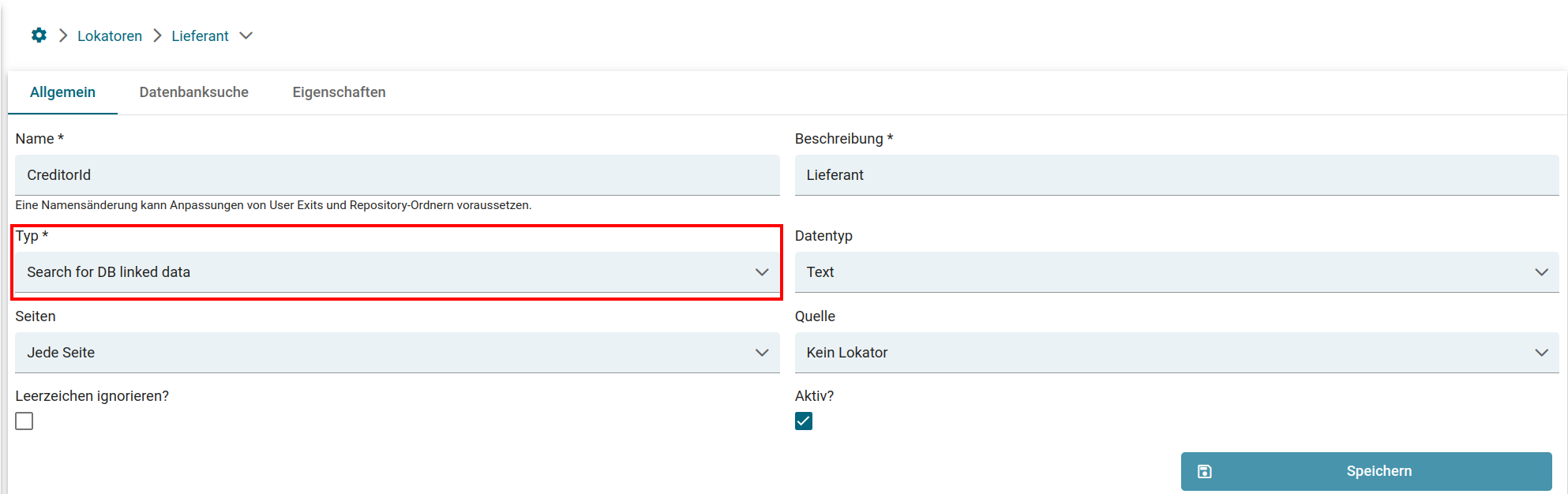
Wie man nun erkennt sind neben des Typen-Merkmals auch die weiteren allgemeinen Merkmale, entsprechend unseres Beispiels, eingepflegt
Um nun die Datenbanksuche und die Filtermerkmale zu konfigurieren müssen wir den Tab "Datenbanksuche" öffnen und die Stammdaten-Tabelle sowie die Ausgabespalte definieren.

Für die Umsetzung des konkreten Beispiels werden wir hier als Stammdaten-Tabelle die "Liste aller Lieferanten" wählen und die Ausgabespalte mit "Nummer" definieren. Auf die Konfigurationsmerkmale Filterspalte, Filterfeld und Filterlokator (ab Squeeze 2.5.0) gehen wir im Abschnitt Lokator-Filter weiter ein.
Im Unteren Abschnitt des Tabs "Datenbanksuche" können nun die ersten Filtermerkmale(Quell-Lokatoren), im Tabellenabschnitt, konfiguriert werden:
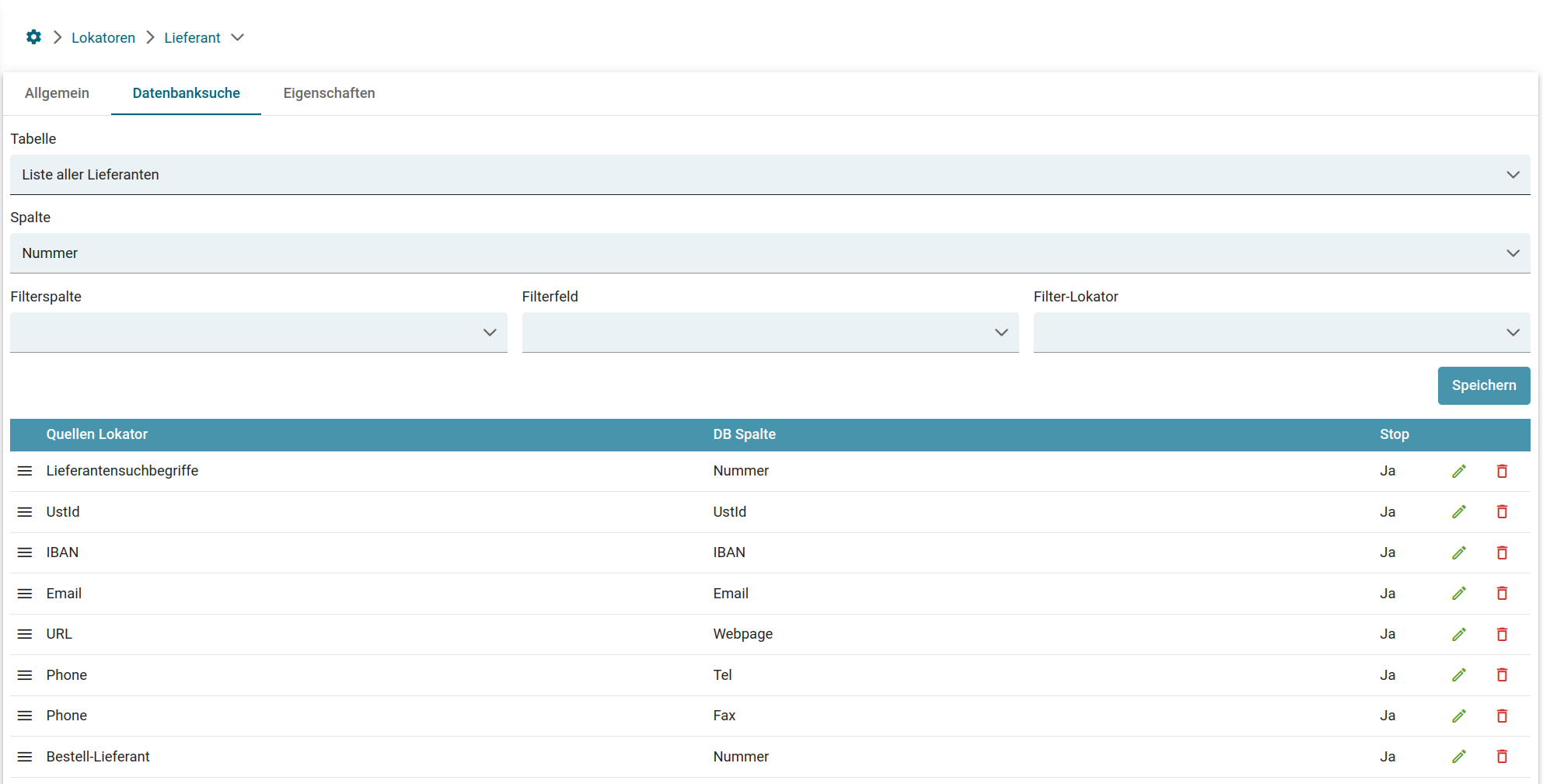
| Source Lokator (Quell-Lokator) | DB-Spalte der ausgewählten DB | Stop-Kennzeichen |
| UstId (Lokator für die Ermittlung von Umsatzsteuer-IDs) | EUTaxId | Nein |
| IBAN (Lokator für die Ermittlung von IBANs) | IBAN | Nein |
| Email (Lokator für die Ermittlung von Emails) | Nein | |
| URL (Lokator für die Ermittlung von URLs) | Webpage | Nein |
| Phone (Lokator für die Ermittlung von Telefonnummern) | Phone | Nein |
| Phone (Lokator für die Ermittlung von Telefaxnummern) | Fax | Nein |
Die Such-Ergebnisse der Source-Lokatoren werden in der DB-Spalte der entsprechenden Datenbank gesucht und der Wert der Ergebnis-Spalte zurückgegeben.
Die Reihenfolge wie die Ergebnisse der Source-Lokatoren in der Datenbank gesucht werden, kann in der Liste via Drag & Drop geändert werden. Der oberste Eintrag wird zuerst gesucht, der unterste Eintrag zuletzt.
Für das Stop-Kennzeichen kann entweder ja oder nein ausgewählt werden. Ja bedeutet, wenn nur ein Ergebnis in der Datenbank gefunden wird, wird der Wert der konfigurierten Ergebnis-Spalte zurückgegeben und die Suche beendet. Nein bedeutet, unabhängig ob es Treffer in der Datenbank gibt, es wird immer mit dem nächsten Lokator in der Liste weiter gesucht.
Für die IBAN bedeutet diese Konfiguration, alle via IBAN-Lokator gefundenen IBANs werden in der Datenbankspalte IBAN gesucht, wenn eine oder mehrere passende IBANs gefunden werden, werden die Kreditor-IDs dieser Zeilen zurückgegeben.
Mit dem Symbol "Neuer Eintrag" können weitere Lokatoren die bereits konfiguriert sind, ausgewählt und hinzugefügt werden.
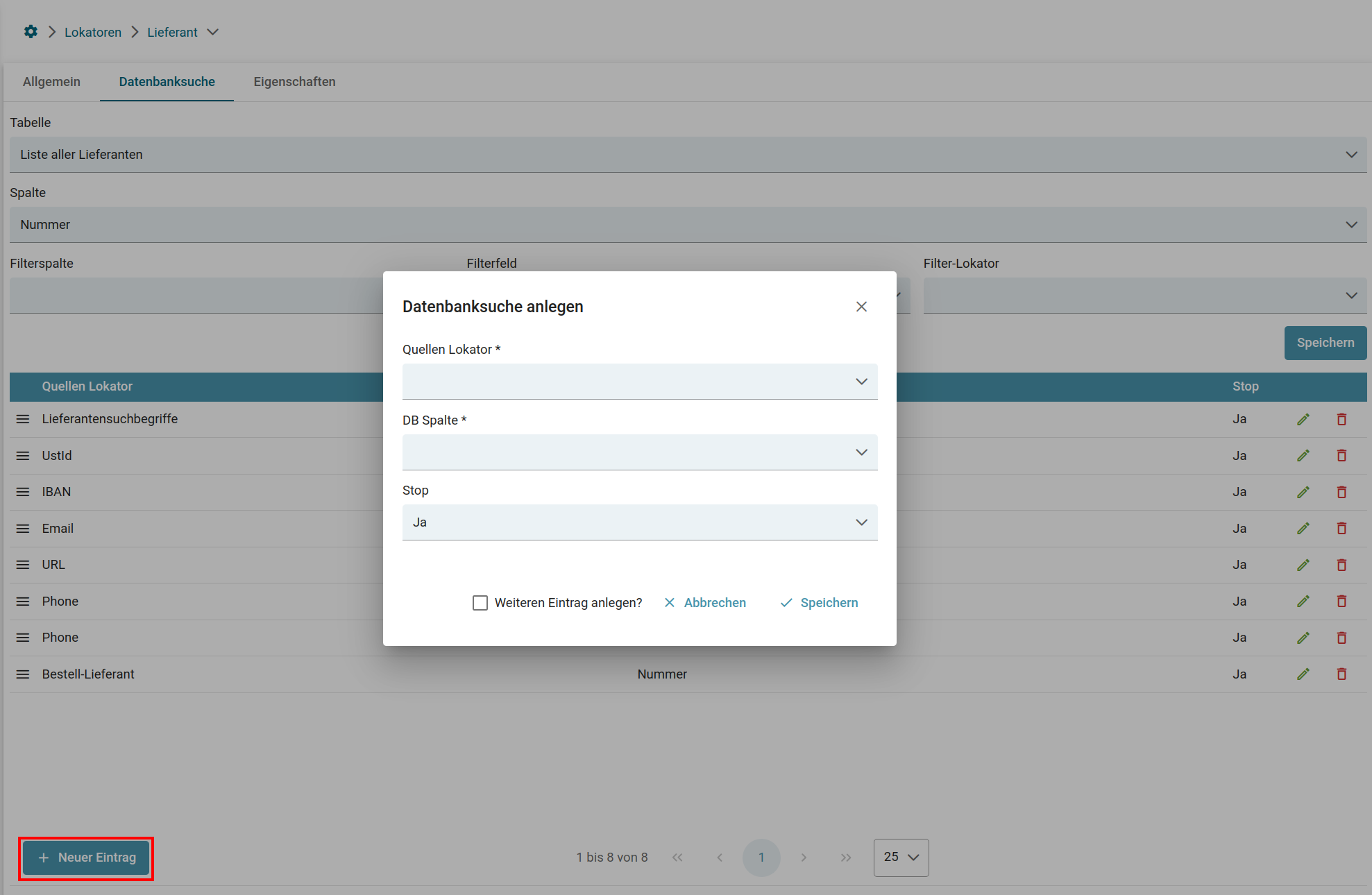
- das Feld "Quellen-Lokator" ist ein Auswahlfeld mit allen Lokatoren die konfiguriert sind
- das Feld "DB Spalte" gibt an in welcher Datenbankspalte das Lokatorergbnis in der Tabelle gesucht werden soll
- für das Feld "Stop" kann ja/nein gewählt werden und bestimmt ob die weitere Suche nach einem eindeutigen Treffer fortgeführt werden soll, wenn ein Wert für das Filtermerkmal "Quellen-Lokator" gefunden wurde.
Verwendungsmöglichkeit als Datenbank-Plausibilisierung
So könnte man zum Beispiel unter Verwendung anderer Lokatortypen wie:
folgende eindeutigen Werte auf dem Dokument ermitteln:
- Bestell-Nummern,
- Lieferschein-Nummern,
- Auftrags-Nummern,
- Mandanten-Namen
und als Quell-Lokatoren in dem Tabellenabschnitt des DB-Link Lokators hinzufügen.
In dem folgenden Beispiel, wird die mittels eines regulären Ausdrucks ermittelte Bestellnummern, gegen eine Datenbank mit entsprechenden Bestellnummern plausibilisiert.
Regex-Lokator für Erkennung der Bestellnummer (10-stellig numerisch) mittels regulärem Ausdruck:
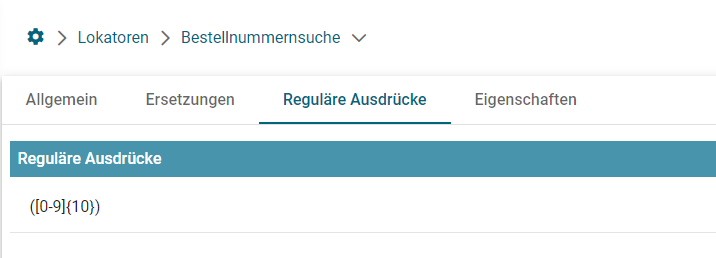
DB-Link Lokator für die Plausibilisierung der erkannten Bestellnummer gegen eine Datenbank:
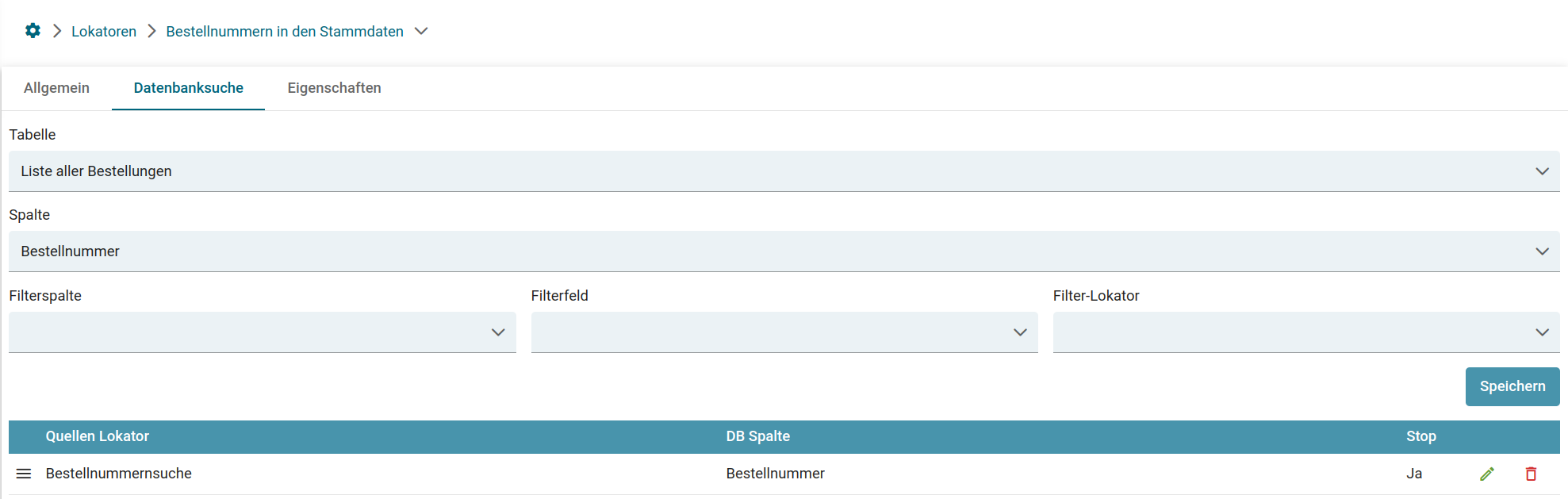
Lokatorenfilterung (ab Squeeze 2.5.0)
Der DB-Link-Lokator bietet ab der Version 2.5.0 drei neue Filtermerkmale um die Datenbankeinträge die zu Prüfen sind vorab einzugrenzen. Unter dem Tab "Datenbanksuche" können nun die drei neue Merkmale zur Filterung definiert werden.
- Filterspalte
- die Datenbank Spalte die als Basis des Vergleichs herangezogen wird
- Filterfeld
- das Dokumentenklassen-Feld das verwendet werden soll, um auf die Filterpalte zu vergleichen
- Filter-Lokator
- ein bereitsbestehender Lokator der ebenfalls verwendet werden soll, um auf die Filterspalte zu vergleichen
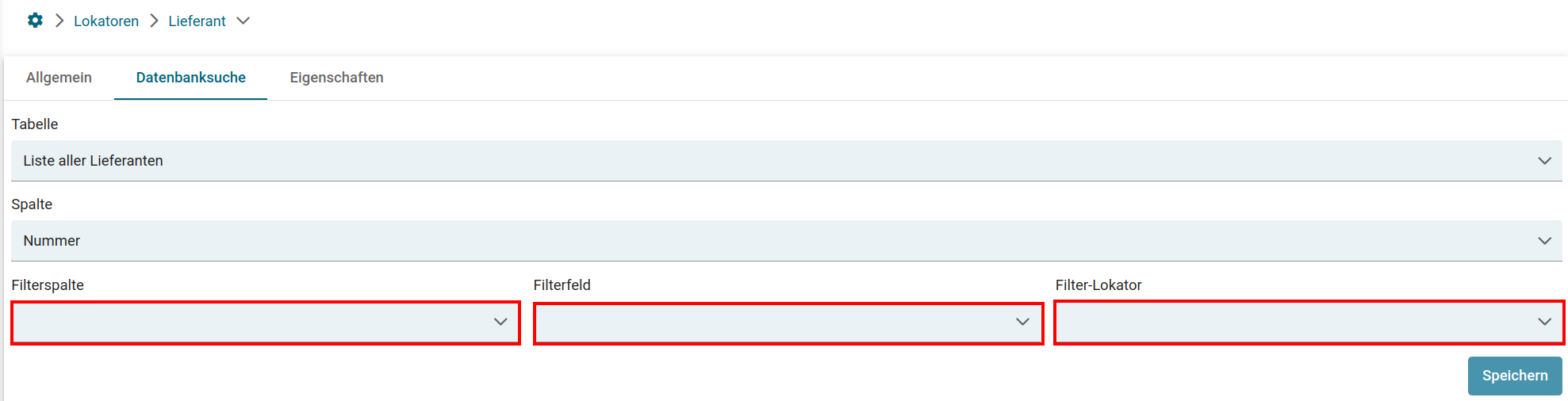
Folgendes Beispiel beschreibt die Formel für eine erfolgreiche Datensatz Identifizierung:
| Filtermerkmal-Ergebnis | Filtermerkmal |
| A | Filterspalte |
| B | Filterfeld |
| C | Filter-Lokator |
Formel: Wahr wenn: A = B = C
Alle Ergebnisse die dieser Formel entsprechen können nun durch die weiteren Quell-Lokatoren Filter validiert werden. Ein konkretes Beispiel wie man mit diesem Filter umgehen kann finden Sie hier.
Lokator: Search for line items
Der Lokator Search for line items findet Positionszeilen auf Dokumenten anhand entsprechender Spalten-Überschriften und unter diesen Spalten befindlichen Werten.
Wir bitten darum die die Seite Unterschiede zu Squeeze 1 (Lokatoren) aufmerksam zu lesen, wenn Sie bereits mit Squeeze 1 (der alten Benutzeroberfläche) arbeiten / gearbeitet haben.
Die Suche nach Positionen ist im ausgelieferten Invoice-Template bereits konfiguriert.
Die Positions-Suche in Squeeze benötigt entsprechende Lokatoren mit deren Hilfe die Spaltenüberschriften der Positions-Tabelle gefunden werden.
Funktionsweise
Die Erkennung von Tabellen mittels dieses Lokators funktioniert in folgenden Schritten:
- Spalten der Tabelle werden über ihre Überschriften ermittelt (nutzt Überschriften-Lokator)
- Werte werden innerhalb der gefunden Spalten gesucht (nutzt Wert-Lokator)
- Gefundene Werte werden zu Zeilen zusammengefasst
Schrittweise Konfiguration
Zur Konfiguration einer Positionserkennung gehören folgende Punkte.
1. Überschriften & Wert-Lokatoren
Sowohl die Überschriften, als auch die Werte werden über normale Lokatoren gefunden. Hier bietet sich bspw. ein "Regular Expression"-Lokator an.
Für jede zu extrahierende Spalte wird also 1 Überschriftenlokator und 1 Wert-Lokator benötigt.
2. Tabelle inkl. Tabellen-Spalten konfigurieren
Als nächstes müssen die Lokatoren an den Tabellen-Spalten konfiguriert werden.
Sollte bis jetzt noch gar keine Tabelle an der zu extrahierenden Dokumentenklasse existieren, dann muss diese zuerst inkl. Spalten konfiguriert werden.
An jeder Tabellenspalte kann 1 Überschriftenlokator und 1 Wert-Lokator konfiguriert werden.
3. Verknüpfung von Tabelle und Tabellen-Lokator (Search for line items)
Zuletzt muss ein Tabellen-Lokator (Search for line items) konfiguriert werden. Diese Konfiguration geschieht an zwei Stellen:
- An der Tabelle muss der angelegte Lokator ausgewählt werden.
- Am Lokator muss die Tabelle ausgewählt werden, für welche der Lokator extrahieren muss.
Achtung: Aktuell kann ein Tabellen-Lokator (Search for line items) nur für die Extraktion einer einzigen Tabelle eingesetzt werden.
D. h. für jede Tabelle (unabhängig davon, zu welcher Dokumentenklasse sie gehört), muss ein neuer Tabellen-Lokator eingerichtet werden.
Das gilt nicht für die Überschriften- und Wert-Lokatoren, welche wiederverwendbar sind.
Das folgende Screenshot zeigt eine Warnung im Konfigurations-Dialog einer Tabelle. Diese Warnung soll dabei helfen mögliche Fehlerquellen auszuschließen.
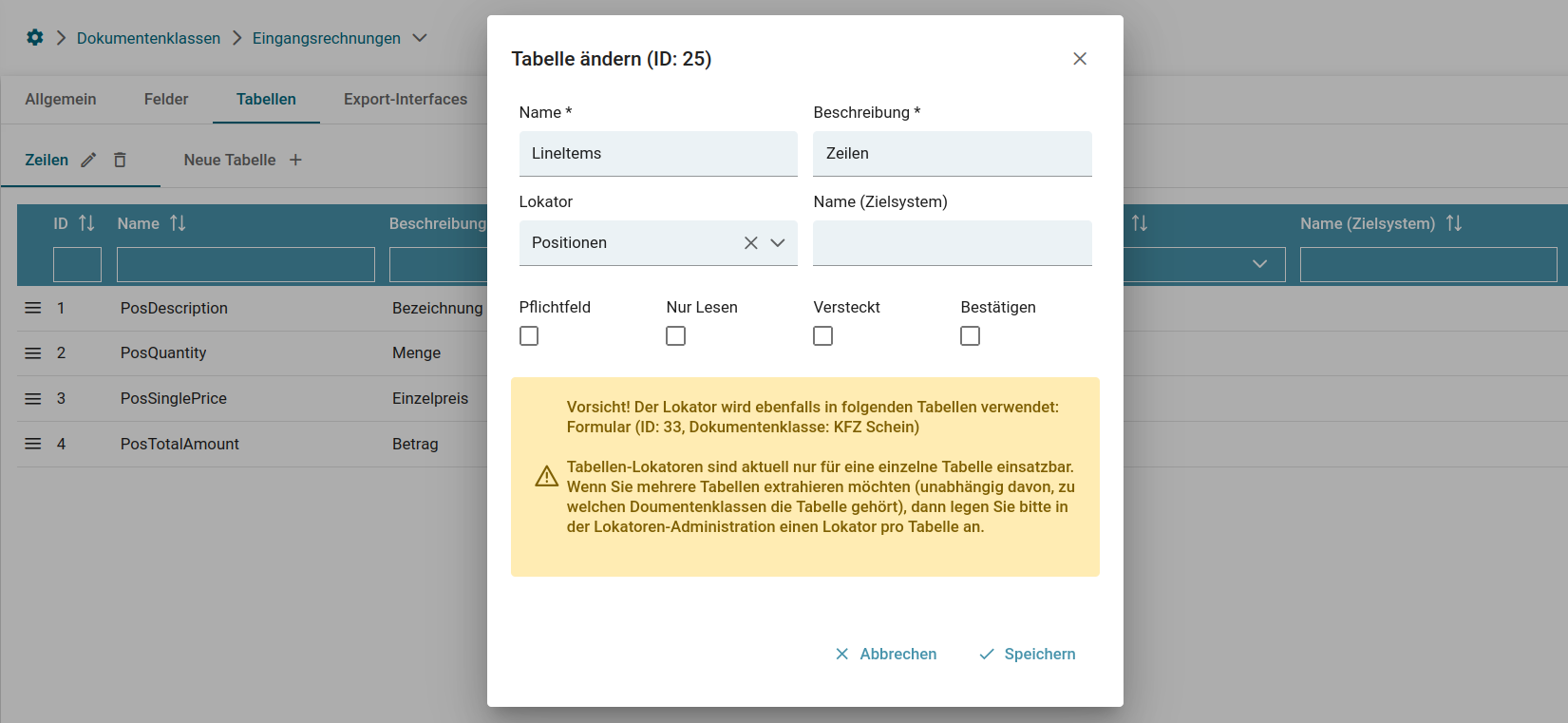
Beispiel: Konfiguration einer Standard-Positions-Suche für Eingangsrechnungen
Beispiel: Überschriften-Lokator für die Spalte Menge:
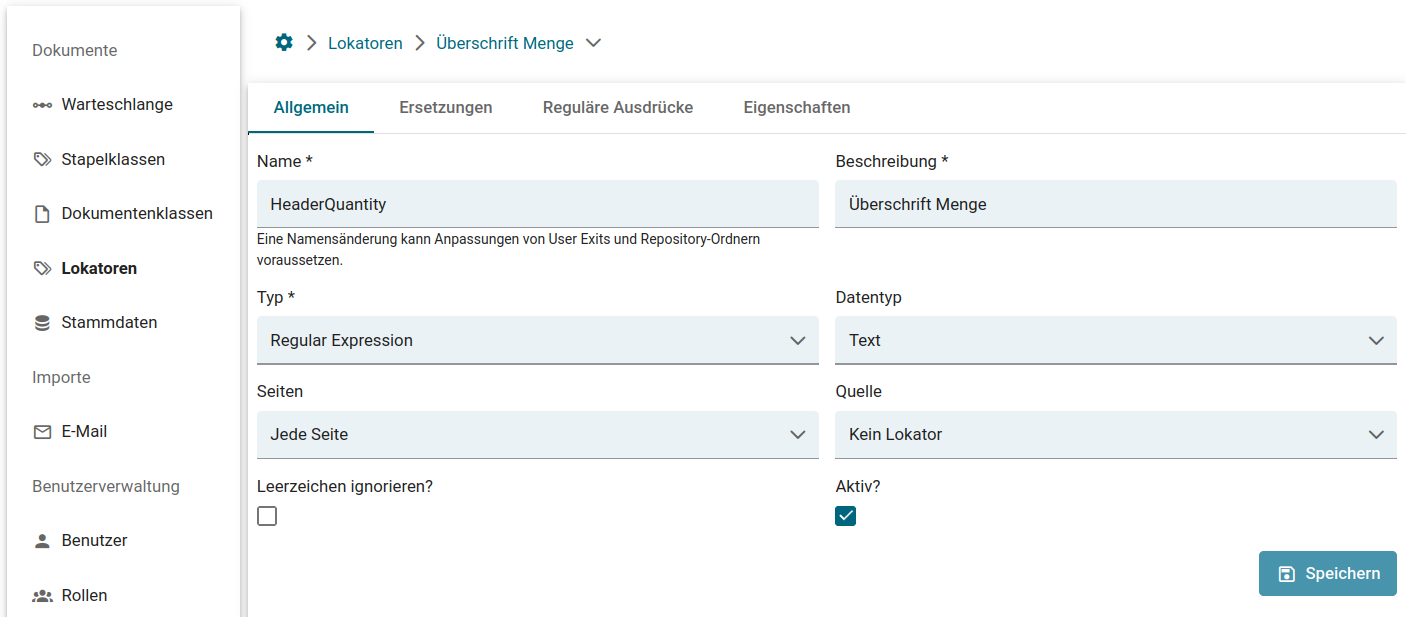
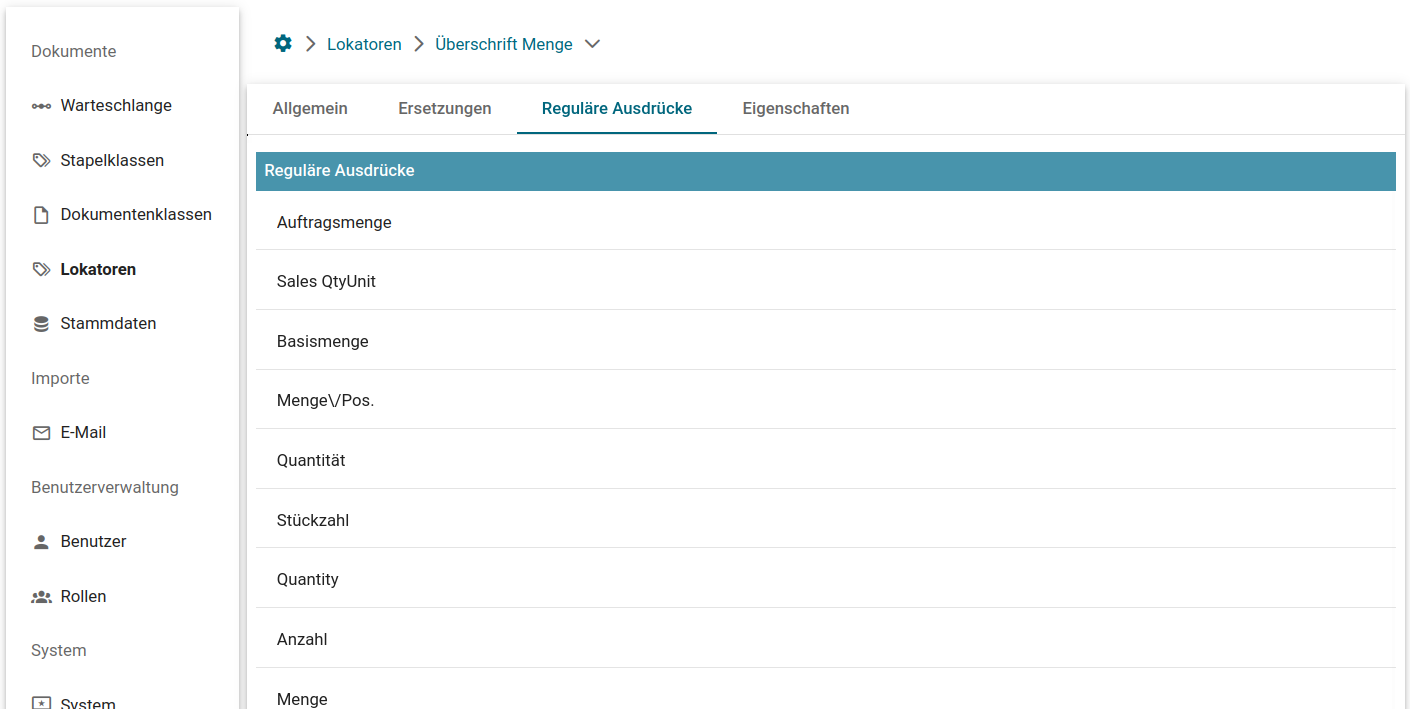
Überschriften-Lokatoren für andere Überschriften sind wie auf den dargestellten Bildern, normale Lokatoren, welche bspw. via regulärem Ausdruck die Überschriften finden.
Die konfigurierten Suchbegriffe können je nach Anwendungsfall entsprechend angepasst und/oder erweitert werden.
Beispiel: Verwendung der Überschriften- und Wert-Lokatoren an der Tabellenspalte Menge:
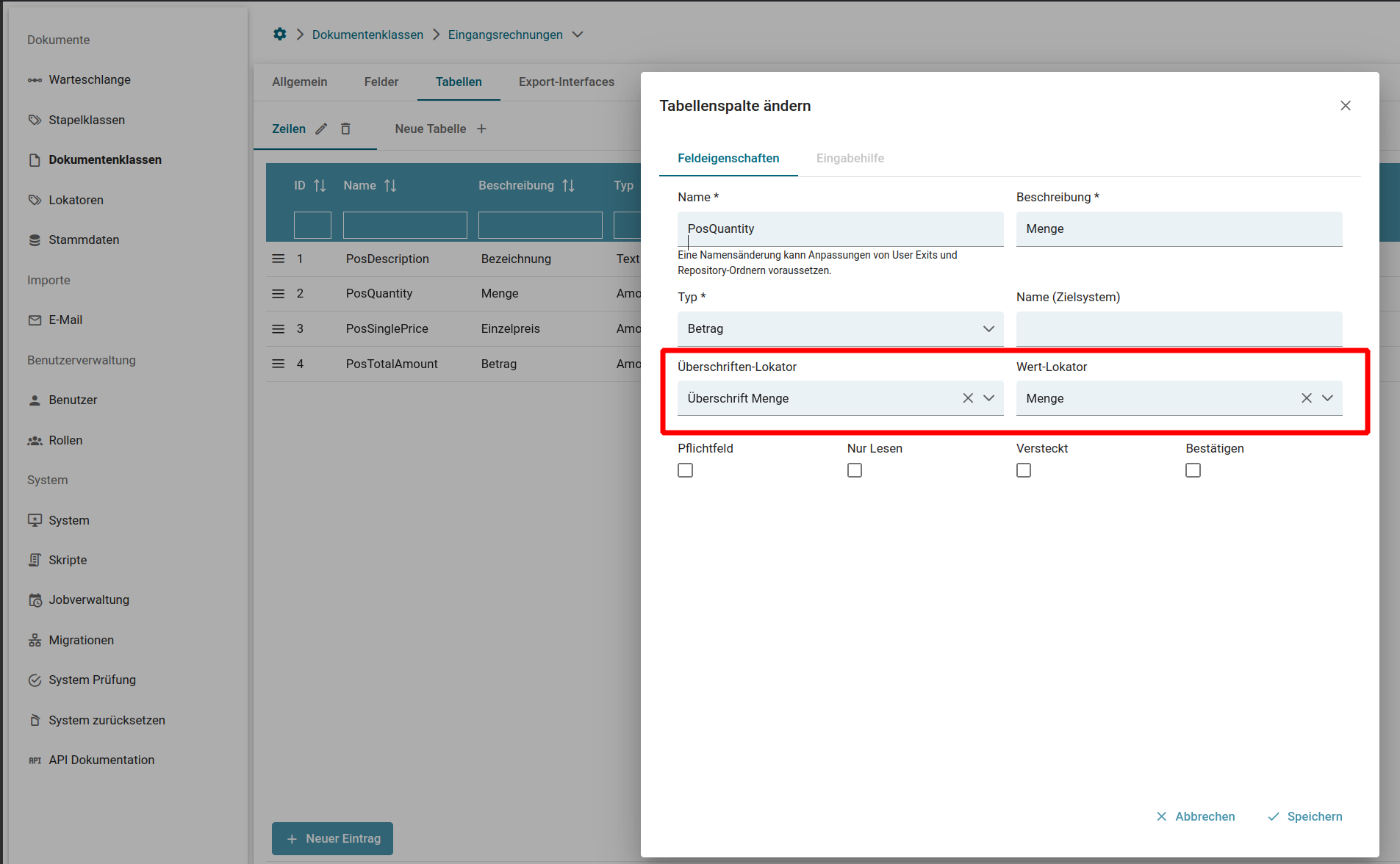
Beispiel: Verwenden des Tabellen-Lokators an der Tabelle
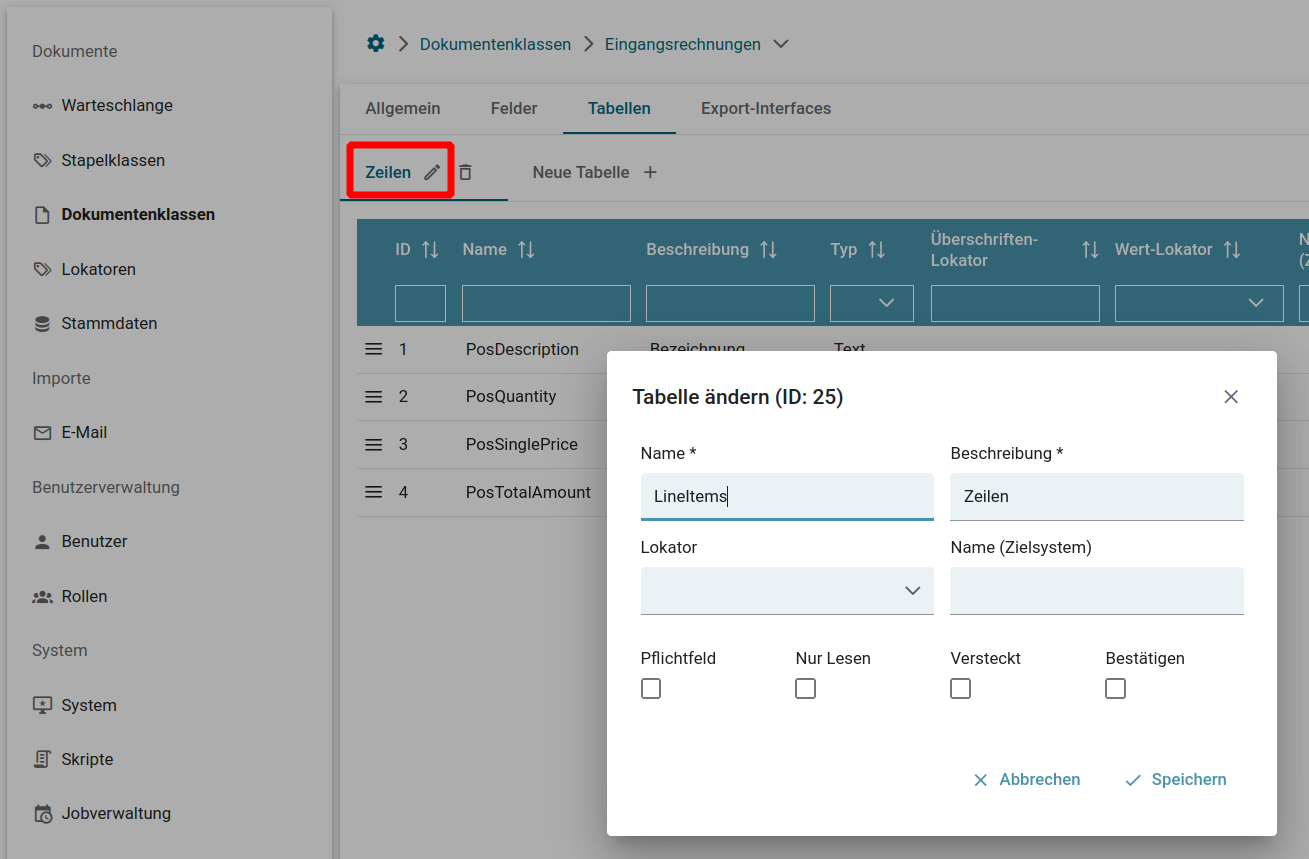
Lokator: Value next to KeyWord
Der Lokator Value next to KeyWord findet Schlüsselwörter und in der Nähe des Schlüsselwortes befindliche Reguläre Ausdrücke.
In der Nähe bedeutet, der Lokator sucht rechts neben dem Schlüsselbegriff und unter dem Schlüsselbegriff nach einem passenden regulären Ausdruck.
Ein klassisches Beispiel für diesen Lokator ist die Suche nach Rechnungsnummern auf einer Rechnung.
In der Konfiguration des Lokators gibt es einen Reiter für die Konfiguration der gewünschten Schlüsselbegriffe und einen Reiter für die regulären Ausdrücke.
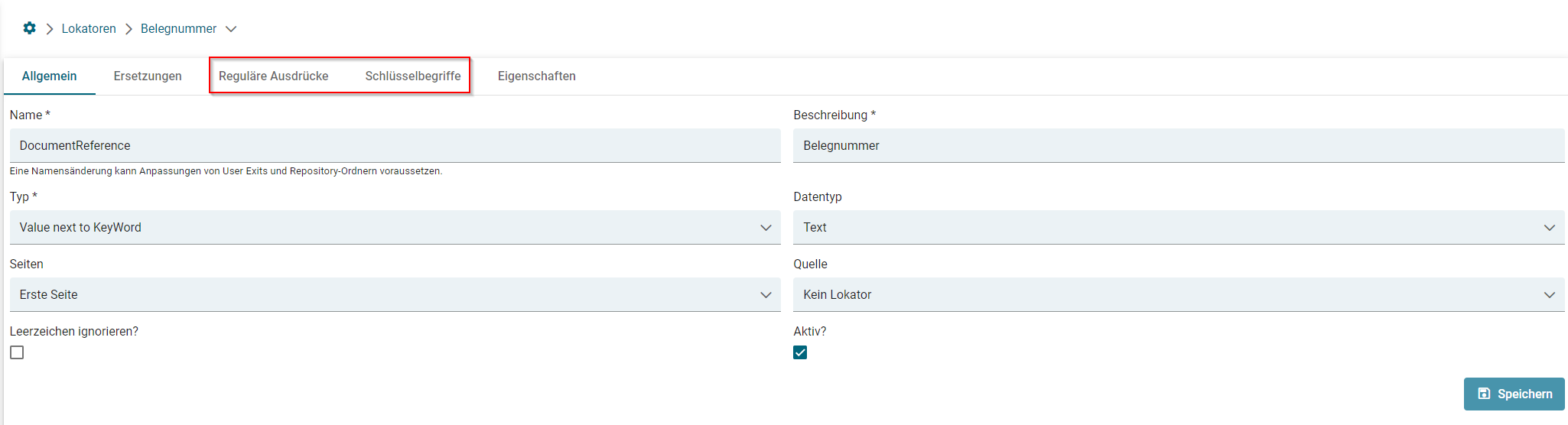
Die Konfiguration der der regulären Ausdrücke und der Schlüsselbegriffe ist analog zur Konfiguration der Lokatoren für KeyWords und des Lokators für reguläre Ausdrücke
Lokator: Value from Regular Expression
Der Lokator Value from Regular Expression sucht mit Hilfe regulärer Ausdrücke(regex) aus einer Stammdatentabelle in den OCR-Textzeilen des Dokumentes. Diese werden mittels der Stammdatentabelle auf einen bestimmen Wert(result) umgeschlüsselt.
Einrichtung eines Lokators Value from Regular Expression am Beispiel des Lokators "Lieferantensuchbegriffe"
Um ins Lokatoren-Menü zu gelangen Klicken Sie auf Admin und danach auf Lokatoren.
In der unteren Bildschirmleiste das Symbol "Neuer Eintrag" klicken um einen neuen Lokator anzulegen.
Weiter mit dem Beispiel "Lieferantensuchbegriffe"
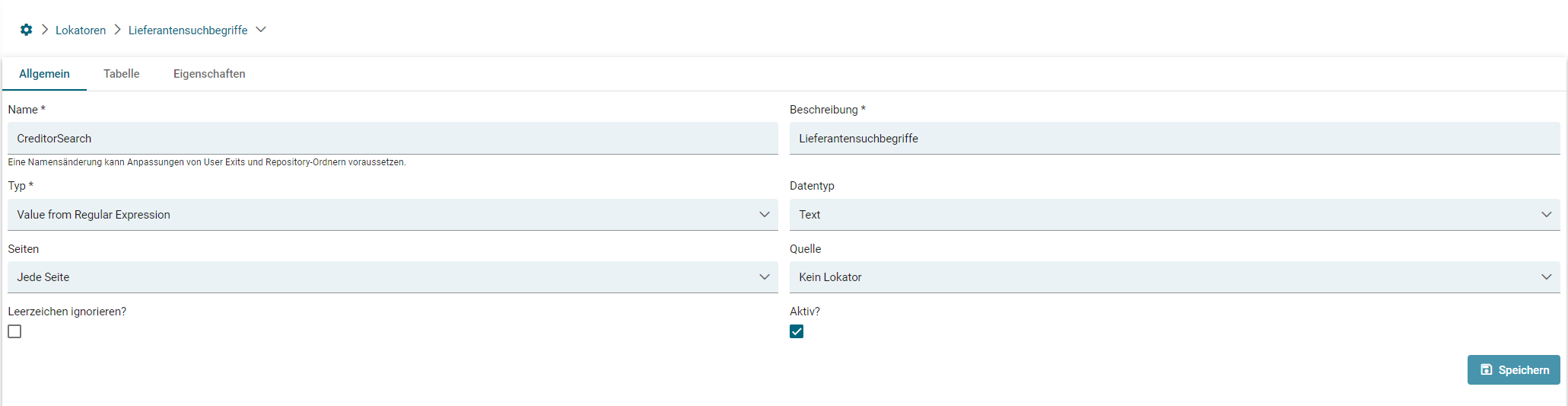
Im sich daraufhin öffnenden Dialog den technischen Namen(CreditorSearch), den Anzeige-Namen(Lieferantensuchbegriffe) des neuen Lokators angeben und den Lokator auf Aktiv setzen. Den Lokator-Typ Value from Regular Expression auswählen und danach den Lokator speichern.
Im Reiter "Tabelle" wird nun die Stammdatentabelle ausgewählt, in der sich die Regulären Ausdrücke(regex) und die Übersetzungswerte(result) befinden. In diesem Beispiel "creditorsearch".
Informationen zur Anlage einer neuen Stammdatentabelle finden Sie im Kapitel "Stammdaten".

Die Verwendung des Lokators Value from Regular Expression ist auf einen bestimmten Aufbau der Spalten und ihrer Beschreibungen in der Stammdatentabelle angewiesen. Siehe Oben. Hierbei sind die Spalten(Name und Quelle) und ihre Einträge wichtig. Die Spaltennamen und Einträge müssen hierbei exakt übernommen werden. Die Spalte Beschreibung und ihre Einträge können je nach Funktion des Lokators variieren.

In den Spalten muss nun der zu übersetzende Wert(result) und das Muster(regex) eingetragen werden. In diesem Fall die Lieferantennummer "1234567890" und die URL "www.brt-gmbh.de". Mehr Informationen zu Regular Expressions finden Sie im Kapitel Lokatoren.
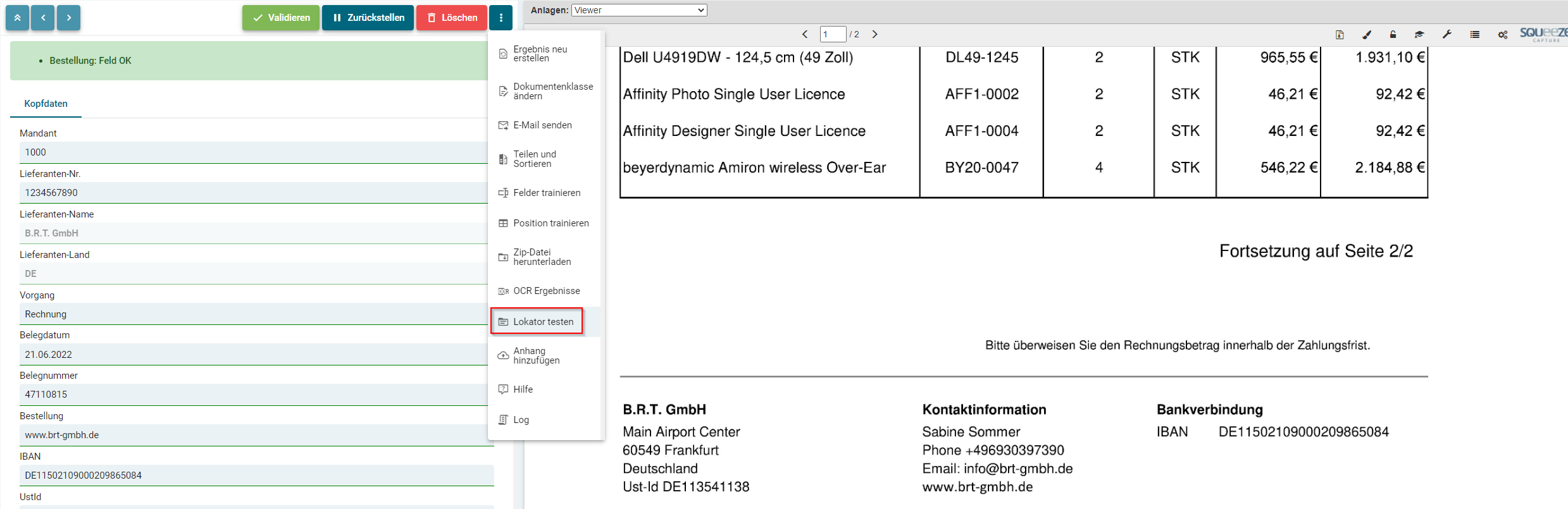
Über "Lokator testen" kann nun der Lokator und seine Übersetzung getestet werden.
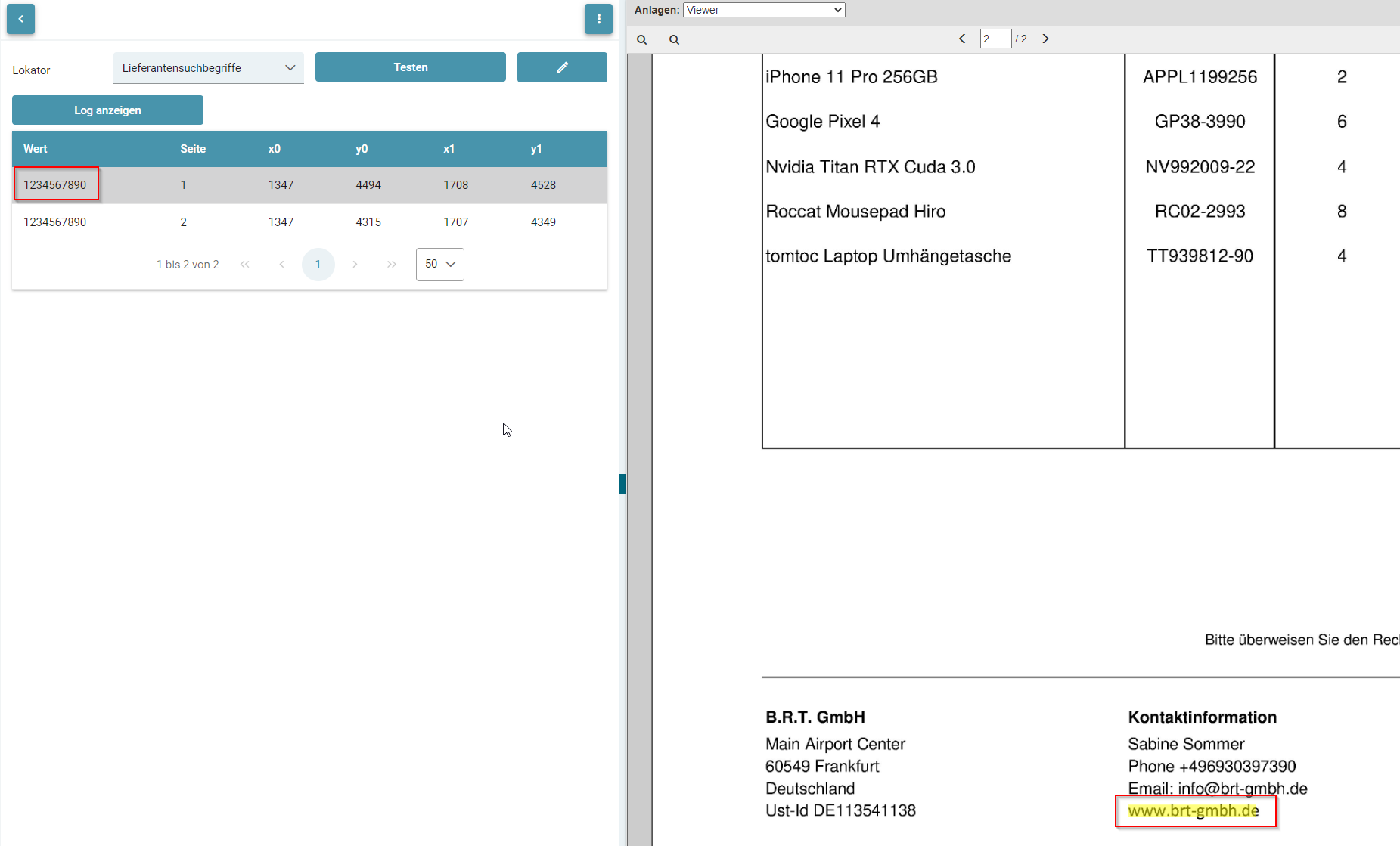
Oben sehen wir nun das die URL(regex) auf die Lieferantennummer(result) übersetzt wurde.
Falls Sie unsicher bei der Erstellung von Regulären Ausdrücken sind, finde Sie hier eine Seiter auf der Sie Ihre Regulären aAsudrücke testen können: https://regex101.com/
Unterschiede zu Squeeze 1
Diese Seite beschreibt relevante Unterschiede zwischen der Extraktion mittels Lokatoren zwischen Squeeze 1 und Squeeze 2.
Globale Lokatoren
In Squeeze 1 wurden Lokatoren immer als Teil einer Dokumentenklasse konfiguriert. Das hatte zur Folge, dass Lokatoren nur in ihrer Dokumentenklasse genutzt werden konnten. Wenn ein System über mehrere Dokumentenklassen verfügt hat, so mussten übliche Lokatoren (Email / IBAN usw.) in jeder Dokumentenklasse erneut angelegt werden.
In Squeeze 2 hingegen werden Lokatoren unabhängig von der Dokumentenklasse verwaltet. Somit ist es möglich, dass bspw. nur ein einziger IBAN-Lokator zu konfigurieren ist und dieser in beliebig vielen Dokumentenklasse wiederverwendet werden kann.
Diese Änderung gilt im Prinzip für alle Lokatoren. Der Tabellen-Lokator (Search for line items) hingegen ist der einzige Lokator, bei welchem diese Umstellung aktuell (Q3 2022) nur teilweise zutrifft.
Besonderheit Tabellen-Lokator (Search for line items)
Zusammenfassung / TLDR:
- Der Tabellen-Lokator (Search for line items) ist aktuell nicht global.
- Für jede zu extrahierende Tabelle muss ein eigener Tabellen-Lokator konfiguriert werden.
- Überschriften- und Wert-Lokatoren von Tabellen können mehrmals verwendet werden.
Kontext
Wie in Globale Lokatoren beschrieben sind Lokatoren global, d. h. sie können mehrfach in unterschiedlichen Dokumentenklassen für diverse Felder wiederverwendet werden. Bei der Extraktion von Tabellen mittels des Tabellen-Lokators (Search for line items) allerdings trifft diese Umstellung nur teilweise zu.
Falls Sie nur wissen möchten, wie die Positionserkennung zu konfigurieren ist, dann lesen Sie bitte die Dokumentation zum entsprechenden Lokator. Dort haben wir dokumentiert, wie in Squeeze 2 das System zu konfigurieren ist.
Andernfalls wird im Folgenden erläutert, wie sich die Konfiguration zwischen Squeeze 1 und 2 unterscheidet, damit Administratoren die Umstellung einfacher fällt.
Funktionsweise des Lokators
Zuerst muss die Funktionsweise des Lokators (egal ob Squeeze 1 oder 2) verstanden werden. Vereinfacht arbeitet der Tabellen-Lokator in folgenden Schritten:
- Spalten der Tabelle über ihre Überschriften finden (nutzt Überschriften-Lokator)
- Werte innerhalb der gefunden Spalten finden (nutzt Wert-Lokator)
- Gefundene Werte zu Zeilen zusammenfassen
Wichtig ist hierbei zu verstehen, dass der Lokator also auf Basis von Überschriften- und Werte-Lokatoren arbeitet. Aus diesem Grund, muss der Tabellen-Lokator wissen, für welche Tabelle dieser ausgeführt wird, um dann wiederum über die Tabellen-Spalten der Tabelle zu erfahren, welche Überschriften- und Werte-Lokatoren zu nutzen sind.
Der Tabellen-Lokator ist nicht global
Die beschriebene Funktionsweise des Tabellen-Lokators setzt voraus, dass bei diesem konfiguriert werden muss, für welche Tabelle dieser ausgeführt wird.
Während das aus funktionaler Sicht kein Problem darstellt, ist der Lokator allerdings somit der einzige Lokator, welcher de facto nicht global einsetzbar ist, was bei der Konfiguration zu Irritation führen kann:
Während alle anderen Lokatoren wiederverwendet werden können, muss für die Extraktion einer Tabelle je ein eigener Tabellen-Lokator genutzt werden.
Roadmap bzgl. der Positionserkennung
Abschließend sei erwähnt, dass die Besonderheit des Positionslokators bekannt ist und das Konzept auch zukünftig überarbeitet werden soll. Ziel dabei soll ist die Einfachheit und Nachvollziehbarkeit der Konfiguration.
Änderungen an dem System werden entsprechend in der Dokumentation (insbesondere Lokator: Search for DB linked data) fortlaufend festgehalten.
Swiss QR-Code
Um einen QR Code Lokator anzulegen, welcher Schweizer QR-Codes auszulesen, kann man einen neuen Lokator von Typen "Swiss QR Code" anlegen.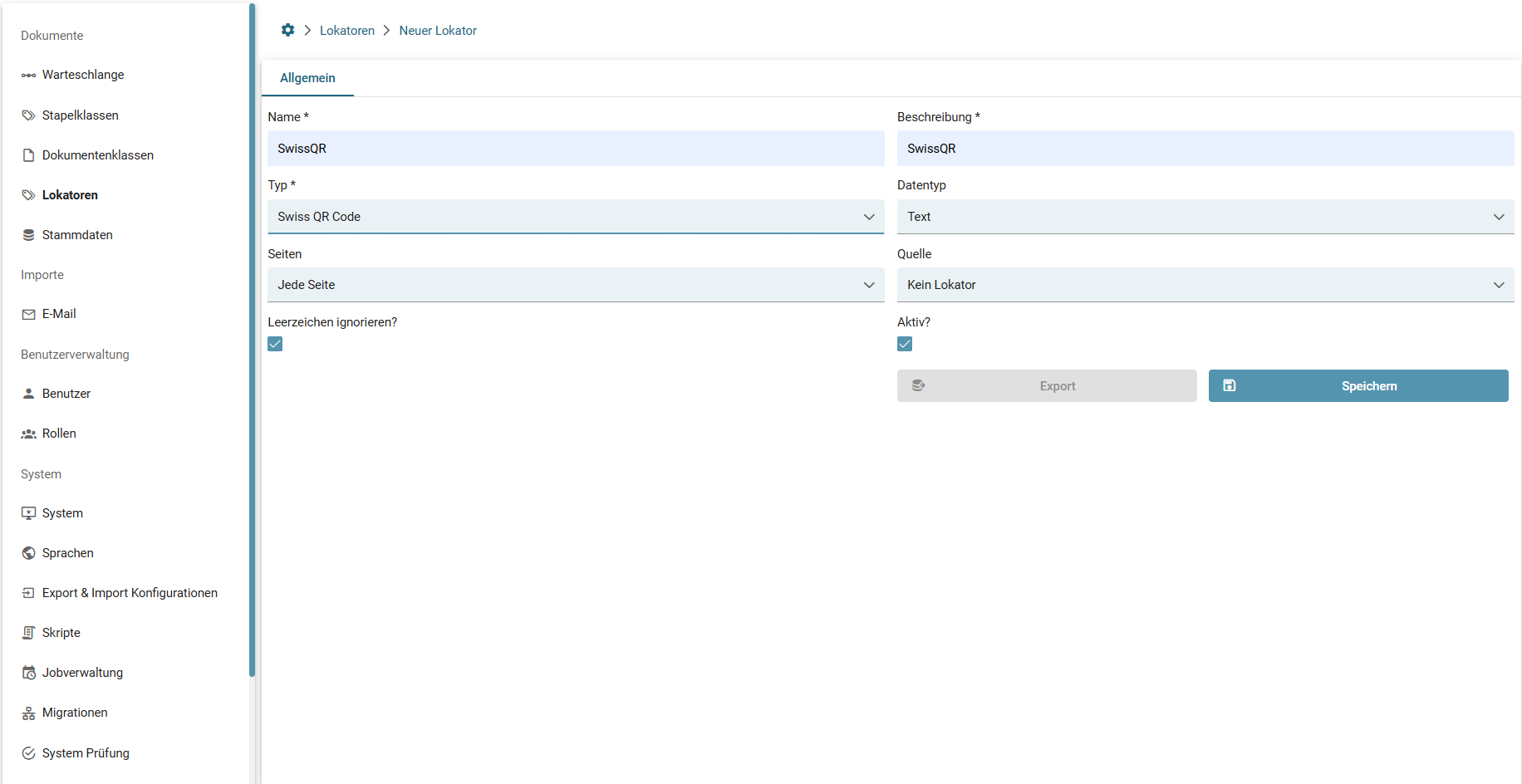 Dann in den Lokator Eigenschaften einen neuen Eintrag anlegen und Barcode Engine auswählen und den Wert "SOFTEK" eintragen.
Dann in den Lokator Eigenschaften einen neuen Eintrag anlegen und Barcode Engine auswählen und den Wert "SOFTEK" eintragen.
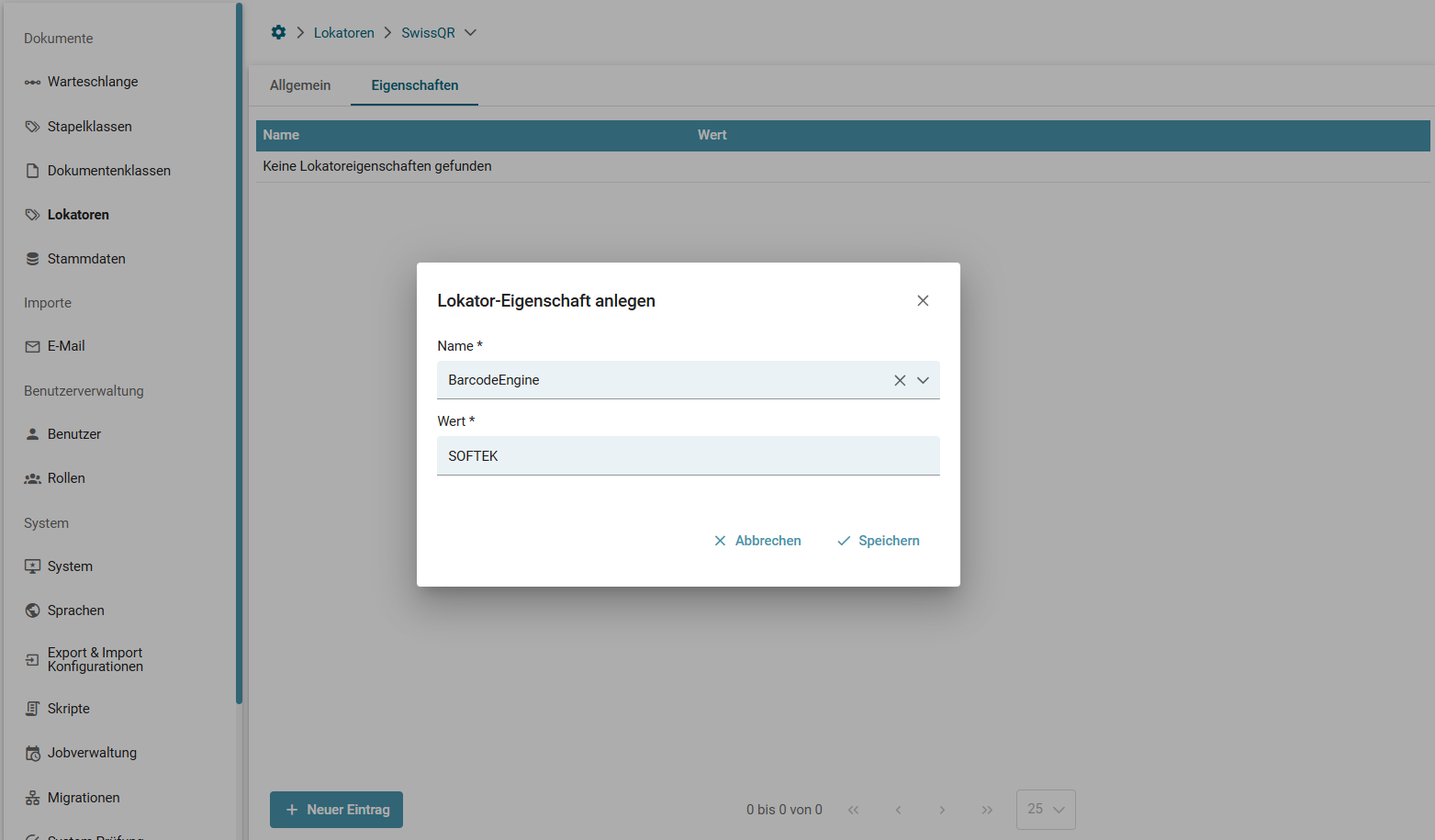
In der Dokumentenklasse muss dann ein Feld "SwissQrCode" angelegt werden und als Lokator den vorher erstellen "SwissOR" Lokator einstellen.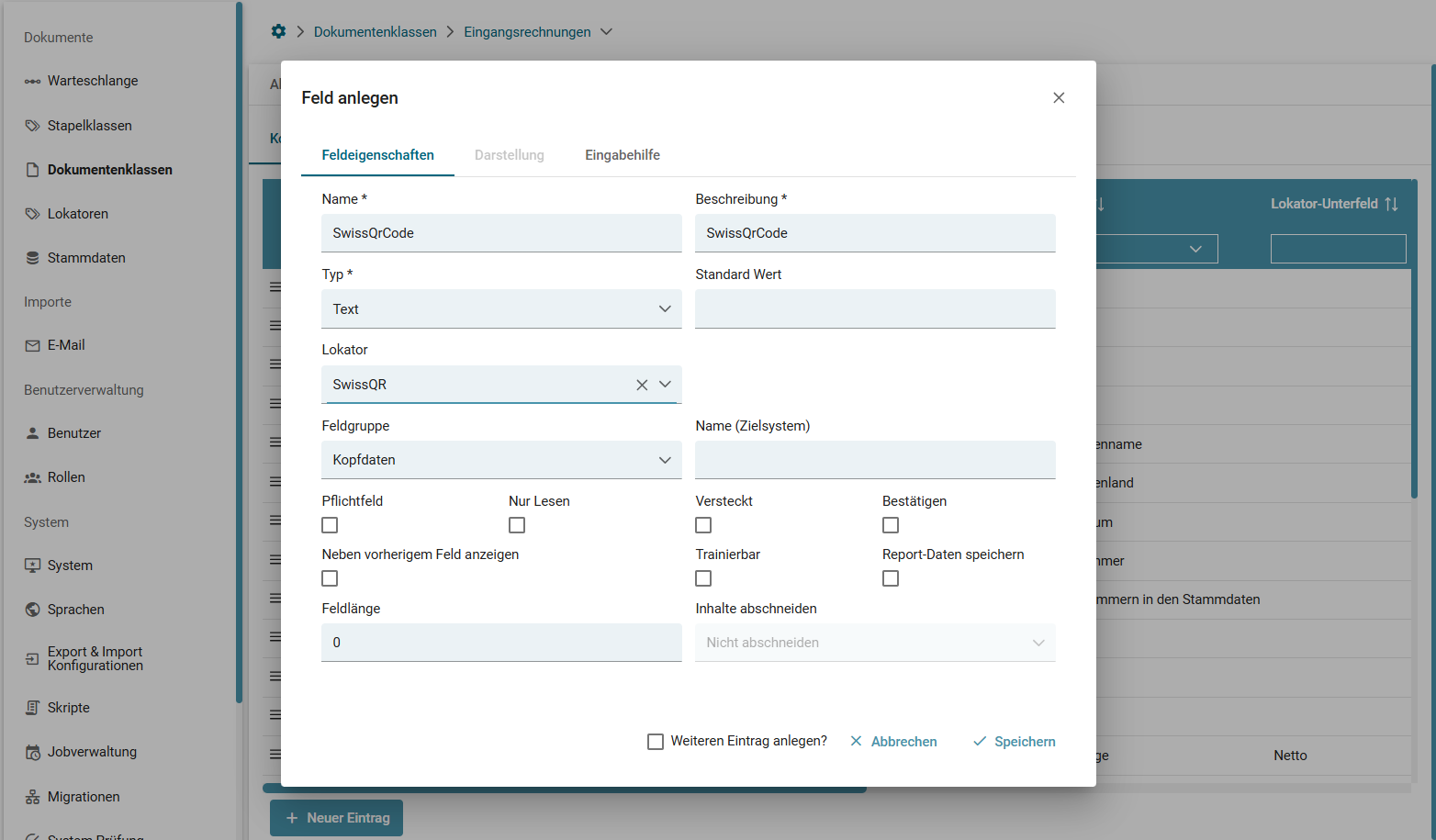
Folgenden Werte werden automatisch aus dem Swiss QR-Code gewonnen:
- IBAN
- Currency (Währung)
- TotalAmount (Brutto)
Zusätzlich kann ein Feld mit dem technischen Namen "PaymentReference" angelegt werden, welcher die Zahlungsreferenz automatisch ausließt.
Validierung
Konfiguration rund um die Validierung
Autovalidierung
Die Autovalidierung ist ein Feature, mit welchem der Validierungsschritt (teil-) automatisiert werden kann.
Verhalten
Die Autovalidierung findet in der Verarbeitungskette von Squeeze nach der Extraktion und der Validierung statt. Fall sie aktiviert ist, validiert Squeeze automatisch die Inhalte eines Dokumentes. Bspw. wird geprüft, ob Pflichtfelder gefüllt sind.
Die Feld-Konfiguration Bestätigungsfeld wir in der Autovalidierung übersprungen. Das gilt für jegliche interaktive Interaktionen in der Standard-Validierungsoberfläche.
,Falls alle Validierungen erfolgreich sind, wird die manuelle Validierung übersprungen und das Dokument direkt exportiert. Falls nicht, wird das Dokument mit einem Fehler in den Validierungsschritt versetzt.
Konfiguration
Verwenden Sie die Stapelklasseneigenschaft ExportAfterExtraction um die Autovalidierung für alle Dokumente einer Stapelklasse zu aktivieren.
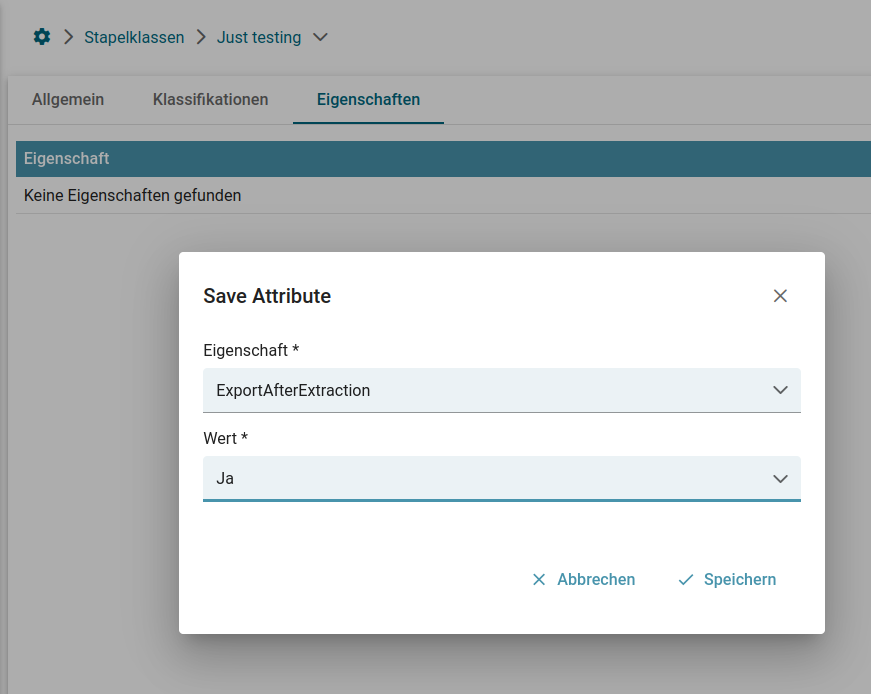
Asynchroner Dokumenten-Export nach manueller Validierung
Diese Funktion steht ab Squeeze 2.12 zur Verfügung.
Funktion
Bei einigen Export-Schnittstellen kann es vorkommen, dass der Export zum Ziel-System länger als einige wenige Sekunden braucht. Sollte dies bei Ihrem System auftreten, bringt das den Nachteil mit sich, dass Validierer nach dem Validieren eines Dokumentes lange warten müssen, bevor das nächste Dokument bearbeitet werden kann.
Zu diesem Zweck ist es möglich den Dokumenten-Export im Hintergrund (also asynchron) durchführen zu lassen. Wenn Sie diese Funktion aktivieren, dann werden Dokumente nach dem Validieren in die Warteschlange versetzt und werden so früh wie möglich durch einen Worker exportiert.
Sollte beim Export ein Fehler auftreten, wird das Dokument mit dem Fehlerzustand zurück in den Validierungsschritt versetzt.
Diese Funktion bringt Vor- und Nachteile mit sich:
- Vorteile
- Validierer können direkt das nächste Dokument bearbeiten und müssen weniger Zeit mit Warten verbringen.
- Nachteile
- Sollten Fehler beim Export auftreten, sind diese nicht direkt beim Validieren sichtbar.
Zusammenfassung: Der asynchrone Export nach der manuellen Validierung verhindert Wartezeiten beim Validieren.
Konfiguration
Wenn Sie die Funktion nutzen möchten, gibt es 2 Dinge zu tun:
- Aktivieren Sie das zugehörige Feature Flag (s. Features verwalten) (Nur notwendig, wenn Sie selbst die Squeeze Installation verwalten)
- Aktivieren sie die zugehörige Stapelklasseneigenschaft (s. AsyncExportAfterValidation)
Stammdaten
Anleitungen zur Administration, Integration und Verwendung von Stammdaten.
Stammdaten
Stammdaten dienen in Squeeze zur Erkennung und Plausiblisierung von Merkmalen auf den jeweiligen Dokumententypen.
Stammdaten werden in Squeeze in der Datenbank als Tabelle angelegt. Dabei können beliebig viele unterschiedliche Spalten konfiguriert werden.
Es können unbegrenzt viele Stammdatentabellen angelegt werden.
Klassische Beispiele für Stammdatentabellen:
- Kreditoren
- Bestellnummern
- Mandanten
- Auftragsnummern
- Vertragsnummern
- ...
Squeeze kann die auf dem Dokument gefundenen Merkmale in den Stammdaten plausiblisieren und / oder auf zugehörige Werte umsetzen.
Die Stammdaten können auf verschiedene Art und Weise aktualisiert / gepflegt werden:
- Mittels File Upload
- Mittels HTTP-Schnittstelle
- Über die Benutzeroberfläche
In Sonderfällen ist auch der Import mittels Datenbank-Skript möglich, allerdings nicht im Standard-Cloudbetrieb.
Anlegen einer neuen Stammdatentabelle im Webclient
Das Anlegen einer neuen Stammdatentabelle in Squeeze muss initial via CSV-Upload aus dem Webclient erfolgen.
Beim Klick auf den Reiter Stammdaten öffnet sich der Dialog für die Stammdatenkonfiguration.
Die Oben aufgeführten Stammdatentabellen werden aktuell mit dem Invoice Template ausgeliefert.
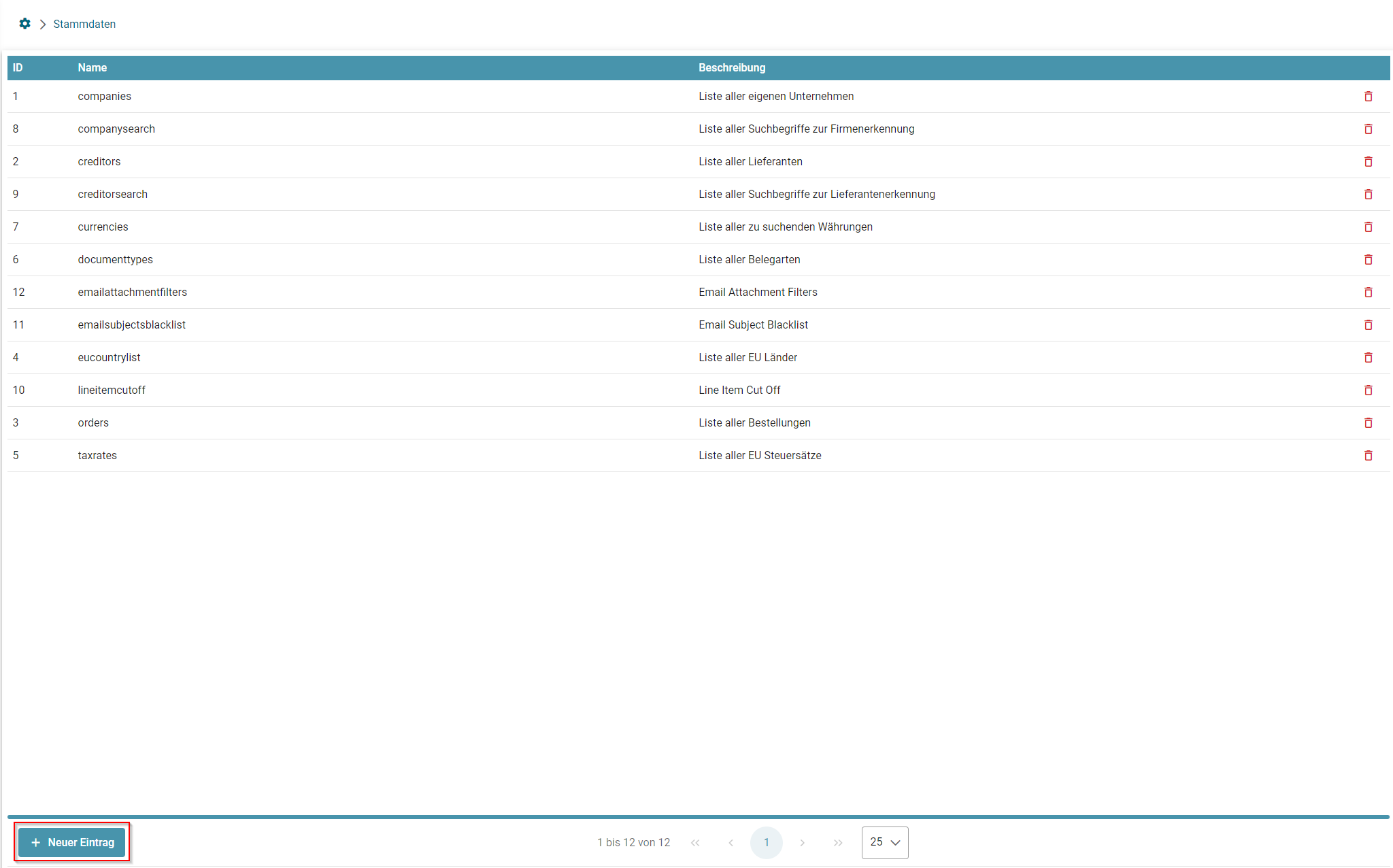
Eine neue Stammdatentabelle wird über das Symbol "Neuer Eintrag" angelegt.
Im nächsten Dialog wird der technische Name und der Anzeigenamen angegeben.

Konfiguration und Initialisieren einer neuen Stammdatentabelle via CSV-Upload
Im Webclient wird die Konfiguration der Spalten für diese Stammdatentabelle durchgeführt.
Stammdateneigenschaften

Spaltenkonfiguration
Zuerst werden die Spalten konfiguriert. Beim Klick auf den Reiter Spalten öffnet sich der Dialog zum Konfigurieren der Tabellenspalten.
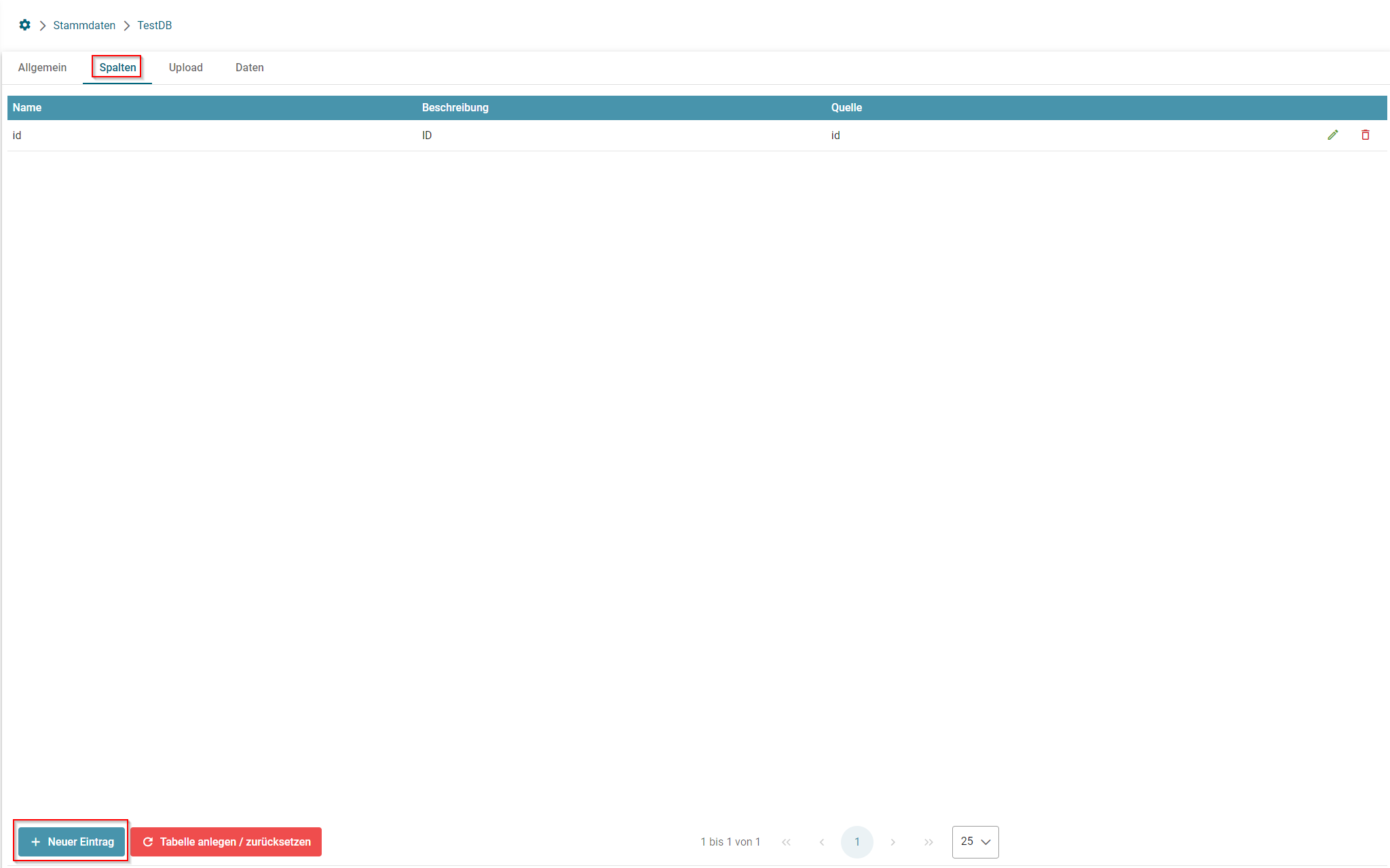
Mit dem Symbol "Neuer Eintrag" können neue Spalten hinzugefügt werden.
Wichtig!: Beim Betätigen des Buttons "Tabelle anlegen/zurücksetzen" werden alle Datensätze innerhalb der Tabelle gelöscht.
Hier werden folgende Informationen benötigt:
| Eigenschaft | Beschreibung |
| Name | Technischer Name für der Datenbankspalte |
| Beschreibung | Anzeigenamen für der Datenbankspalte |
| Quelle | externer Spaltenname (z.B. die Spaltenüberschrift in einer CSV-Datei) |
Jede Stammdatentabelle in Squeeze benötigt mindestens eine ID-Spalte.
Es können dann beliebig viele eigene Spalten definiert werden.
Test-Tabelle mit id-Spalte + 2 weitere Spalten:

Nachdem die Spalten konfiguriert sind, wird eine CSV-Datei benötigt um die Tabelle auf dem Datenbankserver initial zu erstellen.
Die CSV Datei muss die selben Überschriften enthalten, wie in der Spaltenkonfiguration unter Quelle angegeben worden ist. Die Reihenfolge der Überschriften spielt keine Rolle.
WICHTIG: die Schreibweise der Spaltenüberschriften in der CSV-Datei ist case-sensitive. Das bedeutet Groß-Kleinschreibung ist relevant.
CSV-Datei Beispiel für die obige Tabelle:

Für die Werte-Zeilen müssen keine ID´s angegeben werden. Die ID Spalte ist eine Auto-Inkrement Spalte und erzeugt eigene fortlaufende ID´s beim Upload.
Nachdem die CSV-Datei erstellt wurde kann die Initialisierung der neuen Stammdatentabelle erfolgen mit einem Klick auf den Reiter Upload.
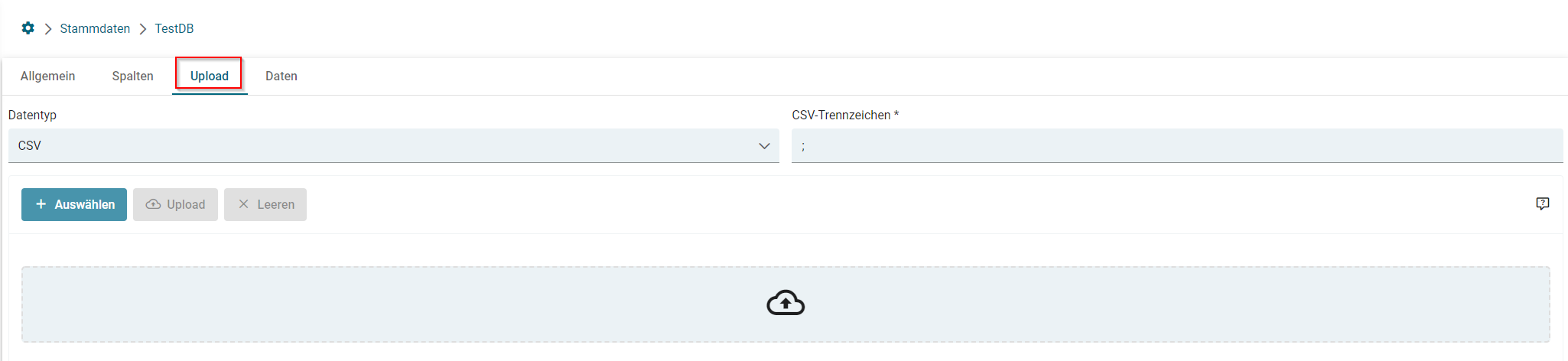
Die übergeben Werte können mit einem Klick auf den Reiter Daten geprüft werden.

Daten hinzufügen
Mit dem Webclient können manuell mit dem Symbol "NeuerEintrag" weitere Werte hinzugefügt werden.
Den neuen Datensatz mit dem Speichern Button bestätigen.

Export von Stammdaten als CSV
Neben dem Import von Stammdaten als CSV gibt es ab Squeeze 2.5 auch einen Export, der sich ähnlich verhält.
Voraussetzungen
Der CSV-Export steht nur dem Admin-User zur Verfügung, nicht normalen Usern.
Export per API
Am einfachsten kann man das ganze mit Hilfe der integrierten Swagger-UI ausprobieren:
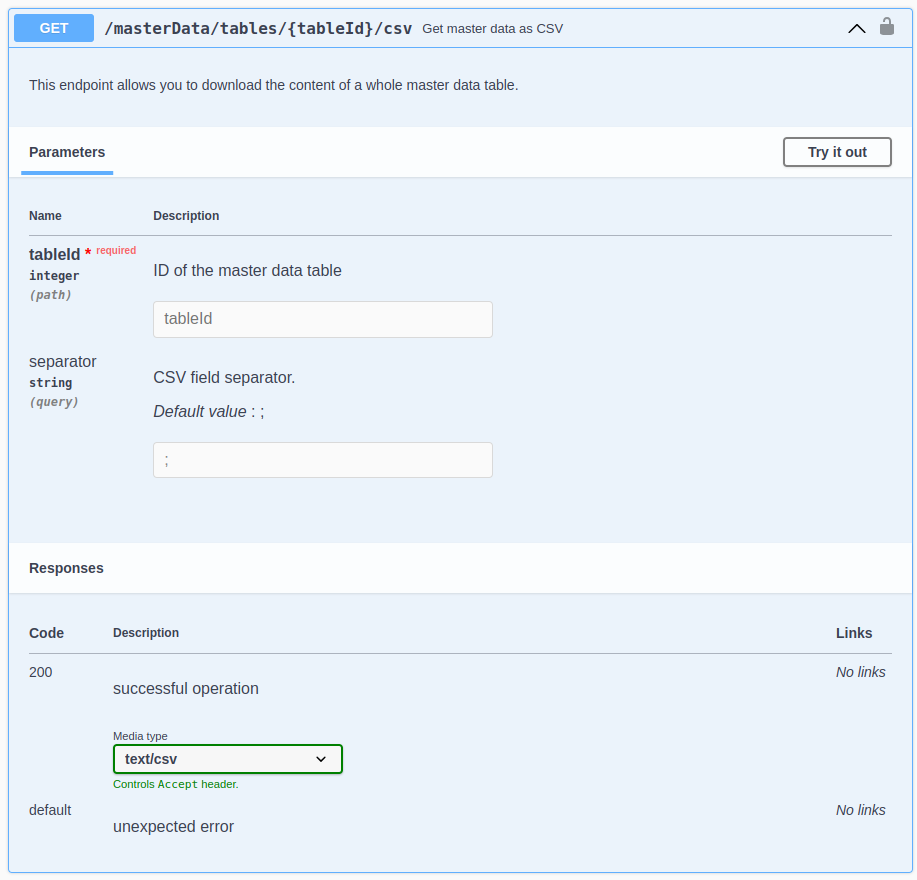
Als Parameter tableId gibt man die numerische ID einer existierenden Stammdatentabelle an. Das resultierende File wird danach als Download-Link in der Swagger-UI angeboten.
Export per GUI
tbd
Stammdaten ab Squeeze 2.5
Mit dem Release von Squeeze 2.5 haben sich bei der Benutzung von Stammdaten ein paar Details geändert. Diese Seite soll eine Übersicht geben und helfen eventuelle Probleme beim Update zu umgehen.
Lese- und Schreiboperationen
Soweit die Stammdaten nur gelesen und geschrieben werden ist keine Anpassung notwendig. Das betrifft insbesondere auch die Verwendung in DB-Link Lokatoren, welche lesend auf die Daten zugreifen.
Änderungen der Datenstruktur
Alle Änderungen der Struktur werden direkt umgesetzt. Nach dem Erzeugen einer Tabelle oder Spalte können dort direkt Daten geschrieben werden, ein separates Initialisieren der Tabelle (mit dem Verlust aller Daten) ist nicht mehr erforderlich. Die Daten in einer Tabelle werden bei Änderungen auch beibehalten, beispielsweise wenn man nur eine Tabelle oder Spalte umbenennt.
Integration existierender Tabellen
In Squeeze bis Version 2.4 gab es on-premise die Möglichkeit existierende (also nicht von Squeeze angelegte und verwaltete) DB-Tabellen oder -Views als Stammdaten zu integrieren. Dieses Feature war nie konsequent umgesetzt, was zu Bugs führte und mit Squeeze 2.5 entfernt wurde, um die Benutzung zu vereinheitlichen.
Bei einem Update auf Squeeze 2.5 sollte eine existierende Integration zunächst nicht betroffen sein, Zugriff auf Daten also weiterhin funktionieren. Was man jedoch vermeiden sollte ist die Struktur dieser Tabellen über Squeeze anzupassen. Es besteht hier die Gefahr von Datenverlusten!
Falls für eine on-premise Installation eine derartige Integration notwendig ist, müsste das als Sonderanpassung umgesetzt werden.
Falls sie vor Squeeze Stammdatentabellen entweder auf ihre eigenen SQL Tabellen- und Views oder produktinterne Tabellen eingerichtet haben, berücksichtigen Sie, dass ein Update auf Squeeze > 2.5 mit Support-Aufwänden verbunden sein kann.
Systeminterne Stammdatentabellen
Squeeze hat ein paar Stammdatentabellen die Teil des Systems selbst sind, also nicht erst durch manuelle Konfiguration oder das Invoices-Paket erstellt werden. Diese Daten werden als Stammdaten bereitgestellt, damit man mit den existierenden Mechanismen auf die Daten zugreifen kann. Insbesondere kann man per UI die Daten Pflegen und DB-Link Lokatoren auf diesen Daten erstellen. Da interne Abhängigkeiten auf die Struktur dieser Daten besteht, sind diese Tabellen ab Squeeze 2.5 geschützt. Modifikationen der Struktur werden daher vom System nicht mehr zugelassen.
Betroffen sind hiervon die folgenden Tabellen:
- creditorsettings
- emailattachmentfilters
- emailbodyconversion
- emailsenderwhitelist
- emailsubjectsblacklist
- taxrates
Jobs
Wiederkehrende Ausführung von Jobs und Skripten.
Jobs über Benutzeroberfläche steuern
Das folgende Feature befindet sich noch in Entwicklung und steht nur einigen Testkunden bereit. Falls die dargestellten Menüpunkte nicht verfügbar sind, wurde die Funktion noch nicht freigeschalten.
Wenn sie Squeeze selbst betreiben, stellen Sie sicher, dass das Jobsystem korrekt eingerichtet ist. Dies ist hier dokumentiert: Einrichten der Jobverwaltung SQUEEZE 2
In der Administration befinden sich die folgenden zwei Menüpunkte.
Skript-Übersicht
Hier werden Skripte des aktuellen Mandanten dargestellt. Diese Skripte können Sie als Jobs wiederkehrend starten.
Job-Verwaltung
Hier können Jobs für Job-Skripte eingerichtet werden.
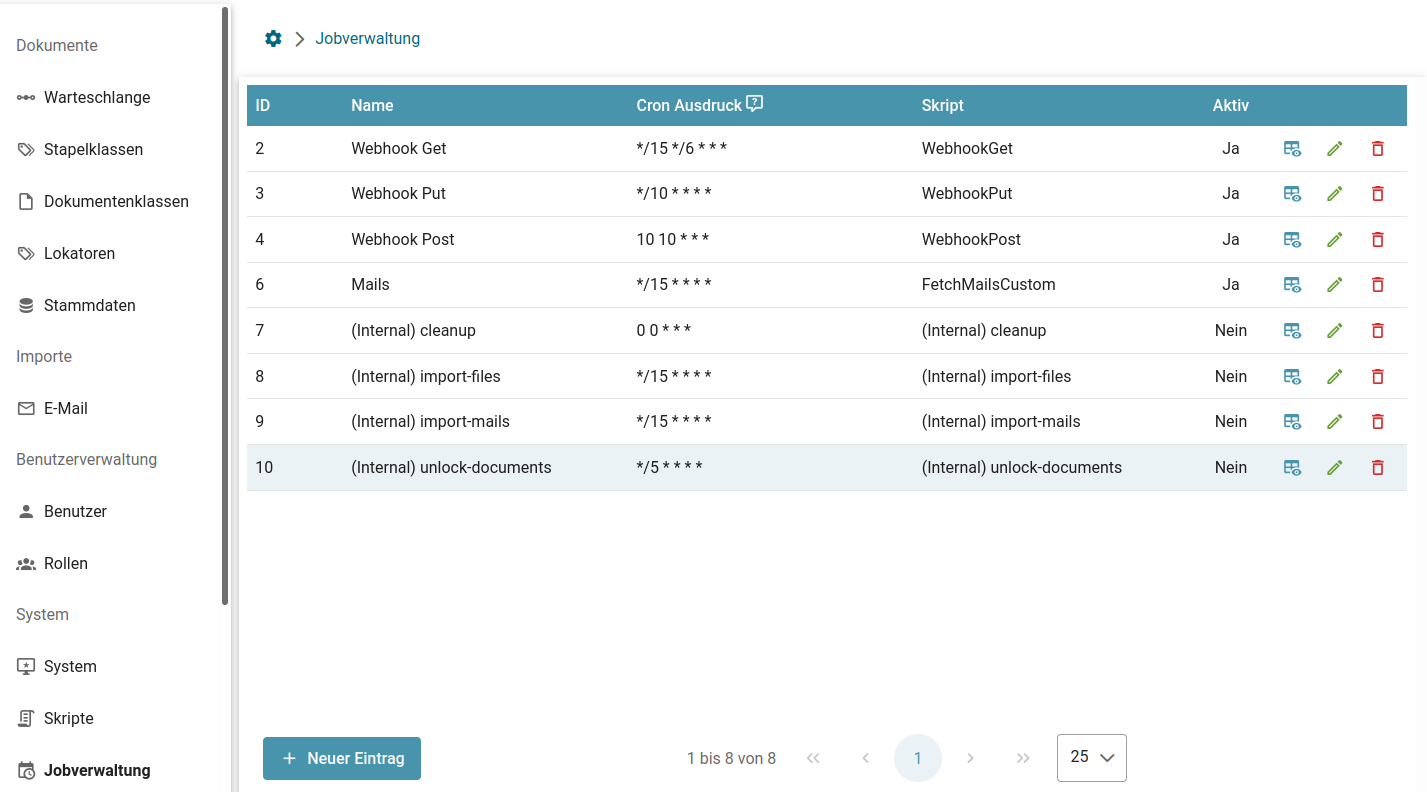
Anlage eines Jobs
Es können beliebig viele Jobs für ein Script konfiguriert werden. Dabei stehen vorgefertigte Intervalle bereit. Sollten diese nicht ausreichen kann ein Cron-Ausdruck genutzt werden.
Wir empfehlen nicht ein Skript zu häufig oder mehrfach als Job zu konfigurieren. Handelt es sich bspw. bei einem Job um ein Stammdaten-Sync-Job, so kann es passieren, dass diese gleichzeitig ausgeführt werden.
Wir werden dieses System erweitern und entsprechend absichern, aktuell muss dies manuell beachtet werden.
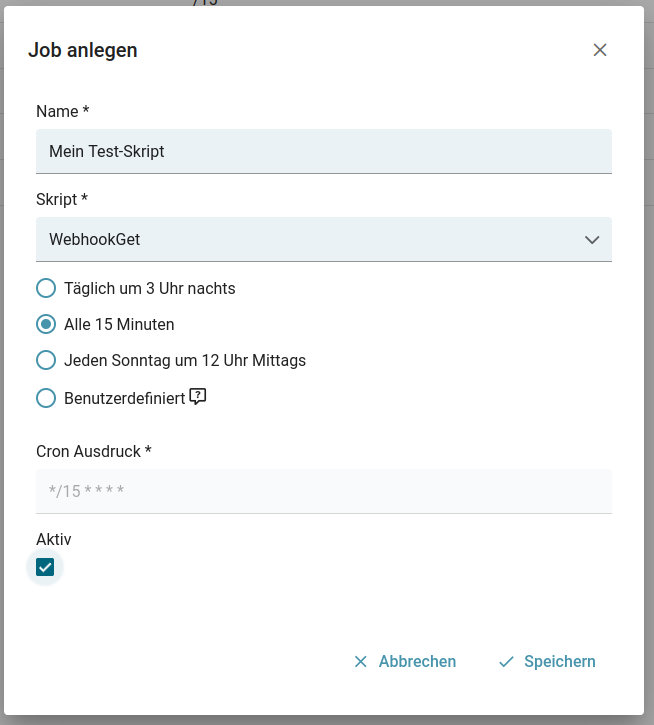
Einrichten der Jobverwaltung
Falls Sie Squeeze nicht selbst betreiben, ist dieser Artikel nicht relevant. Vermutlich möchten Sie nur wissen, wie Jobs in der Benutzeroberfläche zu verwalten sind: Jobs über Benutzeroberfläche steuern
Einleitung
Ab Squeeze 2 sollen Jobs primär über die UI konfiguriert werden. Somit ist nur noch die Konfiguration eines einzelnen Jobs im Betriebssystems notwendig, der Rest geschieht dann über die UI.
In Squeeze 1 musste noch pro auszuführendem Job in Squeeze ein Job im Betriebssystem geplant werden. Das System ist in der Theorie weiterhin nutzbar, erzeugt allerdings administrativen Mehraufwand.
Job im Betriebssystem einrichten (ab Squeeze 2.5)
Für die Gewährleistung der zeitgesteuerten Ausführungen muss auf dem Host ein Job hinterlegt werden der das PHP-Job-Script squeezer jobs:schedule --all immer zur vollen Minute ausführt.
Dieses Skript ist verantwortlich für die eigentliche Job-Ausführung und führt je nach Parameter die Jobs aller Mandanten oder nur der angegebenen Mandanten aus.
Für weitere Informationen können alle Optionen mittels --help flag gelistet werden (siehe auch Einführung zur Squeeze 2.5 CLI):
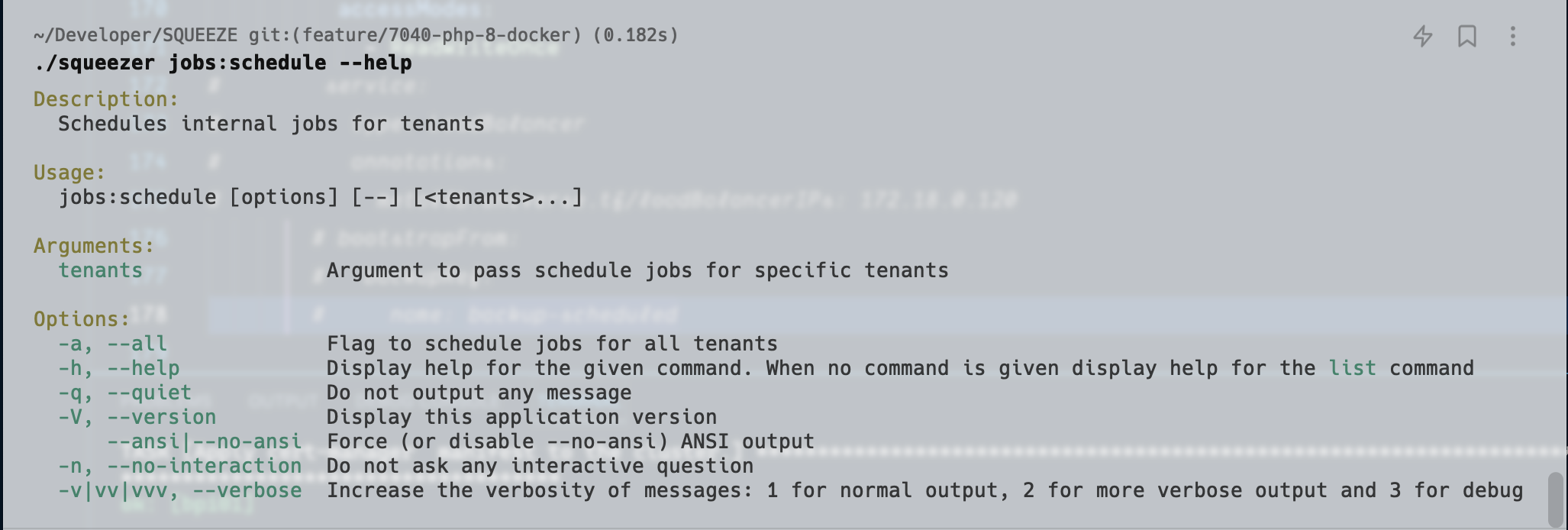
Beispiel Linux
Auf Linux ist besonders darauf zu achten, dass Jobs mittels des www-data Users ausgeführt werden.
Falls SQUEEZE auf Linux betrieben wird, ist ein Cronjob (bspw. mittels sudo crontab -u www-data -e) einzurichten.
*/1 * * * * php /var/www/html/squeeze/squeezer jobs:schedule --all
Job im Betriebssystem einrichten (vor Squeeze 2.5)
Für die Gewährleistung der zeitgesteuerten Ausführungen muss auf dem Host ein Job hinterlegt werden der das PHP-Jobs-Script cli/jobs.php schedule immer zu vollen Minute ausführt.
Dieses Skript ist verantwortlich für die eigentliche Job-Ausführung und führt Jobs aller Mandanten aus.
Beispiel Linux
Auf Linux ist besonders darauf zu achten, dass Jobs mittels des www-data Users ausgeführt werden.
Falls SQUEEZE auf Linux betrieben wird, ist ein cronjob (bspw. mittels sudo crontab -u www-data -e) einzurichten.
*/1 * * * * php /var/www/html/squeeze/cli/jobs.php schedule
Beispiel Windows
In der Windows Aufgabenplanung (Task Scheduler) muss ein Task definiert werden, welcher als Trigger die folgenden Einstellungen aufweist:
- Nach einem Zeitplan
- Täglich
- Wiederholen jede 1 Minute für die Dauer von 1 Tag
Die 1 Minute kann man manuell eintragen
Als Aktion muss die PHP Excutable aus dem SQUEEZE Installationsverzeichnis mit den CLI script jobs.php ausgeführt werden:
- Programm starten
<INSTALLATIONS_PFAD_SQUEEZE>/php/php.exe- Argumente:
<INSTALLATIONS_PFAD_SQUEEZE>/htdocs/cli/jobs.php schedule
(für alle Mandanten)
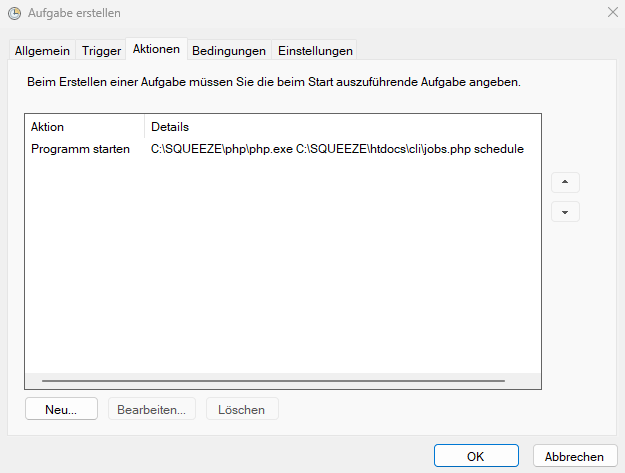
Ohne Angabe von Mandanten, werden die Jobs für alle SQUEEZE Mandanten geprüft. Der Mandant kann im Aufruf angegeben werden:
<INSTALLATIONS_PFAD_SQUEEZE>/htdocs/cli/jobs.php schedule <tenant>
Hinweis bzgl. Performance
Bei einem System mit vielen Mandanten kann es vorkommen, dass die Job-Ausführung länger dauert. Das ist im Kontext von Job-Skripten besonders kritisch, da sich ggf. Jobs "überholen" oder parallel ablaufen könnten. In solchen Fällen kontaktieren Sie bitte den DEXPRO Support, damit gemeinsam evaluiert werden kann, ob eine Sonderanpassung notwendig ist.
Cleanup-Job
Diese Seite dokumentiert, wie Squeeze Daten nach Ablauf ihrer Haltefrist löscht und welche Daten nicht gelöscht werden.
Squeeze 2
Verhalten
Ein Dokument in Squeeze 2 wird nicht mehr benötigt, wenn keine weiteren Bearbeitungsschritte mehr anstehen. Üblicherweise sind das Dokumente in den Steps "Verarbeitet" (Backup) und Gelöscht (Deleted). Squeeze hält diese Dokumente noch eine gewisse Zeit vor und löscht sie danach permanent. Hierbei werden die Dateien (Bilder und PDFs), Einträge in der SQL-DB und Suchindizes (in ElasticSearch) gelöscht, welche aus dem Dokument extrahiert wurden.
Ausgenommen sind Informationen, die für Audits relevant sind.
Haltefrist
Die Haltefrist gibt an wie lange ein Dokument gespeichert bleibt, nachdem es von Squeeze selbst nicht mehr benötigt wird. Als Admin kann man die aktuellen Einstellungen im "System"-Bereich der UI einsehen.
Um die Haltefrist einzustellen, muss man der Mandantenkonfiguration (s. Server- und Mandantenkonfiguration) dieses Objekt hinzufügen:
"cleanupJob": {
"maxDocumentAge": "100",
"maxLogAge": "0"
}Eine maxDocumentAge vom Wert 0 bedeutet hierbei, dass Dokumente schnellstmöglich vom System gelöscht werden.
Auditlog
Die finale Löschung eines Dokuments wird ab Squeeze 2.3.4 im Auditlog (SQL Tabelle queueentrychanges) vermerkt.
Squeeze 1
In Squeeze 1 werden Cleanup-Jobs anders gepflegt als in Squeeze 2. Diese Dokumentation wird aktuell nicht gepflegt, da wir uns auf die Verbesserung und Dokumentation des Cleanup-Jobs von Squeeze 2 konzentrieren.
Unlock-Job
Falls Dokumente von Nutzern gesperrt sein sollten, welche nicht mehr am Dokument arbeiten, kann der "unlock-documents" Job helfen.
Zu finden ist der Job in der Jobverwaltung (Internal) unlock-documents. Standard mäßig läuft der Job alle 5 Minuten und entsperrt alle Dokumente, in welchen zurzeit nicht gearbeitet wird.
Exportschnittstellen
Dokumentation von Exportschnittstellen.
Otris Documents SOAP
Eine der wohl am häufigsten genutzten Schnittstellen in Verbindung mit Squeeze ist die Otris Documents SOAP Schnittstelle.
Diese Schnittstelle bietet die Möglichkeit bidirektional mit dem Documents System zu interagieren.
Konfiguration
Um ein Documents System per SOAP anzusprechen und Aktionen auszuführen, muss an der Squeeze Dokumentenklasse ein Export definiert werden:
Über "Neuer Eintrag" kann ein Export angelegt werden.
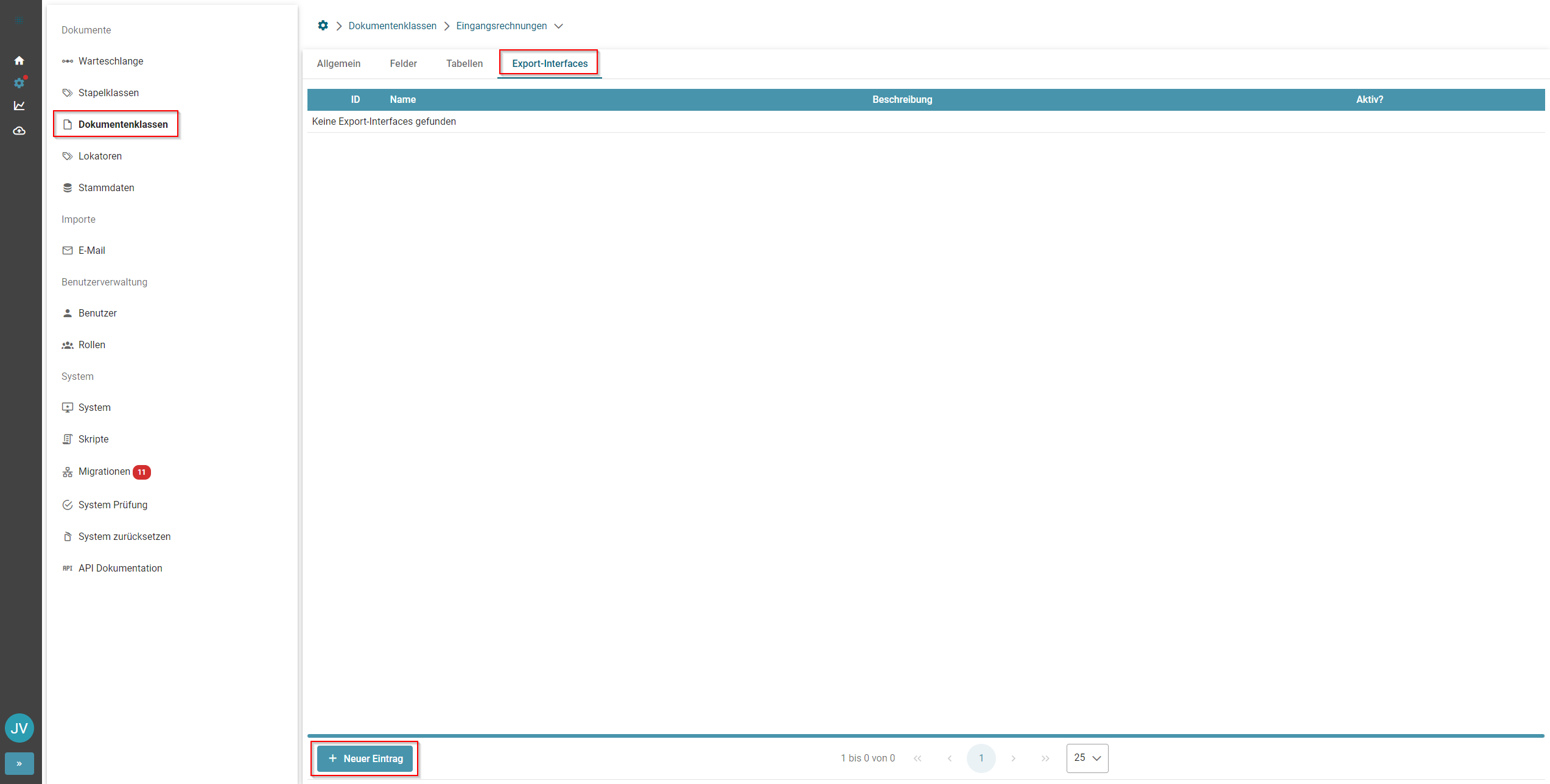
Das Passwort ist nach dem Speichern nicht mehr einsehbar.
Beim Speichern der Konfiguration wird versucht eine Verbindung zum Server herzustellen. Gelingt dieser Verbindungsaufbau nicht erscheint die Fehlermeldung in einem neuen Dialog, wie hier zu sehen ist:
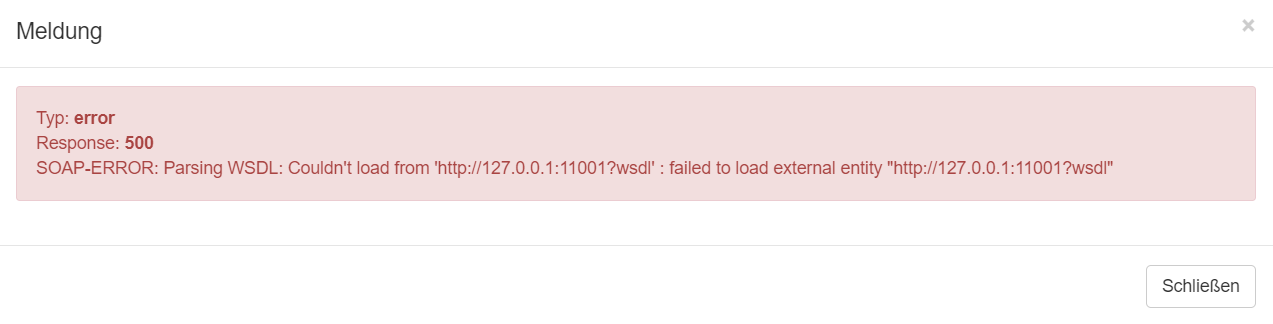
Wenn die Verbindung jedoch hergestellt werden konnte, wird die Konfiguration zu den definierten Exportschnittstellen hinzugefügt.
Typische Fehler
Dokumente können nicht exportiert werden und bleiben liegen
In älteren Versionen dieser Schnittstelle wurden beliebige viele Dokumente gleichzeitig exportiert. Der Soap Server von DOCUMENTs ist allerdings nicht in der Lage damit umzugehen. Daher ist die Anzahl gleichzeitiger Exporte dieses Schnittstellentypens auf 1 limitiert.
Bei dieser Schnittstelle ist die Anzahl gleichzeitiger Exporte auf 1 beschränkt, um Fehler zu vermeiden.
Fehler wenn keine Internetverbindung besteht
Die mit Documents ausgelieferte WSDL verweist auf ein Schema, welches bei W3C liegt. Sollte keine Internetverbindung bestehen, führt das zu einem Fehler, da das Schema nicht geladen werden kann. Um diesen Fehler zu umgehen und auf eine Interverbindung verzichten zu können, kann folgender Workaround genutzt werden:
Sicherung der WSDL erstellen
Im Soap Server Verzeichnis von Documents sollte eine Sicherung der Originalen WSDL erstellt werden:
Verweis zum Schema anpassen
in der DOCUMENTS.wsdl muss nun der Verweis so angepasst werden dass auf eine xsd verwiesen wird, die im lokalen netzwerk erreichbar ist. Am einfachsten ist hier, auf den Documents Server selbst zu verweisen (z.B. mittels IP des Documents-Servers)

Die xop.xsd muss nun noch im public root Verzeichnis des Documents Servers abgelegt werden, damit diese auch für Squeeze erreichbar ist.
SharePoint API
Diese Schnittstelle bietet die Möglichkeit bidirektional mit dem SharePoint System zu interagieren.
Kompatibilität
Konfiguration
Um ein SharePoint System per REST/OData anzusprechen und Aktionen auszuführen, muss an der Squeeze Dokumentenklasse ein Export definiert werden:
Authentifizierung
Bei der Authentifizierung kann zwischen drei verschiedenen Mechanismen gewählt werden:
- User - Anmeldung am SharePoint mit Benutzer
- App
- NTLM
Authentifizierung als User
Um eine Benutzter-basierte Authentifizierung zu nutzen, ist im Feld Authentication Type der Wert User auszuwählen. Anschließend muss in die Felder Username sowie Password ein Benutzer, der dem SharePoint System bekannt ist, hinterlegt werden.
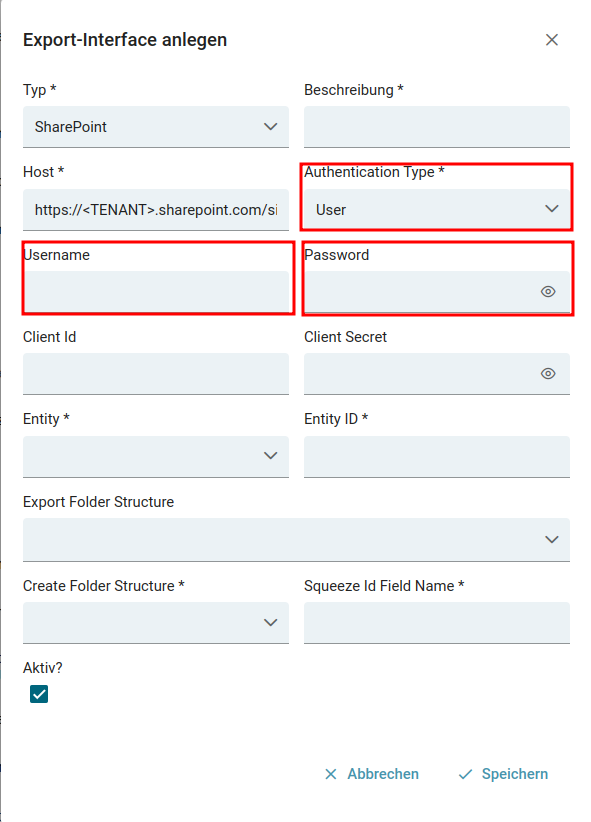
Authentifizierung als App
Um eine App-basierte Authentifizierung zu nutzen, ist im Feld Authentication Type der Wert App auszuwählen. Anschließend muss in die Felder Client Id sowie Client Secret eine Registrierte App Kennung hinterlegt werden, die dem SharePoint System bekannt ist.
Die Passwortfelder (Passwort und ClientSecret) sind nach dem Speichern nicht mehr einsehbar.
Entität
Um in das System zu exportieren, muss zunächst die Entität bestimmt werden, in welche exportiert werden soll:
- Dokumentenbibliothek
- Liste
Nachdem dies ausgewählt wurde, kann im Feld "Entity ID" die entsprechende Liste oder Dokumentenbibliothek angegeben werden in der letztendlich der Export stattfindet.
Für Dokumentenbibliotheken muss der technische Name angegeben werden, bei Listen der Anzeigename.
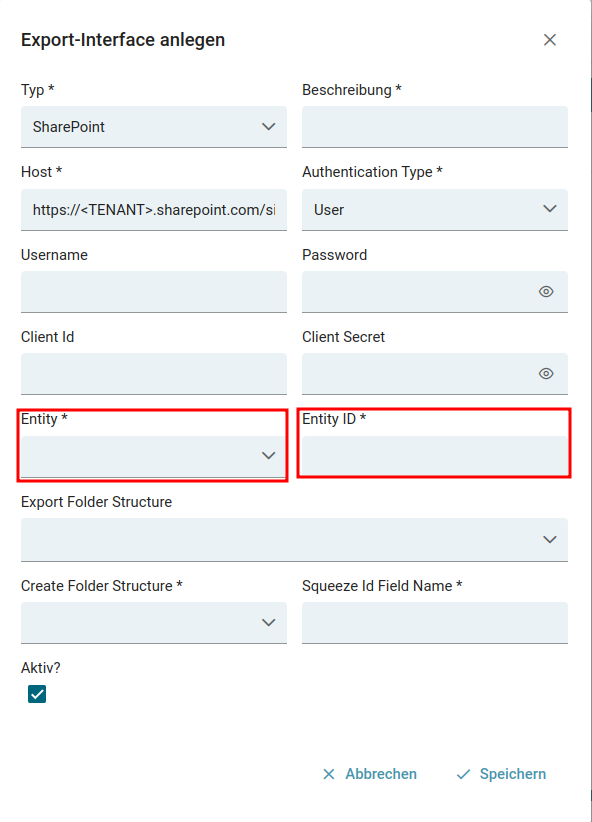
Dokumentenbibliothek
Für die Dokumentenbibliotheken gibt es noch zwei weitere Einstellungen.
Export Folder Structure gibt den Pfad in der Dokumentenbibliothek an, in den exportiert werden soll. Dieser kann dynamisch aus Feldwerten der Felder der jeweiligen Dokumentenklasse angegeben werden. Hierzu in dem Feld den Pfad von links nach rechts mit Feldern der Dokumentenklasse auswählen:
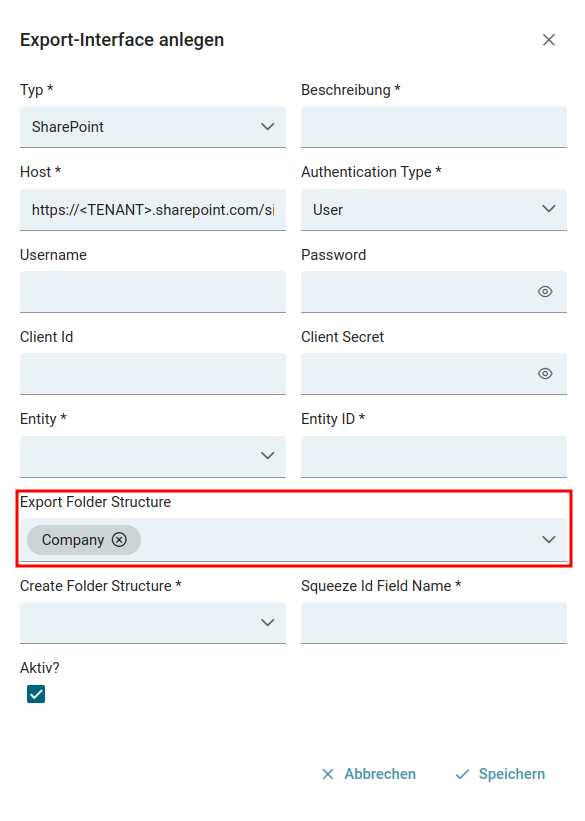
Die letzte Einstellungsmöglichkeit gibt an, ob SQUEEZE den Export-Pfad erstellen soll, falls dieser nicht vorhanden ist.
Ist der Pfad nicht vorhanden und SQUEEZE soll diesen nicht erstellen, wird ein Fehler beim Export eines Vorgangs durch den SharePoint zurückgegeben.
Feldwerte exportieren
Mit den Namen im Zielsystem (externe Feldnamen) können die Spalten eines Listeneintrages bzw. weitere Spalten/Details eines Eintrags einer Dokumentenbibliothek angegeben werden.
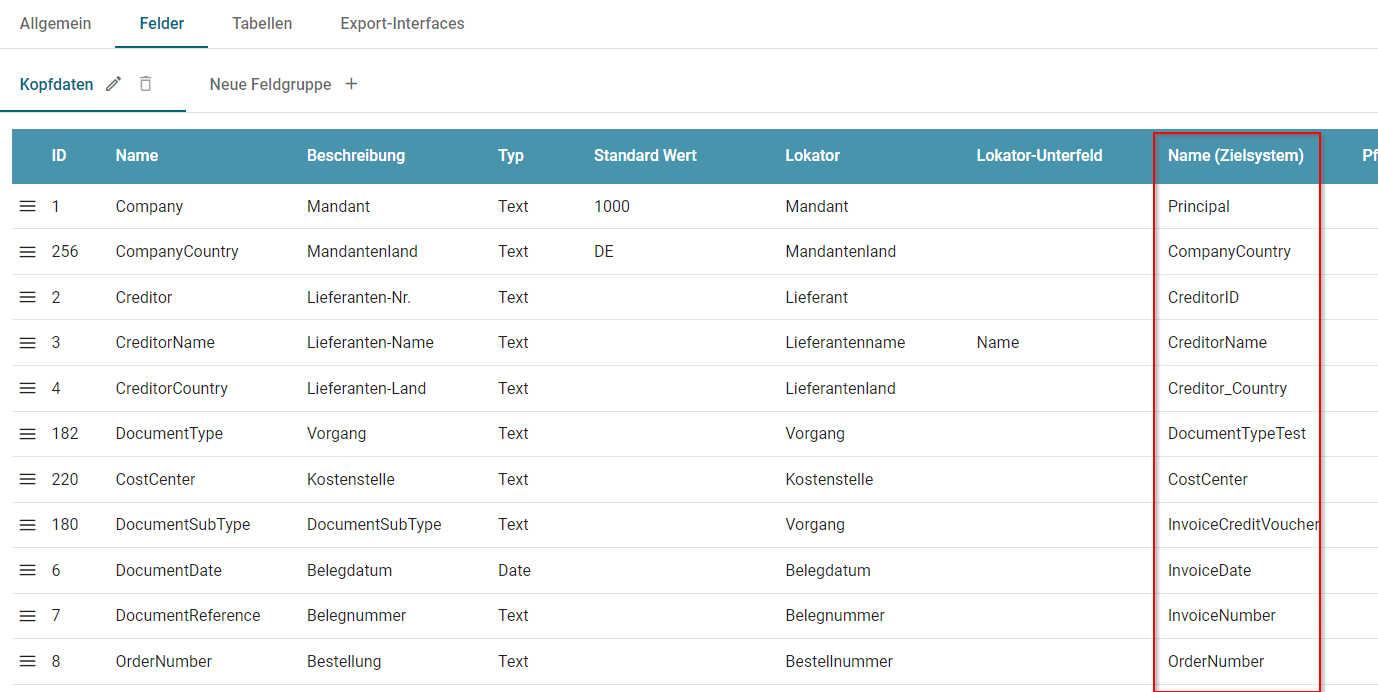
Diese können in der Dokumentenklasse bei den Feldern angegeben werden.
Positionen exportieren
Jedes "Table"-Feld (in dem Beispiel die "LineItems") kann als JSON exportiert werden, wenn ein Zielname definiert wurde.
Dabei muss das Zielfeld mehrzeilig sein.
Reservierte Zielnamen
Hierbei handelt es sich um die globalen Inhaltstypen (Root) des SharePoints.
Navision Soap
Bei dieser Schnittstelle ist die Anzahl gleichzeitiger Exporte auf 1 beschränkt, um Fehler zu vermeiden.
Das Passwort ist nach dem Speichern nicht mehr einsehbar.
Freeze EAS Export
Diese Schnittstelle bietet die Möglichkeit in einen Freeze EAS Store zu exportieren.
Kompatibilität
- Squeeze ab 2.4.1
- Dexpro Platform-Integration
- Hinweis: Aktuell steht sowohl die Platform als auch Freeze nur in der Cloud zur Verfügung
Setup
Allgemein ist es erstmal notwendig, eine funktionierende Integration in die Dexpro Platform zu haben. Am einfachsten kann man das über die Systemchecks sehen:
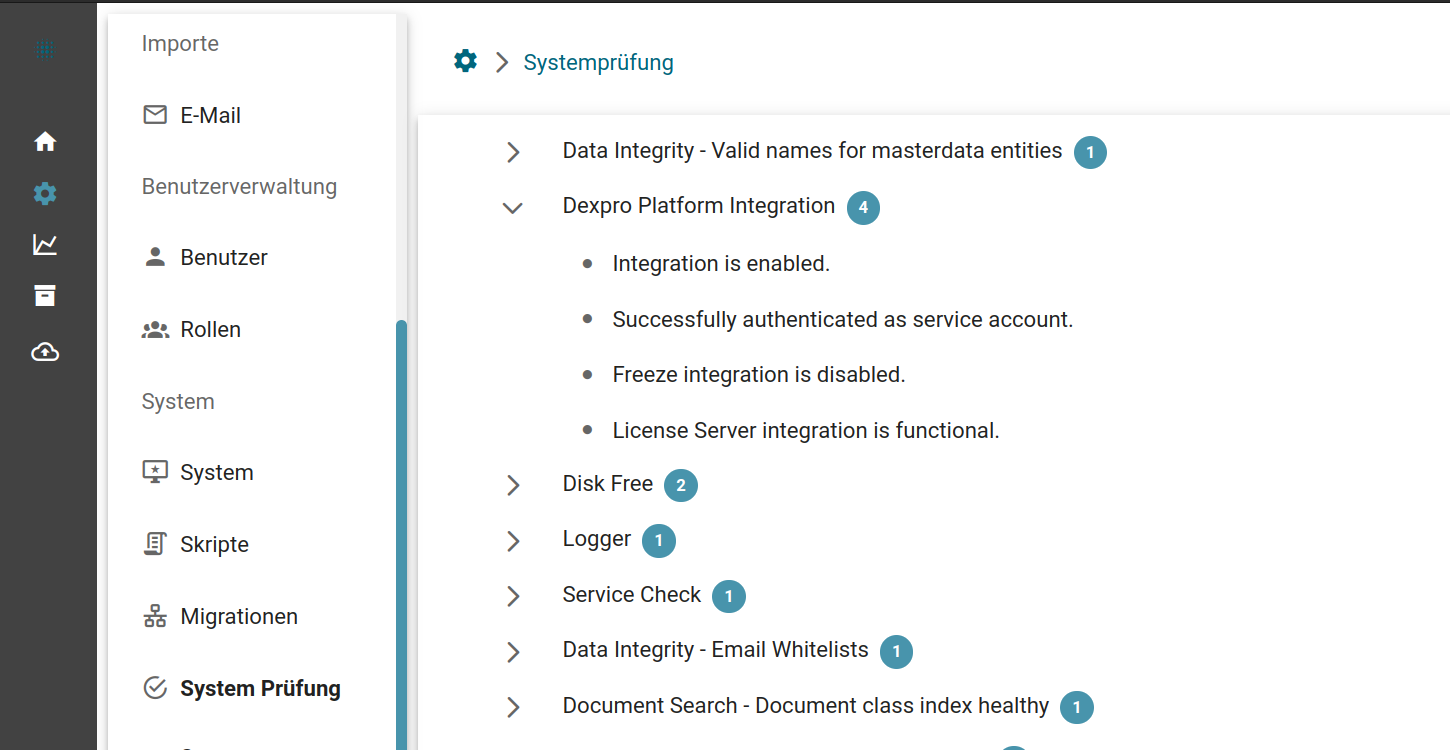
Für die Freeze EAS-Integration muss man zusätzlich in der Mandantenkonfiguration die BasisURL von Freeze eintragen:
...
"dexp": {
...
"freeze": {
"baseUrl": "https://public-02.freeze.one/apis/freeze/"
},
...
},
...Wenn man erneut die Systemchecks durchführt, sollte die Freeze Integration angezeigt werden, gefolgt von der Liste der registrierten Stores:
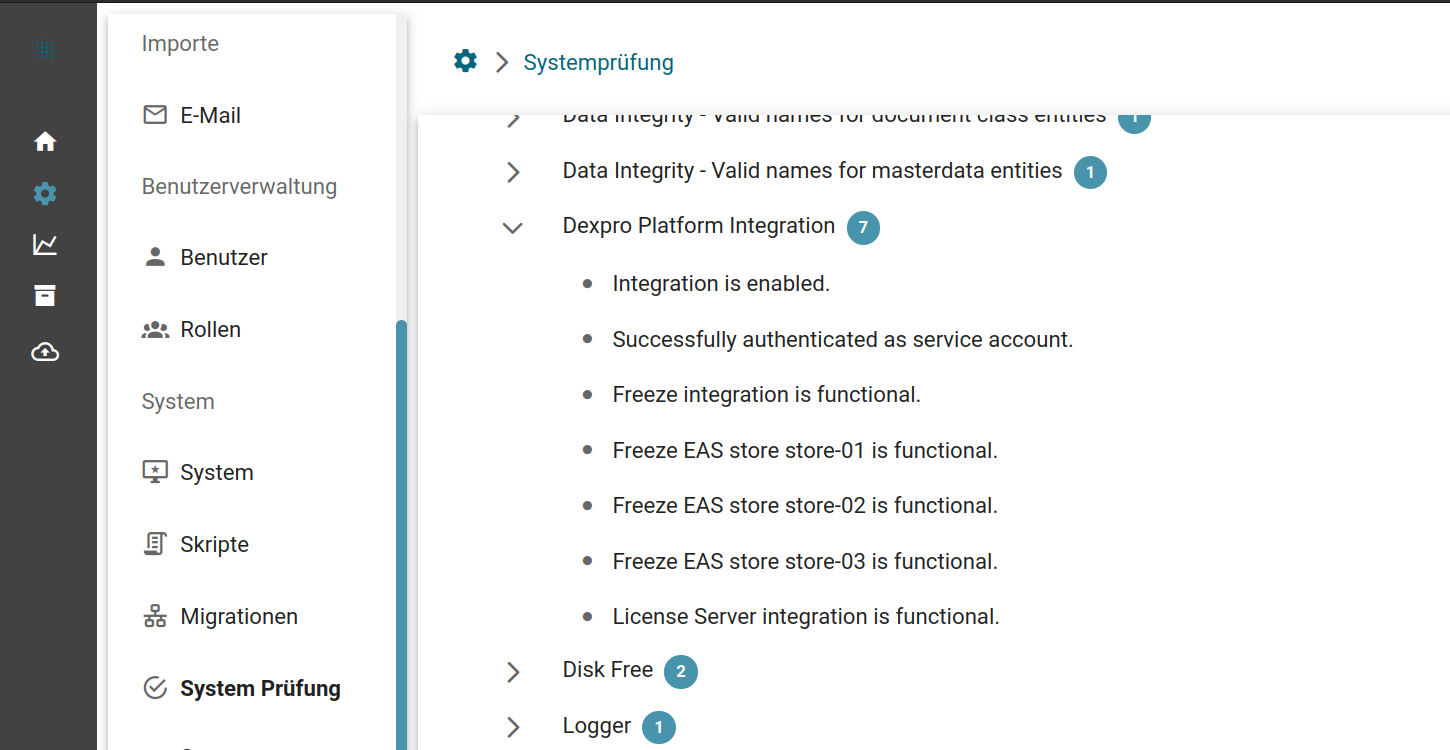
Konfiguration
Die Konfiguration erfolgt wie bei jedem Export an der Dokumentenklasse:
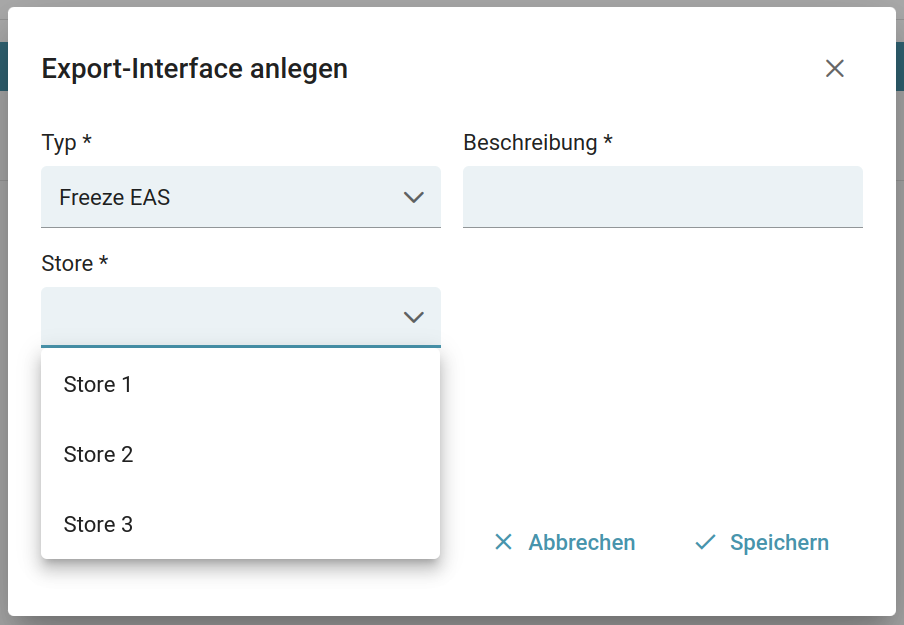
Ob ein Feld exportiert wird hängt davon ab ob dessen Eigenschaft "Name (Zielsystem)" gesetzt ist. Falls ja, wird es unter diesem Namen an den Archiv-Record angehängt.
Pull Export
Der Pull Export ist ein Hilfsmittel, das für die Integration von Squeeze in anderen Anwendungen gedacht ist.
Dieser Export ist asynchon aus Sicht von Squeeze und ermöglicht, dass Integratoren Dokumente abholen, anstelle sie von Squeeze gesendet bekommen. Daher die Benennung "Pull Export" (im Kontrast zu "Push Export").
Das Prinzip hierbei ist:
- Ein Dokument wird in Squeeze validiert. Es liegt jetzt im Export-Schritt, wartend auf die Abholung von außen.
- Die Integration holt das Dokument ab.
- Die Integration markiert das Dokument als exportiert.
- Das Dokument wird jetzt in den nächsten Verarbeitungsschritt verschoben (Archiv, o. Ä.)
Falls Sie als Integrator Dokumente von Squeeze nach der Validierung aktiv abholen wollen, sprechen Sie Ihren Ansprechpartner für den Squeeze-Betrieb an.
SharePoint Export via Graph API
Mit dieser Schnittstelle kann die offizielle SharePoint Graph API von Microsoft integriert werden, um mit einem SharePoint Verzeichnis zu kommunizieren.
Dafür ist eine registrierte Microsoft Azure Applikation notwendig.
Integrierte Services der Graph API
- Dokumente in ein zuvor definiertes SharePoint Verzeichnis hochladen
Zugangsberechtigungen in Microsoft Azure
Benötigte Applikationen
Erstellen Sie zwei neue Applikationen in Microsoft Azure.
Eine dient zu administrativen Zwecken, die Andere für den Export selbst.
Zur Bewilligung der folgenden Rechte wird ein User mit Administrationsrechten in Microsoft Azure benötigt.
Die Rechte können im Menü "API Permissions" (im deutschen Client: "API-Berechtigungen") hinzugefügt werden:
- Die Admin-Applikation benötigt die API-Berechtigung
Sites.FullControl.All - Die Export-Applikation benötigt die API-Berechtigung
Sites.Selected
In der Admin-Applikation muss ein neues Client-Secret im Menü Certificates & secrets erstellt werden.
Dieses ist nötig, um die Export-Applikation mit den nötigen Rechten auszustatten.
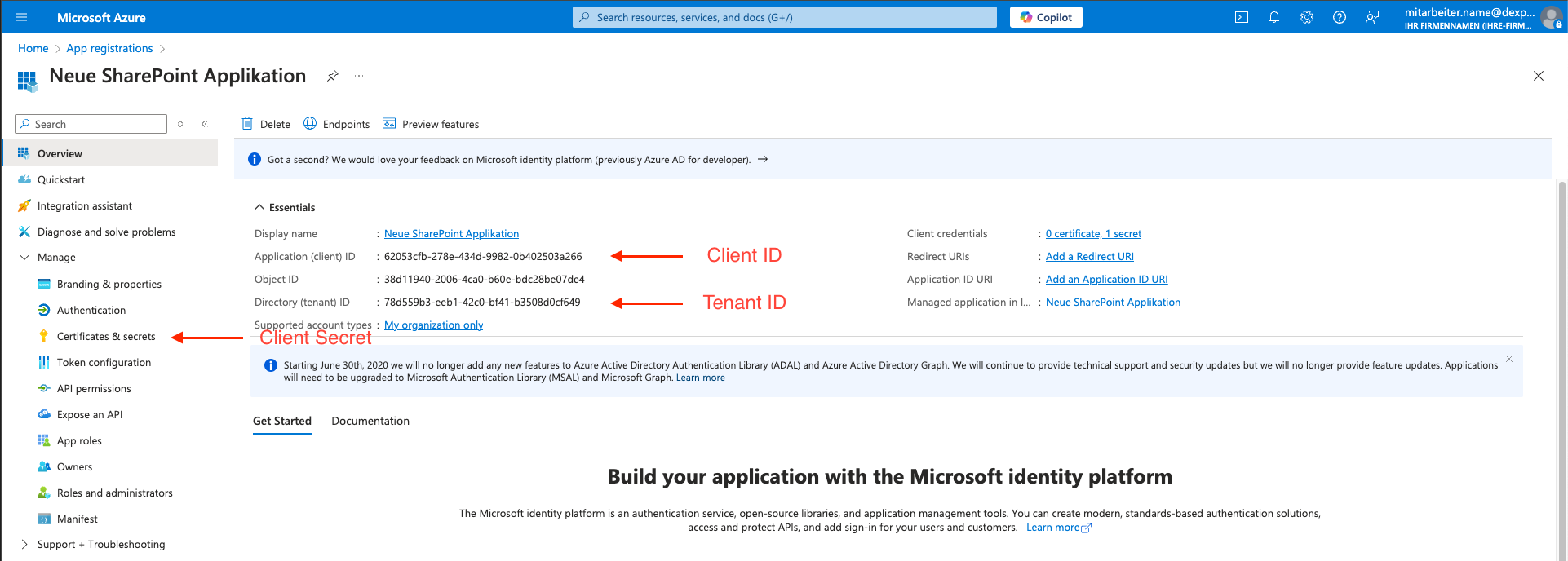 Abbildung - Registrierte Microsoft Applikation "Neue SharePoint Applikation"
Abbildung - Registrierte Microsoft Applikation "Neue SharePoint Applikation"
Rechte für die Export-Applikation
Für diesen Abschnitt benötigen Sie die Daten der zuvor erstellten Admin-Applikation.
Die Export-Applikation muss zwingend die Berechtigungen auf die von Ihnen gewünschte SharePoint Seite erhalten.
Dafür ist die Id der SharePoint-Seite notwendig.
Bedauerlicherweise ist es zum aktuellen Zeitpunkt nicht möglich, die SharePoint Seiten Id über die grafische Oberfläche ausfindig zu machen (Stand März 2025).
Daher wird wie folgt beschrieben, wie die Id der Seite ermittelt und die Erteilung der Berechtigung per cURL Requests erteilt werden kann. Diese cURL Requests können Sie in einem beliebigen Terminal (Windows CMD / Linux Bash) ausführen.
Einloggen
Zu erst benötigen Sie einen Bearer Token, um sich an der API zu authentifizieren. Dies erfolgt durch folgenden Request:
- URL: https://login.microsoftonline.com/<TENANT_ID>/oauth2/v2.0/token
- HTTP Methode: POST
- Request Body Typ: form-data
- Request Body:
- client_id:<CLIENT_ID>
- client_secret:<CLIENT_SECRET>
- grant_type:client_credentials
- scope:https://graph.microsoft.com/.default
Statt "<TENANT_ID>", "<CLIENT_ID>" und "<CLIENT_SECRET>" müssen Sie Ihre jeweiligen Daten verwenden.
Wo Sie diese Daten finden steht in den Abschnitten "Feld Tenant Id", "Feld Client Id" und "Feld Client Secret" dieses Artikels.
Anbei der cURL Befehl (Linux Bash):
curl --location 'https://login.microsoftonline.com/<TENANT_ID>/oauth2/v2.0/token' \--form 'client_id="<CLIENT_ID>"' \--form 'client_secret="<CLIENT_SECRET>"' \--form 'grant_type="client_credentials"' \--form 'scope="https://graph.microsoft.com/.default"'curl --location "https://login.microsoftonline.com/<TENANT_ID>/oauth2/v2.0/token" --form "client_id=<CLIENT_ID>" --form "client_secret=<CLIENT_SECRET>" --form "grant_type=client_credentials" --form "scope=https://graph.microsoft.com/.default"access_token" der Response. Dieser Bearer Token wird im folgenden "
<BEARER_TOKEN>" genannt, zur Verdeutlichung wo dieser einzusetzen ist.Site Id erhalten
- URL: https://graph.microsoft.com/v1.0/sites/<TENANT>.sharepoint.com/sites/<NAME>
- HTTP Methode: GET
- Header: "Authorization: Bearer <BEARER_TOKEN>"
Anbei der cURL Befehl (Linux Bash):
curl --location 'https://graph.microsoft.com/v1.0/sites/<TENANT>.sharepoint.com:/sites/<NAME>' \--header 'Authorization: Bearer <BEARER_TOKEN>'Anbei der cURL Befehl (Windows CMD):
curl --location "https://graph.microsoft.com/v1.0/sites/<TENANT>.sharepoint.com:/sites/<NAME>" --header "Authorization: Bearer <BEARER_TOKEN>"Die Response dieses Requests ist etwas umständlicher zu lesen, ein Beispiel:
{
"@odata.context": "https://graph.microsoft.com/v1.0/$metadata#sites/$entity",
"createdDateTime": "2025-03-13T00:11:15.033Z",
"description": "TestDescription",
"id": "<TENANT>.sharepoint.com,808dec17-aa6d-4158-a9fe-8caa8d909dff,81f7ad14-65ae-46c2-b0fc-10602e9401cc",
"lastModifiedDateTime": "2025-03-13T07:07:19Z",
"name": "TestName",
"webUrl": "https://<TENANT>.sharepoint.com/sites/<SITE_NAME>",
"displayName": "TestName",
"root": {},
"siteCollection": {
"hostname": "<TENANT>.sharepoint.com"
}
}Die Site Id in diesem Fall ist der Wert 808dec17-aa6d-4158-a9fe-8caa8d909dff.
Er befindet sich im Index "id" und ist der mittlere der Werte (wenn den Wert an seinen Kommata aufteilt).
Zugriffsrechte erteilen
Für die Zugriffsrechte benötigen sie die Client ID der Export-Applikation und den Namen.
Diese setzen Sie an der Stelle von "<EXPORT_APPLIKATION_CLIENT_ID>" bzw. "<EXPORT_APPLIKATION_NAME>" ein.
Die Rechte zum Schreiben beinhalten auch die Leserechte.
- URL: https://graph.microsoft.com/v1.0/sites/<SITE_ID>/permissions
- HTTP Methode: POST
- Request Body Type: JSON
- Request Body:
{
"roles": ["write"],
"grantedToIdentities": [{
"application": {
"id": "<EXPORT_APPLIKATION_CLIENT_ID>",
"displayName": "<EXPORT_APPLIKATION_NAME>"
}
}]
}Anbei der cURL Befehl (Linux Bash):
curl --location 'https://graph.microsoft.com/v1.0/sites/<SITE_ID>/permissions' \
--header 'Authorization: Bearer <BEARER_TOKEN>' \
--header 'Content-Type: application/json' \
--data '{
"roles": ["write"],
"grantedToIdentities": [{
"application": {
"id": "<EXPORT_APPLIKATION_CLIENT_ID>",
"displayName": "<EXPORT_APPLIKATION_NAME>"
}
}]
}'Anbei der cURL Befehl (Windows CMD):
curl --location "https://graph.microsoft.com/v1.0/sites/<SITE_ID>/permissions" --header "Authorization: Bearer <BEARER_TOKEN>" --header "Content-Type: application/json" --data "{'roles': ['write'],'grantedToIdentities': [{'application': {'id': '<EXPORT_APPLIKATION_CLIENT_ID>','displayName': '<EXPORT_APPLIKATION_NAME>'}}]}"Der Server gibt im Erfolgsfall eine Response mit dem Statuscode 201 zurück.
Da der Statuscode aussagekräftig genug ist, kann der Inhalt der Response vernachlässigt werden.
Konfiguration
Um diese Schnittstelle zu verwenden und Aktionen auszuführen, muss an der Squeeze Dokumentenklasse eine Export-Schnittstelle definiert werden.
Die benötigten Zugangsdaten entnehmen Sie aus der Export-Applikation.
Authentifizierung
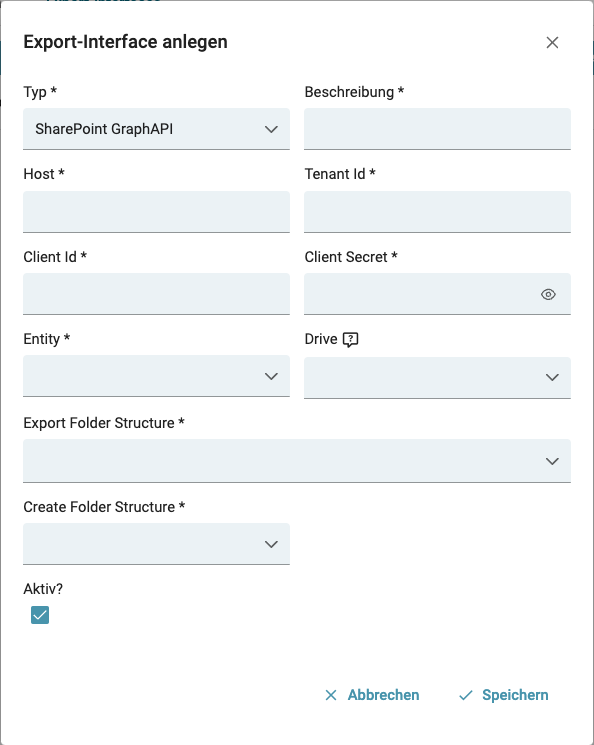
Abbildung - Export Interface SharePoint GraphAPI (WIP)
Feld Beschreibung
Für das Export Interface kann ein Name angegeben werden, im Feld Beschreibung.
Feld Host
In diesem Feld wird die Adresse zur SharePoint Seite hinterlegt. Diese hat folgendes Muster: <TENANT>.sharepoint.com/sites/<NAME>.
Feld Tenant Id
Die Tenant Id befindet sich in der Übersicht einer registrierten App. Eine Auflistung dieser Apps finden sie hier.
Um die Liste zu sehen müssen Sie eingeloggt sein.
Die Tenant Id wird auf der Seite auch "Directory (tenant) ID".
Feld Client Id
Die Tenant Id befindet sich in der Übersicht einer registrierten App. Eine Auflistung dieser Apps finden sie hier.
Um die Liste zu sehen müssen Sie eingeloggt sein.
Hier wird sie auch unter dem Begriff "Application (client) ID" geführt.
Feld Client Secret
Die Tenant Id befindet sich in der Übersicht einer registrierten App. Eine Auflistung dieser Apps finden sie hier.
Um die Liste zu sehen müssen Sie eingeloggt sein.
Das Client Secret wird innerhalb der registrierten App hinterlegt.
Das dafür nötige Menü finden Sie in, in der ausgewählten App, unter dem Menü "Certificates & secrets".
Für das Erstellen eines Secrets müssen sie lediglich eine aussagekräftige Beschreibung angeben, und den Zeitraum, in welchem das Secret valide ist.
Das Client Secret wird bei Microsoft unter "Secret Value" geführt.
Diese Information wird nur einmalig angezeigt, aus diesem Grund sollte es in einer sicheren Umgebung gespeichert werden.
Verwechseln Sie das Client Secret nicht mit "Secret-ID".
Das ClientSecret ist nach dem Speichern nicht mehr einsehbar.
Feld Entity
Über die Entity wird der Service ausgewählt, welchen Sie verwenden möchten:
Feld Export Folder Structure
Dateien werden alle in das Home Verzeichnis des SharePoint Verzeichnisses hochgeladen.
Um zu spezifizieren, in welche Verzeichnis Struktur ein Dokument abgelegt werden soll, können in dieser Auswahlliste mehrere Felder ausgewählt werden.
Die Felder werden durch ihre in SQUEEZE erkannten Daten ersetzt. So könnte beispielsweise die Auswahl des Feldes "IBAN" dazu führen, dass ein Dokument in das Verzeichnis der erkannten IBAN abgelegt wird (nicht in einem Verzeichnis mit dem Namen "IBAN").
Feld Drive
Bei der korrekten Eingabe von Host, Tenant ID, Client ID und dem Client Secret, wird im Feld Drive eine Liste von möglichen Verzeichnissen aufgeführt, welches als Home Verzeichnis des SharePoints dienen soll, das Sie auswählen müssen.
Feld Create Folder Structure
Diese Funktion erstellt beim Wert "Ja" ein Pfad Verzeichnis, auch wenn es vorher nicht existiert.
Sollte das Verzeichnis bereits existieren wird kein neues Verzeichnis erstellt.
Der Pfad für das Verzeichnis wird durch das Feld Export Folder Structure bestimmt.
Beim Wert "Nein" wird beim Export an Sharepoint geprüft, ob der Verzeichnis Pfad existiert.
Existiert das Verzeichnis, dann werden die verarbeiteten Dokumente hochgeladen (exportiert).
Existiert das Verzeichnis jedoch nicht, dann wird das Dokument nicht hochgeladen (nicht exportiert).
Es wird beim Export eine entsprechende Fehlermeldung ausgegeben.
Dadurch soll vermieden werden, das unerwartete Verzeichnisse erstellt werden und Dokumente ggf. verschwinden.
Beispiel
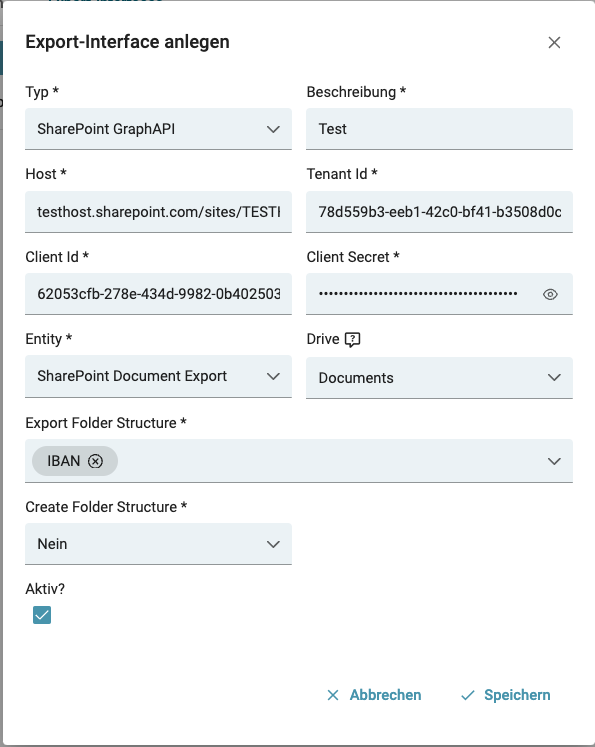
Abbildung - Beispiel ausgefülltes Formular für Export Interface (WIP)
Wenn wir eine neue Applikation in Microsoft Azure erstellt haben, rufen wir diese auf und erhalten folgende Ansicht.
Abbildung - Registrierte Microsoft Applikation "Neue SharePoint Applikation"
Auf dieser Abbildung ist zu sehen was die Client ID ist, sowie wo die Tenant ID zu finden ist.
Bei Auswahl des Menüs "Certificates & secrets" existiert ein kleiner Button mit dem Namen "New client secrets". Nachdem die nötigen Daten angegeben wurden erhalten wir einen neuen Eintrag:

Feldwerte / Metadaten exportieren
Um Feldwerte als Metadaten zu exportieren, beim Upload, müssen diese in der Dokumentenklasse angegeben werden.
Dafür muss das nötige Feld ausgewählt werden, und der entsprechende Wert muss im Feld "Name (Zielsystem)" eingetragen werden.
Abbildung - Kopfdaten-Felder der Dokumentenklasse
Kontrolle der exportierten Dokumente
Ab der SQUEEZE Version 2.29 ist es möglich die Exportvorgänge für jedes Dokument zu kontrollieren.
Um die exportierten Dokumente einsehen und kontrollieren zu können, gehen Sie bitte wie folgt vor:
Öffnen der Dokumentenklasse in der Administration

Auf den Reiter Export-Interfaces wechseln

Hier können Sie über das kleine Tabellensymbol auf die Liste der exportierten Dokumente zugreifen

Die Liste lässt sich normal filtern und sortieren.
Mit dieser Ansicht besteht also die Möglichkeit schnell und einfach zu kontrollieren, wann ein Dokument exportiert wurde.
Benutzer und Rollen
Alle Themen, die mit Benutzerverwaltung und Berechtigungskonzepten in Zusammenhang stehen.
Rollenfilter & Feldbedingungen (bis Squeeze 2.5)
Rollenfilter und Feldbedingungen werden genutzt um das Anzeigen, Validieren, Zurückstellen und Löschen von Dokumenten in Squeeze zu berechtigen.
Rollenfilter
Rollenfilter (im Folgenden kurz "Filter") gehören zum Autorisierungskonzept von SQUEEZE und unterstützen bei feldbasierter Autorisierung von Dokumenten. Mittels dieser Filter ist es möglich für unterschiedliche Benutzergruppen unterschiedliche Dokumente (auch innerhalb einer Dokumentenklasse) zu berechtigen.
Konfiguration
Jeder Rolle können beliebig viele Filter hinzugefügt werden.
Ein Filter steht im Bezug zu einer Dokumentenklasse und berechtigt den Zugriff (lesend & schreibend) auf alle Dokumente dieser Klasse.
Auswertung
Rollenfilter werden mit einem logischen Oder ausgewertet. D. h., wenn einer Rolle mehrere Filter zu der selben Dokumentenklasse zugeordnet sind, dann genügt bereits eine positive Auswertung eines Filters (und seiner Feldbedingungen) aus, um Zugriff auf das Dokument zu erhalten.
Dieses Verhalten gilt auch dann, wenn ein Benutzer Mitglied mehrerer Rollen mit wiederum diversen Filtern ist.
Zusammengefasst: Ein Benutzer erhält Zugriff auf ein Dokument, sobald mindestens eine seiner Rollen über einen Rollenfilter den Zugriff gewährt.
Feldbedingungen
Soll nur auf eine Teilmenge der Dokumente einer Dokumentenklasse berechtigt werden, können Rollenfilter um Feldbedingungen ergänzt werden. Diese erlauben die Filterung von Dokumenten auf Basis ihrer Feldwerte.
Aktuell (Squeeze 2.0 - 2.4) können nicht alle konfigurierbaren Filter korrekt ausgewertet werden. Die Konfiguration solcher Filter ist zwar möglich, sollte aber vermieden werden.
Beispiel: Die Filterung auf ein Textfeld mit einem "Größer als" Komparator (bspw. "Lieferantenname größer als 20") würde zu einem Suchfehler führen.
Wir arbeiten kontinuierlich an Verbesserungen an diesem System. Weiteres finden Sie unter der Überschrift "Besonderheiten".
SQUEEZE 1 unterstützt mehr Komparatoren als SQUEEZE 2. Sollten Sie einen Komparator nutzen, der nicht mehr unterstützt wird, kontaktieren Sie bitte den Support, wenn Sie migrieren möchten.
Konfiguration
An einem Filter können beliebig viele Feldbedingungen definiert werden. Eine Bedingung ist zusammengesetzt aus:
- Dem Feld dessen Inhalt geprüft werden soll
- Dem Komparator, der zur Prüfung genutzt wird
- Dem Vergleichswert (kann von einigen Komparatoren ignoriert werden)
Besonderheiten
Das hier sind bekannte Sonderheiten bei der Konfiguration der Feldbedingungen. Diese werden laufend dokumentiert:
Betragsfelder
- Betragsfelder müssen generell immer mit zwei Stellen nach dem Punkt angegeben werden.
Geben Sie also 200.00 statt 200 ein.
Auswertung
Feldbedingungen werden anders als Rollenfilter mit einem logischen Und verknüpft ausgewertet.
Es müssen also alle Bedingungen erfüllt sein, damit ein Rollenfilter den Zugriff auf ein Dokument gewährt.
Zusammenspiel mehrerer Rollenfilter
Wenn für einen Benutzer mehrere Rollenfilter (mit wiederum diversen Feldbedingungen) ausgewertet werden, dann spielen Rollenfilter ohne Feldbedingungen keine Rolle mehr und werden ignoriert.
Ein Beispiel:
- Eine Rolle hat zwei Filter. Der erste Filter hat keine Feldbedingungen. Der zweite Filter hat eine Feldbedingung.
- Bei der Auswertung dürfen Nutzer der Rolle nur Dokumente sehen, die durch den zweiten Filter freigegeben werden.
Zusammenspiel mit vererbten Rollen
Beispiele
Konfiguration
Im Folgenden Beispiel ist zu sehen:
- Für die Rolle "System Administration" wurde ein Rollenfilter für die Dokumentenklasse "Eingangsrechnung" konfiguriert (1)
- An diesem Rollenfilter hängt eine Feldbedingung. Dokumente müssen im Feld "Barcode" exakt den Wert "123" enthalten, um Usern angezeigt werden zu dürfen. (2)
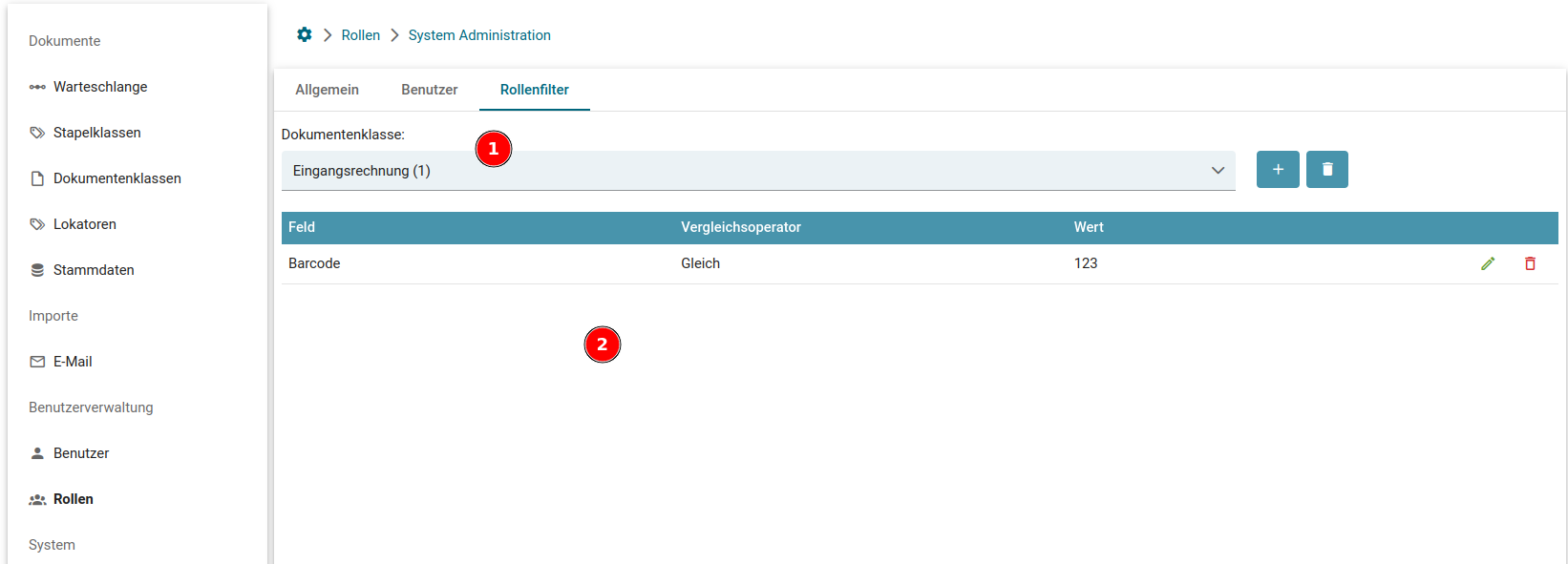
Berücksichtigung in der UI
Dieser Abschnitt stellt dar, in welchen Bereichen der Software, Rollenfilter und Feldbedingungen ausgewertet werden und in welchen nicht. Aus Performance-Gründen ist es nicht überall möglich diese Filter anzuwenden.
Rollenfilter und Feldbedingungen werden aus Performance-Gründen nicht überall in der UI ausgeführt.
Auf dem Dashboard
- Die angezeigte Dokumentensumme in auf den Validierungskacheln berücksichtigt die Rollenfilter nicht.
- Ebenso berücksichtigt die Warteschlange im oberen Bereich die Rollenfilter nicht.

Dokumentensuche
- In der eigentlichen Dokumentensuche (hier ist die Trefferliste zu sehen), werden Rollenfilter berücksichtigt.
- Zu erkennen ist das bspw. daran, dass in der Warteschlange 5 Dokumente in der Validierung gezeigt werden, entsprechend der Rollenfilter aber nur 1 Dokument dem Validierer angezeigt werden.
Validierung
- Wenn ein Dokument direkt in der Validierung angezeigt werden soll, werden Rollenfilter berücksichtigt.
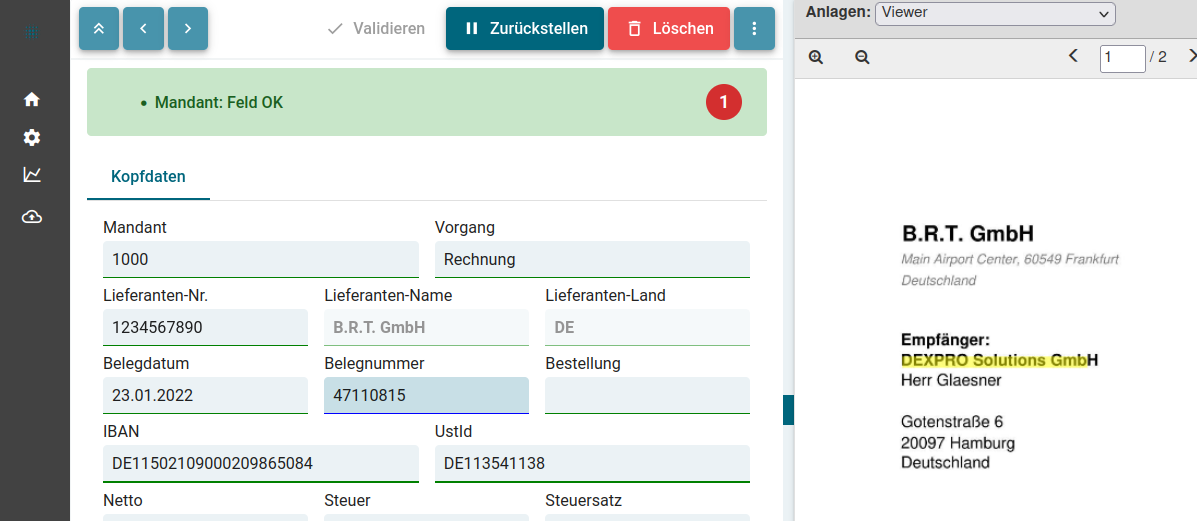
Administration
- In der Administration werden Rollenfilter i. A. nicht angewandt, um gewährleisten zu können, dass Administratoren technische Probleme wie "liegengebliebene" Dokument sehen und lösen können.
FAQ
Es fehlen Dokumente im Validierungsschritt
Bei der Verwendung von Feldbedingungen kann es vorkommen, dass diese nicht korrekt konfiguriert wurden. Das äußert sich dann darin, dass scheinbar eine andere Anzahl an Dokumenten im Validierungsschritt dargestellt wird (Vergleiche Timeline (1) und Ergebnisse der Dokumentensuche (2)). Dieses Verhalten tritt auch bei Admins mit der Root-Rolle auf.
Das ist kein Softwarefehler, sondern Folge der Konfiguration. I. d. R. tritt das bei Projekten auf, wo viele Rollen mit eigenen Filtern eingesetzt werden.
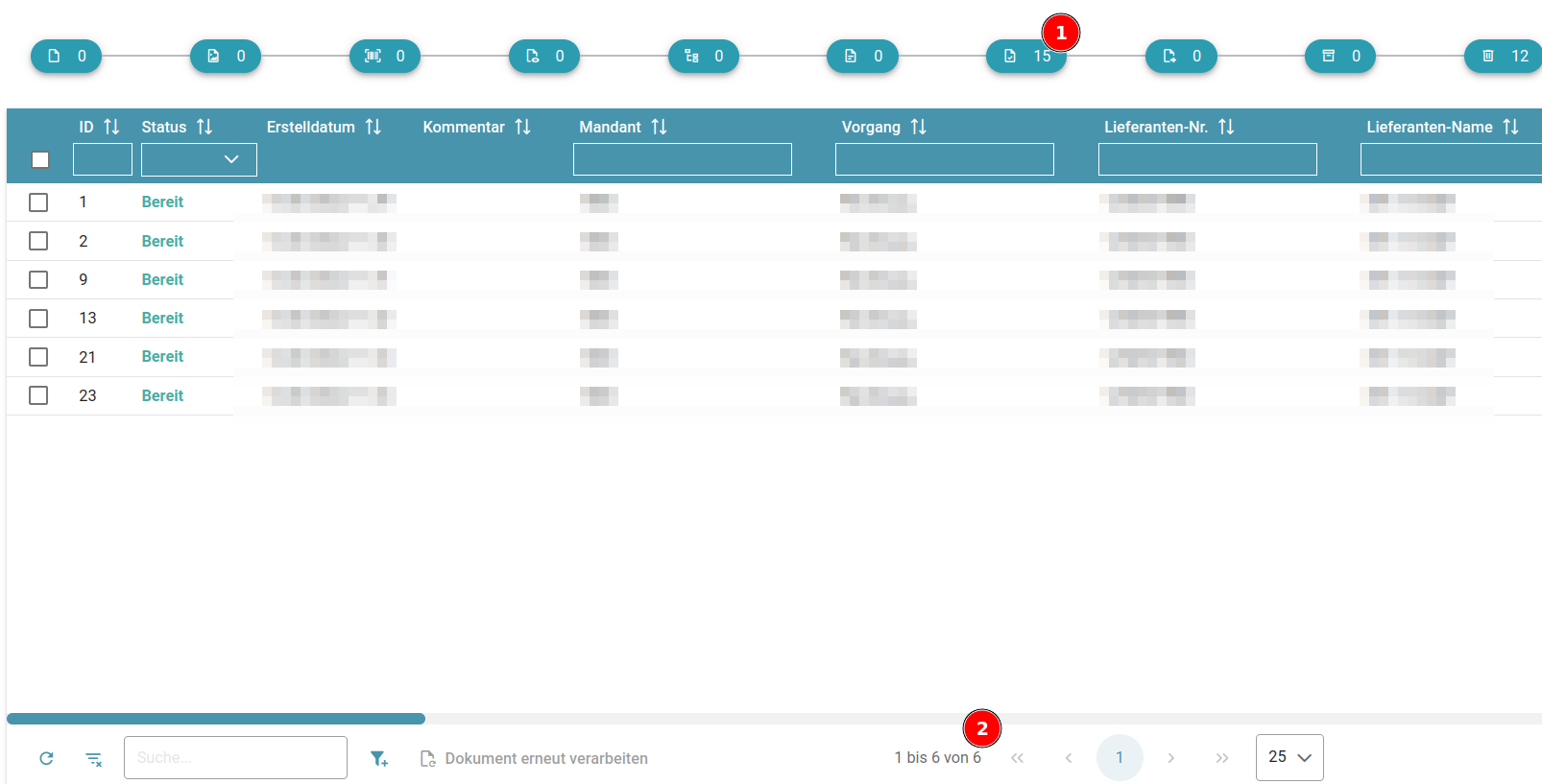
Beispiel-Schaubild
Problem verifizieren: So ist zu testen, ob die Konfiguration der Rollenfilter das Problem für die scheinbar fehlenden Dokumente sind. Wie im vorherigen Text erklärt, erben die Rollen ihre Rollenfilter und deren Rollenfilter-Feldbedingungen von unten nach oben, gehen Sie wie folgt vor um den Fehler zu ermitteln:
- Prüfen Sie die Rolle die ihren Nutzer berechtigt und ermitteln Sie welche Rollen die Rolle bereits durch die Vererbung einschließt.
- Kontrollieren Sie nun jede Rolle und deren Rollenfilter achten Sie auf die Rollenfilter-Feldbedingungen.
Eine Rolle die Zugriff auf alle Dokumentenklassen-Dokumente haben soll muss einen Rollenfilter auf die bezogene Dokumentenklasse besitzen.
Ein Beispiel-Fehlerbild:
Ein Admin kann weniger Dokumente auffinden, als in der Verarbeitungskette (Punkt 1. Abbildung "Beispiel-Schaubild") angezeigt werden. Es gibt mehrere untergeordnete Rollen, die Rollenfilter-Feldbedingungen auf das Feld "Mandant", bspw. "Mandant = 1000", "Mandant = 2000" usw. haben.
- Stellen Sie sicher, dass die Admin-Rolle einen Rollenfilter auf die komplette Dokumentenklasse besitzt. Der Rollenfilter darf keine Feldbedingungen besitzen die den Zugriff einschränken.
Rollenfilter & Feldbedingungen (ab & inkl. Squeeze 2.5)
Rollenfilter und Feldbedingungen werden genutzt um das Anzeigen, Validieren, Zurückstellen und Löschen von Dokumenten in Squeeze zu berechtigen.
Rollenfilter
Rollenfilter (im Folgenden kurz "Filter") gehören zum Autorisierungskonzept von SQUEEZE und unterstützen bei feldbasierter Autorisierung von Dokumenten. Mittels dieser Filter ist es möglich für unterschiedliche Benutzergruppen unterschiedliche Dokumente (auch innerhalb einer Dokumentenklasse) zu berechtigen.
Konfiguration
Jeder Rolle können beliebig viele Filter hinzugefügt werden.
Ein Filter steht im Bezug zu einer Dokumentenklasse und berechtigt den Zugriff (lesend & schreibend) auf alle Dokumente dieser Klasse.
Auswertung
Rollenfilter werden mit einem logischen Oder ausgewertet. D. h., wenn einer Rolle mehrere Filter zu der selben Dokumentenklasse zugeordnet sind, dann genügt bereits eine positive Auswertung eines Filters (und seiner Feldbedingungen) aus, um Zugriff auf das Dokument zu erhalten.
Dieses Verhalten gilt auch dann, wenn ein Benutzer Mitglied mehrerer Rollen mit wiederum diversen Filtern ist.
Zusammengefasst: Ein Benutzer erhält Zugriff auf ein Dokument, sobald mindestens eine seiner Rollen über einen Rollenfilter den Zugriff gewährt.
Feldbedingungen
Soll nur auf eine Teilmenge der Dokumente einer Dokumentenklasse berechtigt werden, können Rollenfilter um Feldbedingungen ergänzt werden. Diese erlauben die Filterung von Dokumenten auf Basis ihrer Feldwerte.
Aktuell (Squeeze 2.0 - 2.4) können nicht alle konfigurierbaren Filter korrekt ausgewertet werden. Die Konfiguration solcher Filter ist zwar möglich, sollte aber vermieden werden.
Beispiel: Die Filterung auf ein Textfeld mit einem "Größer als" Komparator (bspw. "Lieferantenname größer als 20") würde zu einem Suchfehler führen.
Wir arbeiten kontinuierlich an Verbesserungen an diesem System. Weiteres finden Sie unter der Überschrift "Besonderheiten".
SQUEEZE 1 unterstützt mehr Komparatoren als SQUEEZE 2. Sollten Sie einen Komparator nutzen, der nicht mehr unterstützt wird, kontaktieren Sie bitte den Support, wenn Sie migrieren möchten.
Konfiguration
An einem Filter können beliebig viele Feldbedingungen definiert werden. Eine Bedingung ist zusammengesetzt aus:
- Dem Feld dessen Inhalt geprüft werden soll
- Dem Komparator, der zur Prüfung genutzt wird
- Dem Vergleichswert (kann von einigen Komparatoren ignoriert werden)
Besonderheiten
Das hier sind bekannte Sonderheiten bei der Konfiguration der Feldbedingungen. Diese werden laufend dokumentiert:
Betragsfelder
- Betragsfelder mit den folgenden Kombinationen aus Tausendertrennzeichen und Dezimaltrenner konfiguriert werden:
- 2187,50
- 2187.50
- 2.187,50
- 2,187.50
Auswertung
Feldbedingungen werden anders als Rollenfilter mit einem logischen Und verknüpft ausgewertet.
Es müssen also alle Bedingungen erfüllt sein, damit ein Rollenfilter den Zugriff auf ein Dokument gewährt.
Zusammenspiel mehrerer Rollenfilter
Wenn für einen Benutzer mehrere Rollenfilter (mit wiederum diversen Feldbedingungen) ausgewertet werden, dann gilt weiterhin, dass nur einer der Rollenfilter positiv ausgewertet werden muss.
Ein Beispiel:
- Eine Rolle hat zwei Filter. Der erste Filter hat keine Feldbedingungen. Der zweite Filter hat eine Feldbedingung.
- Bei der Auswertung dürfen Nutzer alle Dokumente der Dokumentenklasse sehen.
Zusammenspiel mit vererbten Rollen
Beispiele
Konfiguration
Im Folgenden Beispiel ist zu sehen:
- Für die Rolle "System Administration" wurde ein Rollenfilter für die Dokumentenklasse "Eingangsrechnung" konfiguriert (1)
- An diesem Rollenfilter hängt eine Feldbedingung. Dokumente müssen im Feld "Barcode" exakt den Wert "123" enthalten, um Usern angezeigt werden zu dürfen. (2)
Berücksichtigung in der UI
Dieser Abschnitt stellt dar, in welchen Bereichen der Software, Rollenfilter und Feldbedingungen ausgewertet werden und in welchen nicht. Aus Performance-Gründen ist es nicht überall möglich diese Filter anzuwenden.
Rollenfilter und Feldbedingungen werden aus Performance-Gründen nicht überall in der UI ausgeführt.
Auf dem Dashboard
- Die angezeigte Dokumentensumme in auf den Validierungskacheln berücksichtigt die Rollenfilter nicht.
- Ebenso berücksichtigt die Warteschlange im oberen Bereich die Rollenfilter nicht.
Dokumentensuche
- In der eigentlichen Dokumentensuche (hier ist die Trefferliste zu sehen), werden Rollenfilter berücksichtigt.
- Zu erkennen ist das bspw. daran, dass in der Warteschlange 5 Dokumente in der Validierung gezeigt werden, entsprechend der Rollenfilter aber nur 1 Dokument dem Validierer angezeigt werden.
Validierung
- Wenn ein Dokument direkt in der Validierung angezeigt werden soll, werden Rollenfilter berücksichtigt.
Administration
- In der Administration werden Rollenfilter i. A. nicht angewandt, um gewährleisten zu können, dass Administratoren technische Probleme wie "liegengebliebene" Dokument sehen und lösen können.
FAQ
Es fehlen Dokumente im Validierungsschritt
Bei der Verwendung von Feldbedingungen kann es vorkommen, dass diese nicht korrekt konfiguriert wurden. Das äußert sich dann darin, dass scheinbar eine andere Anzahl an Dokumenten im Validierungsschritt dargestellt wird (Vergleiche Timeline (1) und Ergebnisse der Dokumentensuche (2)). Dieses Verhalten tritt auch bei Admins mit der Root-Rolle auf.
Das ist kein Softwarefehler, sondern Folge der Konfiguration. I. d. R. tritt das bei Projekten auf, wo viele Rollen mit eigenen Filtern eingesetzt werden.
Beispiel-Schaubild
Problem verifizieren: So ist zu testen, ob die Konfiguration der Rollenfilter das Problem für die scheinbar fehlenden Dokumente sind. Wie im vorherigen Text erklärt, erben die Rollen ihre Rollenfilter und deren Rollenfilter-Feldbedingungen von unten nach oben, gehen Sie wie folgt vor um den Fehler zu ermitteln:
- Prüfen Sie die Rolle die ihren Nutzer berechtigt und ermitteln Sie welche Rollen die Rolle bereits durch die Vererbung einschließt.
- Kontrollieren Sie nun jede Rolle und deren Rollenfilter achten Sie auf die Rollenfilter-Feldbedingungen.
Eine Rolle die Zugriff auf alle Dokumentenklassen-Dokumente haben soll muss einen Rollenfilter auf die bezogene Dokumentenklasse besitzen.
Ein Beispiel-Fehlerbild:
Ein Admin kann weniger Dokumente auffinden, als in der Verarbeitungskette (Punkt 1. Abbildung "Beispiel-Schaubild") angezeigt werden. Es gibt mehrere untergeordnete Rollen, die Rollenfilter-Feldbedingungen auf das Feld "Mandant", bspw. "Mandant = 1000", "Mandant = 2000" usw. haben.
- Stellen Sie sicher, dass die Admin-Rolle einen Rollenfilter auf die komplette Dokumentenklasse besitzt. Der Rollenfilter darf keine Feldbedingungen besitzen die den Zugriff einschränken.
Rollen
Rollen
Rollen können genutzt werden, um den Dokumentenzugriff zu verwalten und die Verwendung von Funktionen wie Benutzerverwaltung zu authorisieren.
Das zugrundeliegende Authorisierungskonzept ist RBAC.

Konfiguration
Es können beliebig viele Rollen angelegt werden. Jede Rolle verfügt über einen Namen und eine Beschreibung.
Außerdem muss jeder Rolle eine Eltern-Rolle zugeordnet werden. Durch diese Zuordnung entsteht eine Rollenhierarchie, welche bspw. genutzt werden kann, um Organisationsstrukturen abzubilden.
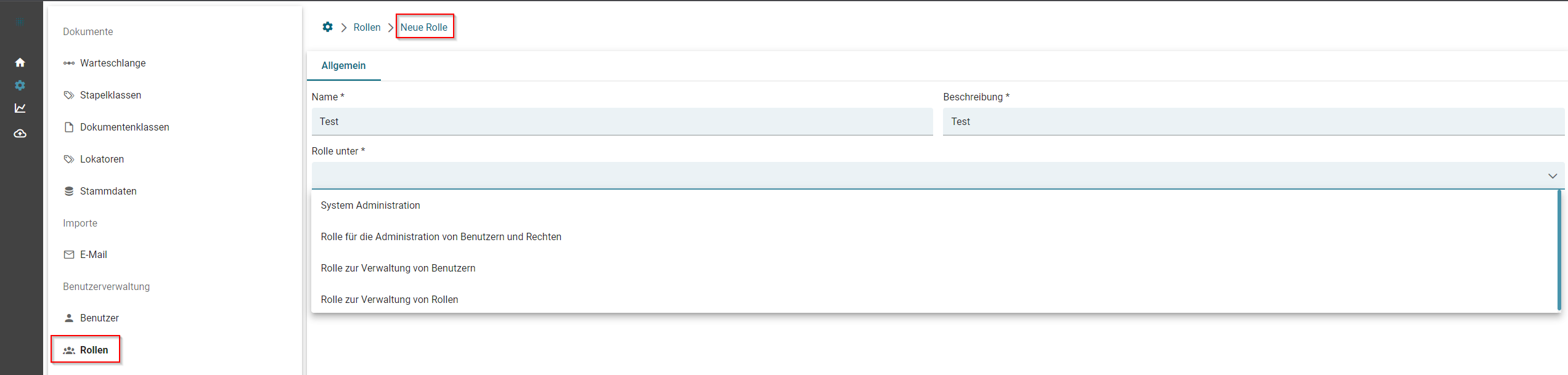
Benutzerzuordnung & Vererbung
Ein Benutzer kann zu beliebig vielen Rollen hinzugefügt werden.
Der zugeordnete Benutzer ist implizit Mitglied aller Sub-Rollen der zugeordneten Rolle.
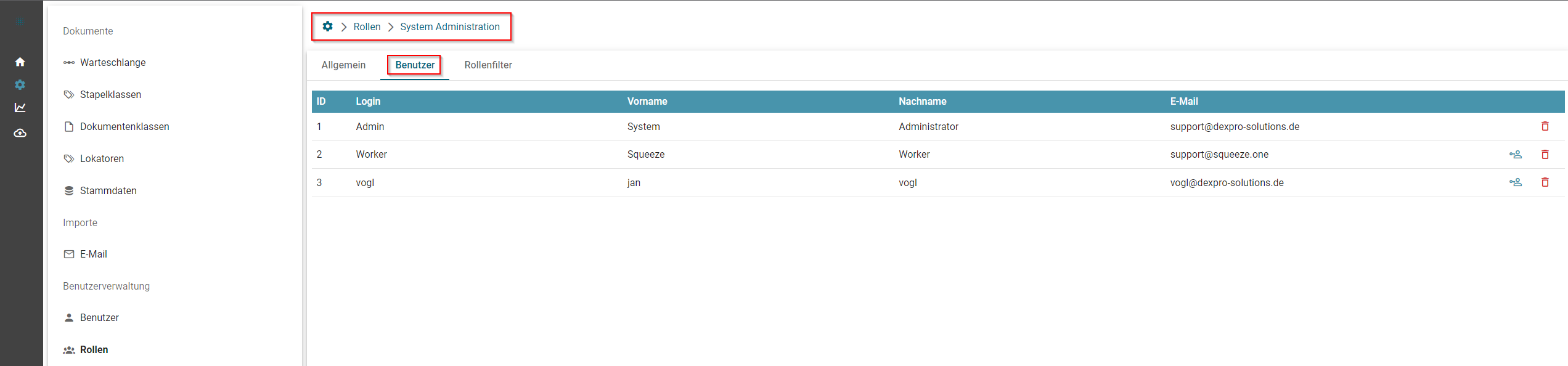
Benutzer anlegen
Um einen Benutzer anzulegen klicken Sie in der Benutzerverwaltung auf Benutzer. Dort klicken Sie auf das Symbol "+ Neuer Eintrag" .
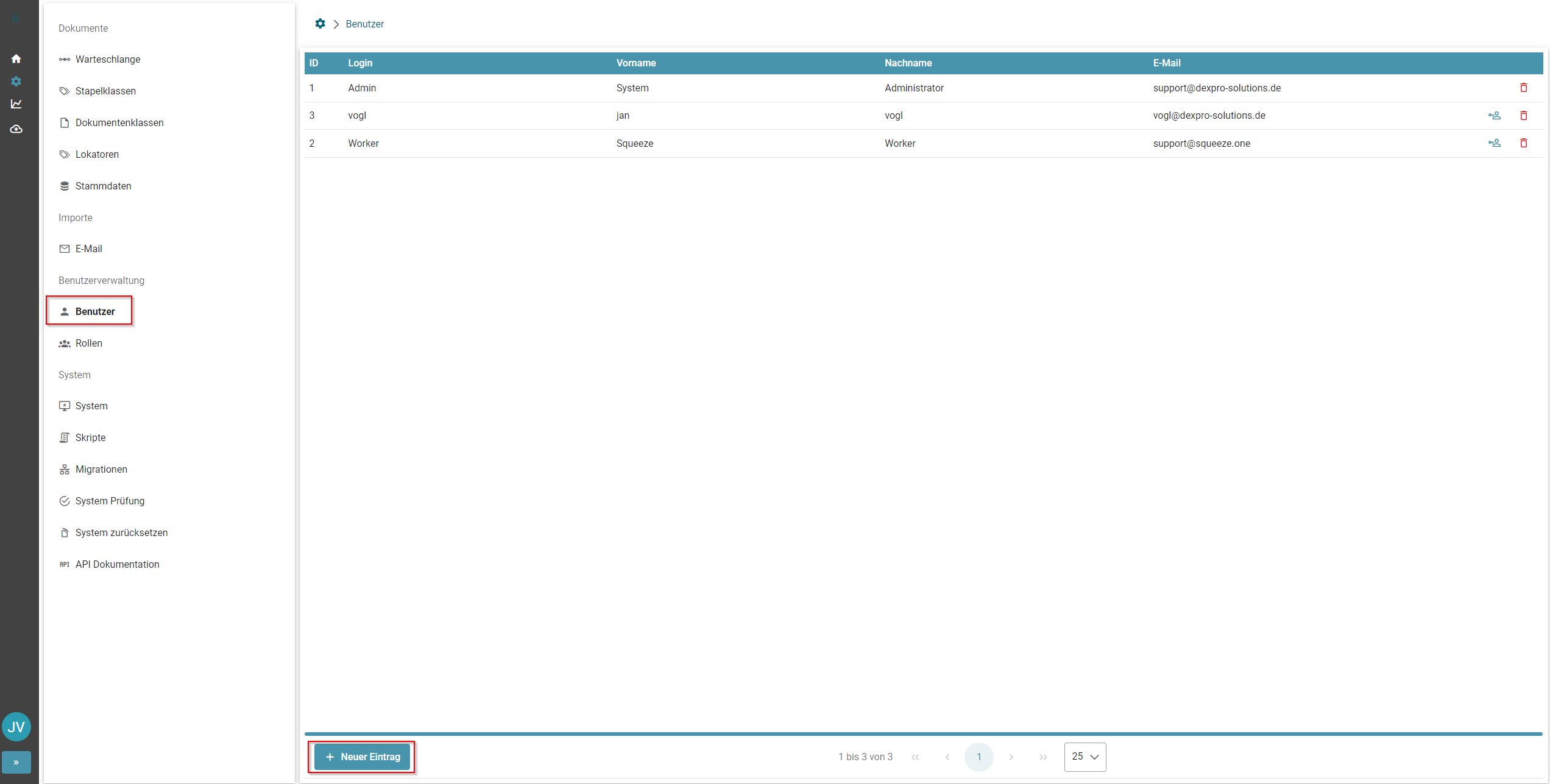
Unter dem Reiter "Allgemein" müssen jetzt alle mit einem "*"gekennzeichneten Felder ausgefüllt werden. Danach kann der Benutzer über das "Speichern" Symbol angelegt werden.
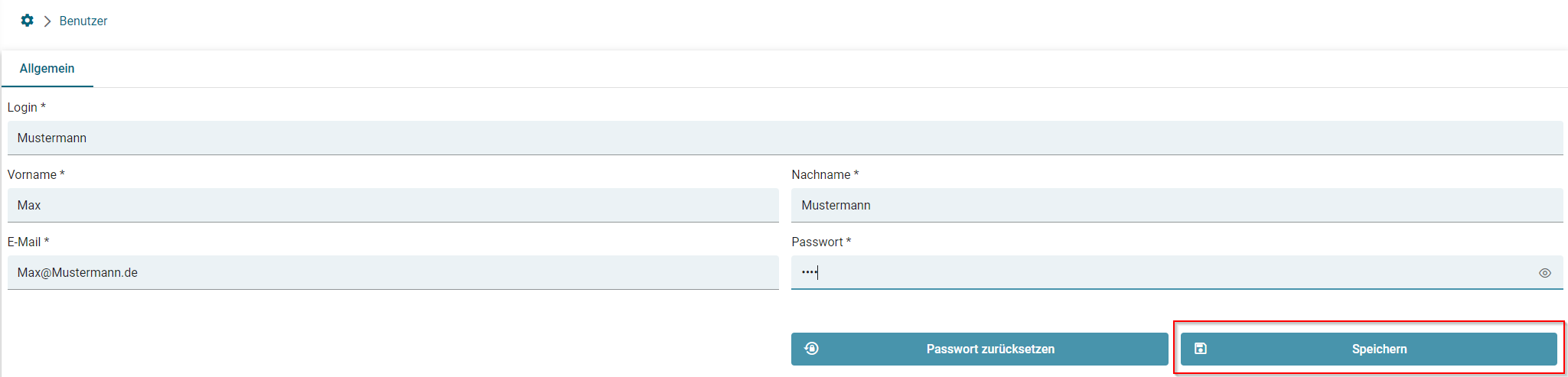
Nachdem ein Benutzer angelegt worden ist, sollte er immer mindestens einer Rolle hinzugefügt werden, da dieser Benutzer ansonsten keine Dokumente ansehen kann.
Standard-Rollen von SQUEEZE
Diese Rollen sind in jedem SQUEEZE Mandanten vorhanden. Sie berechtigen Benutzer auf Teilbereiche der Anwendung, insbesondere die Administration.
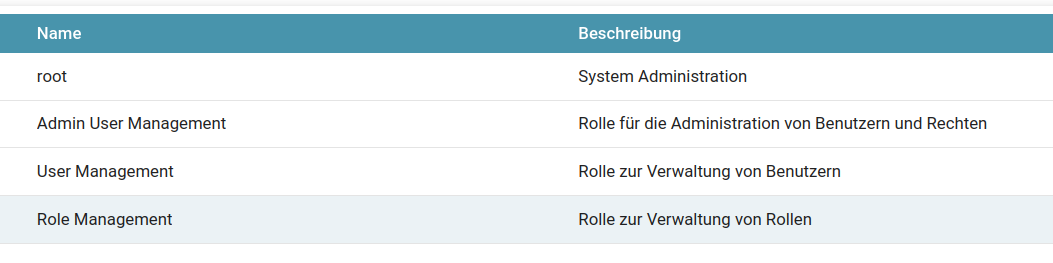
Rollen und ihre Berechtigungen
root
Diese Rolle gibt vollständige Berechtigungen auf alle Funktionen.
Admin User Management
Diese Rolle beinhaltet User Management und Role Management
User Management
Diese Rolle berechtigt darauf Benutzer anzulegen, zu verändern, ihre Rollen zu verwalten usw.
Role Management
Diese Rolle berechtigt dazu Rollen anzulegen, verändern und zu löschen.
SSO / OAuth / OpenID Connect
Benutzerverwaltung mittels SSO, OAuth und OpenID Connect.
Login mit Microsoft
Mit der Squeeze Version 2.20 besteht die Möglichkeit des einfachen Logins mit Hilfe von Microsoft Entra ID auch bekannt als Azure AD.
Auf dieser Seite wird beschrieben wie sie vorgehen können, um einen Login Button auf der Anmeldeseite von Squeeze anzeigen zulassen. Nach Abschluss der Konfiguration sieht die Anmeldeseite wie folgt aus:
Konfiguration in Microsoft Entra ID
Erstellen Sie ein Microsoft Entra App für ihr Unternehmen
Die Redirect URL ist die URL Ihres Squeeze Tenants mit der zusätzlichen Pfadangabe /sso/
In diesen Beispiel ist es https://private.squeeze.one/sso/
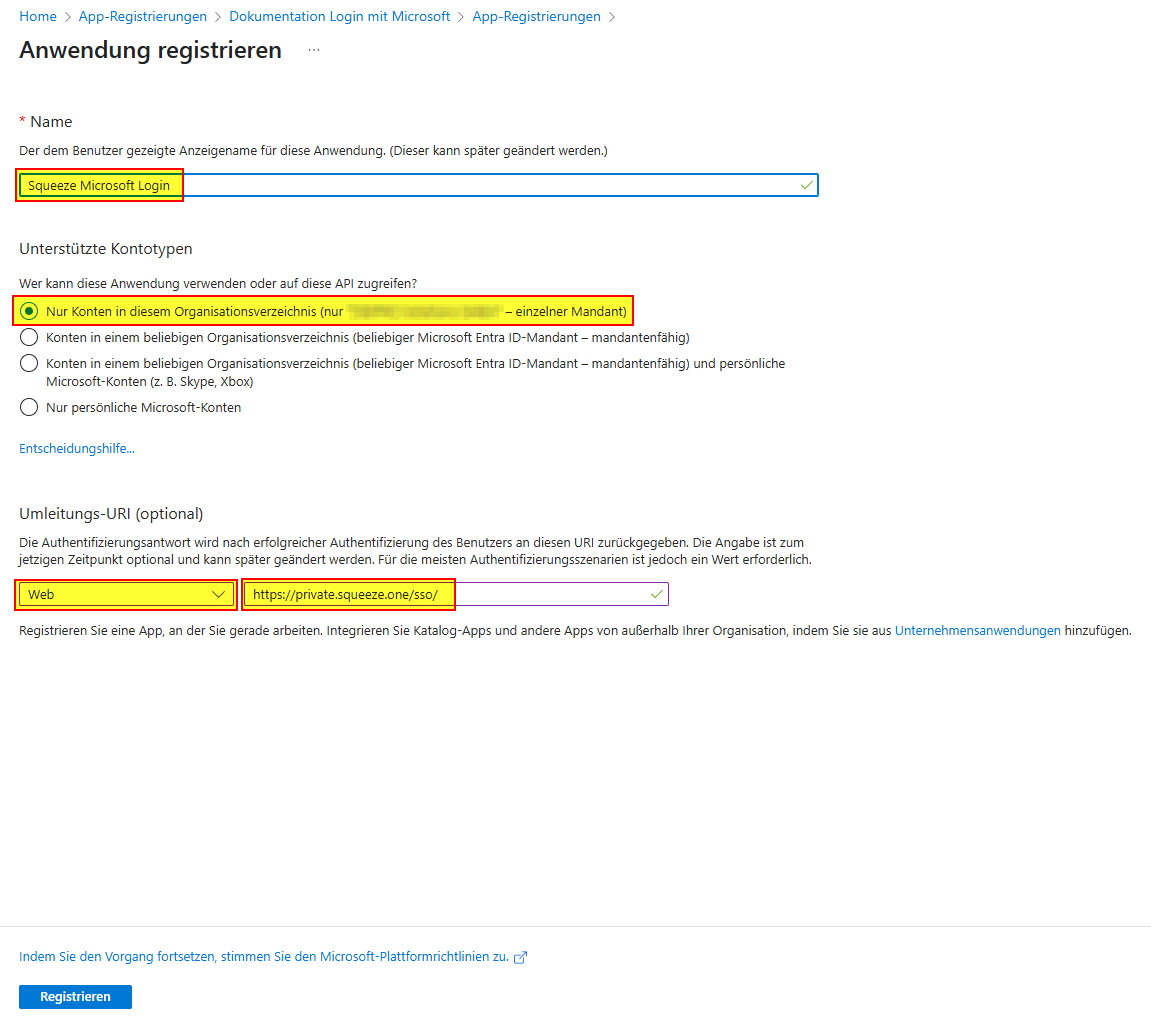
Secret für die App erstellen
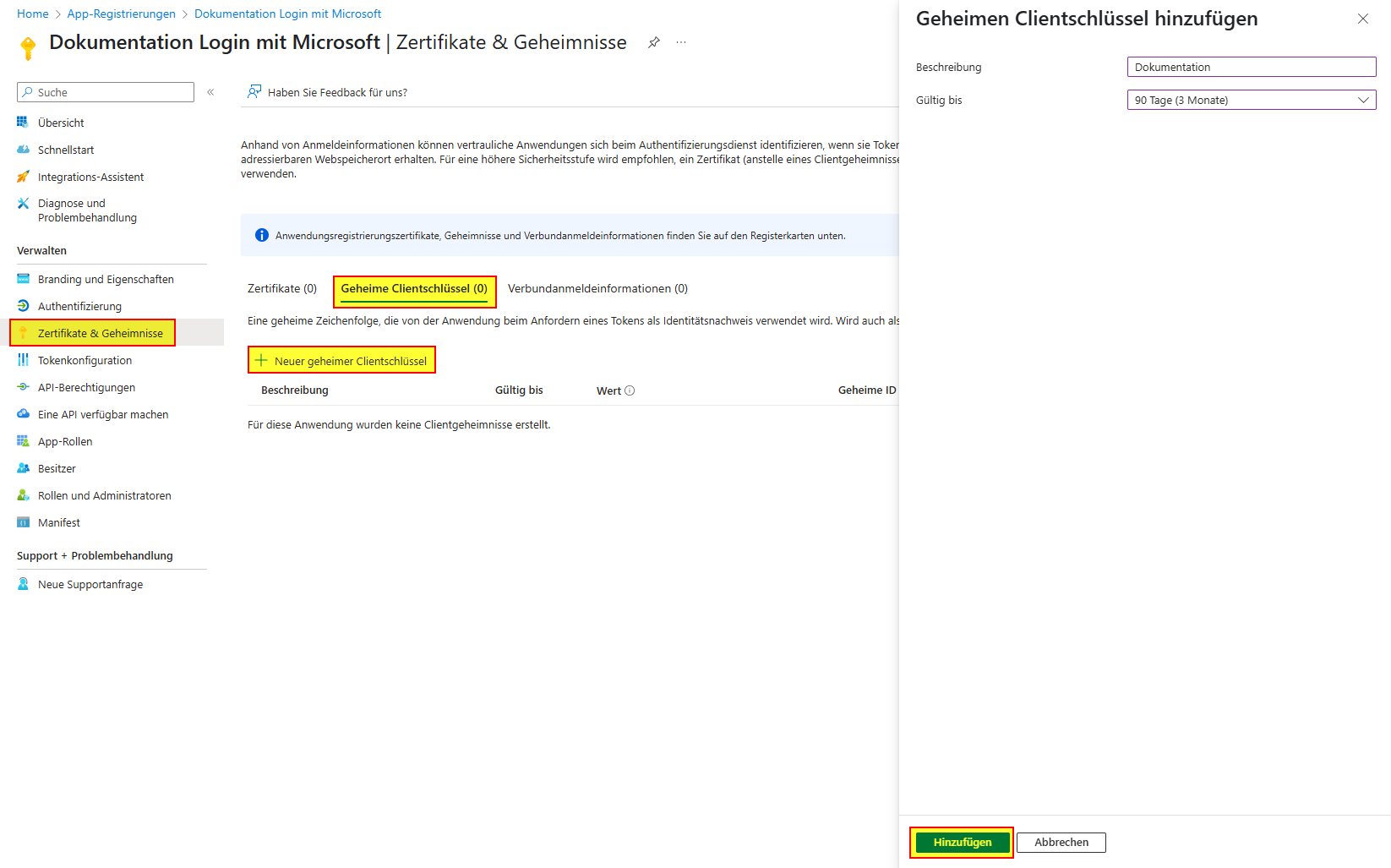
Kopieren Sie das Secret.
Beachten Sie, dass das Secret später nicht mehr eingesehen/kopiert werden kann.
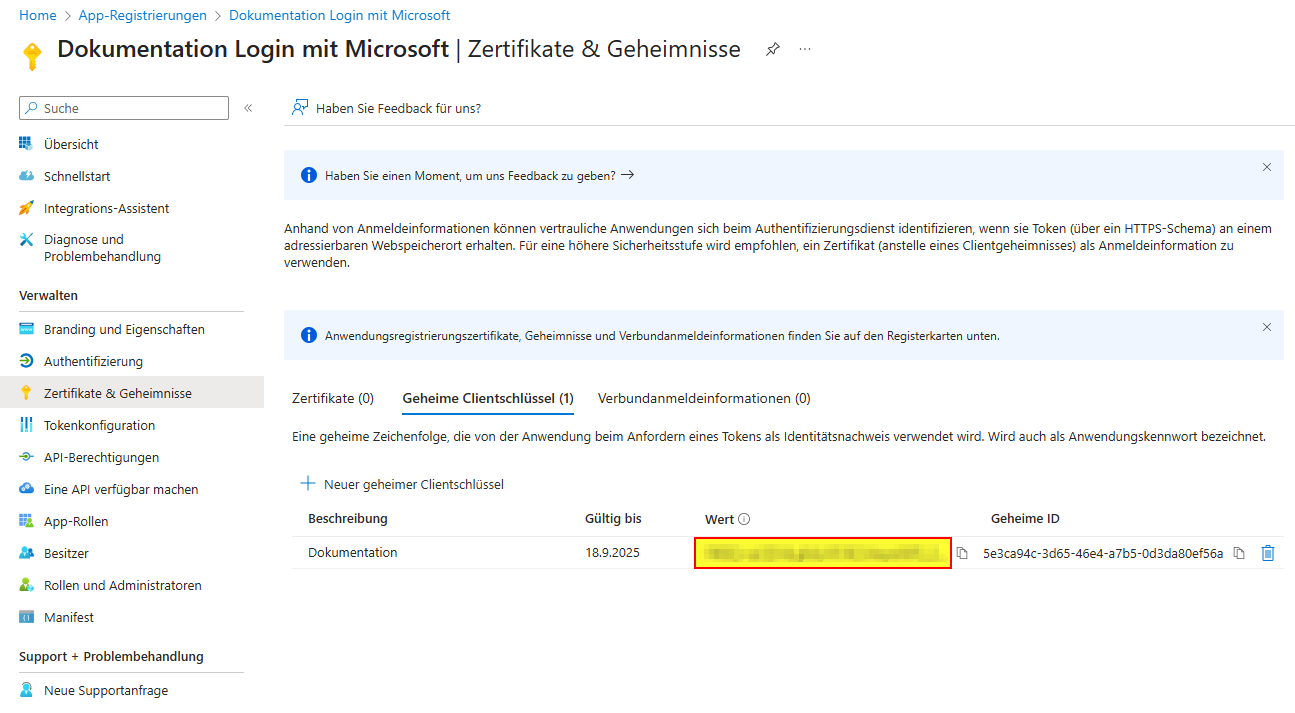
API-Berechtigungen festlegen
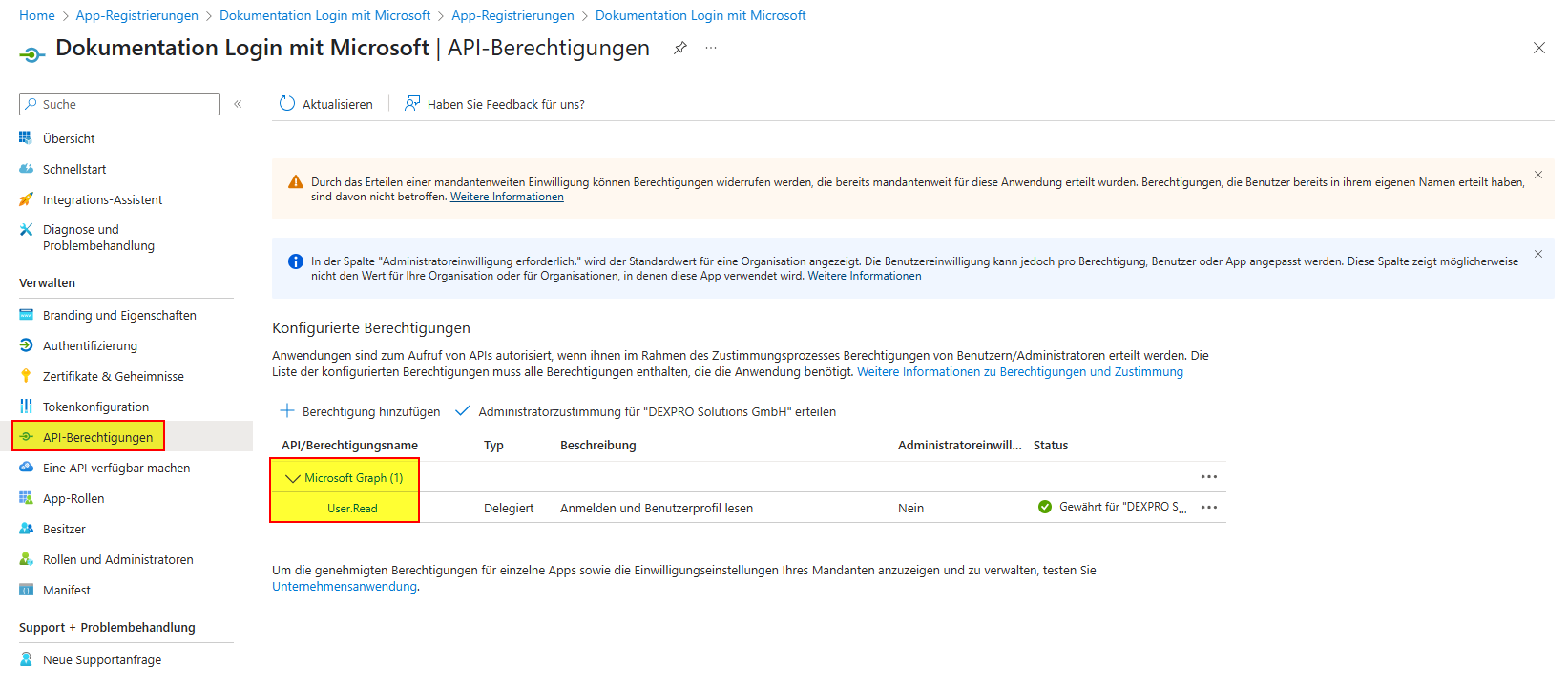
Client App-Id und Secret in Squeeze hinterlegen
Das Secret ist nach dem Speichern nicht mehr einsehbar.
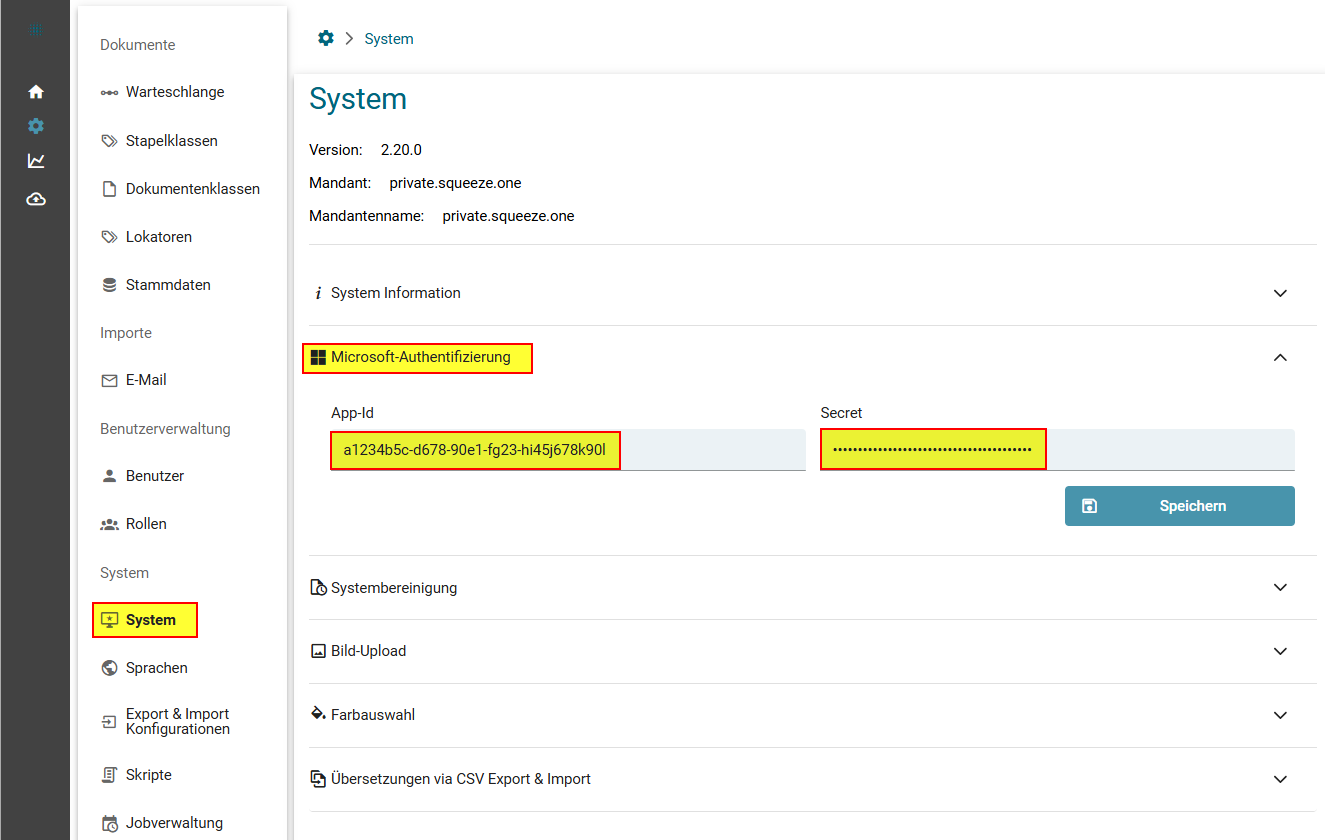
Digitale Formate (XML, XRechnung, ZUGFeRD)
Dieses Kapitel behandelt die Verarbeitung von digitalen Formaten, die nicht mit visuellen Repräsentation eines Dokumentes (also Bilder, Scans, PDFs) zusammenhängen.
Das sind Formate wie XRechnung, ZUGFeRD usw. die üblicherweise als XML- oder JSON-Dateien verschickt werden.
Einführung Digitale Formate: XML, XRechnung und ZUGFeRD in der Software Squeeze
Willkommen zur Dokumentation von Squeeze, insbesondere des Moduls Elektronische-Daten, einer leistungsstarken Komponente zur Verarbeitung digitaler Formate.
In dieser Dokumentation erfahren Sie alles Wichtige zur Nutzung und Verwaltung dieses Moduls, der Schwerpunkt liegt hierbei auf der Verarbeitung von gängigen, digitalen, Formate wie ZUGFeRD und XRechnung. Obwohl die Unterstützung für benutzerdefinierte XML-Formate (Customized XMLs) noch nicht verfügbar ist, wird diese Funktionalität in zukünftigen Updates bereitgestellt.
Digitale Formate im Überblick
In der heutigen digitalen Geschäftswelt sind effiziente und standardisierte Datenformate unerlässlich. Die folgenden Formate spielen dabei eine besonders wichtige Rolle:
XML (Extensible Markup Language) XML ist ein vielseitiges und weit verbreitetes Datenformat, das speziell für die strukturierte Datenspeicherung und -übertragung entwickelt wurde. Es ermöglicht die Definition eigener Tags und Strukturen, was es zu einem flexiblen Werkzeug für unterschiedlichste Anwendungen macht. Der Einsatz von XML sorgt für eine effiziente und transparente Datenkommunikation.
XRechnung XRechnung ist ein speziell für elektronische Rechnungen entwickeltes Format, das in vielen europäischen Ländern, einschließlich Deutschland, gesetzlich vorgeschrieben ist. Es basiert auf XML und erfüllt die Anforderungen der Europäischen Norm EN 16931. Durch die Standardisierung von Rechnungsdaten ermöglicht XRechnung eine einfache und effiziente Verarbeitung und Archivierung elektronischer Rechnungen.
ZUGFeRD (Zentraler User Guide des Forums elektronische Rechnung Deutschland) ZUGFeRD ist ein hybrides Rechnungsformat, das sowohl ein menschenlesbares PDF-Dokument, als auch maschinenlesbare XML-Daten kombiniert. Dieses Format vereinfacht die Rechnungsverarbeitung, indem es die Vorteile beider Formate nutzt. Es ist besonders nützlich für Unternehmen, die mit unterschiedlichen Geschäftspartnern zusammenarbeiten und verschiedene Anforderungen an Rechnungsformate erfüllen müssen.
Squeeze: Ihre Lösung für die Verarbeitung digitaler Formate
Squeeze ist darauf ausgelegt, die Verarbeitung von ZUGFeRD- und XRechnung-Formaten nahtlos zu integrieren. Mit Squeeze können Unternehmen ihre Rechnungsprozesse effizient automatisieren und sicherstellen, dass sie den aktuellen gesetzlichen Anforderungen entsprechen. Die Unterstützung für benutzerdefinierte XML-Formate ist in der Entwicklung und wird in einer zukünftigen Version von Squeeze verfügbar sein, hier finden Sie die aktuell unterstützten Formate.
Hauptfunktionen von Squeeze:
- Verarbeitung von ZUGFeRD-Rechnungen: Squeeze kann ZUGFeRD-Rechnungen problemlos einlesen und die enthaltenen Daten sowohl aus dem PDF- als auch aus dem XML-Teil extrahieren.
- Unterstützung für XRechnung: Squeeze ermöglicht die einfache Handhabung von XRechnungen, was die Konformität mit europäischen Vorschriften sicherstellt.
- Prüfbericht der Koordinierungsstelle für IT-Standards(KoSIT): Squeeze generiert auf Kundenwunsch Konformitätsnachweise für XML-Daten gemäß den KoSIT-Standards.
- Umschlüsselung von technischen Codes in Werte:
Mit Squeeze können Codes die in elektronischen Belegen genutzt werden in hausinterne Werte umgeschlüsselt werden.
Weiterführende Informationen
In den folgenden Kapiteln dieser Dokumentation finden Sie detaillierte Anleitungen zur Funktionsweise, Konfiguration und Verwaltung des Moduls Digitale Formate.
Wir empfehlen, diese Dokumentation gründlich zu lesen und bei Bedarf als Referenz zu verwenden, um das volle Potenzial von Squeeze auszuschöpfen.
XML-Pipeline
In der XML-Pipeline von Squeeze werden XML-Dokumente durch speziell angepasste Verarbeitungsstufen geführt, um den unterschiedlichen Anforderungen der Datenextraktion und Dokumentenkategorisierung gerecht zu werden.
| Schritt | Aktuelle Pipeline |
|---|---|
|
Einganskanäle |
- Alle Eingangskanäle prüfen die Dokumente auf ihre Validität in Bezug auf die EN16931-Spezifikationen. |
|
Initialisierungs-Schritt |
- Hochgeladene XML-Dateien werden in ein internes Standard-XML-Format ( - Je nach Kundenwunsch wird in diesem Schritt ein KoSIT-Prüfbericht erstellt. |
|
Barcode- Extraktions-Schritt |
- Viewer-Bilder auf Basis der PDF werden erstellt, gilt auch für ZUGFeRD und XRechnung |
|
OCR-Schritt |
- PDF-Dateien mit eingebetteten XML werden normal verarbeitet, um ein OCR-Ergebnis zu erstellen. - Dieser Schritt wird für reine XML-Dateien übersprungen. |
|
Klassifizierungs-Schritt |
- Die Klassifizierung von XML-Dokumenten ist derzeit nicht möglich. Eine Fehler wird erzeugt, sobald das Dokument keine Dokumentenklasse nachweist |
|
Extraktions-Schritt |
- Übliche Extraktionsmechanismen werden ausgeführt oder übersprungen durch die Stapelklasseneigenschaft: - |
Extraktion von XMLs
In der XML-Pipeline von Squeeze erfolgt die XML-Extraktion als letzter Schritt vor der Autovalidierung/Validierung und hat dabei eine besondere Rolle: Sie überschreibt extrahierte Feldwerte aus den KI-Extraktionen und den Lokatoren-Ergebnissen. Die Extraktion von XML-Daten basiert auf dem Mapping, welches im Administrationsbereich angepasst werden kann. Alternativen werden gemäß der Definition im Mapping verarbeitet.
Rendering von XMLs
Das XML-Rendering in Squeeze bezieht sich auf den Prozess der Erstellung von PDF-Dokumenten aus XML-Dateien. Dieser Prozess unterscheidet sich je nach Art des XML-Dokuments und umfasst spezifische Anforderungen für standardisierte und benutzerdefinierte XML-Formate.
Rendering von Spezifischen XML-Dokumenten
Für standardisierte XML-Formate wie XRechnung und ZUGFeRD, die der Norm EN16931 entsprechen, erfolgt das Rendering nach den folgenden Schritten:
-
Erstellung des Zwischenformats: Im InitStep wird aus der XML-Datei ein Zwischenformat erstellt, das als Basis für das PDF-Rendering dient. Dieses Zwischenformat wird aus der
intermediate.xmlgeneriert, die die für die PDF-Erstellung benötigten Daten enthält. -
PDF-Erzeugung: Basierend auf dem Zwischenformat wird ein PDF-Dokument erstellt, das die strukturierten Daten aus der XML übersichtlich darstellt. Dies ermöglicht die Generierung von PDFs, die den Anforderungen der jeweiligen Spezifikation entsprechen und für den Austausch und die Archivierung verwendet werden können.
Ausblick
In einer zukünftigen Version von Squeeze ist geplant, auch für XML-Dokumente, die nicht den EN16931-Spezifikationen entsprechen, eine vollständige Verarbeitung zu ermöglichen. Diese Weiterentwicklung wird es erlauben, alle Arten von XML-Dokumenten einheitlich und umfassend zu behandeln, wodurch die Integration und Handhabung von benutzerdefinierten XML-Formaten weiter verbessert wird.
XRechnung und ZUGFeRD
XRechnung und ZUGFeRD sind digitale Rechnungsformate, welche in der Praxis als XML-Dateien oder PDFs mit eingebetteten XML-Daten verschickt werden.
Validierung von digitalen Rechnungen
Nicht alle digitalen Rechnungen, die Sie erhalten erfüllen die öffentlichen Standards. In der Praxis kann es daher passieren, dass Lieferanten digitale Rechnungen senden, die nicht durch Squeeze verarbeitet werden, weil die Dateien nicht valide sind.
Eine digitale Rechnung ist valide, wenn sie diese zwei Kriterien erfüllt:
- Die Datei (i. d. R. XML) ist korrekt formatiert. Sie enthält also gültiges XML
- Die fachlichen Kriterien an eine EN-16931 + Extension XML sind erfüllt. Beispiel: Die Rechnung enthält eine gültige Kombination aus Netto-, Steuer- und Brutto-Beträgen.
In der Validierung (UI) weist ein Icon darauf hin, dass ein Dokument als XRechnung verarbeitet wurde.
Validatoren
Hier ein Liste von Validatoren, mit denen Sie prüfen können, ob eine digitale Rechnung valide ist:
- https://erechnungsvalidator.service-bw.de/
- https://validator.invoice-portal.de/
- https://ecosio.com/en/peppol-and-xml-document-validator/
- https://peppol.munich-enterprise.com/xrechnung/
- https://www.zugferd-community.net/de/dashboard/validation (Speziell auch alle ZugFERD Varianten)
Extraktion
|
Schritt |
|
|---|---|
|
Extraktion |
|
Konfiguration von XML-Auswertungen
Ab der Version 2.13 und nach Freischaltung durch Dexpro oder einen der Partner, können Sie in die Extraktion von XML-Werten bei EN16931 konformen XML-Dokumenten eingreifen.
Siehe auch XRechnung und ZUGFeRD Auswertungstabellen
PDF-Rendering
Das PDF-Rendering für XRechnung und ZUGFeRD hat sich ebenfalls geändert:
-
EN-16931 konforme XML-Dokumente: Für standardisierte XML-Dokumente wie XRechnung und ZUGFeRD wird eine PDF aus dem Zwischenformat erstellt, das im InitStep generiert wurde. Dieses Zwischenformat basiert auf der
intermediate.xmlund wird genutzt, um alle relevanten Daten in einer übersichtlichen PDF-Darstellung zu präsentieren.
In der zukünftigen Version von Squeeze wird die vollständige Unterstützung für die PDF-Erzeugung von nicht EN16931-konformen XML-Dokumenten implementiert. Dies wird die Flexibilität und Integration für benutzerdefinierte XML-Formate weiter verbessern.
XML-Prüfbericht KoSIT
Ab Version 2.15 von Squeeze bietet unsere Squeeze-Lösungen die Möglichkeit, automatisch Prüfberichte für verarbeitete ZUGFeRD und XRechnung-Daten zu erstellen. Diese Berichte entsprechen den KoSIT-Standards und gewährleisten die Datenqualität. Während bei XRechnungen eine strikte Fehlerprüfung erfolgt, um die Datenintegrität zu schützen, bietet das System für ZUGFeRD-Belege eine größere Flexibilität. Dies ermöglicht eine individuelle Anpassung der Verarbeitungsprozesse an die spezifischen Anforderungen der Kunden.
Die Aktivierung der Funktionalität erfolgt durch unsere Partner oder unserer Berater. Den KoSIT Prüfbericht, können Sie sich in der Validierung des Dokumentes anzeigen lassen oder direkt über das Kontext-Menü in der Validierung herunterladen.
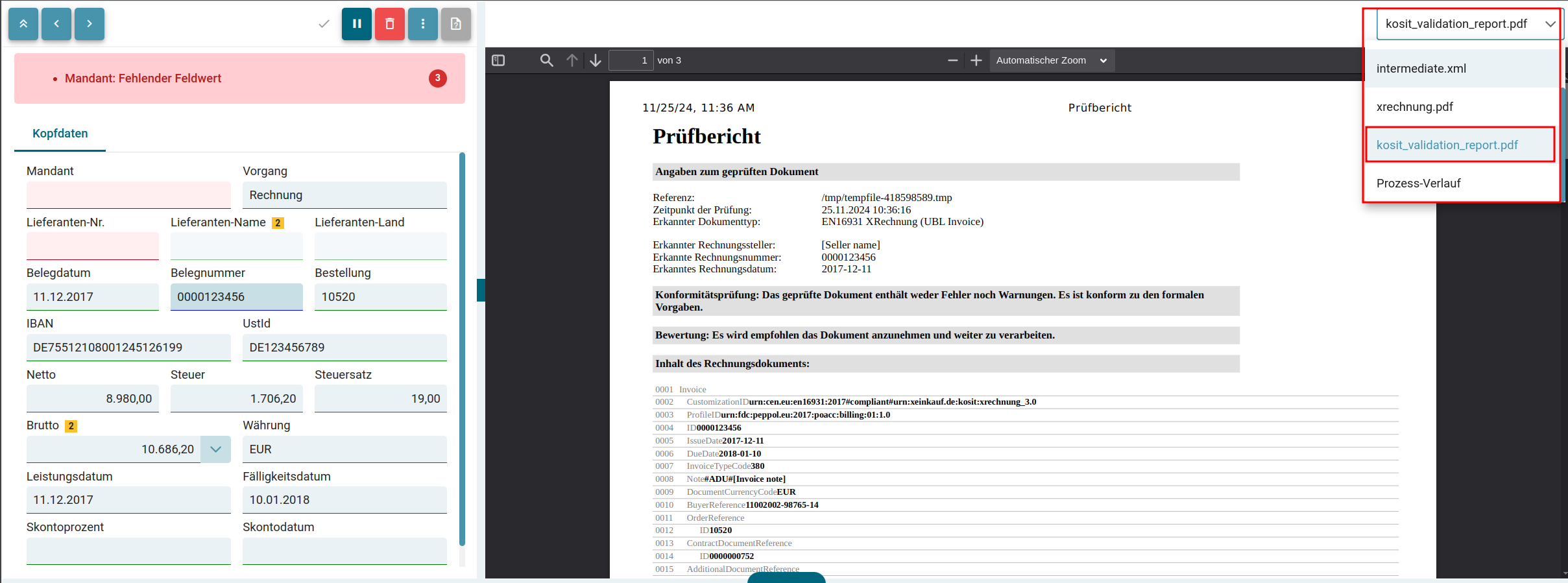
Validierungsoberfläche
Umschlüsselung von Codes in Werte
Ab der Version 2.16 ist es möglich, Codes die in elektronischen Belegen genutzt werden in eigene Werte umzuschlüsseln. Solche Codes werden z.B. verwendet um Mengeneinheiten festzulegen, Steuerfälle zu definieren oder auch um den Vorgang festzulegen.
Hier die Anleitung, wie die Umschlüsselung der Codes aus elektronischen Belegen konfiguriert werden kann.
Auswertungstabellen XRechnung und ZUGFeRD
Standardmäßig werden bereits viele Felder automatisch erkannt und extrahiert. Eine Übersicht der standardmäßig unterstützten Felder finden Sie in den folgenden Tabellen:
Kopfdaten:
| Dokumentenklassen-Feld | Xpath |
|---|---|
| VatId | /xr:invoice[1]/xr:SELLER[1]/xr:Seller_VAT_identifier[1] |
| DocumentReference | /xr:invoice[1]/xr:Invoice_number[1] |
| DocumentDate | /xr:invoice[1]/xr:Invoice_issue_date[1] |
| IBAN | /xr:invoice[1]/xr:PAYMENT_INSTRUCTIONS[1]/xr:CREDIT_TRANSFER[1]/xr:Payment_account_identifier[1] |
| CreditorName | /xr:invoice[1]/xr:SELLER[1]/xr:Seller_name[1] |
| CreditorCountry | /xr:invoice[1]/xr:SELLER[1]/xr:SELLER_POSTAL_ADDRESS[1]/xr:Seller_country_code[1] |
| ServiceDate | /xr:invoice[1]/xr:DELIVERY_INFORMATION[1]/xr:Actual_delivery_date[1] |
| TotalAmount | /xr:invoice[1]/xr:DOCUMENT_TOTALS[1]/xr:Invoice_total_amount_with_VAT[1] |
| Currency | /xr:invoice[1]/xr:Invoice_currency_code[1] |
| OrderNumber | /xr:invoice[1]/xr:Purchase_order_reference[1] |
| NetAmount | /xr:invoice[1]/xr:VAT_BREAKDOWN[1]/xr:VAT_category_taxable_amount[1] |
| TaxAmount | /xr:invoice[1]/xr:VAT_BREAKDOWN[1]/xr:VAT_category_tax_amount[1] |
| TaxRate | /xr:invoice[1]/xr:VAT_BREAKDOWN[1]/xr:VAT_category_rate[1] |
| NetAmount2 | /xr:invoice[1]/xr:VAT_BREAKDOWN[2]/xr:VAT_category_taxable_amount[1] |
| TaxAmount2 | /xr:invoice[1]/xr:VAT_BREAKDOWN[2]/xr:VAT_category_tax_amount[1] |
| TaxRate2 | /xr:invoice[1]/xr:VAT_BREAKDOWN[2]/xr:VAT_category_rate[1] |
| NetAmount3 | /xr:invoice[1]/xr:VAT_BREAKDOWN[3]/xr:VAT_category_taxable_amount[1] |
| TaxAmount3 | /xr:invoice[1]/xr:VAT_BREAKDOWN[3]/xr:VAT_category_tax_amount[1] |
| TaxRate3 | /xr:invoice[1]/xr:VAT_BREAKDOWN[3]/xr:VAT_category_rate[1] |
| DueDate | /xr:invoice[1]/xr:Payment_due_date[1] |
| CreditorName | /xr:invoice[1]/xr:SELLER[1]/xr:Seller_trading_name[1] |
| CreditorName | /xr:invoice[1]/xr:SELLER[1]/xr:SELLER_CONTACT[1]/xr:Seller_contact_point[1] |
| TotalAmount | /xr:invoice[1]/xr:DOCUMENT_TOTALS[1]/xr:Amount_due_for_payment[1] |
| IBAN | /xr:invoice[1]/xr:PAYMENT_INSTRUCTIONS[1]/xr:DIRECT_DEBIT[1]/xr:Debited_account_identifier[1] |
| TaxRate3 | /xr:invoice[1]/xr:VAT_BREAKDOWN[3]/xr:VAT_category_tax_rate[1] |
| TaxRate2 | /xr:invoice[1]/xr:VAT_BREAKDOWN[2]/xr:VAT_category_tax_rate[1] |
| TaxRate |
|
Positionen:
| Spalte | Xpath |
|---|---|
| PosQuantity | xr:Invoiced_quantity[1]/text() |
| PosDescription | xr:ITEM_INFORMATION[1]/xr:Item_name[1]/text() |
| PosSinglePrice | xr:PRICE_DETAILS[1]/xr:Item_net_price[1]/text() |
| PosTotalAmount | xr:Invoice_line_net_amount[1]/text() |
| PosTaxRate | xr:LINE_VAT_INFORMATION[1]/xr:Invoiced_item_VAT_rate[1]/text() |
Um ein erfolgreiches Mapping von Spalten zu gewährleisten muss die Tabelle in der die Spalten angelegt werden den technischen Namen "LineItems" besitzen.
Doppelte Felder werden als Alternativen dem Feldwert angehängt
Sollte der Standard nicht ausreichen, so lesen sie hier wie sie die Auswertung erweitern können
Konfiguration XML-Auswertung
Ab Version 2.13 verfügbar und nach Freischaltung durch Partner oder Dexpro !
Standardmäßig liefert Squeeze eine Vielzahl von vordefinierten Mappings zur Extraktion von Kopfdaten aus Rechnungen. Um die bestmögliche Datenerfassung zu gewährleisten, können Sie diese Mappings individuell anpassen und erweitern. Diese Seite bietet eine Anleitung zur Konfiguration von Kopfdaten/Positionsdaten-Mappings im XML-Format.
In der Administration finden Sie einen neuen Unterpunkt (ZUGFeRD und XRechnung):

2. Sobald Sie den Menüpunkt gewählt haben, kommen Sie in eine tabellarische Übersicht. Auf dieser sollten Sie bereits einige Einträge sehen, die sie nicht bearbeiten können, denn dabei handelt es sich um die Standard-Auswertungen; beschrieben in: XRechnung und ZUGFeRD Auswertungstabellen:
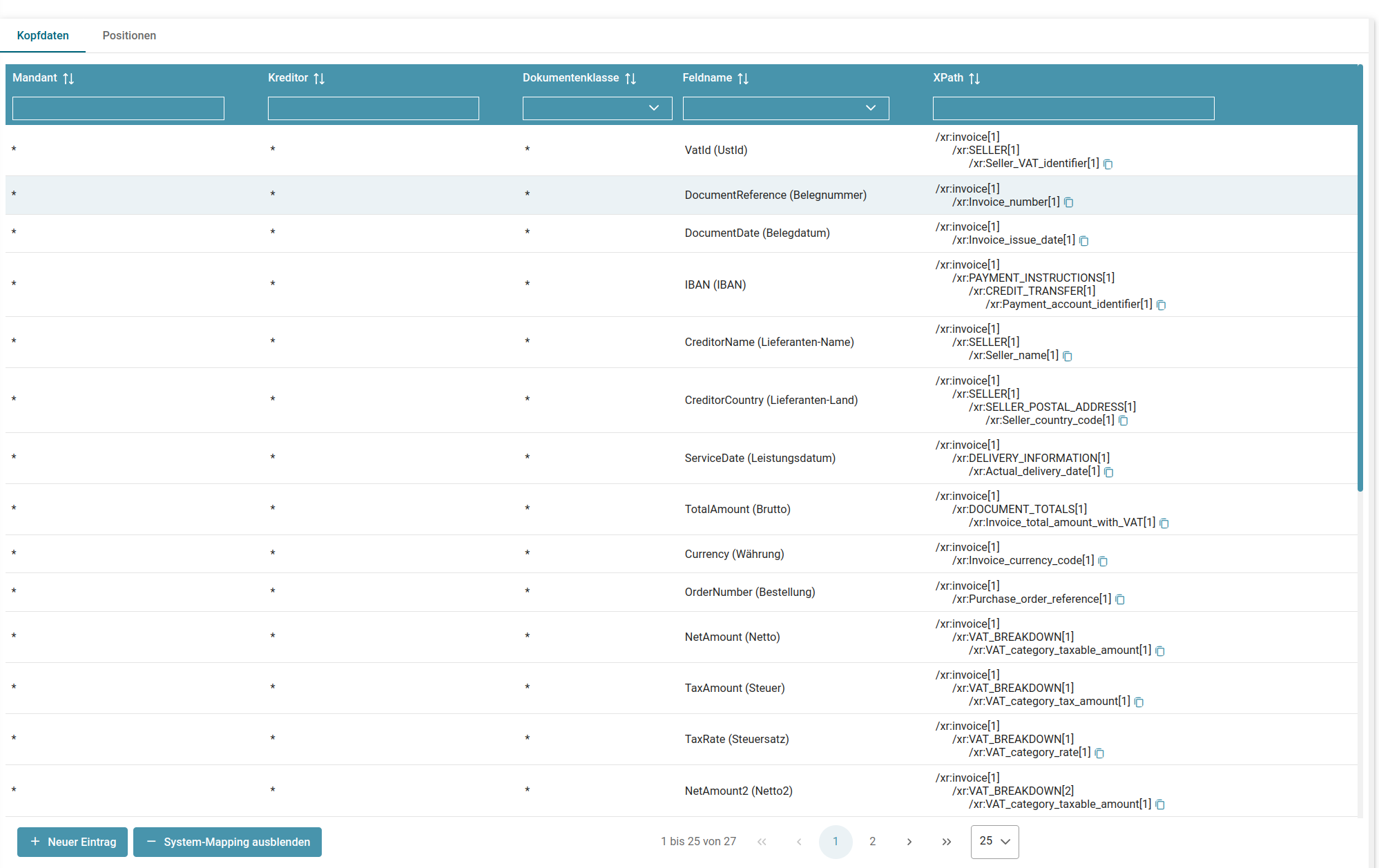
Priorisierung der Mappings
Die Reihenfolge der Mappings spielt eine wichtige Rolle bei der Auswertung der Kopffelder. Squeeze verwendet ein hierarchisches System, um zu bestimmen, welches Mapping für ein bestimmtes Feld verwendet werden soll.
Hierarchie:
- Spezifische Mappings: Mappings, die für einen bestimmten Mandanten, Kreditor und eine Dokumentenklasse definiert sind, haben die höchste Priorität.
- Mandanten- und Kreditor-spezifische Mappings: Sind keine spezifischen Mappings vorhanden, werden Mappings verwendet, die für einen Mandanten und Kreditor definiert sind, unabhängig von der Dokumentenklasse.
- Allgemeine Mappings: Danach folgen Mappings, die nur für die Dokumentenklasse definiert sind, unabhängig von Mandant und Kreditor.
- Standard Mappings: Mappings, die für alle Mandanten, Kreditoren und Dokumentenklassen gelten (Auslieferungszustand), haben die niedrigste Priorität.
Siehe:
|
Prio |
Mandant |
Kreditor |
Dokumentenklasse |
System-Konfiguration |
|
1 |
definiert |
definiert |
definiert |
false vor true |
|
2 |
definiert |
definiert |
* |
false vor true |
|
3 |
* |
definiert |
definiert |
false vor true |
|
4 |
* |
definiert |
* |
false vor true |
|
5 |
definiert |
* |
definiert |
false vor true |
|
6 |
* |
* |
definiert |
false vor true |
|
7 |
definiert |
* |
* |
false vor true |
|
8 |
* |
* |
* |
false vor true |
Anlage neuer Mappings für Kopffelder
Im Tab Kopffelder können Sie neue Mappings anlegen. Dabei wählen Sie die Filterkriterien wie gewünscht.
Beachten Sie dabei, solange keine Dokumentenklasse gewählt wurde, werden ihnen unter Feldname alle Felder aller verfügbaren Dokumentenklassen aufgelistet.

Anlage neuer Mappings für Positionsfelder
Im Tab Positionen können Sie neue Mappings anlegen, dabei wählen Sie die Filterkriterien wie gewünscht.
Beachten Sie dabei, solange keine Dokumentenklasse gewählt wurde werden ihnen unter Spaltenname alle Spalten der verfügbaren ("LineItems-Tabellen") Dokumentenklassen angezeigt.
Wichtig: Es werden nur Spalten aus Dokumentenklassen angezeigt, deren technischer Tabellenname "LineItems" ist.
Bei der der Ermittlung der Spalten werden die konfigurierten Xpath-Ausdrücke mit folgendem Tabellenknotenpunkt ausgewertet: /xr:invoice/xr:INVOICE_LINE.
Das hat zur folge, dass sie nur Kindelemente des Tabellenknotenpunktes /xr:invoice/xr:INVOICE_LINE zur Auswertung der Spalten verwenden dürfen.
Beispiel:
Tabellenknotenpunkt-Xpath: /xr:invoice/xr:INVOICE_LINE
Spalten-Xpath-Ausdruck: xr:PRICE_DETAILS[1]/xr:Item_net_price[1]/text()
Daher achten Sie darauf bei den Spalten-Xpath-Audrücken kein "/" am Anfang zu setzen.
XML-Konformitäts-Prüfung
Seit Version 2.15 bietet die Konfigurationsoberfläche eine integrierte Funktion zur Überprüfung von ZUGFeRD/XRechnung-Dokumenten. Hiermit kann die Konformität des XML-Dokuments mit den spezifischen Anforderungen der gewählten XRechnung-Version bewertet werden.
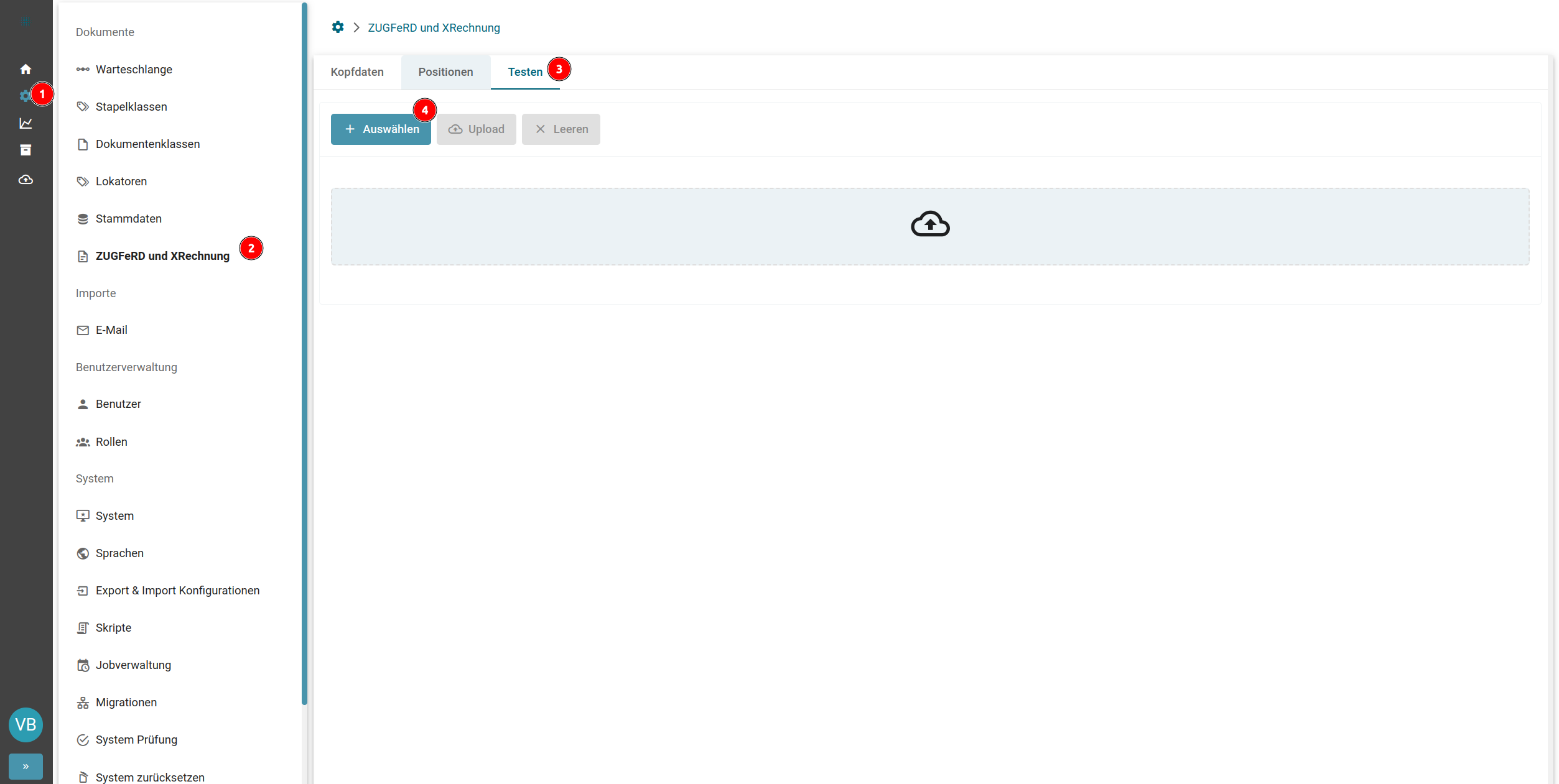
Sobald sie ein Dokument hochgeladen haben, erhalten Sie in einem das Ergebnis der Prüfung.

Sollte das Ergebnis, negativ ausfallen, wird das Dokument dennoch von Squeeze verarbeitet.
Eine PDF-Prüfbericht steht Ihnen ab Version 2.15 und nach Freischaltung unserer Berater oder Partner in der Validierung zur Verfügung, siehe hier.
Allgemeine Infos
Kontrollieren Sie ihren eingegeben XPath auf einer geeigneten Seite wie zum Beispiel:
http://xpather.com/
Die Auswertung der Xpaths erfolgt auf dem intermediate.xml . Die XML-Datei kann durch ein Download der Anhänge aus der technischen Warteschlange gewonnen werden.
XML Formate in Squeeze
Dieser Artikel beschreibt die allgemeine Verarbeitung von E-Rechnungen im XML-Format und welche EN16931-konformen XML-Dokumente Squeeze verarbeiten kann.
Die folgende Tabelle listet die aktuellsten Versionen der Formate auf, die Squeeze prüft, wenn ein XML-Dokument als eingebettete XML in einem PDF (z. B. ZUGFeRD) oder als einzelnes Dokument (z. B. XRechnung) vorliegt.
| Standard | Version |
| Factur-X | 1.0 bis 1.0.07 |
| ZUGFeRD | 1.0 bis 2.3 |
| XRechnung | 1.0 bis 3.0.2 |
In Zukunft wird Squeeze unabhängig von Formaten, XML-Dokumente verarbeiten können
XML-Prüfbericht KoSIT
Diese Seite bietet eine umfassende Anleitung zur Konfiguration und Durchführung von KoSIT-Prüfberichten für XML-Daten.
Die Erstellung des XML-Prüfberichtes erfordert Internetzugriff und ist in abgekapselten Intranet-Strukturen vorerst nicht einsetzbar.
Konfiguration des externen Dienstes
Vor SQUEEZE 2.21
Damit die Erzeugung des Prüfberichtes erfolgen kann muss ein neuer Dienst in der Server-/ Mandanten-Konfiguration konfiguriert werden. Der Dienst ist aktuellen Zeitpunkt(23.11.24) noch auf keinen festen Host bestimmt, daher erfragen Sie den aktuellen Host bei unseren Beratern
{
...,
"digivoice": {
"baseUrl": "https://{digivoice.example.host}/apis/digivoice/v1"
},
...,
}Nachdem der Dienst in einer der Konfigurationsdateien konfiguriert ist, können Sie in Squeeze die Stapelklasseneigenschaft XmlValidationReport (ab Squeeze v2.15.0) aktivieren.
Ab SQUEEZE 2.21
Ab Squeeze 2.21 wird ein anderes, dediziertes Backend für die KoSIT Prüfung genutzt. Mit Diesem werden zwei Optionen angeboten: Lokal und Remote.
Bei der lokalen Prüfung wird ein lokales Java-Tool genutzt, um den Prüfbericht zu erzeugen. Da dieses Tool für jeden Aufruf gestartet werden muss, ist diese Variante langsam und benötigt pro Ausführung ca. 2 GB RAM auf dem Server.
Die remote Prüfung nutzt die von uns betriebene Online-Variante des Tools und ermöglicht eine wesentlich schnellere Prüfung ohne zusätzliche Ressourcen-Belastung des Squeeze-Servers.
Welche Variante genutzt wird, kann in der Mandantenkonfiguration hinterlegt werden:
{
...,
"kosit": {
"validationType": "remote", // Oder "local" für die lokale Prüfung
"remoteServiceUrl": "https://kosit-validator.squeeze.one"
},
...,
}Es müssen ebenfalls Projekt-Zugangsdaten (OAuth Client Credentials) für das DEXPRO Portal hinterlegt und aktiviert sein (diese erfragen Sie ggf. bei ihrem zuständigen Berater), damit SQUEEZE sich bei dem Online-Service authentifizieren kann:
{
...,
"portal": {
"enabled": "True",
"host": "https://portal.dexpro.de"
"auth": {
"clientId": "<Ihre Tenant-ID>",
"secret": "<Ihr Client Secret>"
}
},
...,
}Nachdem der Dienst in einer der Konfigurationsdateien konfiguriert ist, können Sie in Squeeze die Stapelklasseneigenschaft XmlValidationReport aktivieren.
KoSIT-Prüfbericht
Wird die Stapelklasseneigenschaft genutzt, so erstellt Squeeze den KoSIT-Prüfbericht zu Beginn des Verarbeitungsprozesses. Sollte es während der Belegerstellung zu Fehlern kommen, beeinflusst dies die restliche Verarbeitung des Beleges in der Regel nicht. Dadurch wird sichergestellt, dass auch bei Problemen eine umfassende Verarbeitung des Dokumentes zur Verfügung steht.
Den KoSIT Prüfbericht, können Sie sich in der Validierung des Dokumentes anzeigen lassen.
Validierungsoberfläche
Mandanten- und Lieferanten- Erkennung
Einleitung
Sowohl bei elektronischen Rechnungen im XRechnung- oder ZUGFeRD-Format als auch bei der Verarbeitung beliebiger XML-Dokumente (generische XML-Verarbeitung) wird die Extraktion von Lieferanten- (Kreditoren) und Mandanten-Schlüsseln nach demselben grundlegenden Prinzip durchgeführt. Ziel ist es, die in den elektronischen Rechnungen enthaltenen Informationen zu Geschäftspartnern effizient und zuverlässig in unser internes System zu überführen, um eine weitere Verarbeitung zu ermöglichen.
Prozessbeschreibung
- Identifikation relevanter Daten: In den eingehenden XML-Dokumenten werden die für Geschäftspartner relevanten Daten (z.B. Name, Adresse, Steuernummer) identifiziert.
- Zuordnung zu einem Feldkatalog: Die identifizierten Daten werden anhand eines vordefinierten Feldkatalogs den entsprechenden Feldern in unserem internen System zugeordnet.
- Mapping auf interne Schlüssel: Die zugeordneten Daten werden anschließend unseren internen Schlüsseln für Geschäftspartner zugewiesen.
Detaillierte Betrachtung der Zuordnung für Mandanten und Kreditoren
Mandanten
- Suche in der companysearch: Zunächst wird der in der XML angegebene Mandantenname in unserer internen Firmensuche (companysearch) abgeglichen. Falls ein Treffer gefunden wird, wird der zugehörige interne Schlüssel verwendet.
- Suche nach der VAT-ID: Wenn keine Übereinstimmung in der Firmensuche gefunden wird, wird die in der XML angegebene Umsatzsteuer-Identifikationsnummer (VAT-ID) in unserer Tabelle "Companies" gesucht. Falls hier ein Eintrag existiert, wird der entsprechende interne Schlüssel verwendet.
- Kein Treffer: Wenn keine der beiden Bedingungen erfüllt ist, bleibt der Eintrag für den Mandanten leer.
Kreditoren
- Suche in der creditorsearch: Analog zur Mandantenidentifikation wird zunächst der in der XML angegebene Kreditorenname in unserer internen Kreditoren-Suche (creditorsearch) abgeglichen. Falls ein Treffer gefunden wird, wird der zugehörige interne Schlüssel verwendet.
- Suche nach der VAT-ID des Kreditors: Wenn keine Übereinstimmung in der Kreditoren-Suche gefunden wird, wird die in der XML angegebene Umsatzsteuer-Identifikationsnummer (VAT-ID) des Kreditors in unserer Tabelle "Creditors" gesucht. Falls hier ein Eintrag existiert, wird der entsprechende interne Schlüssel verwendet.
- Kein Treffer: Wenn keine der beiden Bedingungen erfüllt ist, bleibt der Eintrag für den Kreditoren leer.
Zusammenfassung der Mechanismen
| Geschäftspartner | Bedingung | Aktion |
|---|---|---|
| Mandant/Kreditor | Name gefunden in entsprechender Suche | Interner Schlüssel aus der Suche verwenden |
| Mandant/Kreditor | Name nicht gefunden, VAT-ID gefunden | Interner Schlüssel aus der entsprechenden Tabelle verwenden |
| Mandant/Kreditor | Keine Übereinstimmung | Eintrag bleibt leer |
Umschlüsselung von Codes eines elektronischen Beleges
Diese Seite erklärt das Verfahren, wie Codes eine elektronischen Beleges in andere Werte umgeschlüsselt werden können.
Das Beispiel orientiert sich auf den Vorgang des Beleges z. B. Rechnung oder Gutschrift. Es kann aber auf jeden anderen Wert angewendet werden.
Voraussetzung
Diese Umschlüsselung bezieht sich auf die elektronischen Formate ZUGFeRD und XRechung.
Damit ein Code aus der XML-Datei in einen neuen Wert umgeschlüsselt werden kann, muss zunächst sichergestellt werden, dass der Code aus der XML-Datei stammt. In diesem Beispiel wohlen wir die Standard Vorgänge
- Code 380 = Rechung
- Code 381 = Gutschrift
um weitere Vorgangsarten ergänzen.
Im Standard wird die Zuordnung der Codes 380 und 381 bereits durch die Invoice-Solution von Squeeze durchgeführt.
Um dieses Verhalten anzupassen muss zunächst eine neues Feld-Mapping hinzugefügt werden:
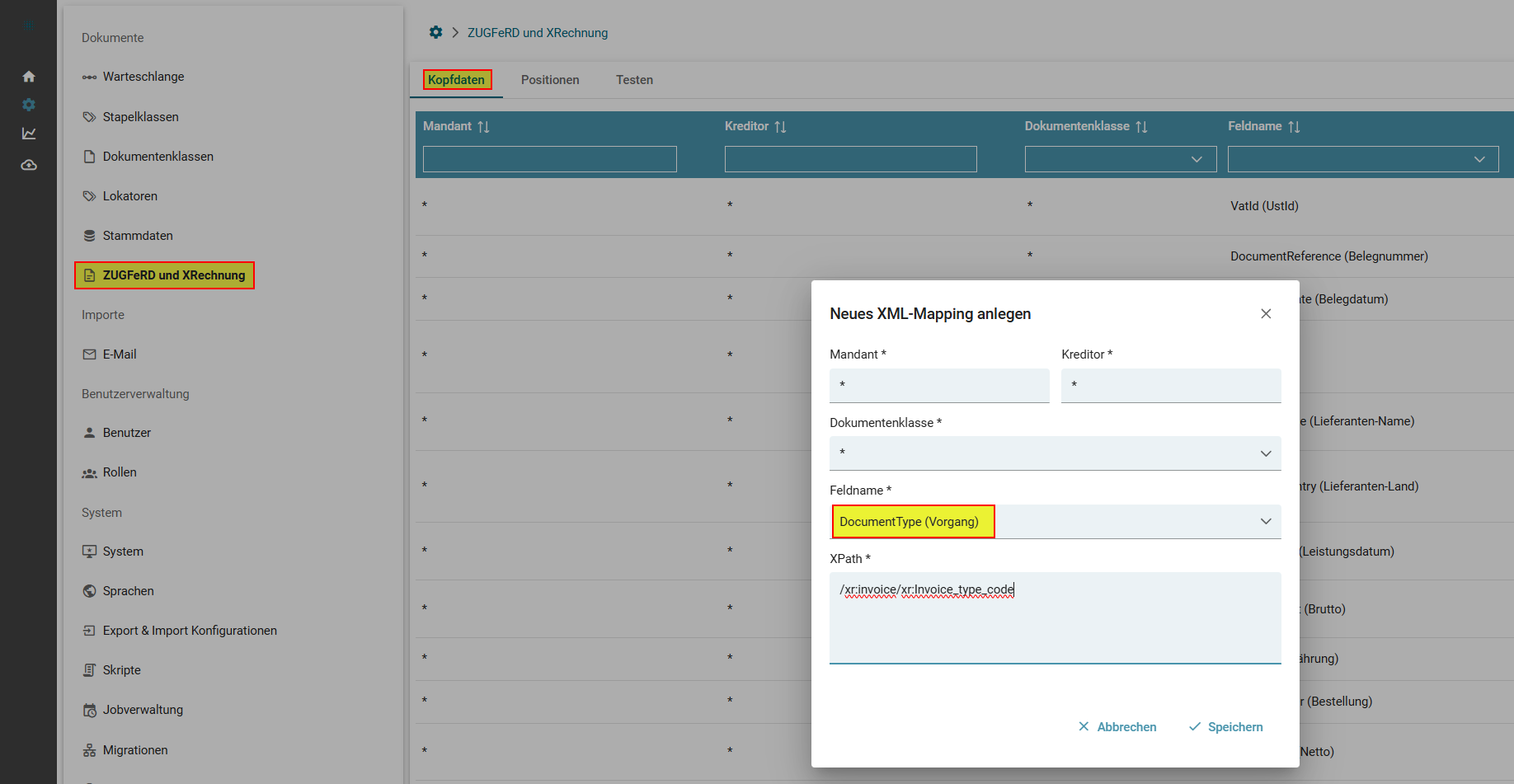
Dieses Mapping ermöglicht, dass beim Auslesen des Codes der XML Datei, eine Umschlüsselung durchgeführt werden kann, da sonst der Standard der Invoice Solution genutzt wird.
Bitte Groß-/ Kleinschreibung beachten:
Der XPath ist case-sensitiv. Das bedeutet das der XPath so geschrieben sein muss, wie er in der XML-Datei angegeben ist.
/xr:invoice/xr:Invoice_type_code
Umschlüsselung anderer Codes
Ab der Version 2.16 wurde eine neue Tabelle (einvoice_value_mapping) eingeführt, die genutzt werden kann, um individuell andere Werte statt der Codes zu nutzen und selbst festlegen zu können. Die Tabelle befindet sich unter dem Menüpunkt Stammdaten:
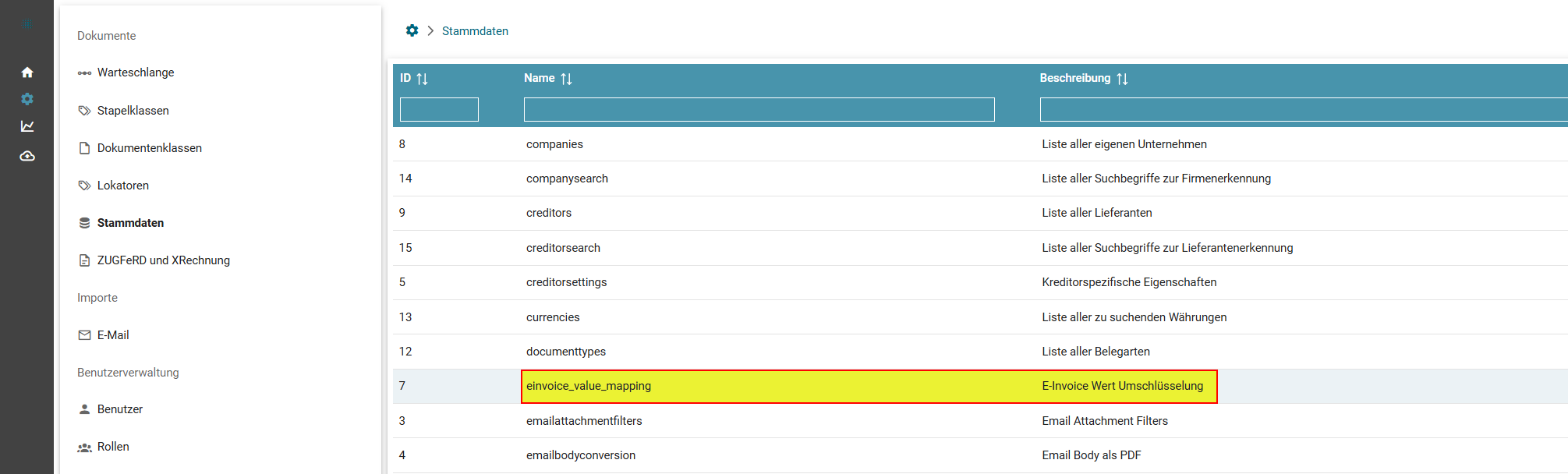
In dieser Tabelle lassen sich die Umschlüsselungen sehr genau konfigurieren. Ähnlich wie bei den Mappings lassen sie die Umschlüsselungen je Unternehmen, Lieferant, Dokumentenklasse und Feld konfigurieren. Hier ein Beispiel, wie die Standard-Codes 380 (Rechnung) und 381 (Gutschrift) um einen weiteren Eintrag 384 (Rechnungskorrektur) erweitern lassen:
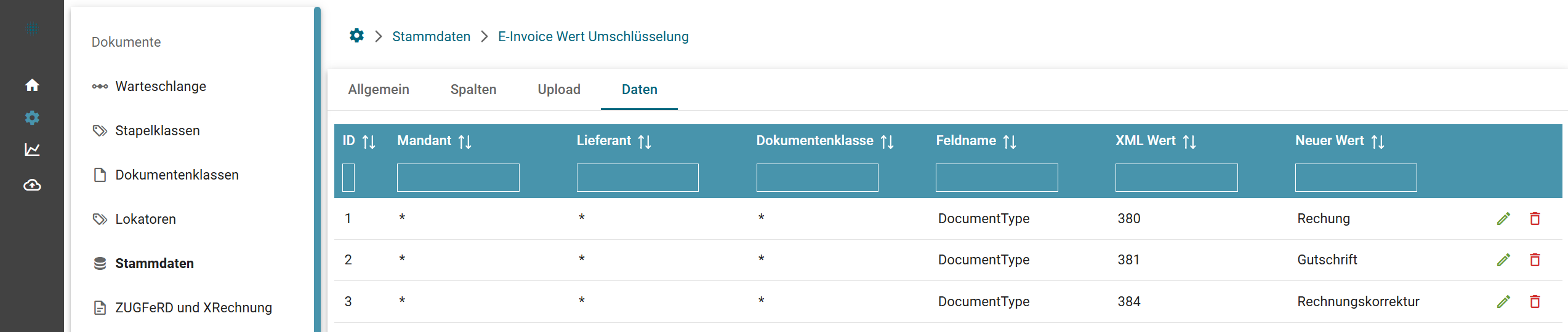
Dieses Vorgehen lässt sich nicht nur auf Kopffelder anwenden, sondern auch auf Positionsangaben. So lässt sich mit dieser Möglichkeit auch gut die Umschlüsselung von Mengeneinheiten realisieren.
Hier ein weiteres Beispiel für Mengeneinheiten:
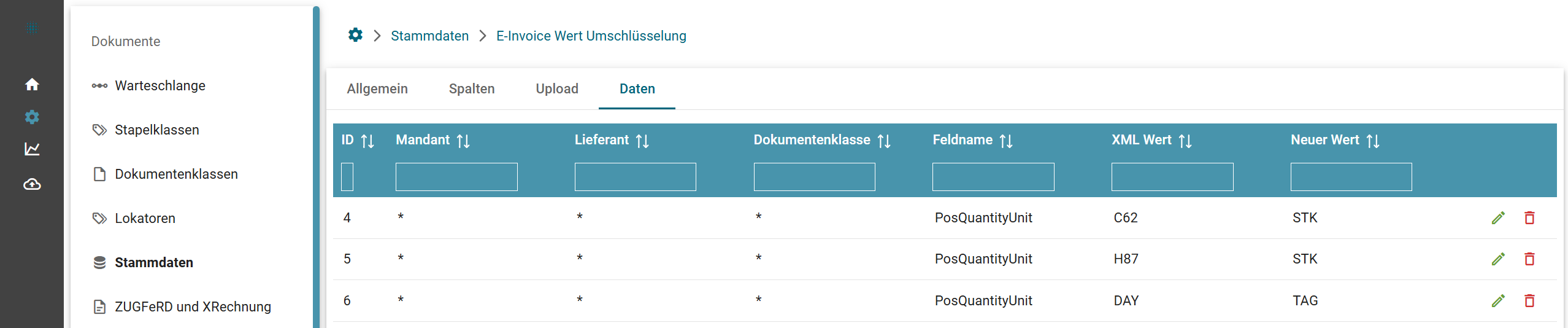
Die Listen lassen sich exportieren und auch wieder importieren, was die Übertragung von Test in Produktivsysteme oder andersherum sehr vereinfacht.
Mehrsprachigkeit
Dieses Kapitel behandelt Mehrsprachigkeit und die Möglichkeiten zur Übersetzung der Anwendung.
Übersicht aller sprachbezogenen Systeme
In Squeeze gibt es unterschiedliche Anwendungsbereiche, die unterschiedlich übersetzt werden (können). Diese Seite bietet eine Übersicht über diese Bereiche.
Ganz unten finden Sie ein Beispiel, dass alle Systeme in einem Bild zusammenfasst.
Der Support für Mehrsprachigkeit wird ab Squeeze 2.3 phasenweise umgesetzt. Wir bitten zu berücksichtigen, dass Mehrsprachigkeit (besonders im Kontext von Extraktionssoftware) ein vielschichtiges Thema ist.
Unterschiedliche Systeme
Übersetzung der Benutzeroberfläche
Die Benutzeroberfläche kann nicht durch Administratoren übersetzt werden. Die Übersetzung der Benutzeroberfläche ist Teil des Standard-Produktes und wird somit durch Produktupdates ausgeliefert.
Falls Sie die Benutzeroberfläche in einer bisher nicht vorhandenen oder übersetzen Sprache nutzen möchten, kontaktieren Sie bitte den Support.
Übersetzung von Inhalten
Die Übersetzung von Inhalten ist frühestens ab Squeeze 2.3 möglich.
Neben der einfachen Übersetzung der Benutzeroberfläche ist es auch möglich Inhalte wie Dokumentenklassen, Felder usw. zu übersetzen. Damit soll die Anwendung für Validierer und Endanwender in diversen Sprachen einsetzbar sein.
Übersetzung von Feldwerten
Aktuell gibt es noch kein System zur Übersetzung von Feldinhalten. Die Anforderung ist bekannt und wird vorerst (seitens DEXPRO) nur in kostenpflichtigen Projektlösungen umgesetzt.
Bei der Übersetzung von Feldwerten geht es bspw. darum, dass Validierern im Invoice-Feld "Vorgang" der enthaltene Wert in die Sprache des Validierers übersetzt angezeigt wird, im Hintergrund allerdings der gleiche technische Wert genutzt wird.
Übersetzte Bereiche
Im Folgenden werden alle Bereiche aufgezeigt, die aktuell übersetzt dargestellt werden können.
Validierung
Im folgenden Bild sehen Sie alle unterschiedlichen Übersetzungsmechanismen:
- (1) und (2) sind Standardelemente der Benutzeroberfläche
- (3) Feldnamen (Beispiel "Mandant") und Feldgruppen ("Kopfdaten") sind inhaltsbezogene Übersetzungen. Auch die Überschriften der Tabellenspalten unten im Bild gehören dazu.
- (4) Feldwerte (Beispiel "Rechnung" im Feld "Vorgang") gehören zur jeweiligen Lösung.
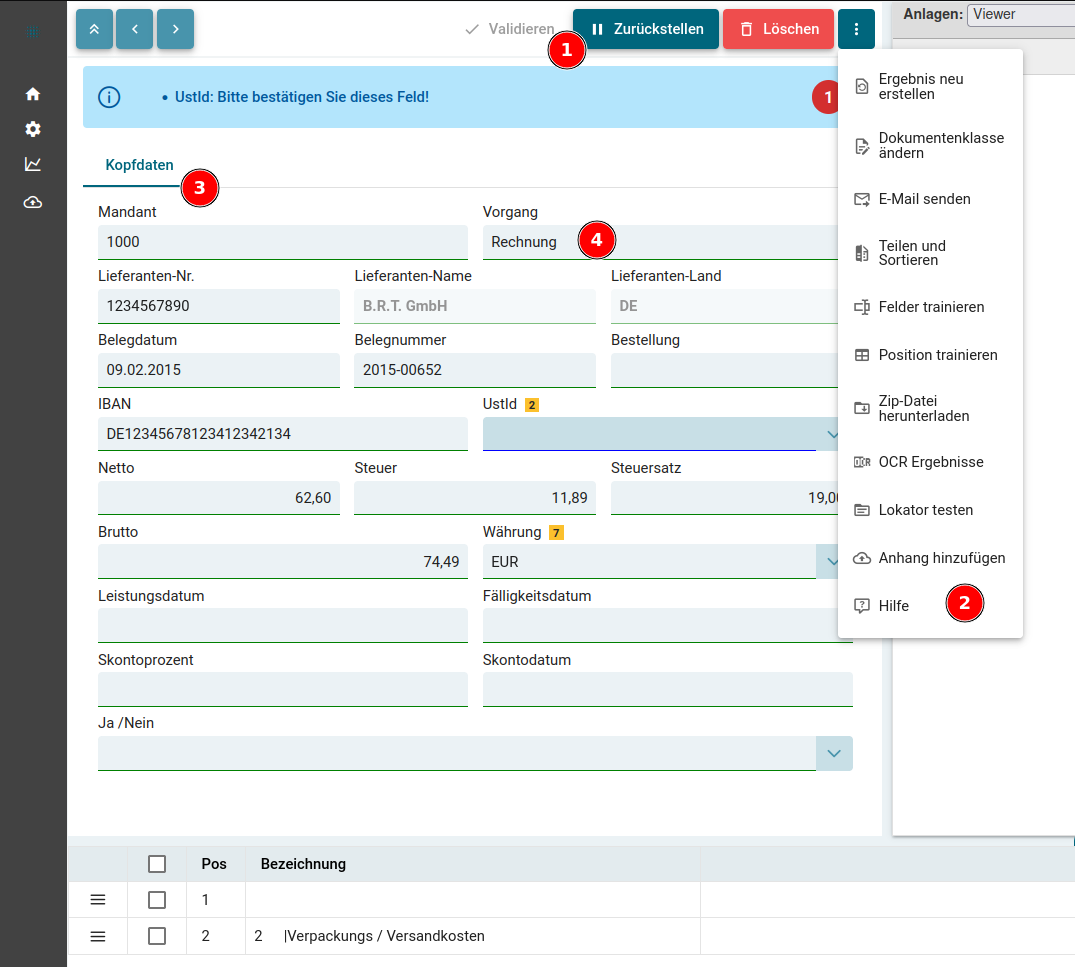
Trefferliste der Dokumentensuche
Dashboard
Sprachen
In der Administration unter dem Menüpunkt "Sprachen" können Sie die Sprachen eines Mandanten verwalten.
Aktuell ist es nur möglich vordefinierte Sprachen zu aktivieren oder deaktivieren.
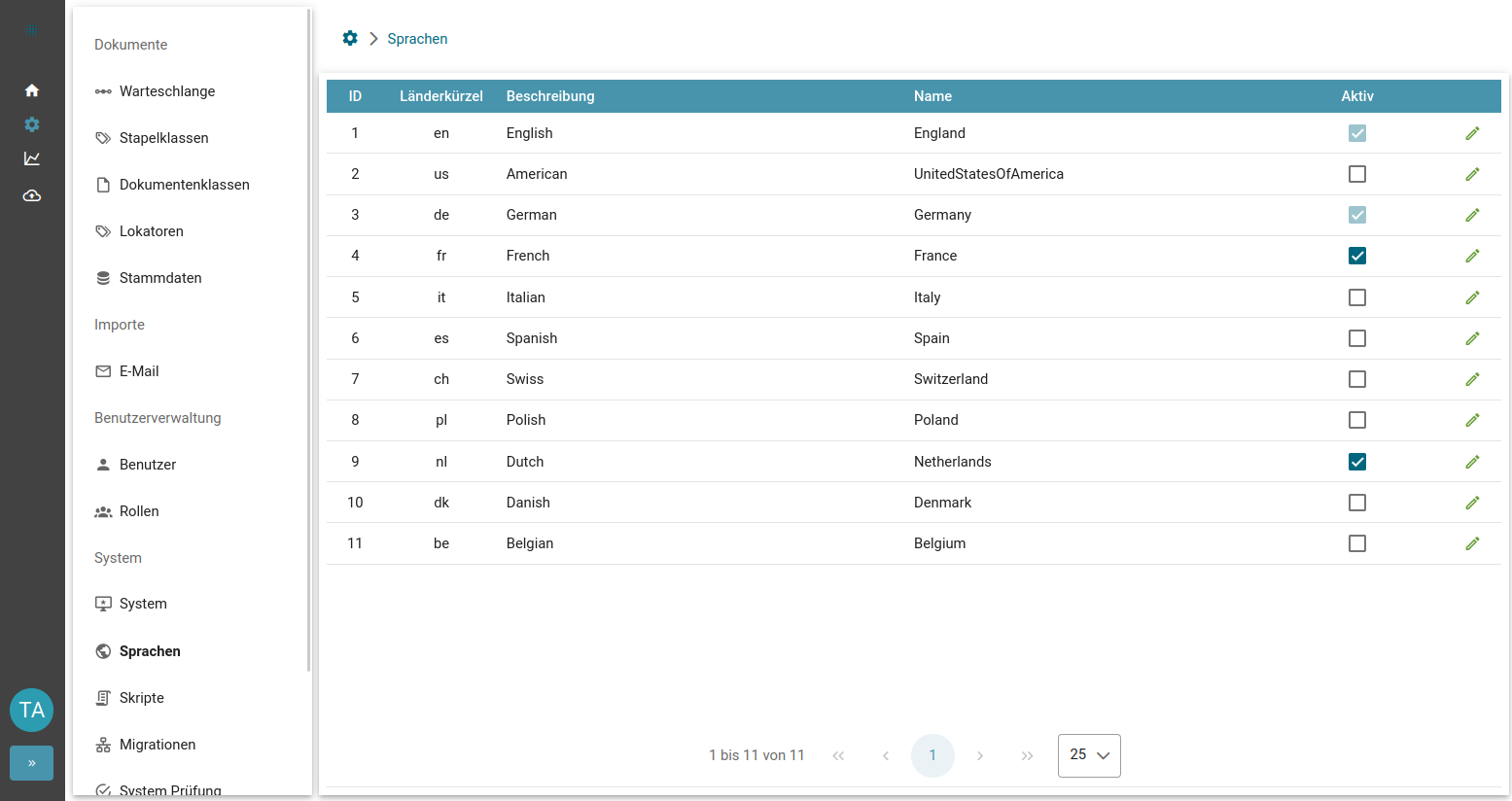
Sprachen, die Sie in der Administration aktivieren, sind für alle User auswählbar.
Pflege von Übersetzungen
Diese Seite dokumentiert wie Sie Übersetzungen pflegen können.
Massen-Übersetzung mittels CSV-Export & -Import
Einleitung
In der Benutzeroberfläche haben Sie die Möglichkeit alle vorhandenen und fehlenden Übersetzungen als CSV-Datei zu exportieren. Diese Datei können Sie für eine komfortablere Übersetzung nutzen und später wieder importieren.
Der CSV-Upload ersetzt alle vorhandenen Übersetzungen im System.
Daher empfehlen wir Ihnen beim Bearbeiten der Übersetzungen immer ein Backup der originalen Übersetzungen als Kopie zu behalten.
Für den Import von Übersetzungen werden CSV-Dateien nur in dem Format unterstützt, wie sie durch die Export-Funktion exportiert werden. Ein Beispiel finden Sie weiter unten.
Im Menü "System" der Administration finden sie im Register "Übersetzungen via CSV Export & Import" die Möglichkeiten zum Herunterladen und Hochladen der Übersetzungsdateien.
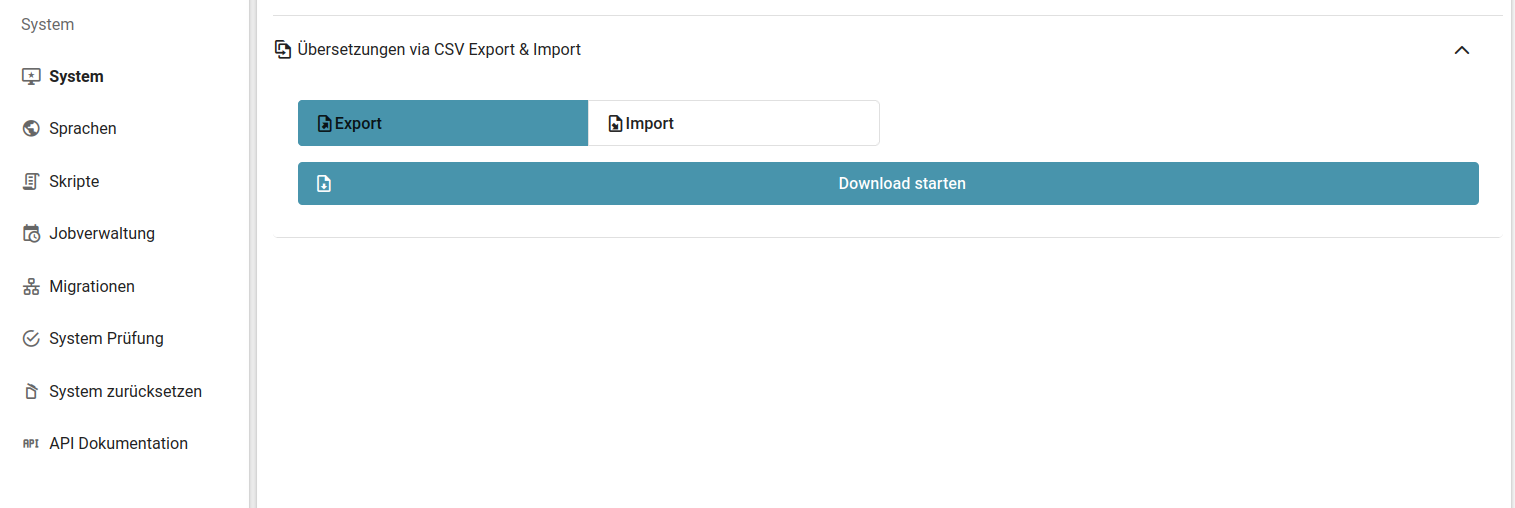
CSV-Beispiel
Die exportierte CSV beinhaltet eine Zeile pro Übersetzung. Jede Zeile hat mindestens eine Spalte für den Übersetzungsschlüssel (translationkey) und eine Spalte pro Sprache.
Zum Übersetzen füllen Sie die leeren Zellen mit den Übersetzungen der jeweiligen Sprache. Dabei sind die Übersetzungsschlüssel so zu lesen:
documentclasses.Invoices.fields.Creditor.description übersetzt aus der Dokumentenklasse Invoices für das Feld Creditor die Eigenschaft description (das ist die Beschreibung des Feldes)
CSV Dateien können nur importiert werden, wenn sie das selbe Format haben wie die exportierte CSV-Datei. Aktuell ist das:
- Semikolon als Trennzeichen
- Werte werden mittels Anführungszeichen escaped
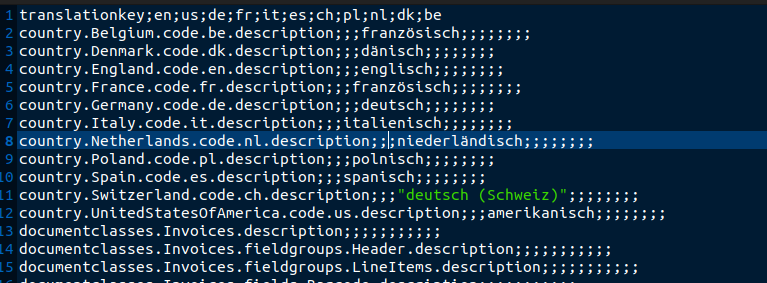
Leitfaden: CSV mit Excel übersetzen
Der folgende Leitfaden dokumentiert, wie Sie mittels Excel die Übersetzungsdatei (CSV) bearbeiten können.
Erfahrungsgemäß ist der Umgang von Excel mit CSV-Dateien häufig fehlerhaft. Üblich ist bspw. dass eine CSV-Datei im Dateiexplorer mit einem Linksklick direkt in Excel geöffnet wird und dann die Spalten nicht korrekt aufgeteilt werden oder Umlaute und Sonderzeichen falsch dargestellt werden. In diesen Fällen öffnet Excel die CSV-Datei mit falschen Parametern.
Der folgende Leitfaden ist unser empfohlener Weg Übersetzungen mit Excel zu bearbeiten und wir bitten darum diesen zu wählen.
- Übersetzungen über die Web UI als CSV-Datei exportieren
- Excel öffnen
- Im Register "Daten" die Option "Aus Text/CSV" wählen.
- Die heruntergeladene Datei auswählen
- In dem aufkommenden Dialog die dargestellten Einstellungen wählen
- Das Encoding ist UTF-8
- Trennzeichen Semikolon
- Dann die Datei nicht laden, sondern auf "Daten transformieren" klicken.
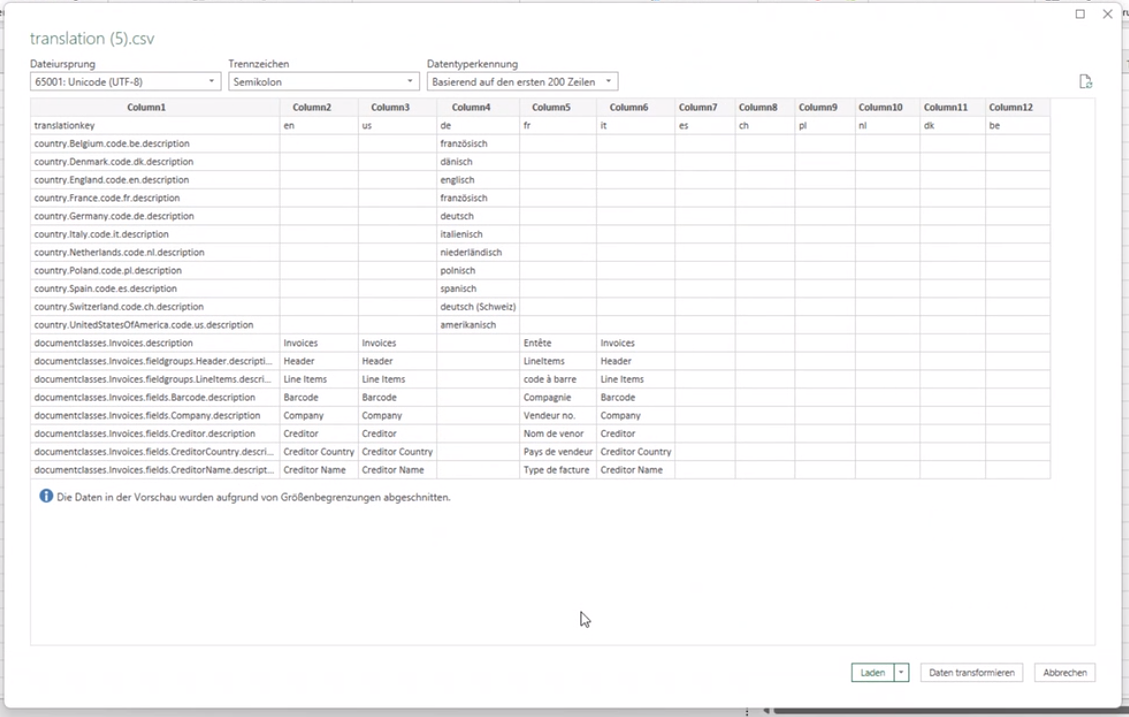
- In diesem Fenster die Aktion "Erste Zeile als Überschrift verwenden" auswählen
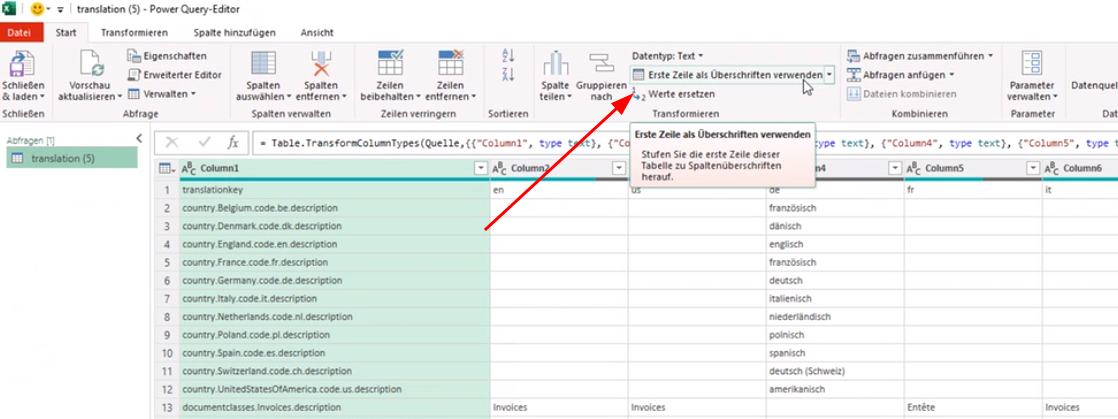
- (1) Nun sollten die Überschriften wie im Screenshot gezeigt werden
- (2) "Schließen und laden" ausführen
- So sieht nun die geöffnete Datei in Excel aus
- Jetzt können Sie Übersetzungen in der Datei verändern bzw. ergänzen
- Wenn Sie fertig sind, dann Speichern sie die Datei mittels "Speichern unter" als neue Datei ab
- Wichtig ist hier die Auswahl des Dateityps "CSV (Trennzeichen-getrennt)"
- Zuletzt laden Sie die Übersetzungen in der UI wieder hoch.
Übersetzung von Inhalten
Aktuell gibt es noch keine Möglichkeit für die direkte Übersetzung von Inhalten (also Feldern, Tabellen, Dokumentenklassen usw.) in der jeweiligen Konfigurationsoberfläche.
Mandanten-Verwaltung
Administrative Tätigkeiten bezogen auf die Verwaltung eines oder mehrerer Mandanten.
Features verwalten
Die Feature-Verwaltung ermöglicht es experimentelle bzw. neue Features je Mandant (und wahlweise für alle Mandanten einer Umgebung) zu aktivieren / deaktivieren. Somit ist es möglich Endkunden phasenweise an neue Funktionen zu gewöhnen oder optionale Features grundsätzlich zu deaktivieren.
Die Feature-Verwaltung wird sich langfristig zwischen On-Premis und SaaS-Angeboten unterscheiden.
Die Features eines Mandanten werden aktuell (Stand Q3 2022) als Teil der Server- und Mandantenkonfiguration gespeichert.
Feature-Übersicht
| Flag | Funktion | Im Standard aktiviert? |
Verfügbar ab Version |
| v2Viewer | Ist der v2 Viewer in der v2 UI nutzbar? | X | < 2.3.0 |
| v1Viewer | Ist der v1 Viewer in der v2 UI nutzbar? | X | < 2.3.0 |
| v2Ui | Ist die v2 UI nutzbar? | X | < 2.3.0 |
| v1Ui | Ist die v1 UI nutzbar? | X | < 2.3.0 |
| masterDataTablePermissions | Soll ein komplexeres Berechtigungssytsem in der Stammdatenverwaltung genutzt werden? | < 2.3.0 | |
| jobManagement | Soll das v2 Jobsystem in der Benutzeroberfläche sichtbar sein? | < 2.3.0 | |
| documentLog | Darf in der UI auf Dokumenten-Logs zugegriffen werden können? (Aktuell nur in Ergänzung mit Logging in Elasticsearch nutzbar) | < 2.3.0 | |
| newsSidebar | Noch nicht veröffentlicht, wird nicht aktiv gepflegt: Falls aktiv, zeigt in der UI ein vereinfachtes Changelog an. | < 2.3.0 | |
| validationFieldLayout | Experimentell: Soll ein komplexeres Feldlayouting (inkl. Layout-Editor) in der v2 UI für die Validierung genutzt werden? | < 2.3.0 | |
| savedDocumentSearches | Können User Dokumenten-Suchen abspeichern und sehen diese als gespeicherte Suchen im Dashboard uws.? | >= 2.3.0 | |
| translationAdministration | Können User in der Administration Sprachen und Übersetungen administrieren? | >= 2.3.0 | |
| uiConfigExport | Können User in der Administration Dokumentenklassen exportieren? | >= 2.5.0 | |
| uiConfigImport | Können User in der Administration Dokumentenklassen importieren? | >= 2.5.0 | |
| uiAllowDocumentUpload | Können User Dokumente hochladen? | X | >= 2.5.0 |
| uiAllowDocumentSplit | Können User Dokumente aufteilen? | X | >= 2.5.0 |
| pipelineAllowMultipleStepExecutions | Können Verarbeitungsschritte mehrfach mit dem selben Dokument ausgeführt werden? | >= 2.6.0 | |
| configurableFieldAmountFormatting | Darf die Formatierung der Betragsfelder konfigurierbar sein? | >= 2.7.0 | |
| Werden Report-Daten für die Auswertung der Extraktionsqualität erhoben und angezeigt? Warnung Stand April 2024: Dieses Feature ist noch nicht vollständig umgesetzt und könnte zur Ansammlung großer Datenmengen führen. |
>= 2.7.0 | ||
|
workerManager
|
Sollen Jobs über den Worker Manager verteilt & verwaltet werden?
Serverseitig überschreibar über die Umgebungsvariable SQZ_WORKER_MANAGER_FORCE |
>= 2.10 | |
|
asyncExportAfterValidation
|
Ist es möglich, dass Dokumente nach einer manuellen Validierung im Hintergrund exportiert werden? Bei sehr langsamen Export-Schnittstellen nützlich.
Bei Aktivierung ist die entsprechende Stapelklassen-Eigenschaft nutzbar. |
X |
>= 2.12 |
|
formTraining
|
Ist Formularbasiertes Training möglich? |
>= 2.12 |
|
| xmlEditor |
Ist der administrative Editor zum Pflegen der XML Verarbeitung aktiv? |
>= 2.13 |
|
| xmlTraining |
Ist das XML-Training für Kopfdaten und Positionen aktiv? |
>= 2.13 |
Konfiguration via Mandanten-Konfig.
Folgendes Beispiel aktiviert zwei und deaktivieren ein Feature für den betroffenen Mandanten.
{
"...": {
"...": "..."
},
"features": {
"v2Ui": true,
"v2Viewer": true,
"oldFeature": false
}
}System API
Beschreibung
Diese Seite dokumentiert die System API von Squeeze. Mit dieser können Mandanten und das System verwaltet werden.
URL
Die URL unter welcher Squeeze erreichbar ist, in Kombination mit dem folgenden Path: /api/system/v1/dist/,
Beispielsweise https://test.staging.squeeze.one/api/system/v1/dist/.
So erreichen Sie die im Swagger UI, welche die Verwendung unserer System API vereinfacht.
Absicherung
Die System API ist mit einer einfachen Basis-Authentifizierung abgesichert. Die Zugangsdaten, ein Benutzername und ein Passwort, befinden sich in der docker-compose.yml ihrer Squeeze Installation oder sollten Ihnen mitgeteilt worden sein.
Ist dies nicht der Fall kontaktieren Sie uns bitte, damit wir Ihnen diese zukommen lassen können.
System API Anfrage authentifizieren
Swagger UI
In der Swagger UI finden Sie einen Button mit dem Namen "Authorize". Durch die Verwendung von diesem Element öffnet sich ein Modaler Dialog, in dem Sie Ihre Nutzerdaten (Benutzername und Passwort) hinterlegen können.
Suchen Sie hierfür nach der "HTTP Basic Authentication"-Methode, welche, im Regelfall, als oberste Methode aufgeführt wird.
Selbst erstellte Anfrage
Sie müssen Ihre Zugangsdaten mit der Base64-Methode enkodieren, wobei das Format der zu enkodierenden Zeichenkette Username:Passwort lautet.
So ergibt beispielsweise der Username system und das Passwort system die nach Base64-Methode enkodierte Zeichenkette c3lzdGVtOnN5c3RlbQ==.
Der Präfix "Basic" wird der enkodierten Zeichenkette beigefügt und als eine Zeichenkette dem Header, mit dem Key "Authorization", beigefügt; Beispiel: Authorization: Basic c3lzdGVtOnN5c3RlbQ==.
Wenn Sie beispielsweise alle Tenants aufgeführt haben möchten, als Teil Ihrer selbst erstellten Anfrage, sähe Ihre Anfrage wie folgt aus (den Beispielen dieser Seite folgend, unter Verwendung von cURL):
curl --location 'http://test.staging.squeeze.one/api/system/v1/tenants' --header 'Authorization: Basic c3lzdGVtOnN5c3RlbQ=='Squeezer CLI
Das Kommandozeilen-Tool zur Verwaltung von Squeeze.
Einführung
Das CLI steht erst ab Squeeze 2.5 zur Verfügung.
Im Projektverzeichnis von Squeeze (htdocs unter Windows, /var/www/html/squeeze unter Linux) liegt das CLI (Kommandozeilen-Tool) für Squeeze namens squeezer.
Mit diesem Tool sind administrative Tätigkeiten möglich, die ggf. nicht über die HTTP Schnittstelle oder Benutzeroberfläche möglich sind. Zusätzlich lässt sich die Verwendung des CLIs mittels Skripten automatisieren, falls gewünscht.
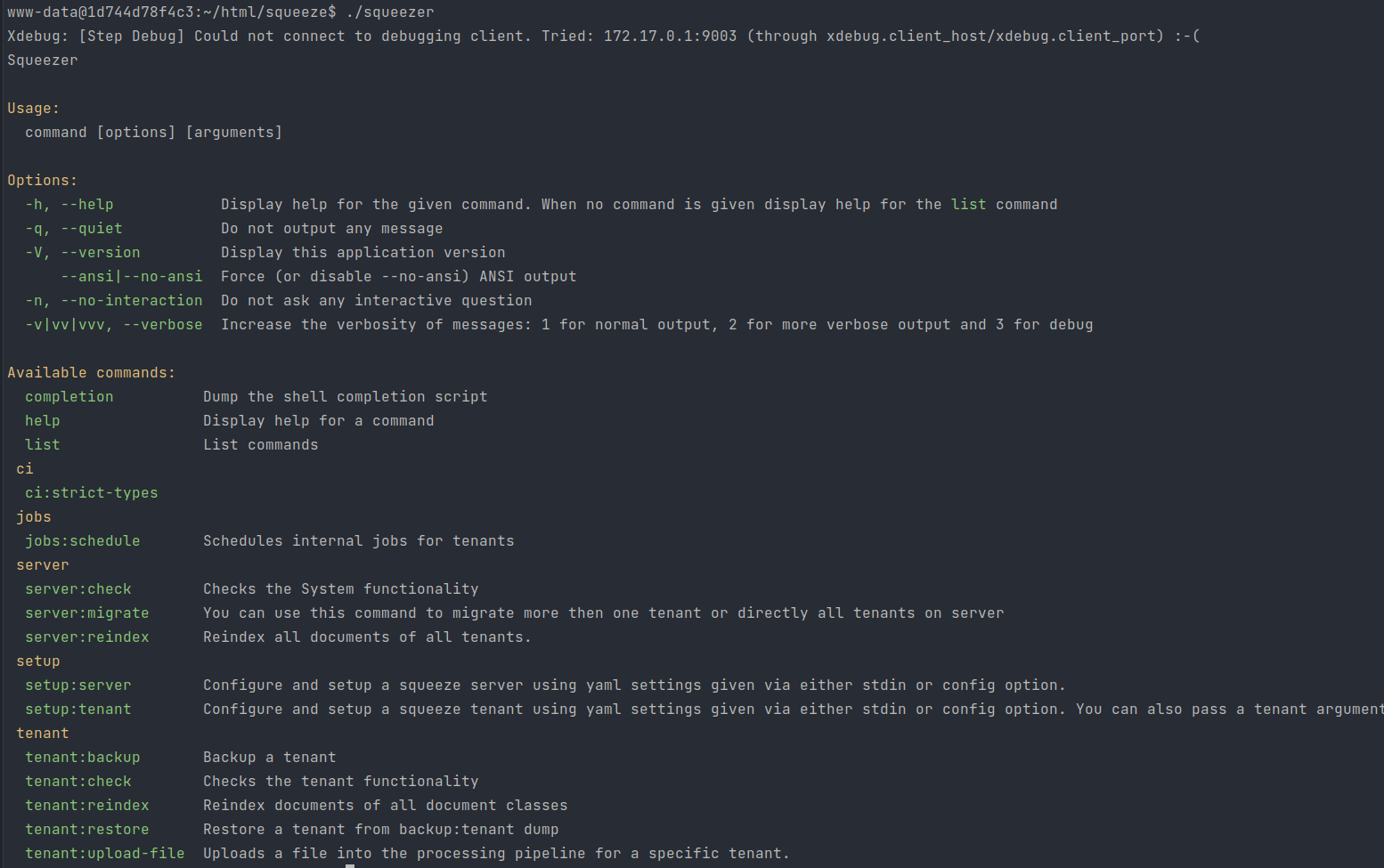
Verwendung
Windows
Öffnen Sie ein Terminal (Kommandozeile oder Powershell) und verwenden sie diese Befehle:
# htdocs Ordner öffnen, nutzen Sie hier Ihren Installationspfad
cd C:\\SQUEEZE\\htdocs
# CLI testen
php ./squeezer --helpLinux
# Installationspfad öffnen
cd /var/www/html/squeeze
# CLI testen
./squeezer --helpBefehle
Das Tool dokumentiert die Unterstützen Befehle und ihre Argumente selbstständig. Nutzen sie folgendes Flag, um herauszufinden welche Befehle es gibt und was sie tun:
# Mögliche Befehle auflisten
./squeezer
# oder
./squeezer list
# Ausgabe:
Squeezer
Usage:
command [options] [arguments]
Options:
-h, --help Display help for the given command. When no command is given display help for the list command
-q, --quiet Do not output any message
-V, --version Display this application version
--ansi|--no-ansi Force (or disable --no-ansi) ANSI output
-n, --no-interaction Do not ask any interactive question
-v|vv|vvv, --verbose Increase the verbosity of messages: 1 for normal output, 2 for more verbose output and 3 for debug
Available commands:
completion Dump the shell completion script
help Display help for a command
list List commands
ci
ci:strict-types
jobs
jobs:schedule Schedules internal jobs for tenants
server
server:check Checks the System functionality
server:migrate You can use this command to migrate more then one tenant or directly all tenants on server
server:reindex Reindex all documents of all tenants.
setup
setup:server Configure and setup a squeeze server using yaml settings given via either stdin or config option.
setup:tenant Configure and setup a squeeze tenant using yaml settings given via either stdin or config option. You can also pass a tenant argument to specify for which tenant installation should be done
tenant
tenant:backup Backup a tenant
tenant:check Checks the tenant functionality
tenant:reindex Reindex documents of all document classes
tenant:restore Restore a tenant from backup:tenant dump
tenant:upload-file Uploads a file into the processing pipeline for a specific tenant.
So lassen Sie sich einen Befehl erklären:
# Hilfe für Command server:check ausgeben
./squeezer server:check --help
# Ausgabe:
Description:
Checks the System functionality
Usage:
server:check
Options:
-h, --help Display help for the given command. When no command is given display help for the list command
-q, --quiet Do not output any message
-V, --version Display this application version
--ansi|--no-ansi Force (or disable --no-ansi) ANSI output
-n, --no-interaction Do not ask any interactive question
-v|vv|vvv, --verbose Increase the verbosity of messages: 1 for normal output, 2 for more verbose output and 3 for debug
SQUEEZE Admin FAQ
Sammlung von Hilfsartikeln, die keiner anderen Gruppe zugeordnet sind.
Email-Verarbeitung (Windows)
Um regelmäßig auf neue Emails zu prüfen, muss eine geplante Aufgabe eingerichtet werden.
Unter Windows können dafür die geplanten Tasks genutzt werden.
Unter Linux erfolgt die Einrichtung mit Hilfe von cron Jobs.
Einrichtung unter Windows
Unter Windows kann ein geplanter Task zur Regelmäßigen Prüfung der konfigurierten Postfächer genutzt werden.
Um einen neuen Task einzurichten müssen folgende Schritte durchgeführt werden:
1. Aufgabenplanung öffnen
Es kann eine eigener Unterordner für Squeeze aufgaben erstellt werden, wenn dies gewünscht ist
Auf der rechten Seite kann über den Menüpunkt "Aufgabe erstellen..." die Aufgabe für den Import der Emails angelegt werden.
2. Aufgabe erstellen
Der Name und die Beschreibung ist natürlich frei wählbar.
Damit die Aufgabe unabhängig von der Anmeldung eines Benutzers ausgeführt wird und auch unabhängig von eventuellen Passwortänderungen ist, hat sich bewährt, das System Konto auszuwählen.
Die Aufgabe "mit höchsten Privilegien" zu starten hat sich ebenfalls bewährt.
3. Trigger/Zeitpunkt festlegen
Das Intervall in dem die Emails abgerufen werden sollen ist ebenfalls frei definierbar.
Bewährt hat sich ein Intervall von 5 Minuten im Produktivsystem. Für Testsysteme kann dieser Intervall natürlich auch kleiner gewählt werden, wenn schnell und viel getestet werden soll.
4. Aktion festlegen
Als Programm muss die php.exe der Squeeze Installation ausgewählt werden.
Als Argumente müssen zwei Werte angegeben werden:
- - Pfad zur EmailProcessing.php z.B. C:\SQUEEZE\htdocs\jobs\EmailProcessing.php
- - Mandant für den die Emails abgerufen werden sollen z.B. client.squeeze.net
C:\SQUEEZE\htdocs\jobs\EmailProcessing.php client.squeeze.net
Datenbank Backup und Restore (Windows)
Backup
Das sichern der SQUEEZE Datenbank(en) ist ein wichtiger Punkt der Administration. Um Sicherzustellen, dass im Fehlerfall nicht alle Daten verloren gehen, muss eine regelmäßiges Backup der Datenbanken durchgeführt werden.
Für MariaDB und MySQL kann folgender Befehl genutzt werden:
D:\SQUEEZE\mariadb\bin\mysqldump.exe --user=root --password="" --host=127.0.0.1 --protocol=tcp --port=3306 --default-character-set=utf8 --routines --events --databases "datenbankname" --result-file="D:\Squeeze\Backup\datenbank.sql"
--databases ist nicht nur für die Selektion der Datenbank verantwortlich, sondern steuert ebenfalls, ob ein Create Statement des Schemas in den dump exportiert werden soll. Soll das Create Statement nicht erstellt werden, muss der Schalter--databases entfernt werden.
Backup aller Datenbanken
Um alle Datenbanken eines Servers zu sichern kann der folgende Befehl genutzt werden
mysqldump --user=root --password="" --host=127.0.0.1 --protocol=tcp --port=3306 --default-character-set=utf8 --routines --events --all-databases --result-file="D:\Squeeze\Backup\alle_datenbank.sql"
--all-databasesDie Aufgabe des Backups sollte zeitlich geplant werden. Dazu kann die Aufgabenplanung des Betriebssystems genutzt werden.
Die Parameter sind natürlich entsprechend der Installation anzupassen.
Restore
Um eine Datenbank aus einer Sicherung wiederherzustellen kann dieser Befehl genutzt werden:
Sollte die Datenbank bereits bestehen, werden hiermit alle vorhandenen Daten mit denen des Backups überschrieben.
D:\SQUEEZE\mariadb\bin\mysql.exe -u root -p "datenbankname" < "D:\Squeeze\Backup\datenbank.sql"
Da jeder Mandant seine eigene Datenbank hat, ist die Aufgabe je Mandant/Datenbank zu planen.
Aufgabe: Periodischer Worker Neustart
Für einen periodischen Neustart des Workers benötigen wir folgendes Script, welches als ".bat" gespeichert wird.
@echo off set DIENSTNAME1="05_SQUEEZE_Worker" net stop %DIENSTNAME1% 2>nul if errorlevel 2 ( echo Dienst ist bereits gestoppt . . . Starte %DIENSTNAME1% net start %DIENSTNAME1% ) net start %DIENSTNAME1%
1. Aufgabe erstellen
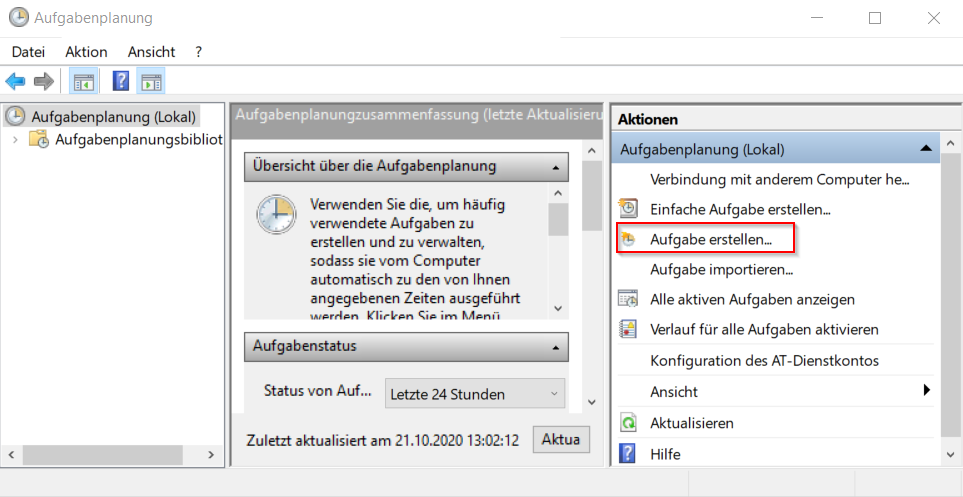
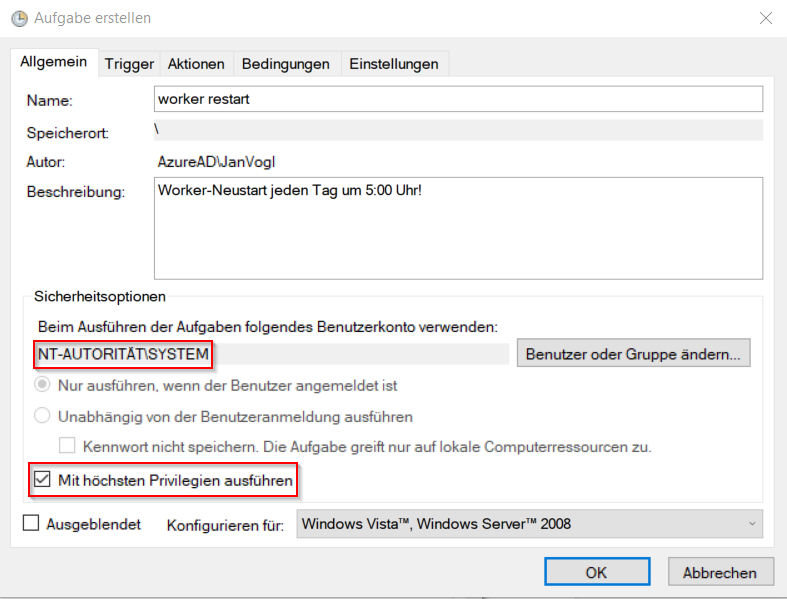
Der Name und die Beschreibung ist natürlich frei wählbar.
Damit die Aufgabe unabhängig von der Anmeldung eines Benutzers ausgeführt wird und auch unabhängig von eventuellen Passwortänderungen ist, hat sich bewährt, das System Konto auszuwählen.
Die Aufgabe "mit höchsten Privilegien" zu starten hat sich ebenfalls bewährt.
2. Trigger/Zeitpunkt festlegen
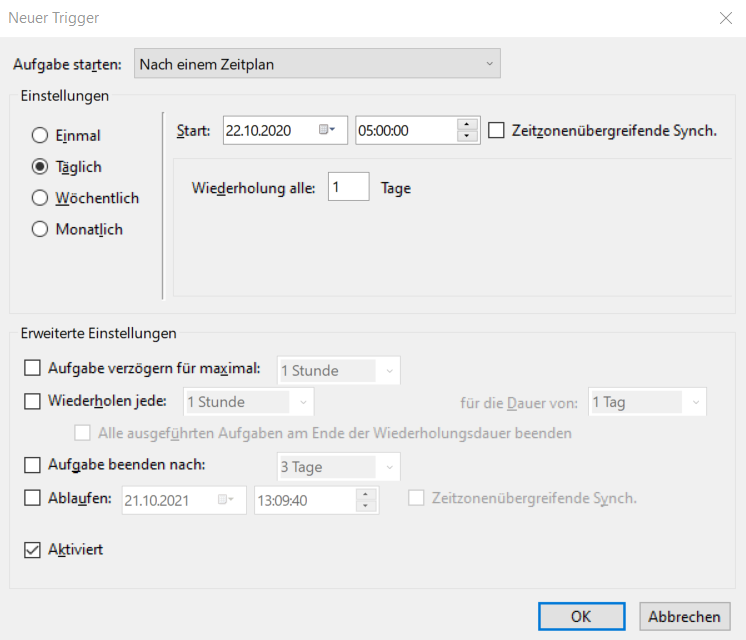
Das Intervall in dem der Worker neu gestartet werden soll ist frei definierbar.
3. Aktion festlegen
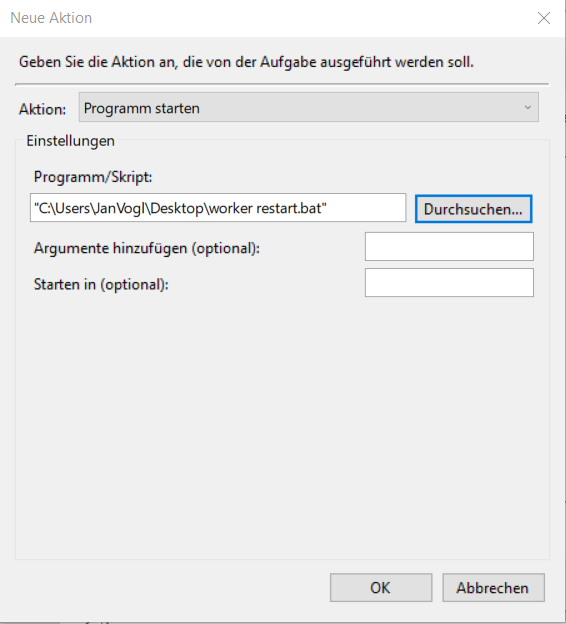
Als Programm wird die Oben erstellte ".bat" (worker restart.bat) ausgewählt.
ElasticSearch Speicher erweitern
Windows
Unter Windows kann eine kleine GUI Anwendung genutzt werden, um die Parameter des ElasticSearch Dienstes anpassen zu können:
C:\SQUEEZE\elasticsearch\bin\elasticsearch-service.bat manager 03_SQUEEZE_SearchEngine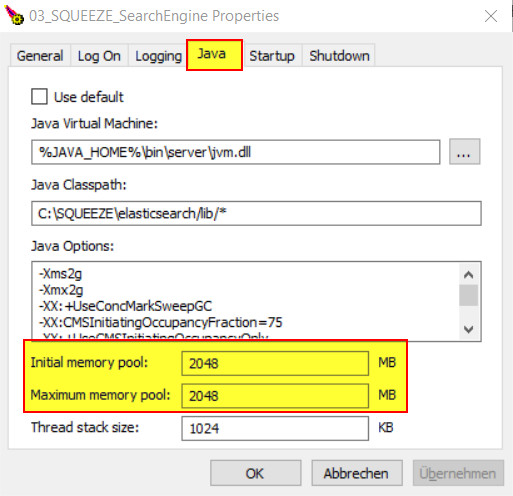
KI Integration
KI Proxy Konfiguration
Wenn Sie Squeeze mit dem KI Proxy verwenden möchten, dann folgen Sie folgendem Leitfaden für die Konfiguration.
Die Integration des KI Proxies ist erst ab Squeeze 2.6 verfügbar.
Ab Squeeze 2.13 müssen sie keinen KI Proxy Token konfigurieren, falls ihr Squeeze Mandant bereits mit dem Portal verknüpft wurde. In diesem Fall authentifiziert sich Squeeze beim KI Proxy mittels OAuth über das Portal.
Integration konfigurieren
Authentifizierung mittels KI Proxy Token (Bisheriges Verfahren)
Um die Integration der KI für alle Mandanten eines Servers zu konfigurieren, fügen Sie folgende Konfiguration der Server-Konfiguration hinzu:
{
"dexp": {
"aiProxy": {
"baseUrl": "https://ocr-proxy.squeeze.one",
"token": "...",
"version": "v0"
}
}
}Ersetzen Sie "..." durch den Access Token, der Ihnen zur Verfügung gestellt wurde.
Authentifizierung mittels Portal
Bei der Authentifizierung über das Portal, müsste die Konfiguration wie folgt aussehen. Mehr zur Integration des Portals, finden sie hier.
Hinterlegen Sie die Portal-Konfiguration nie in der Serverkonfiguration, sondern nur in der Mandantenkonfiguration.
{
"dexp": {
"aiProxy": {
"baseUrl": "https://ocr-proxy.squeeze.one",
"version": "v0"
}
},
"portal": {
"enabled": true,
"host": "https://portal.dexpro.de",
"auth": {
"clientId": "...",
"secret": "..."
}
}
}Integration nutzen
Wenn sie die Konfiguration in der Server- oder Mandantenkonfiguration hinzugefügt haben, dann können sie in der Admin-UI die KI konfigurieren.
Siehe dazu:
Ablaufende Credentials prüfen
Um server-weit zu prüfen, ob verwendete Credentials ablaufen werden, können Sie das Squeezer CLI nutzen:
squeezer server:check-ai-proxy-tokens -d 600
SQUEEZE Ai Proxy Token Check
============================
[WARNING] terstegen.squeeze.one: Token expires on 2024-11-22 12:36 So können Sie sich die Hilfe des Tools anzeigen lassen:
squeezer server:check-ai-proxy-tokens -h
Description:
Checks if ai proxy tokens are expired
Usage:
server:check-ai-proxy-tokens [options]
Options:
-d, --days[=DAYS] numbers of days before ai proxy token expires; default 28 days
-h, --help Display help for the given command. When no command is given display help for the list command
-q, --quiet Do not output any message
-V, --version Display this application version
--ansi|--no-ansi Force (or disable --no-ansi) ANSI output
-n, --no-interaction Do not ask any interactive question
-v|vv|vvv, --verbose Increase the verbosity of messages: 1 for normal output, 2 for more verbose output and 3 for debugReporting
Der Link zu den Reports befindet sich in der Navigation auf der linken Seite Ihrer SQUEEZE Installation, wenn Sie eingeloggt sind.
Autovalidierte Dokumente
Was bringt mir der Report?
Das Reporting "Autovalidierte Dokumente" stellt eine Übersicht dar, wie viele Dokumente autovalidiert wurden und wie viele manuell korrigiert werden mussten.
Abbildung: Report "Autovalidierte Dokumente" mit Testdatensätzen
Die Dokumente können über 4 optionale Filter eingeschränkt werden:
- Zeitraum
- Dokumentenklasse/-n
- Mandantennummer/-n
- Lieferantennummer/-n
Funktionsweise der Filter
Im Falle von einem Zeitraum können zwei Daten angeben werden, um den Zeitraum, wann ein Dokument validiert wurde, einzugrenzen.
Alternativ kann auch nur ein Datum angeben werden, woraufhin das Ergebnis auf die Dokumente reduziert wird, die seit diesem Datum validiert wurden.
Bei der Dokumentenklasse bzw. den Dokumentenklassen kann eine beliebige Anzahl ausgewählt werden, über das integrierte Dropdown-Menü. Die validierten Dokumente werden dann nach ihrer entsprechenden Dokumentenklasse gefiltert.
Es ist möglich die validierten Dokumente auf ihre Mandantennummer zu filtern.
Sollte der Wunsch bestehen mehrere Mandantennummern für die Filterung zu nutzen, müssen diese kommasepariert angegeben werden.
Es ist möglich die validierten Dokumente auf ihre Lieferantennummer zu filtern.
Sollte der Wunsch bestehen mehrere Lieferantennummern für die Filterung zu nutzen, müssen diese kommasepariert angegeben werden.
Was für Daten werden erhoben?
Um die validierten Dokumente zu erhalten werden folgende Daten verwendet:
- Dokumenten ID
- User ID
- Dokumentenklassen ID
- Mandantennummer
- Lieferantennummer
- Zeitpunkt der Validierung des Dokuments
Wann werden diese Daten erhoben?
Die Daten werden erhoben, sobald ein Dokument erfolgreich validiert wurde.
Wann werden die Daten gelöscht, wenn überhaupt?
Gegenwärtig werden die Daten nach 365 Tagen, über den existierenden Cleanup-Job, gelöscht, wenn nicht anders konfiguriert.
Ist ein Feature Flag notwendig?
Für dieses Reporting ist kein Feature Flag notwendig.
Verfügbarkeit
Ab der SQUEEZE Version 2.7 steht dieses Feature zur Verfügung.
Das (optionale) Filtern nach Mandantennummer/-n steht ab der SQUEEZE Version 2.26 zur Verfügung.
Felderauslesequalität
Was bringt mir der Report?
Das Reporting "Felderauslesequalität" stellt eine Übersicht dar, wie gut die einzelnen Felder verarbeitet wurden.
Hierbei wird pro Feld angezeigt wie oft ein Feld korrekt verarbeitet wurde, leer war und/oder inkorrekt befüllt wurde (und damit manuell korrigiert werden musste).
Die Daten werden sowohl als fester Zahlenwert aufgeführt, wie auch als prozentualer Wert.

Abbildung: Report "Feldauslesequalität" mit Testdatensätzen
Die Felder können über 5 optionale Filter eingeschränkt werden:
- Zeitraum
- Dokumentenklasse/-n
- Mandantennummer/-n
- Lieferantennummer/-n
- Felder
Funktionsweise der Filter
Im Falle von einem Zeitraum können zwei Daten angeben werden, um den Zeitraum, wann ein Feld validiert wurde, einzugrenzen.
Alternativ kann auch nur ein Datum angeben werden, woraufhin das Ergebnis auf die Felder reduziert werden, die seit diesem Datum validiert wurden.
Bei der Dokumentenklasse bzw. den Dokumentenklassen kann eine beliebige Anzahl ausgewählt werden, über das integrierte Dropdown-Menü. Die validierten Felder werden dann nach ihrer entsprechenden Dokumentenklasse gefiltert.
Es ist möglich die validierten Felder auf die Mandantennummer des Dokumentes zu filtern, denen die Felder angehören.
Sollte der Wunsch bestehen mehrere Mandantennummern für die Filterung zu nutzen, müssen diese kommasepariert angegeben werden.
Es ist möglich die validierten Felder auf die Lieferantennummer des Dokumentes zu filtern, denen die Felder angehören.
Sollte der Wunsch bestehen mehrere Lieferantennummern für die Filterung zu nutzen, müssen diese kommasepariert angegeben werden.
Um auf bestimmte Felder zu filtern kann ein Dropdown-Menü verwendet werden, in welchem die gewünschten Felder zur Filterung markiert werden können.
Ist es möglich Felder vom Report auszuschließen?
Ja, es ist möglich Felder vom Report auszuschließen.
In Felder-Menü der Dokumentenklasse gibt es eine Checkbox dafür, welche Report-Daten gespeichert werden sollen.
Feld Daten werden immer erst für den Report gespeichert, wenn die Checkbox aktiv ist.
Das heißt, sollte der Wunsch existieren, nachträglich für alle Dokumente ein neues Feld zu speichern, müssen alle Dokumente erneut durch die Prozess-Schritte Extraktion und Validierung bearbeitet werden.
Was für Daten werden erhoben?
- Feldnamen
- Feld Beschreibungen
- Dokumenten ID (vom Dokument in dem das Feld existiert)
- Zeitpunkt der Dokumenten Extraktion
- Aus dem Dokument extrahierter Feldwert
- Manuell angegebener Feldwert
- Anzahl der Alternativen Werte des Feldes
- Feld Zustände
- Ist das Feld leer?
- Ist das Feld valide?
- Ist das Dokument, in dem das Feld existiert, validiert worden?
Wann werden die Daten erhoben?
Die Daten werden erstmals im Extraktionsschritt erhoben. Nach erfolgreicher Validierung eines Dokuments werden die erhobenen Daten abgeglichen und ggf. angepasst (z.B. bei einer manuellen Korrektur).
Wann werden die Daten gelöscht, wenn überhaupt?
Gegenwärtig werden die Daten nach 365 Tagen, über den existierenden Cleanup-Job, gelöscht, wenn nicht anders konfiguriert.
Ist ein Feature Flag notwendig?
Um dieses Feature verwenden zu können ist das Feature Flag "Report Validated Documents" notwendig
Verfügbarkeit
Ab der SQUEEZE Version 2.7 steht dieses Feature zur Verfügung.
Das (optionale) Filtern nach Mandantennummer/-n steht ab der SQUEEZE Version 2.26 zur Verfügung.
Erläuterung der Statistiken
Im folgenden eine kurze Erläuterung zu den unterschiedlichen Graphen, welche im Fenster Reports zu finden sind.
Herkunft der Dokumente/Origin of the documents
Zeigt die Quelle der Dokumente an. Es werden E-Mail, manueller Upload und Dokumenten Splits als Werte mit aufgenommen.
Exporte/Exports
Exporte zeigt die durchgeführte Anzahl an Exporten der Exportschnittstellen.
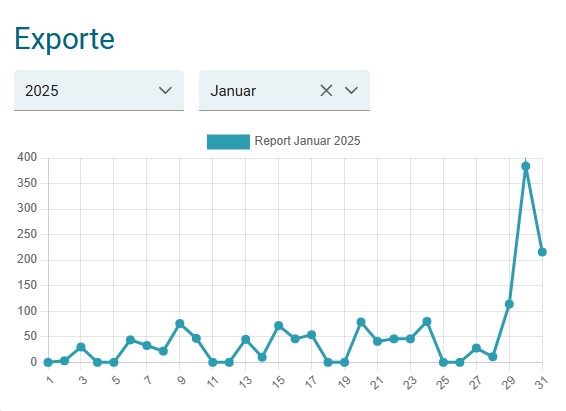
Exportierte Dokumente/Exported documents
Im Gegensatz zu Exporte zeigt Exportierte Dokumente die Anzahl der exportierten Dokumente. Um es besser zu erläutern ein Beispiel: 1 Dokument wird von 2 Schnittstellen exportiert. Damit ist die Anzahl der Exports 2 und die Anzahl der Exportierten Dokumente 1.
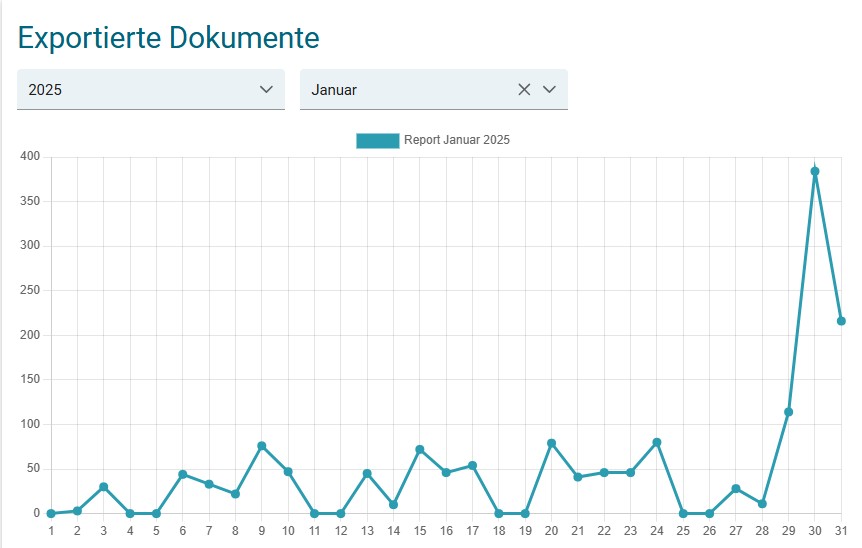
Autovalidierte Dokumente/Autovalidated documents
Zeigt die Dokumente, welche autovalidiert oder manuell validiert worden sind. Man kann nach Zeitraum und Dokumentenklasse filtern. Zusätzlich lässt sich nach bestimmten Lieferanten filtern.
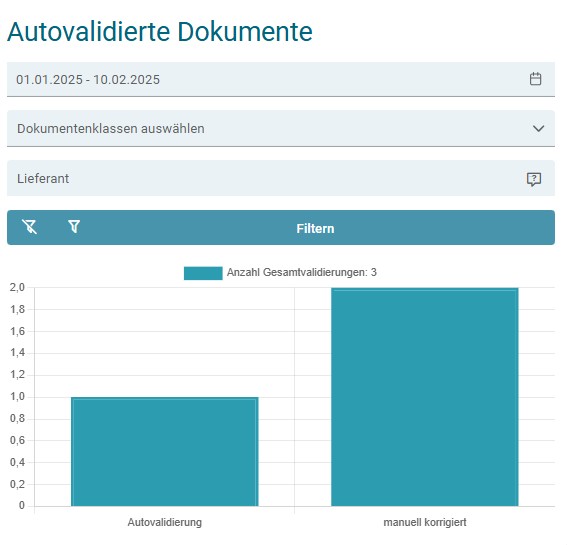
Verarbeitete Dokumente/Processed documents
Verarbeitete Dokumente zeigt die Dokumente, welche verarbeitet wurden. Dazu zählen auch gelöschte Dokumente.