SQUEEZE Admin-Handbuch
Handbuch zur Administration von Squeeze
- Systemvoraussetzungen
- Installation
- Stapelklassen
- Dokumentenklassen
- Dokumentenfelder
- Lokatoren
- Lokatoren
- Testmodus für Lokatoren
- Lokator: Regular Expression
- Lokator: KeyWord
- Lokator: KeyWord to Value
- Lokator: Value next to KeyWord
- Lokator: Invoice Amounts
- Lokator: Document Date
- Lokator: Search for DB linked data
- Lokator: Search for line items
- Lokator: Search for line items
- Stammdaten
- Stammdaten
- Anlegen einer neuen Stammdatentabelle im Webclient
- Konfiguration und Initialisieren einer neuen Stammdatentabelle via CSV-Upload
- Intervall-gesteuerte Aktualisierung der Stammdaten mittels CSV-Upload
- Jobs
- Exportschnittstellen
- Benutzer und Rollen
- SQUEEZE Admin FAQ
Systemvoraussetzungen
Systemvoraussetzungen für Server und Clients
Systemvoraussetzungen des Servers
Übersicht der Systemvoraussetzungen des Servers.
Hardware / Virtual Maschine
| Minimum | Empfehlung | |
|---|---|---|
| Betriebssystem | Linux/Windows | Linux/Windows |
| CPU Takt | 2.2 GHz | 3.0 GHz |
| CPU Kerne | 6 Cores | 8 Cores |
| RAM | 8 GB | 16 GB |
| Festplatte | HDD 7200 rpm | SSD |
| Festplattenspeicher | 200 GB | 500 GB |
| Netzwerk | 100 Mbit | 1000 Mbit |
Betriebssystems
| OS | Version | Anmerkung |
|---|---|---|
| Windows | 7 | Uneingeschränkt unterstützt |
| Windows | 10 | Uneingeschränkt unterstützt |
| Windows | Server 2008 R2 | Uneingeschränkt unterstützt |
| Windows | Server 2012 | Uneingeschränkt unterstützt |
| Windows | Server 2012 R2 | Uneingeschränkt unterstützt |
| Windows | Server 2016 | Uneingeschränkt unterstützt |
| Ubuntu | 14.04 | |
| Ubuntu | 16.04 | Uneingeschränkt unterstützt |
| Ubuntu | 18.04 | Uneingeschränkt unterstützt |
| Debian | 8 | |
| Debian | 9 | Uneingeschränkt unterstützt |
| Debian | 10 | Uneingeschränkt unterstützt |
Generell werden alle Betriebssysteme, auf denen ein Webserver betrieben und PHP inkl. aller benötigten Erweiterungen (siehe Runtimes) interpretiert werden kann, unterstützt. Das bedeutet, dass die meisten Linux Distributionen unterstützt werden, sofern sich alle benötigten Pakete installieren lassen.
Datenbanksysteme
| Hersteller | Version |
|---|---|
| Microsoft | SQL Server 2005 |
| Microsoft | SQL Server 2008 |
| Microsoft | SQL Server 2012 |
| Microsoft | SQL Server 2014 |
| Microsoft | SQL Server 2016 |
| MySQL | 5.5 - 5.7 |
| MariaDB | 5.5.7 |
| MariaDB | 10.0 - 10.2 |
Network
Eingehender Netzwerkverkehr
| Port | Beschreibung |
|---|---|
| 80 | HTML Frontend und API |
| 443 | HTML Frontend und API (mit SSL) |
Ausgehender Netzwerkverkehr
| Port | Beshreibung |
|---|---|
| 25 | SMTP für das versenden von Emails |
| 587 | SMTP für das versenden von Emails (mit Verschlüsselung) |
| 143 | IMAP um Email abzuholen |
| 993 | IMAP um Email abzuholen (mit Verschlüsselung) |
| 443 | EWS um Email abzuholen (mit Verschlüsselung) |
| 33?? | SAP RFC Verbindung (?? = SAP Instanznummer) |
Runtimes
Squeeze und dessen Komponenten benötigen einige Bibliotheken und Anwendungen die installiert sein müssen. Sollten Sie den Windows installer nutzen, so befinden sich alle erforderlichen Anwendungen und Bibliotheken bereits im Setup und werden mit installiert und grundsätzlich eingerichtet. Der Installer ist so erstellt worden, dass ein Out-of-the-Box System installiert wird, welches sofort nutzbar ist.
Die Anwendungen und Bibliotheken werden dabei unterteilt. Es gibt direkte und indirekte Abhängigkeiten Ein Beispiel ist das Message Queue System (RabbitMQ).
In Komplexeren Umgebungen kann es erforderlich sein, diese Komponenten auf verschiedene Systeme zu verteilen. In diesem Fall müssen Sie sich selber um die Bereitstellung der Anwendungen kümmern.
Direkte Abhängigkeiten
| Runtime | Version | Benötigt von |
|---|---|---|
| PHP | 7.3 | Server, Worker |
| Java | 8 | Server, Worker |
"Server" meint den Squeeze Server.
Indirekte Abhängigkeiten
| Runtime | Version | Benötigt von |
|---|---|---|
| Erlang | 10.5 | RabbitMQ |
| Java | In Abhängigkeit der Elasticsearch Version | Elasticsearch |
Systemvoraussetzungen des Clients
Systemvoraussetzungen der Clients
Betriebssystem
Grundsätzlich werden alle gängigen Betriebssysteme unterstützt.
Das Betriebssystem selbst ist nicht sonderlich entscheidend, da es sich bei Squeeze um eine reine Webanwendung handelt.
Entscheidender ist, dass der genutzte Browser HTML5 vollständig unterstützt (siehe Abschnitt Browser).
| OS | Version | Anmerkung |
|---|---|---|
| Windows | 7 | Uneingeschränkt unterstützt |
| Windows | 10 | Uneingeschränkt unterstützt |
| Windows | 11 | Uneingeschränkt unterstützt |
| Ubuntu | 16.04 | Uneingeschränkt unterstützt |
| Ubuntu | 18.04 | Uneingeschränkt unterstützt |
| Debian | 8 | Uneingeschränkt unterstützt |
| Debian | 9 | Uneingeschränkt unterstützt |
| Debian | 10 | Uneingeschränkt unterstützt |
Browser
Grundsätzlich werden alle gängigen Browser unterstützt, jedoch sind nicht immer alle unsererseits aktuell mit allen Funktionen getestet.
Folgend eine Übersicht der aktuell getesteten Browser.
| Hersteller | Version | Anmerkung |
|---|---|---|
| Microsoft | Internet Explorer 11 | Uneingeschränkt unterstützt (bis Squeeze Version 1.12.9) |
| Microsoft | Edge | Uneingeschränkt unterstützt |
| Mozilla | Firefox | Uneingeschränkt unterstützt |
| Chrome | Uneingeschränkt unterstützt |
Installation
Serverinstallation Windows
Der für die Squeeze-Server Installation notwendige Installer wird von der Firma Dexpro-Solutions GmbH auf Anfrage zur Verfügung gestellt.
In Zukunft wird es ein entsprechendes Download-Portal geben, wo sowohl der Server - Installer als auch die Dateien für das Update auf die neueste Squeeze - Version heruntergeladen werden können.
Installation Squeeze - Server
Squeeze kann auf jeder Partition eines Rechners installiert werden. Im Setup sind einige Pfade voreingestellt (D:.\Squeeze).
Für die Installations-Dokumentation wird die Server-Installation mit Version 1.5.0 auf der C:\ Partition durchgeführt.
Die Installation wird mit Doppelklick auf die Installer.exe gestartet und muss mit administrativen Benutzer-Rechten durchgeführt werden.
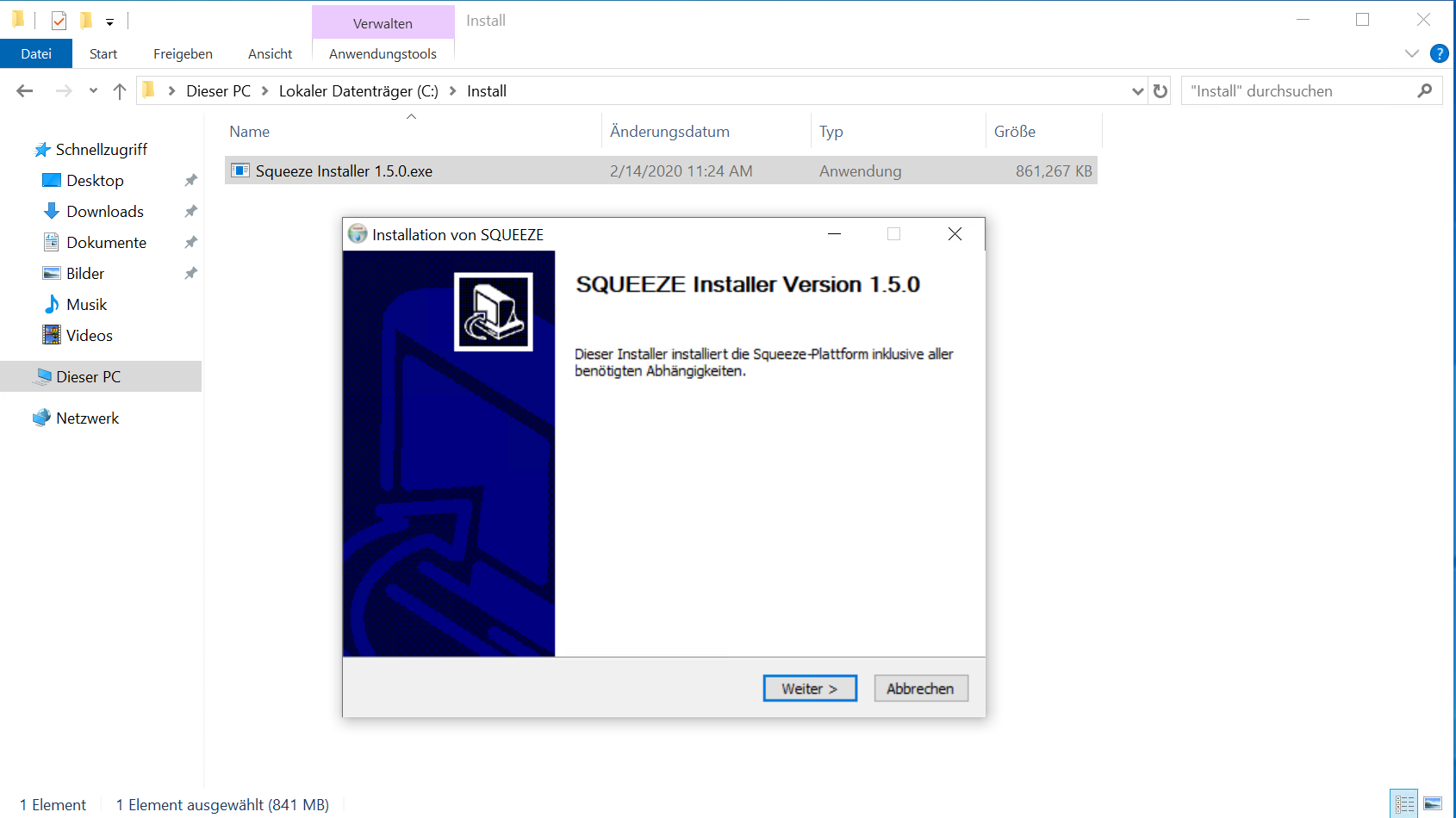
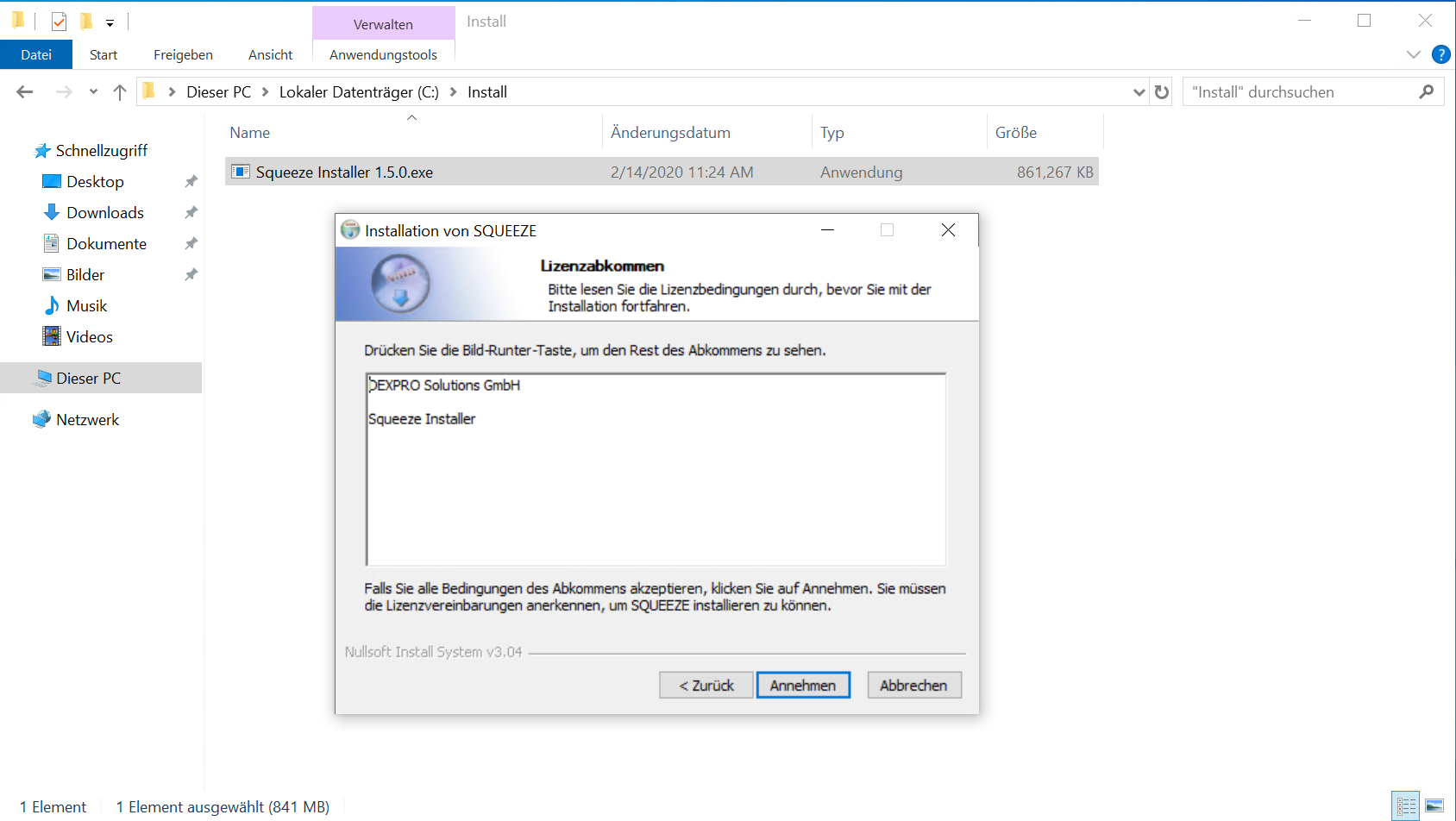
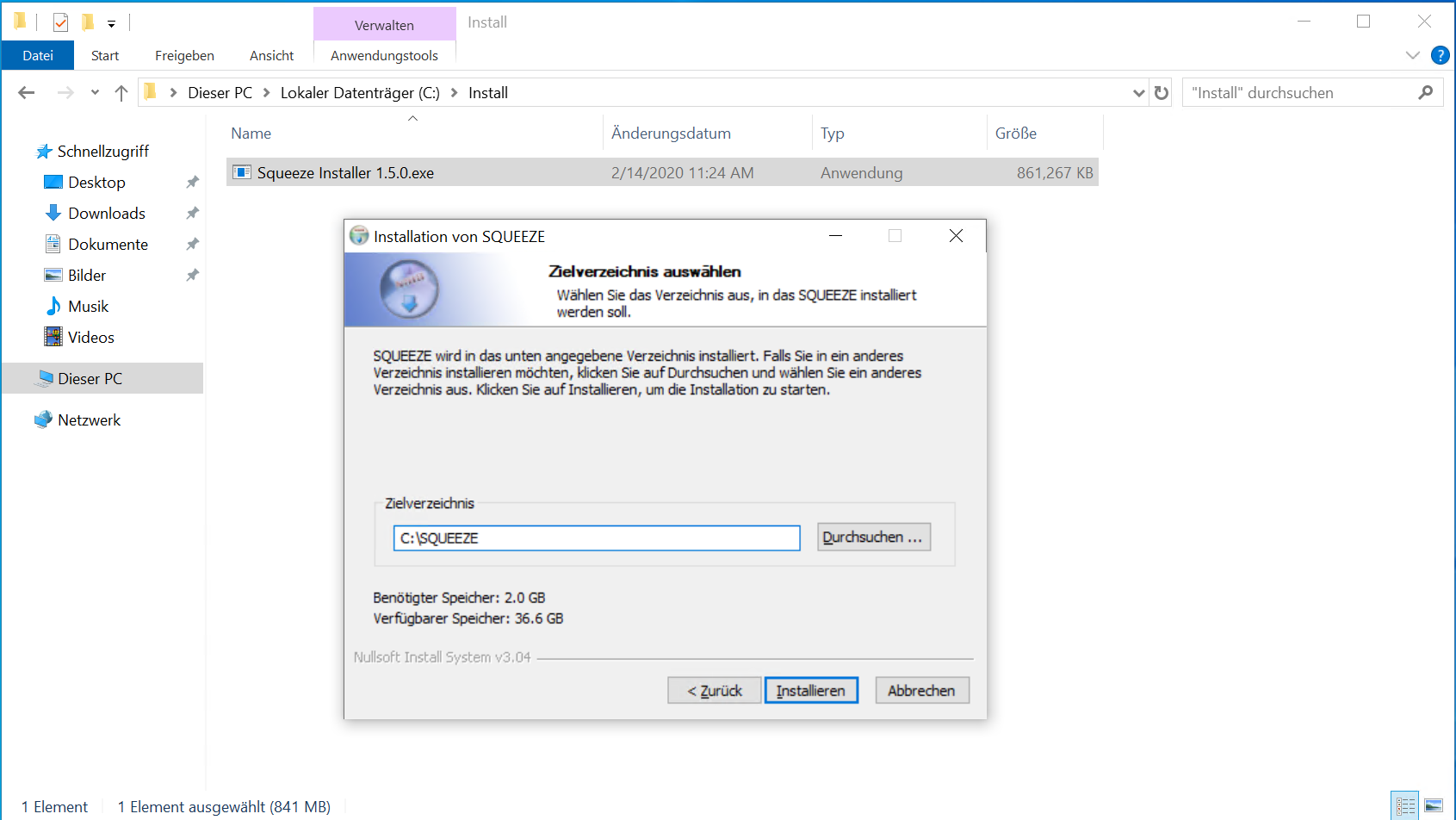
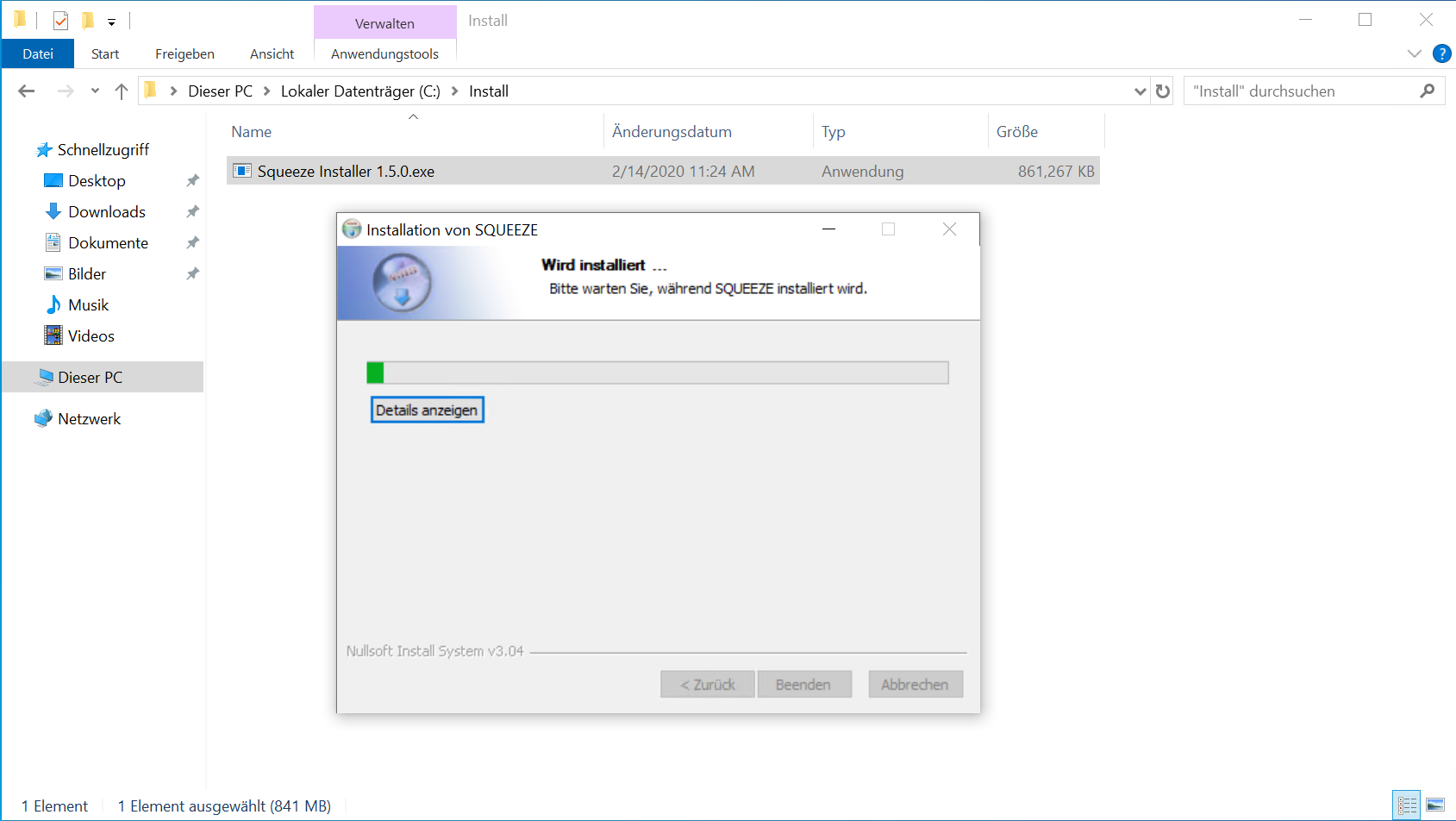
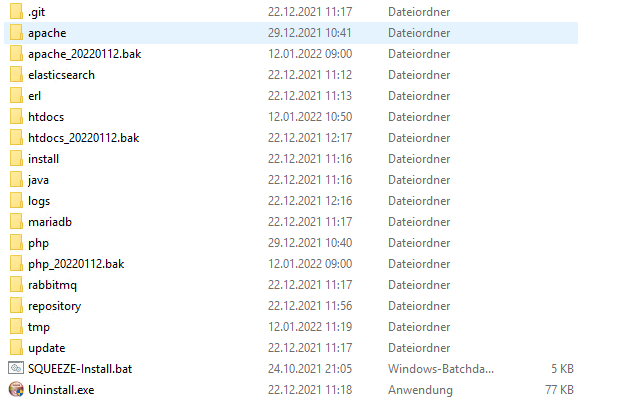
Nachdem der Server-Installer die erforderlichen Dateien in das angegebene Verzeichnis (C:\Squeeze) entpackt hat, startet die Installation automatisch.
Nachdem das initiale Setup abgeschlossen ist, sollten geprüft werden ob alle Dienste installiert worden sind und diese bereits gestartet wurden.
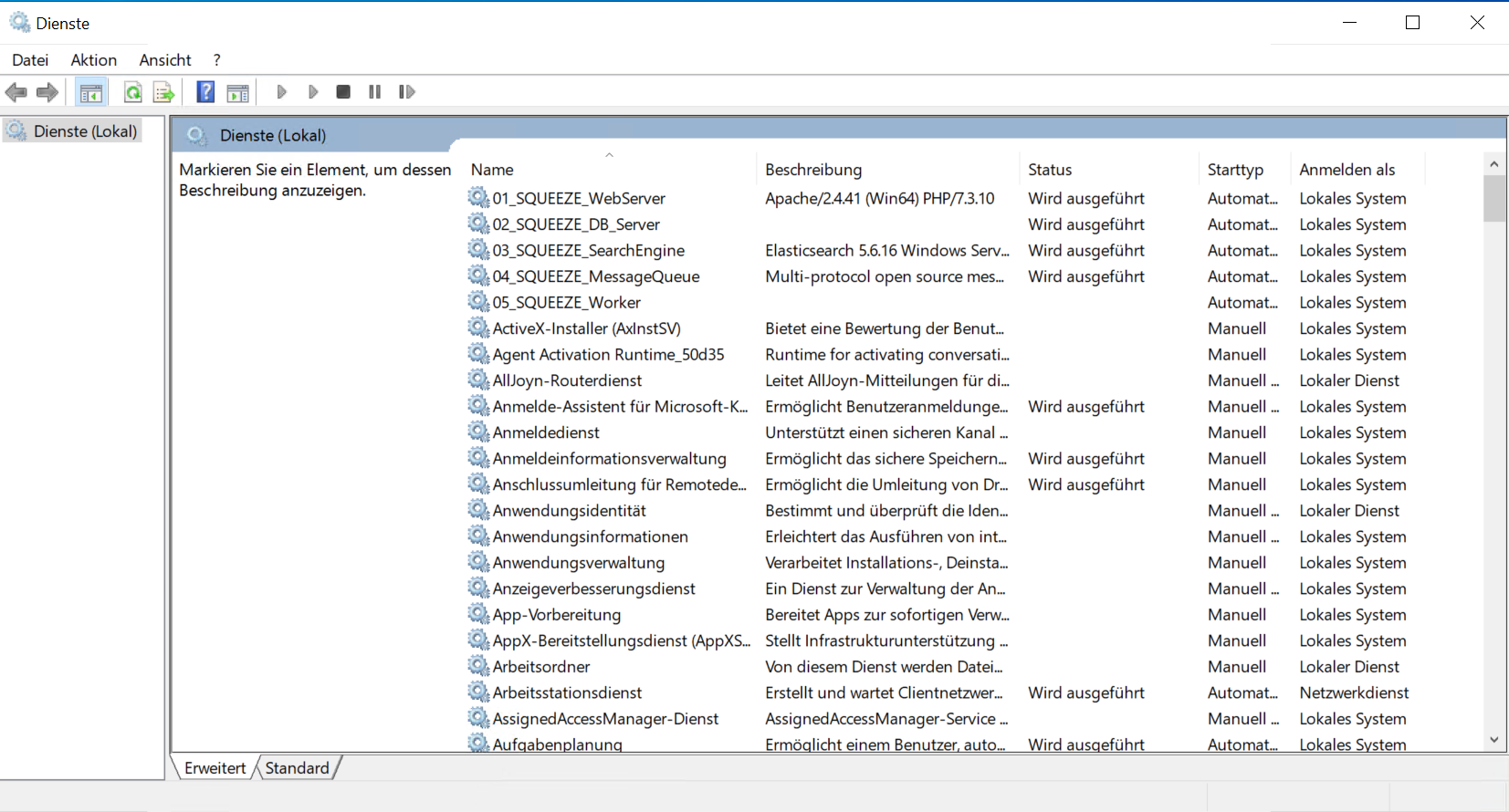
| Dienstname | Staus |
| 01_SQUEEZE_WebServer | Wird ausgeführt |
| 02_SQUEEZE_DB_Server | Wird ausgeführt |
| 03_SQUEEZE_SearchEngine | Wird ausgeführt |
| 04_SQUEEZE_MessageQueue | Wird ausgeführt |
| 05_SQUEEZE_Worker | nicht gestartet |
Die Dienste 01 bis 04 sollten gestartet sein. Der Dienst 05 ist zu diesem Zeitpunkt nicht gestartet, dieser Dienst muss nach Abschluss der Server und - Mandanten-Konfiguration erst konfiguriert werden bis er gestartet werden kann.
Konfiguration Squeeze - Server
Nachdem das eigentliche Server-Setup abgeschlossen ist, wird der Server konfiguriert. Dazu wird der Browser gestartet und in der Adresszeile des Browsers der gewünschte Mandanten-Name eingegeben.
Es können mehrere technische Mandanten auf einem Squeeze Server konfiguriert werden. Jeder Mandant hat sein eigenes Repository und eine eigene Datenbank.
Im ausgelieferten Server-Setup ist bereits eine Lizenz für 300 Dokumente für den Mandanten localhost enthalten.
Die Mandanten-Installation für localhost wird für diese Dokumentation verwendet. Dazu wird im Browser in der Adresszeile http://localhost eingegeben. Daraufhin startet die Konfiguration des Squeeze-Servermandanten:
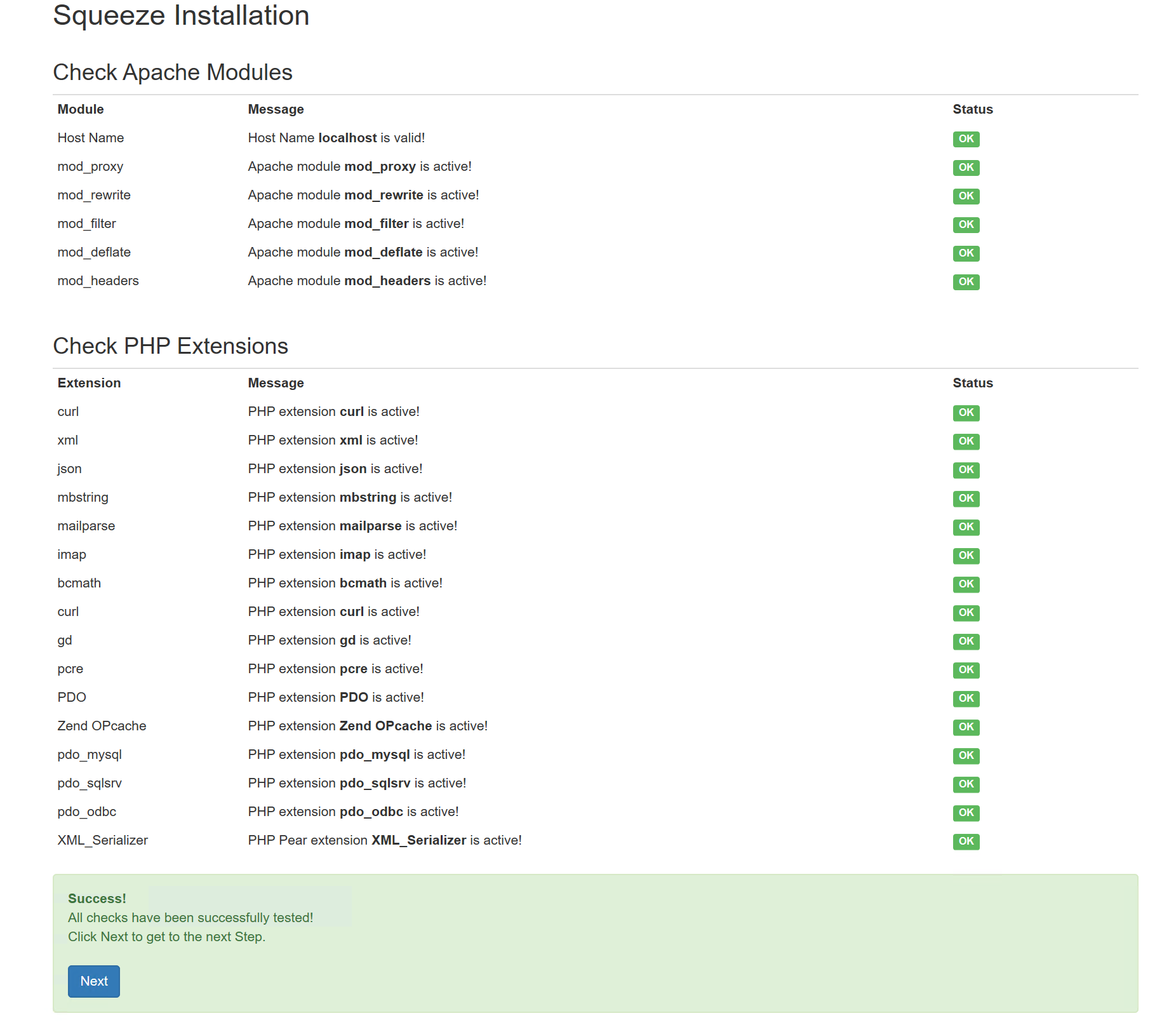
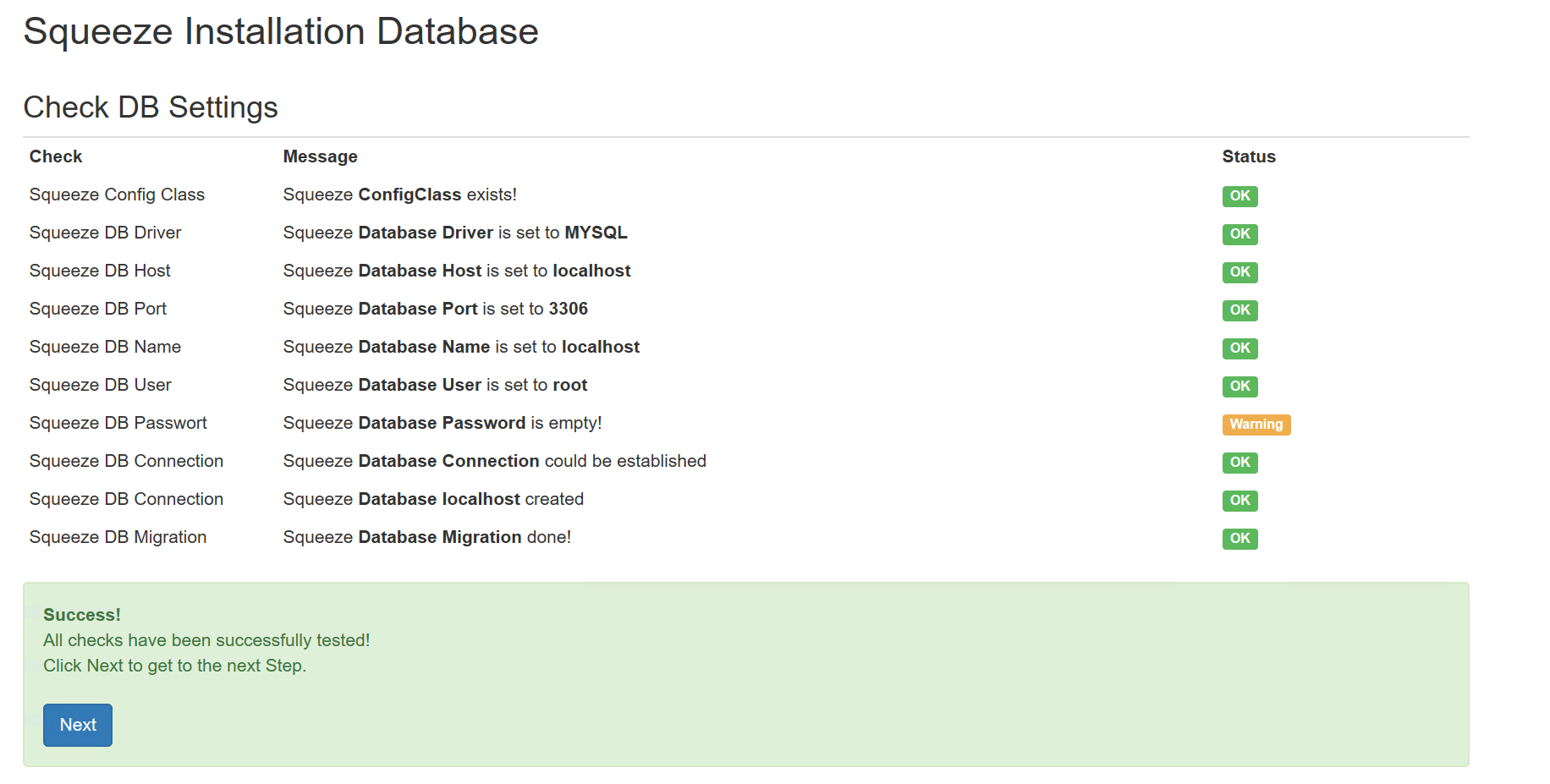
Wenn MS SQL gewählt wird dann ist der Port 1433, sollte eine Instanz von MS SQL genutzt werden, dann muss der Port leer bleiben (dynamischer Port), bei MYSQL ist der Port 3306.
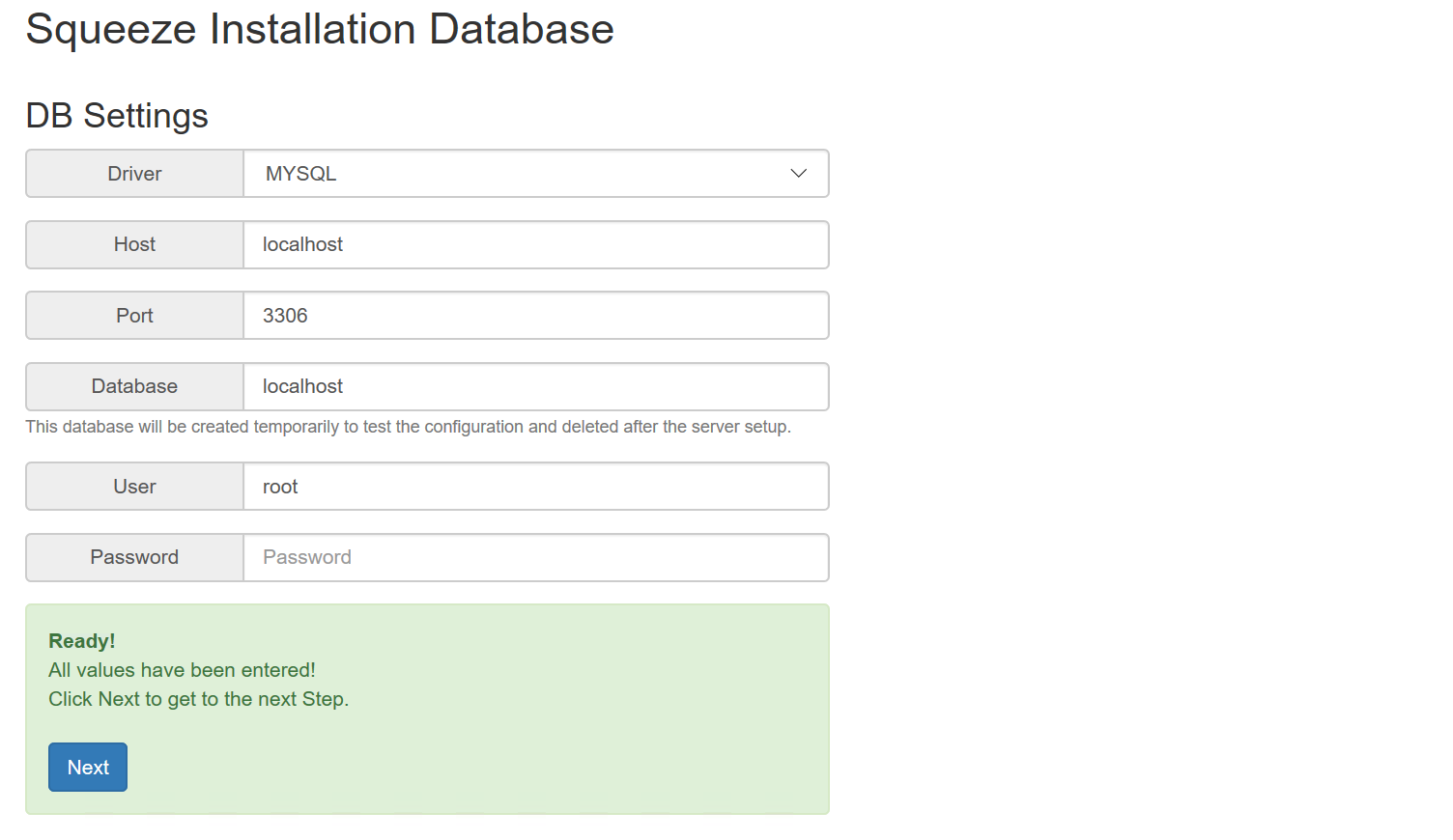
In diesem Beispiel wird die ausgelieferte MariaDB genutzt. Die Felder können entsprechend angepasst werden. Mit dem Button Next öffnet sich der nächste Dialog:
- Admin Password: guest
- Worker Password: squeeze
- Password: squeeze
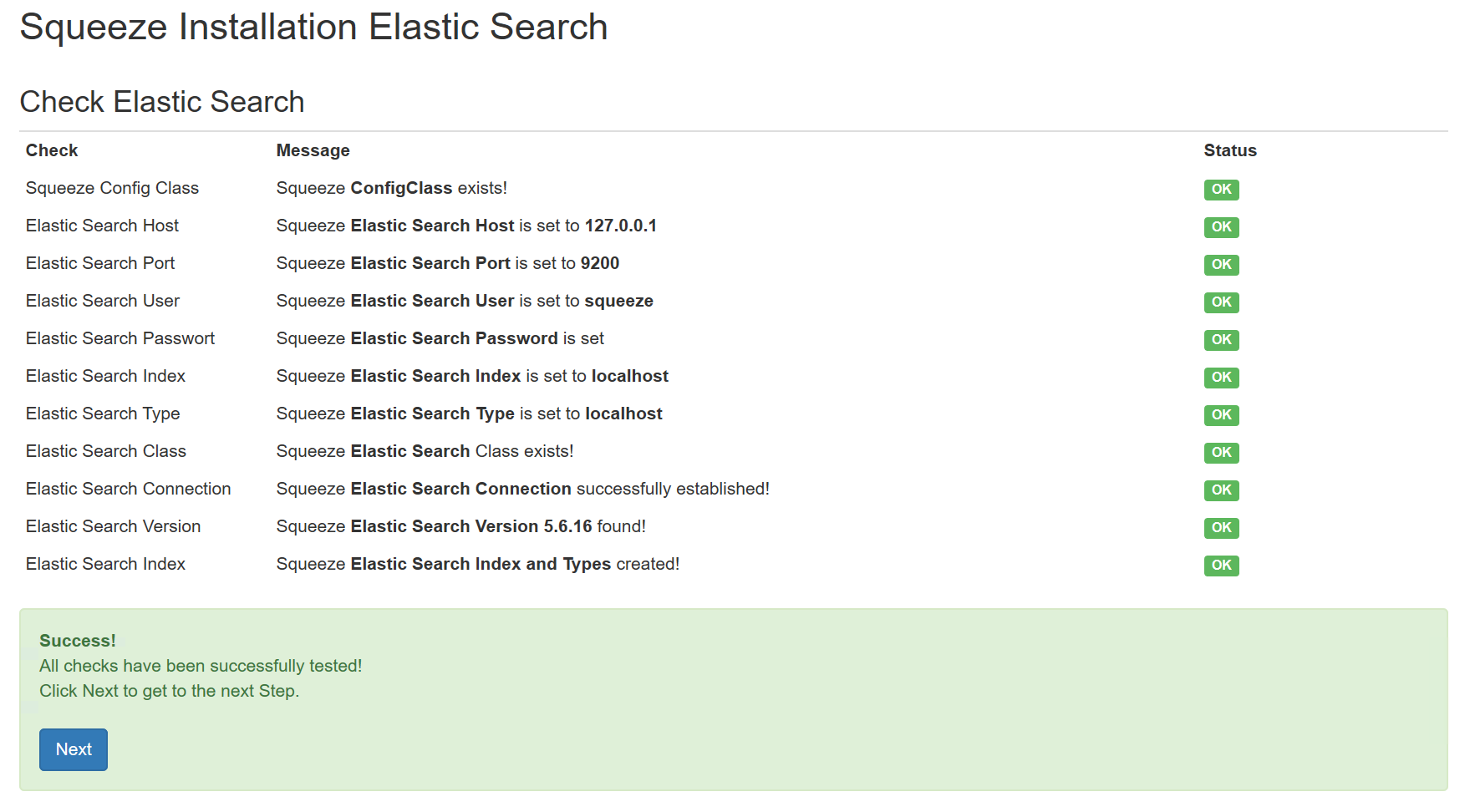
Für die Demo-Installation wird kein SMTP Versand konfiguriert, da die verwendete Sandbox für die Installation keinen Internetzugang hat. Dazu wird im Feld "Use SMTP Zugang" der Wert auf False gesetzt
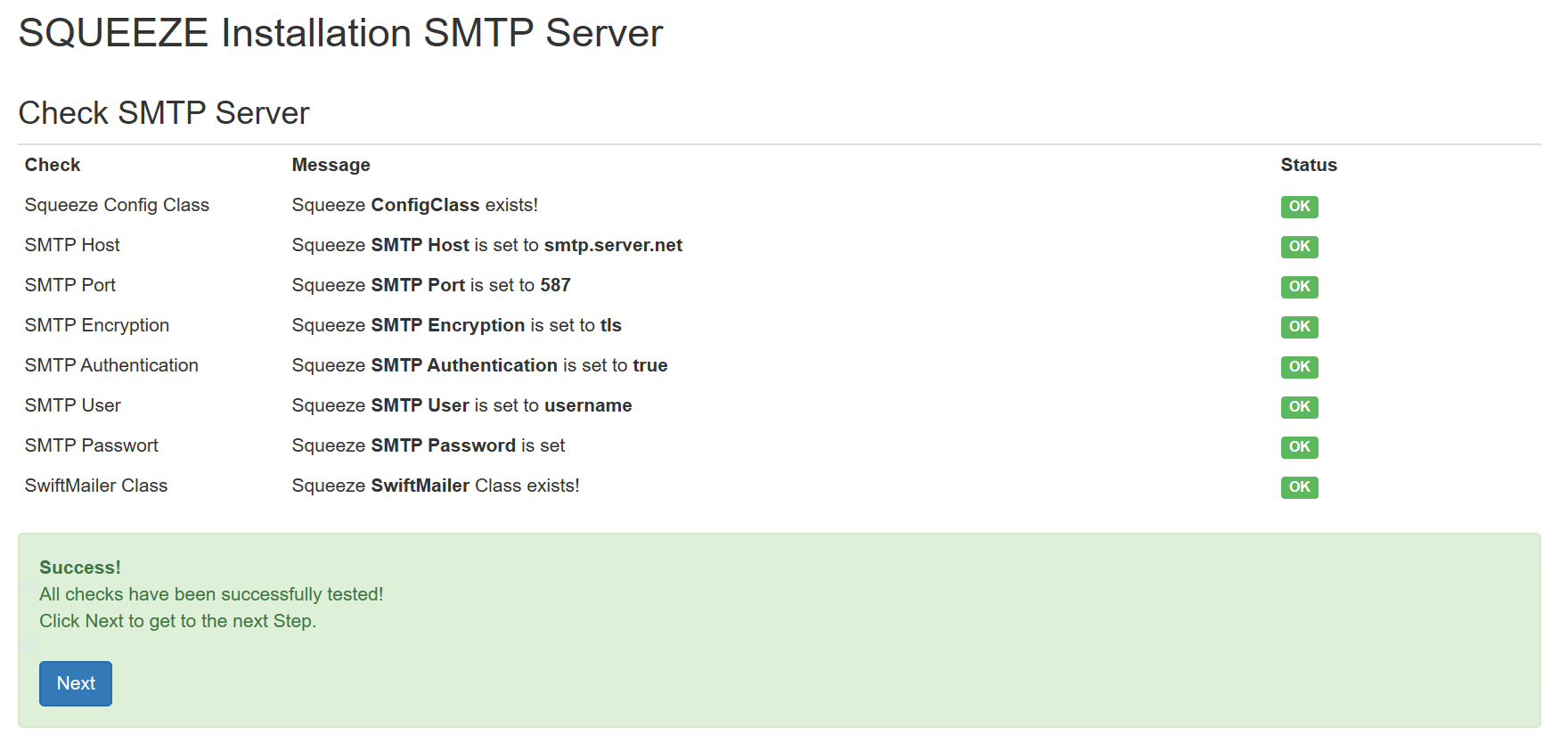
Mit dem Button Next öffnet sich der nächste Dialog:
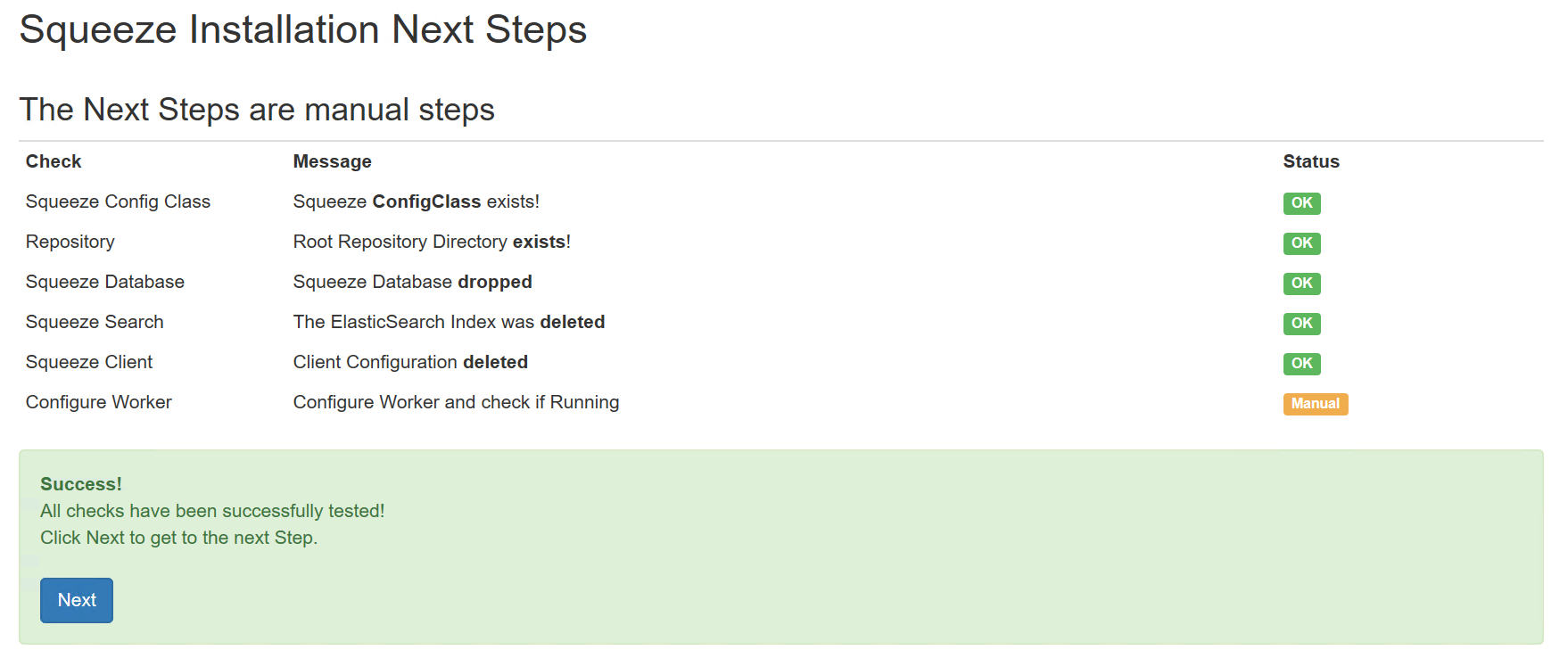
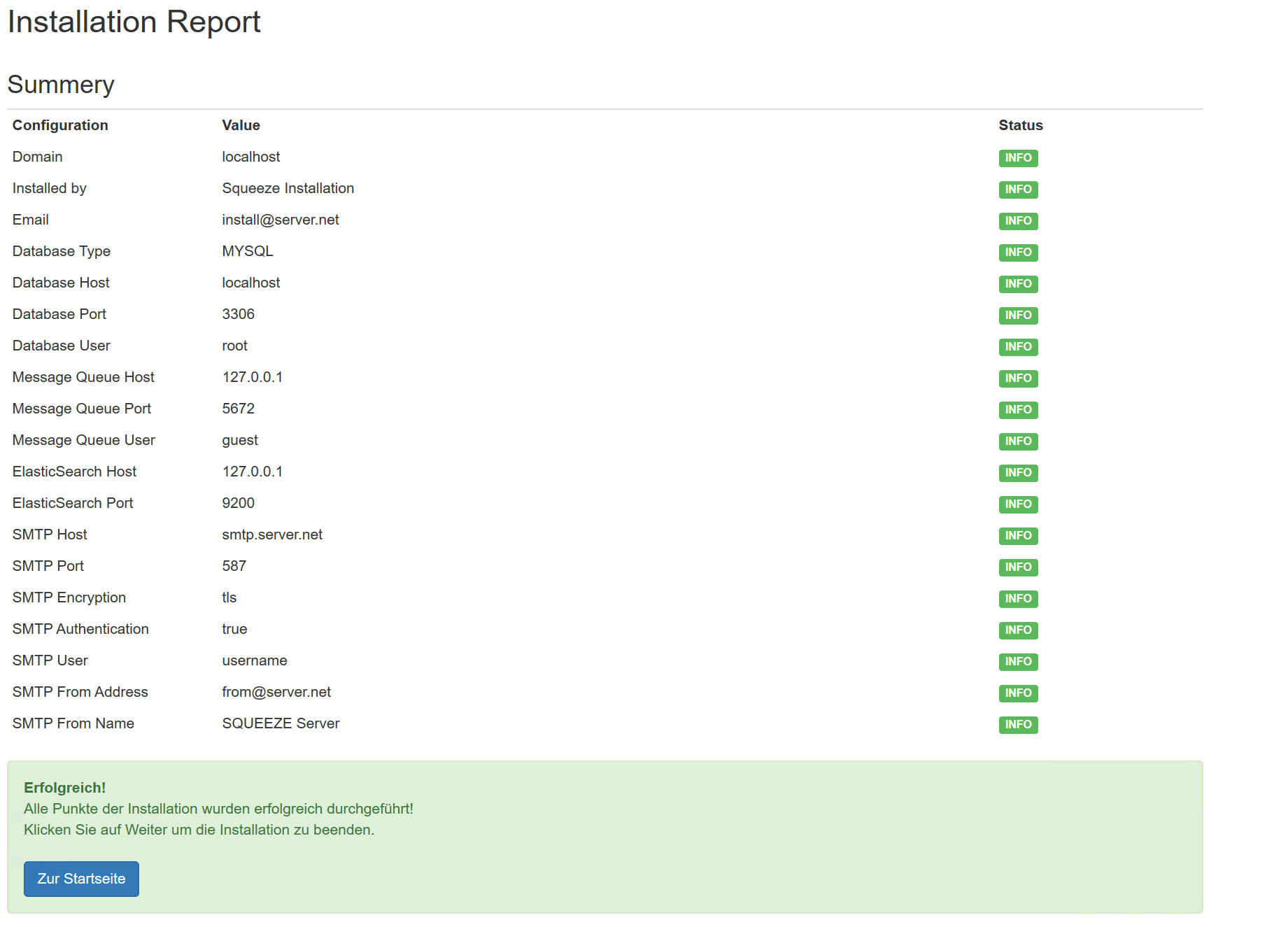



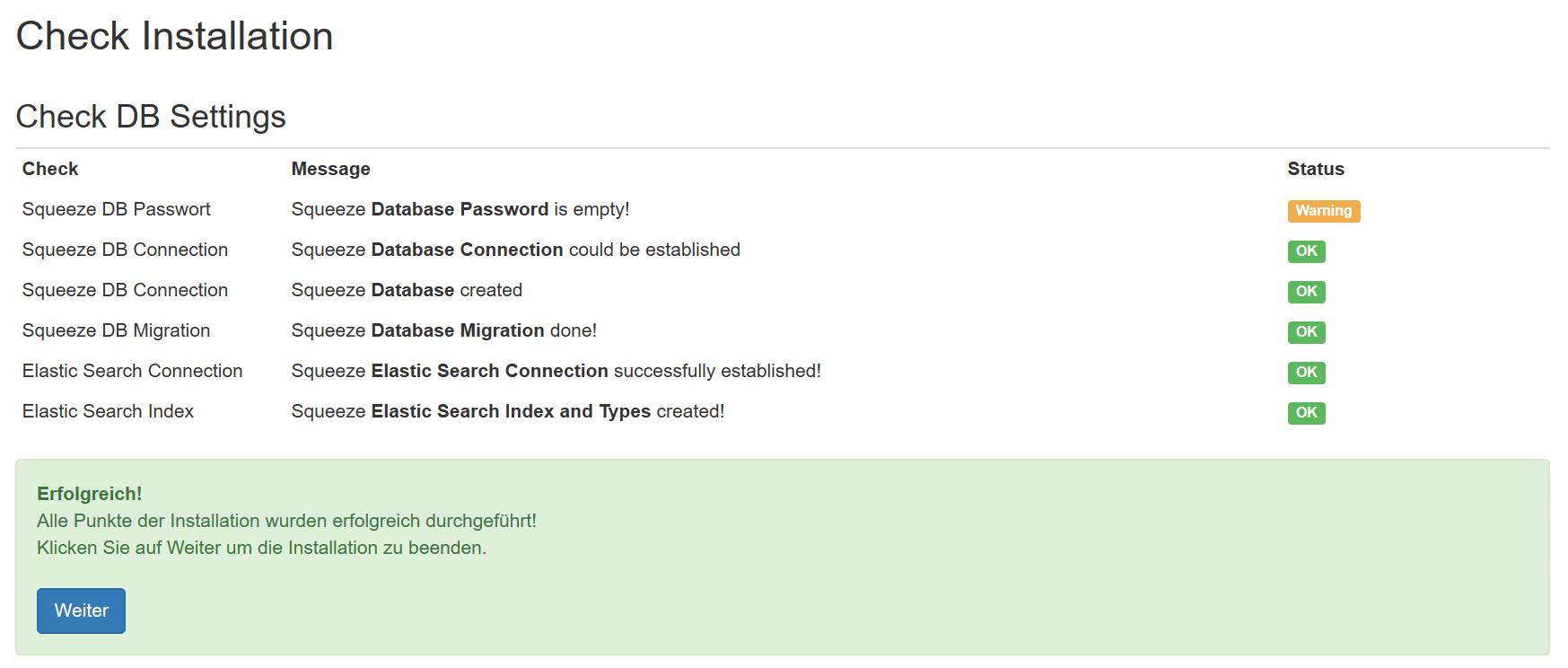
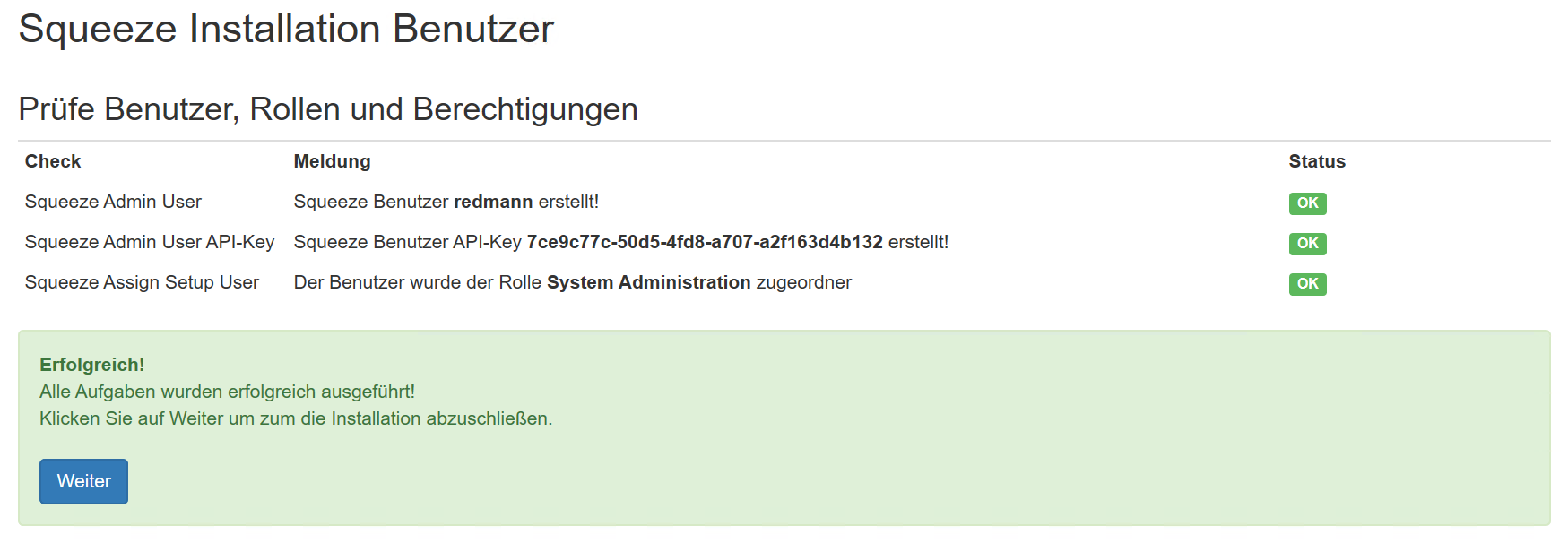
API-Key: 7ce9c77c-50d5-4fd8-a707-a2f163d4b132
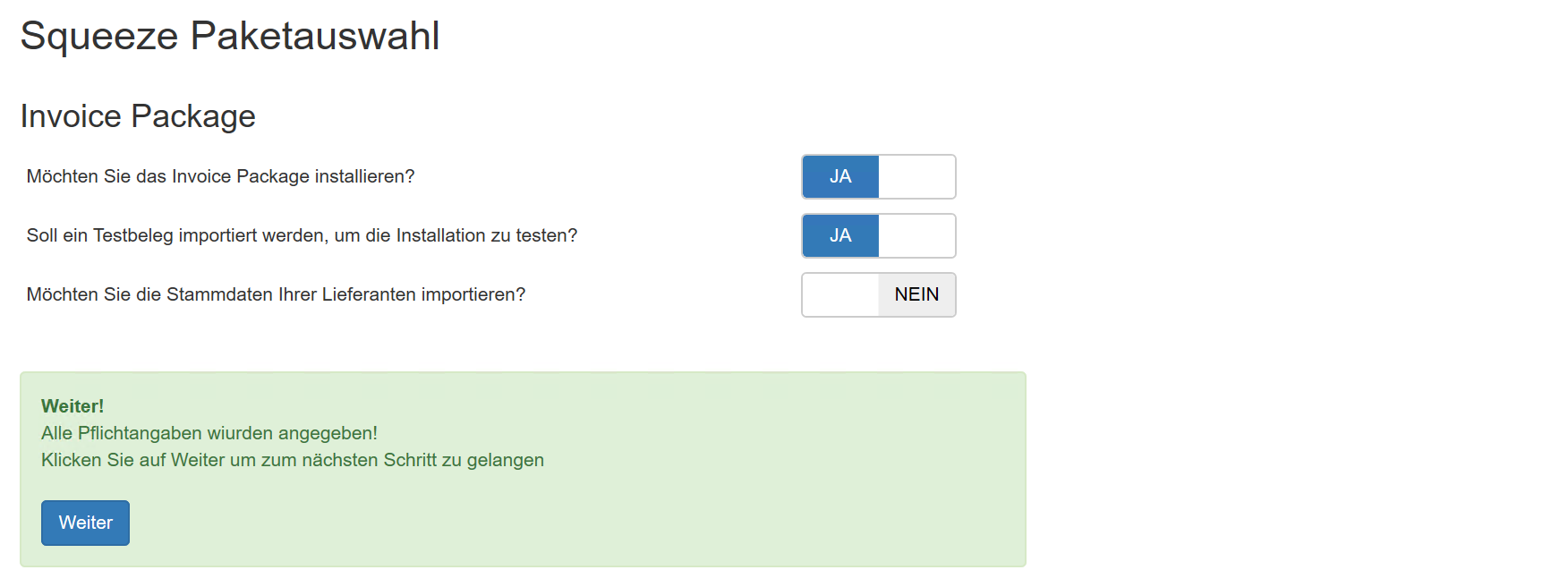
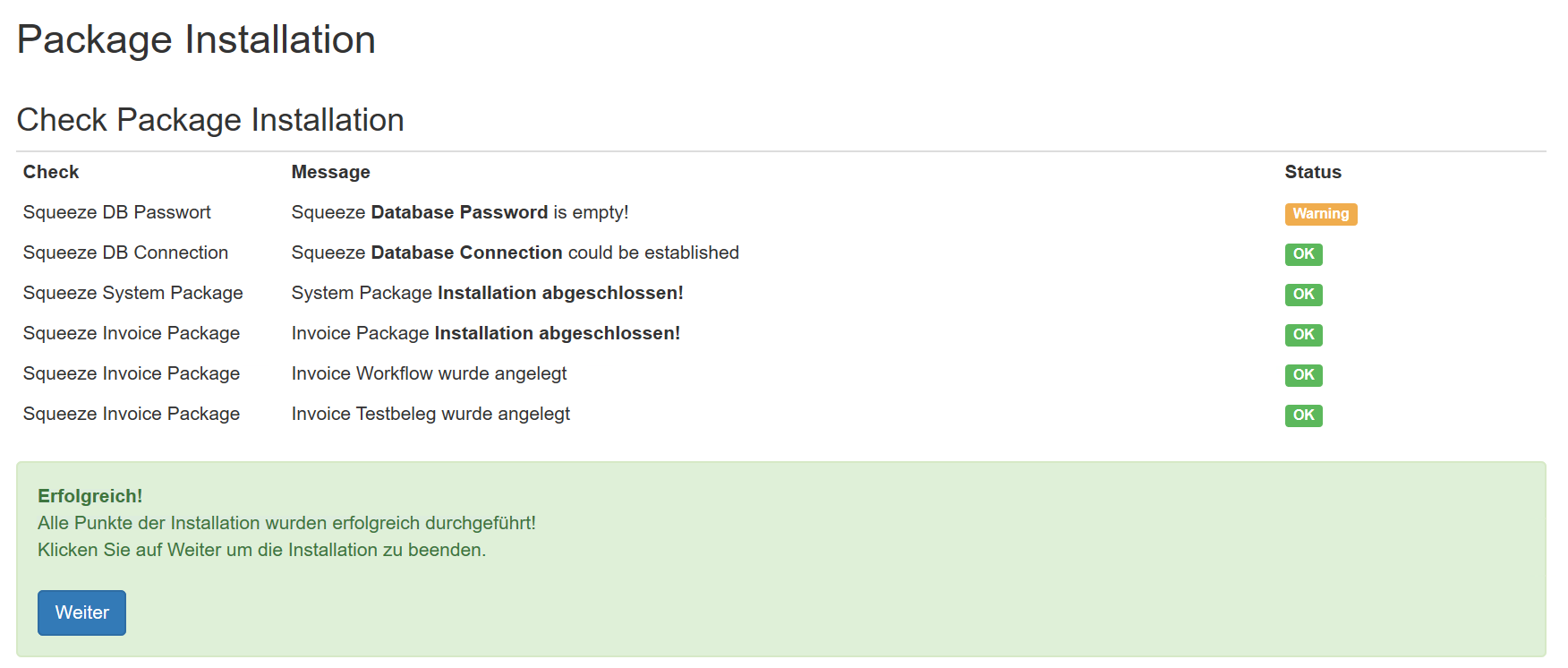
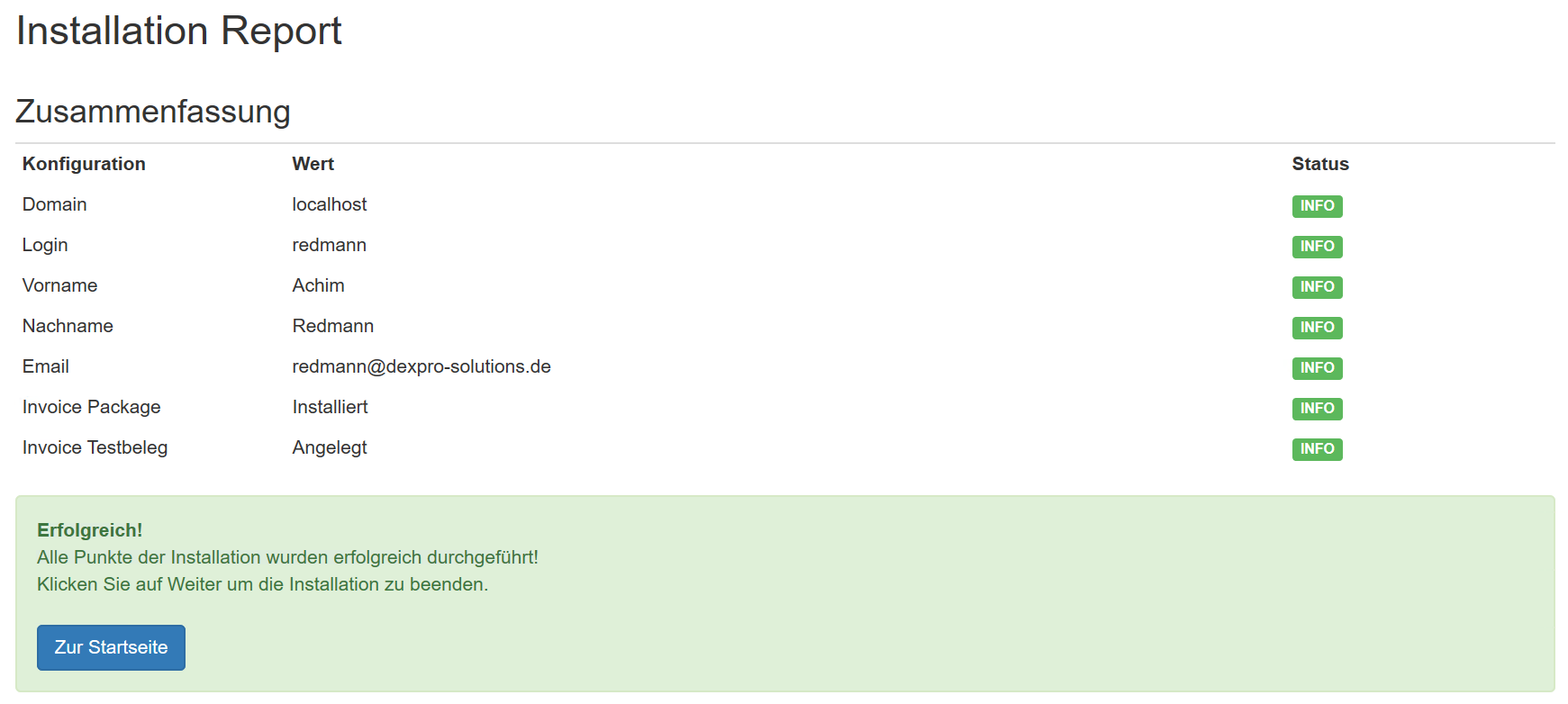
Konfiguration des Workers
C:\SQUEEZE\repository\config\worker\config
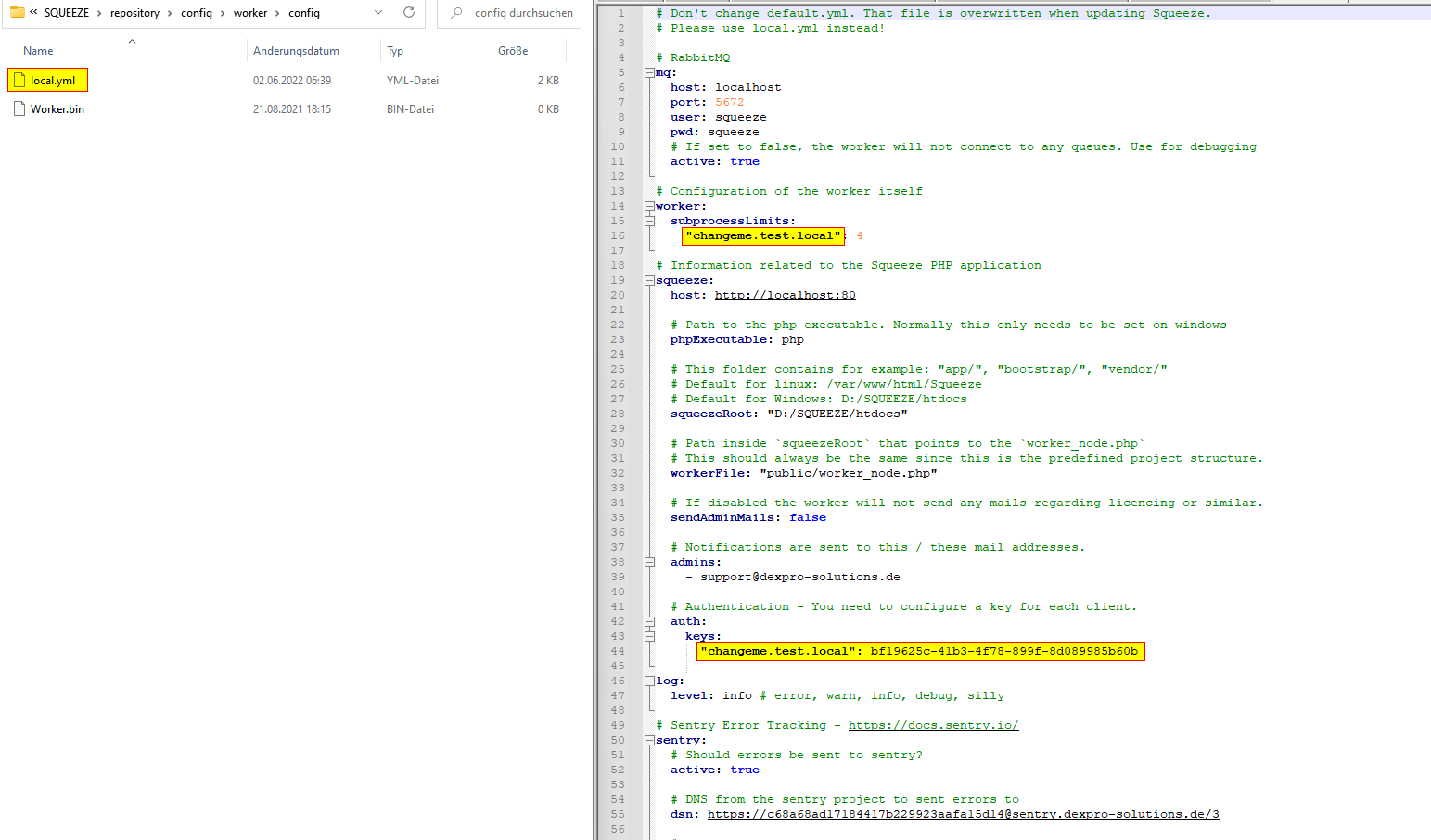
Die Angabe des Servernames (FQDN) für den API Key ist Case-Sensitiv
Wir empfehlen den Servernamen generell in Kleinbuchstaben zu schreiben.
Serverinstallation Linux
The following steps describe how to install on a Debian 10 server. Generally you can try to install on other Linux systems.
This may work if all Squeeze dependencies like the correct PHP version, PHP modules and Apache extensions are present in your operating systems package repositories.
Linux (Debian 10)
1. Prepare Debian for installation via apt
Before installing Squeeze some third party applications need to be installed. Follow the steps below to install these applications.
Please note that using a proxy to connect to the internet might need some additional configuration like:export https_proxy=https://proxy.intra.net:proxy_port
orexport http_proxy=http://user:password@proxy.intra.net:proxy_port
apt update
apt upgrade2. Install PHP 7.4
apt-get update
apt-get install php7.4 php7.4-cli php7.4-common php7.4-imap php7.4-mysql php7.4-mailparse php7.4-bcmath php7.4-intl php7.4-gd php7.4-xml php7.4-xsl php7.4-mbstring php7.4-opcache php7.4-curl php7.4-zip php7.4-bz2 php7.4-soap php7.4-json php7.4-imagick libapache2-mod-php7.43. Install Apache
To install Apache run the following command
apt install apache2And enable the following modules
a2enmod proxy rewrite deflate filter headers4. Install MariaDB
apt update
apt install mariadb-server
systemctl status mariadbrun the follwing command and follow the instructions to secure the installation:
mysql_secure_installationCreate a new user for later use
mysql --user=root mysqlCREATE USER 'squeeze'@'localhost' IDENTIFIED BY 'secret';
GRANT ALL PRIVILEGES ON *.* TO 'squeeze'@'localhost' WITH GRANT OPTION;
FLUSH PRIVILEGES;5. Install RabbitMQ
Run the following command to install RabbitMQ including the management web interface
apt-get install rabbitmq-server
rabbitmq-plugins enable rabbitmq_management
If needed add a new user to RabbitMQ
rabbitmqctl add_user username password
rabbitmqctl set_user_tags username administrator
rabbitmqctl set_permissions -p / username ".*" ".*" ".*"6. Install ElasticSearch
Run the following command to install ElasticSearch
nano /etc/apt/sources.list
deb http://ftp.us.debian.org/debian sid main
apt-get update
apt install openjdk-8-jre-headless
apt install gnupg2
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | apt-key add -
echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-5.x.list
apt update && apt upgrade
apt install apt-transport-https uuid-runtime pwgen
apt update
apt install elasticsearch
cd /usr/share/elasticsearch/bin
./elasticsearch-plugin install analysis-icu
./elasticsearch-plugin install mapper-attachments
To be able to install the plugins behind a proxy please use the following commands:
ES_JAVA_OPTS="-Dhttp.proxyHost=proxy.intra.net -Dhttp.proxyPort=3128 -Dhttps.proxyHost=proxy.intra.net -Dhttps.proxyPort=3128" ./elasticsearch-plugin install analysis-icu
ES_JAVA_OPTS="-Dhttp.proxyHost=proxy.intra.net -Dhttp.proxyPort=3128 -Dhttps.proxyHost=proxy.intra.net -Dhttps.proxyPort=3128" ./elasticsearch-plugin install mapper-attachmentsOptional:
nano /etc/elasticsearch/elasticsearch.yml
cluster.name: my-applicationnano
/etc/elasticsearch/jvm.options
-Xms512m
-Xmx512mEnable and start ElasticSearch
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl restart elasticsearch.service
systemctl status elasticsearch.serviceapt install tesseract-ocr tesseract-ocr-deu imagemagick ghostscript poppler-utils zbar-tools git sudo8. Install Squeeze
cd /var/www/html
git clone https://git.dexpro-solutions.de/dex/squeeze/Squeeze.git
chown -R www-data Squeeze/
chmod -R 775 Squeeze/nano /etc/apache2/sites-enabled/000-default.conf
DocumentRoot /var/www/html/Squeeze/public
<Directory "/var/www/html/Squeeze/public">
AllowOverride All
</Directory>Now restart the apache webserver:
systemctl restart apache29. Web installer
Once the installer finished, start your preferred browser and open http://localhost to run the web installer
Serverupdate Windows
Das Update-Package enthält zumeist (nur) ein neues htdocs Verzeichnis
- SQUEEZE Dienste beenden
- htdocs Verzeichnis sichern
- neues htdocs Verzeichnis im SQUEEZE Verzeichnis entpacken
- Im Worker-Verzeichnis muss die umzug.json enthalten sein, diese ggf. aus dem gesicherten htdocs Verzeichnis kopieren
- SQUEEZE Dienste wieder starten
- Im Swagger mit der API "migrateDatabase" eine Migration durchführen
- Jobs und andere projektspezifische Anpassungen im htdocs Verzeichnis bei Bedarf prüfen/wiederherstellen

Stapelklassen
Stapelklassen
Stapelklassen erfüllen in Squeeze mehrere Funktionen.
1. Stapelklassen für Klassifizierung
In einer Stapelklasse können mehrere Dokumentenklassen für die Klassifizierung zusammengefasst werden.
2. Stapelklassen für Eingangskanal (Email)
Innerhalb der Konfiguration einer Stapelklasse kann der Eingangskanal Emailabruf konfiguriert werden.
Stapelklassen anlegen
Nach der Anmeldung in Squeeze können Benutzer mit administrativen Berechtigungen die Konfiguration für Stapelklassen aufrufen.
Liste der Stapelklassen
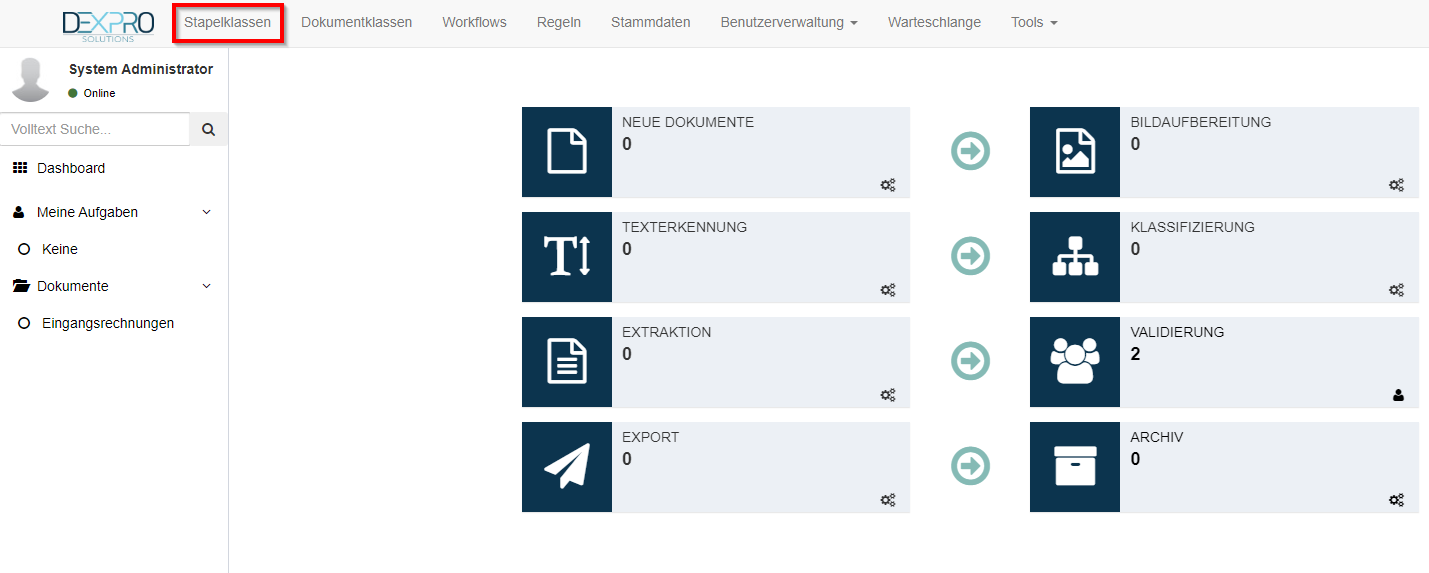
Nach dem Klick auf den Reiter Stapelklassen öffnet sich die Stapelklassenübersicht. Hier werden alle aktuell konfigurierten Stapelklassen angezeigt. Die Stapelklasse Invoice wird zusammen mit dem Invoice Template ausgeliefert.
In der Liste der Stapelklassen kann man die Konfiguration mit einem Doppelklick auf den Eintrag öffnen.
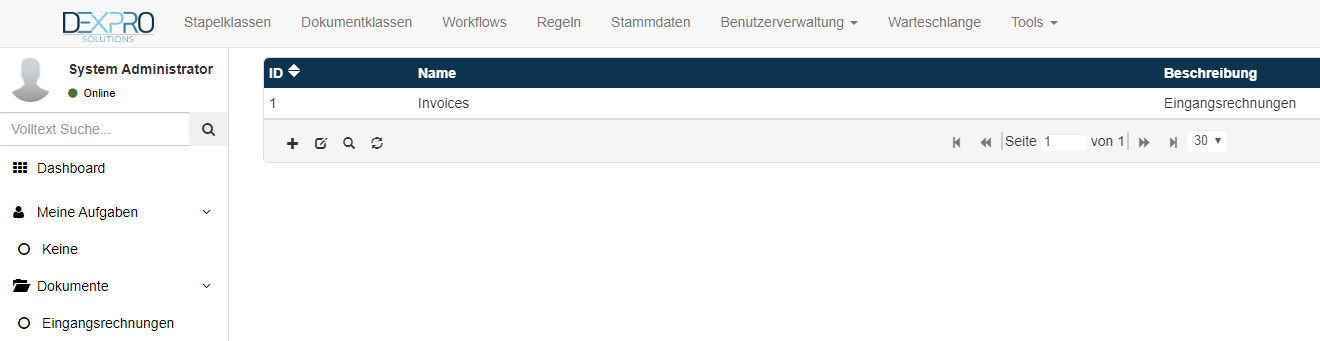
Neue Stapelklasse anlegen
Neue Stapelklassen können mithilfe des + Symbols angelegt werden. Daraufhin öffnet sich ein Dialog wo der technische Namen und der Anzeigenamen eingegeben werden kann.
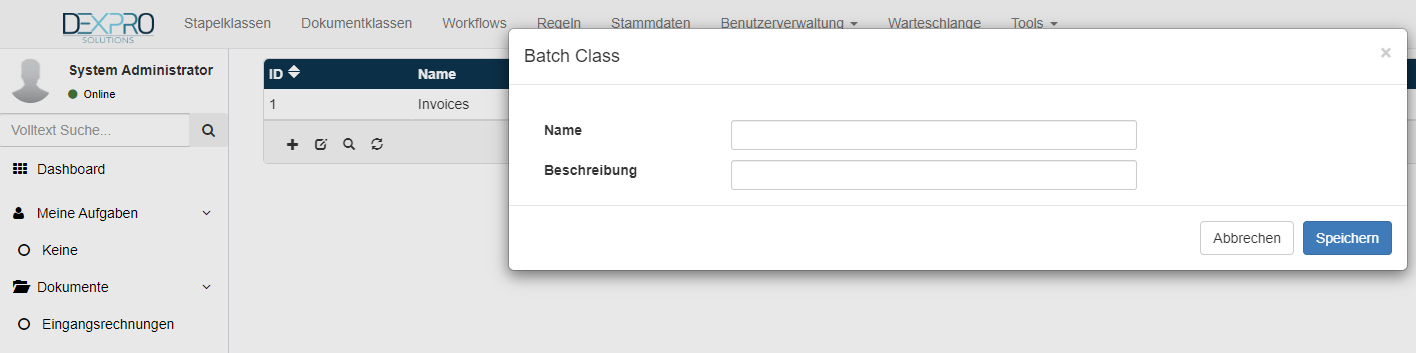
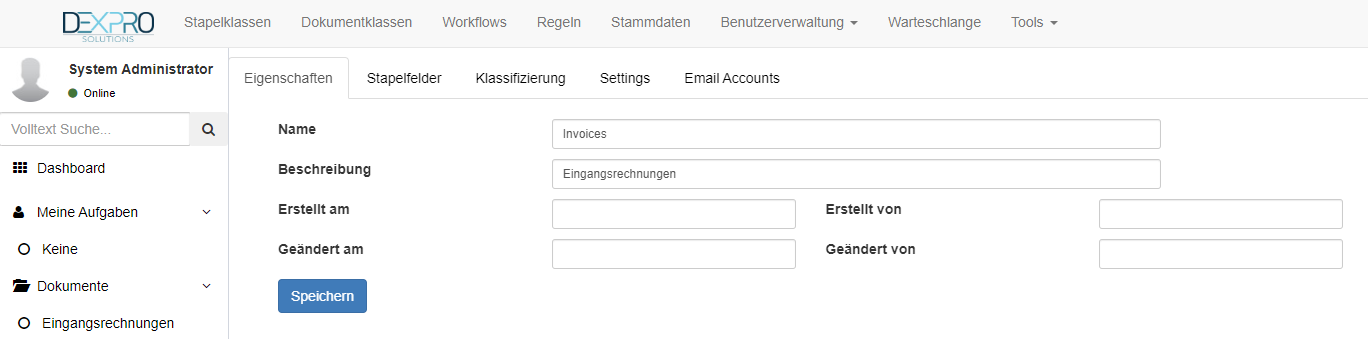
Ab hier können folgende Konfiguration durchgeführt werden:
- Stapelfelder
- Klassifizierung
- Settings
- Email Accounts
Stapelklassen Email-Konfiguration
Je Stapelklasse ist es möglich 1-n Emailkonten zu konfigurieren, um Emails automatisiert aus den konfigurierten Postfächern abzurufen und die angehängten Dokumente (derzeit nur PDFs) zu verarbeiten.
Es werden zwei Verfahren unterstützt, um Emails aus den Postfächern abzuholen.
- Abruf via EWS (Exchange Web Services)
- Abruf via IMAP (Internet Message Access Protocol)
EWS ist bei aktivierter Microsoft Exchange Server extended protection nicht mehr verwendbar. In diesem Fall muss auf IMAP umgestellt werden.
EWS BasicAuth
Die BasicAuth für die Exchange Web Services wird im Oktober 2022 abgeschaltet. Aktuell ist jedoch nur diese zur Nutzung freigegeben. Um zu prüfen, ob die BasicAuth für ein System noch verfügbar ist, kann die folgende URL (ggf. Server durch den eigenen Exchange Server ersetzen) genutzt werden:
https://outlook.office365.com/EWS/Exchange.asmxNach dem Aufruf dieser URL erscheint ein Dialog zur Eingabe des Benutzernamens und des Passworts.
Sofern diese Anmeldung erfolgreich ist und eine entsprechende Webseite angezeigt wird, ist BasicAuth verfügbar.
EWS Verbindungstest
Im Falle einer EWS Verbindung kann es hilfreich sein vorab einen Verbindungstest durchzuführen. Das gilt besonders dann, wenn es sich um einen eignen Exchange Server handelt. Der Verbindungstest kann mit der folgenden Seite durchgeführt werden:
https://testconnectivity.microsoft.com/tests/EwsTask/inputAuf der Seite müssen die Verbindungsdaten angegeben werden, die getestet werden sollen:
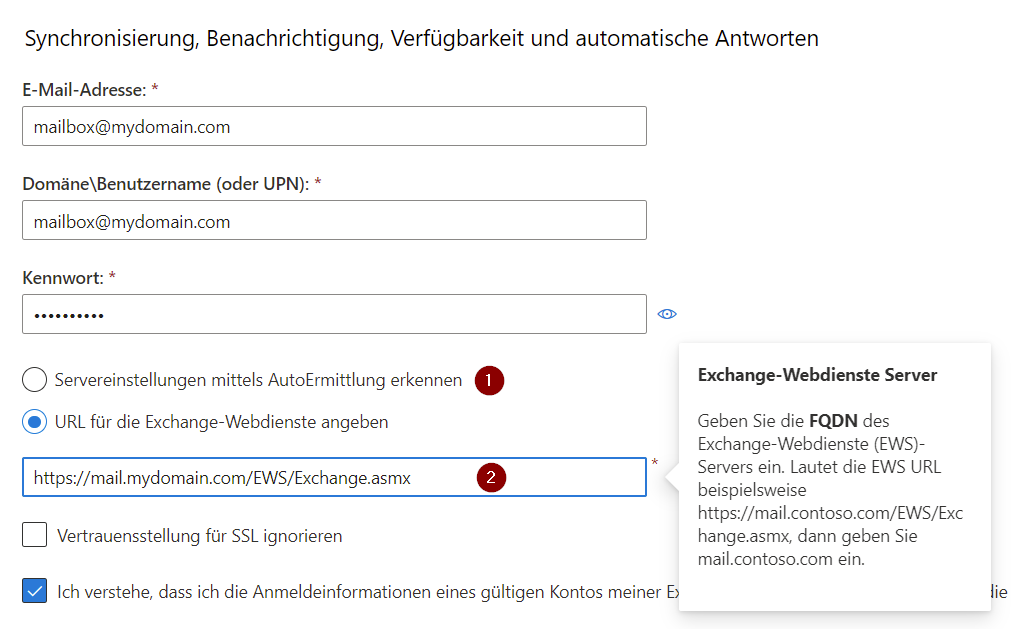
Sofern ein AutoDiscover für den Exchange Server eingerichtet wurde kann die Option (1) genutzt werden.
Sollte es sich um einen eignen Exchange Server handeln für den kein AutoDiscover eingerichtet ist, dann muss die EWS Adresse manuell angegeben werden (2).
Auflistung der Konten
Eine Liste der konfigurierten Konten kann über Reiter Emailkonten der Stapelklasse geöffnet werden.
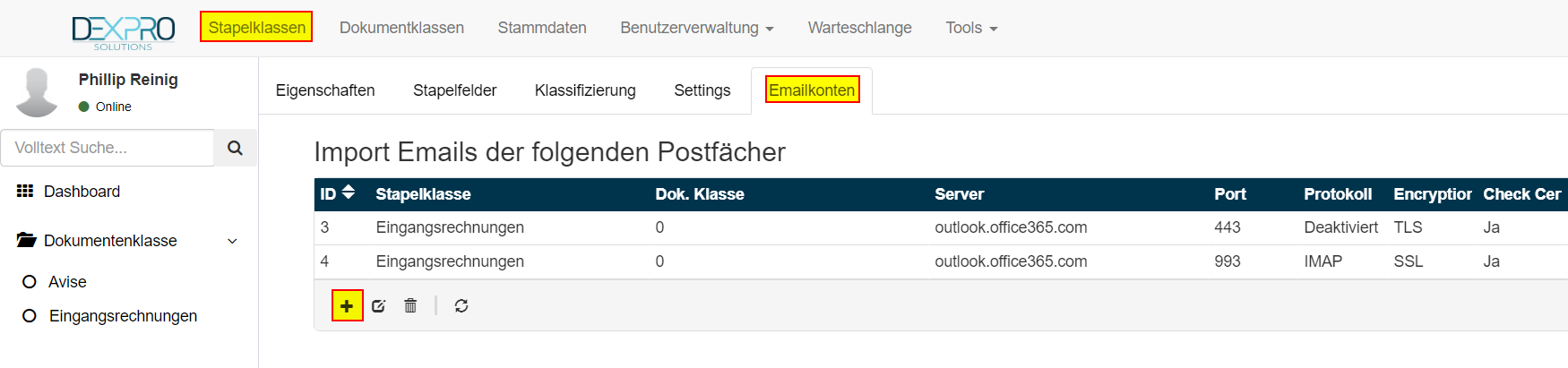
In dieser Bildschirmkopie ist zu sehen, dass zwei Konten definiert sind, die abgerufen werden sollen.
In der Spalte Protokoll kann das Verfahren für den Import festgelegt werden (EWS, IMAP oder Deaktiviert).
Über das ![]() Symbol in der unteren Leiste können weitere Konten definiert werden.
Symbol in der unteren Leiste können weitere Konten definiert werden.
Über das ![]()
Neues Konto definieren
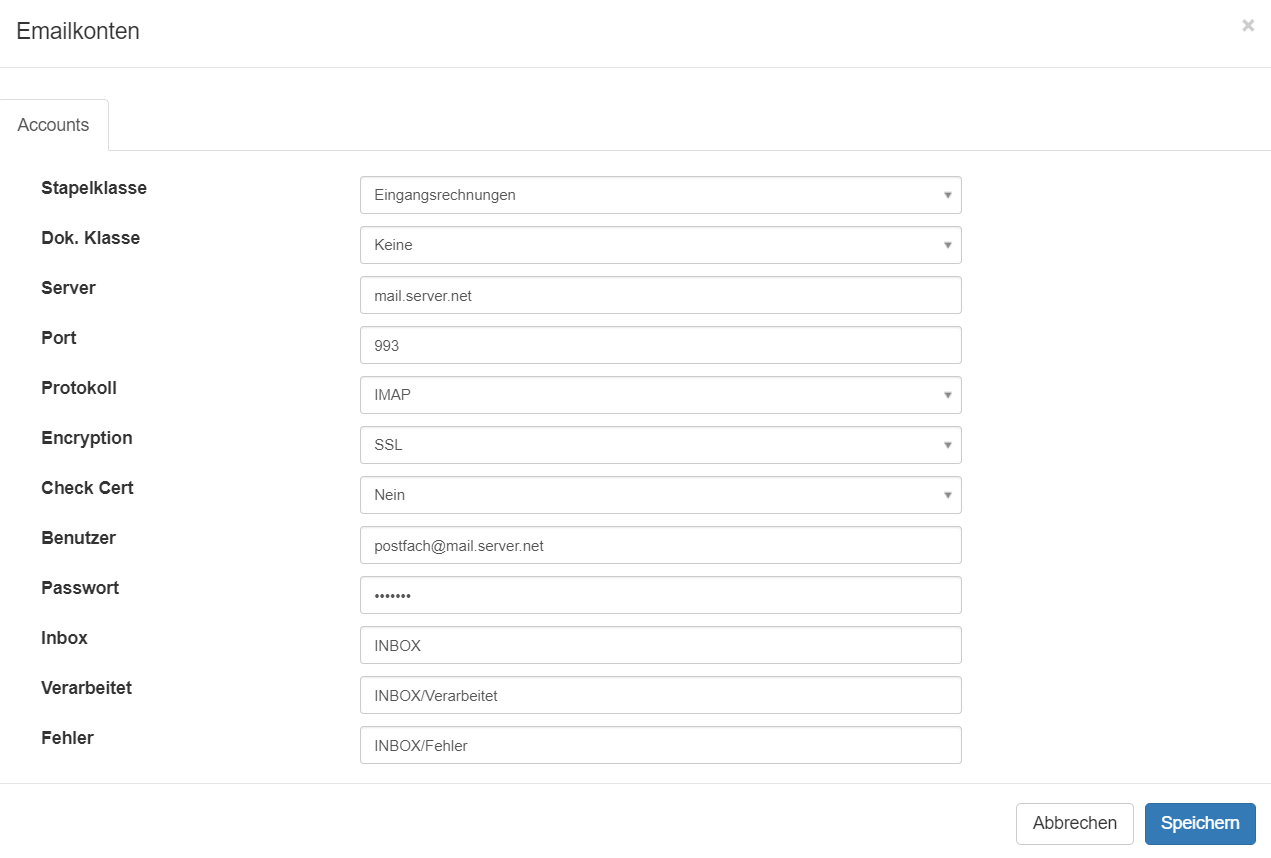
Shared Mailboxes abfragen
Um mit einem Benutzer Zugriff auf ein Postfach zu erhalten, um damit Emails einer anderen shared mailbox abzurufen im Feld "Benutzer" zuerst den Zugriffsbenutzer eintragen und danach den shared mailbox Benutzer getrennt durch "/":
Beispiel: benutzername@domain.de/shared-benutzername@domain.de
Beispiel mit NTLM Anmeldung: local.domain.net\benutzername/mailbox@domain.de
Hinweis: Bei Verwendung von EWS müssen der "Valid" & "Error" Ordner auf oberster Ebene sein. Unterordner von z.B. "Posteingang" können nicht verwendet werden.
Task einrichten
Damit die Emails automatisiert abgeholt werden, muss ein Task eingerichtet werden.
Hier der Link zur Einrichtung des Jobs: Email-Verarbeitung
Übertragen von Standard Email Feldern
Sofern beim Email Import Standard Email Felder wie Absender, Empfänger, Email Betreff ausgelesen werden sollen müssen die entsprechenden folgenden Felder technisch an jeder Dokumenten Klasse vorhanden sein:
- EmailReceivedDate
- EmailFromAddress
- EmailFromName
- EmailToAddress
- EmailCcAddress
- EmailSubject
- EmailMessageId
- EmailImportFolder
- EmailProcessedFolder
- EmailInvalidFolder
- EmailMailBoxUser
- EmailPriority
Dokumentenklassen
Dokumentenklassen
Dokumentenklassen beschreiben jeweils einen spezifischen Dokumententyp.
Innerhalb einer Dokumentenklasse können für den jeweiligen Dokumententyp, spezifische Konfigurationen angelegt werden:
1. Gruppen (auf getrennten Reitern befindliche Feldgruppen)
- Kopfdaten
- Positionen
- ...
2. Felder (für diesen Dokumententyp spezifische Dokumentenfelder)
- Lieferanten-ID
- Lieferanten-Name
- Bestellnummer
- ...
3. Lokatoren (Suchmerkmale zum Befüllen der jeweiligen Felder)
- reguläre Ausdrücke
- Datenbank-Link,
- Key-Value
- ...
4. Export (Schnittstellenkonfiguration für diese Dokumentenklasse)
- Documents Soap
- XML-Datei
- Webservice
- ...
Anlegen einer Dokumentenklasse
Dokumentenklassen können mit einem Klick auf den Reiter Dokumentenklassen konfiguriert werden
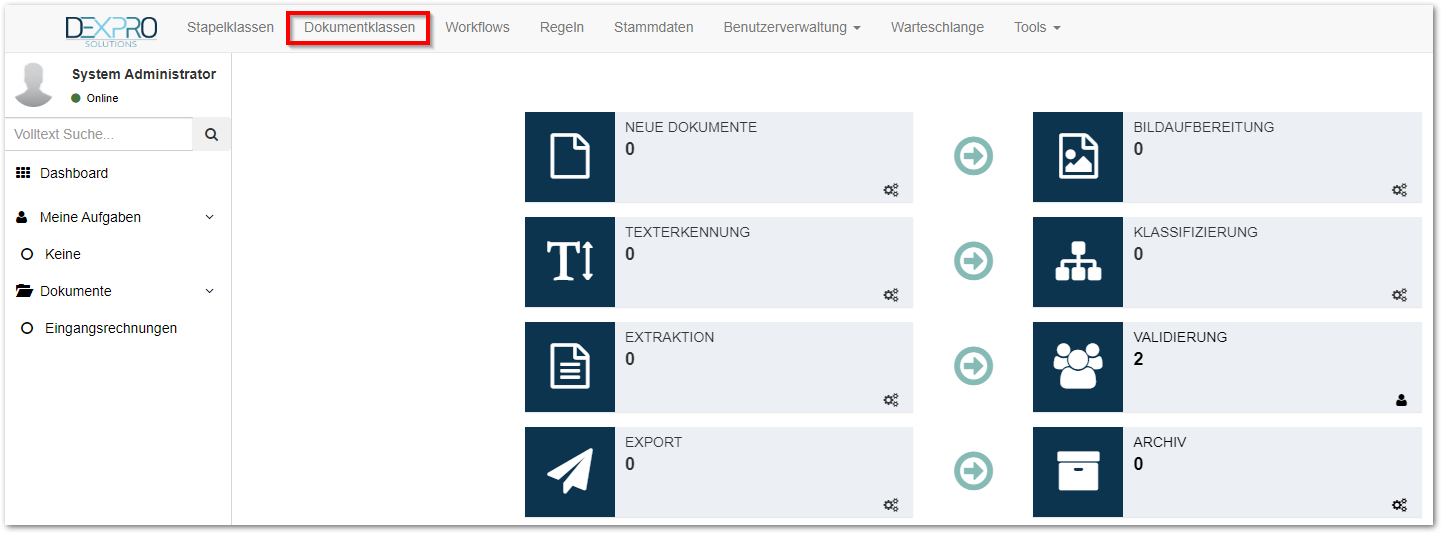
Die Invoice Dokumentenklasse wird mit dem Invoice Template ausgeliefert
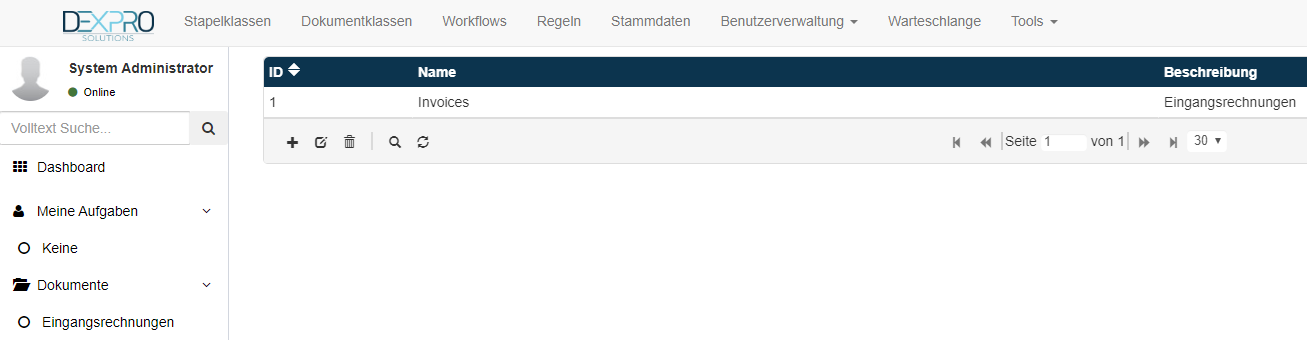
Mit dem + Symbol können neuen Dokumentenklassen angelegt werden. Hier wird der technische Name und die Beschreibung der Dokumentenklasse gefüllt.
Mit einem Doppelklick auf den Eintrag in der Liste öffnet sich der Konfigurationsdialog für die Dokumentenklasse.
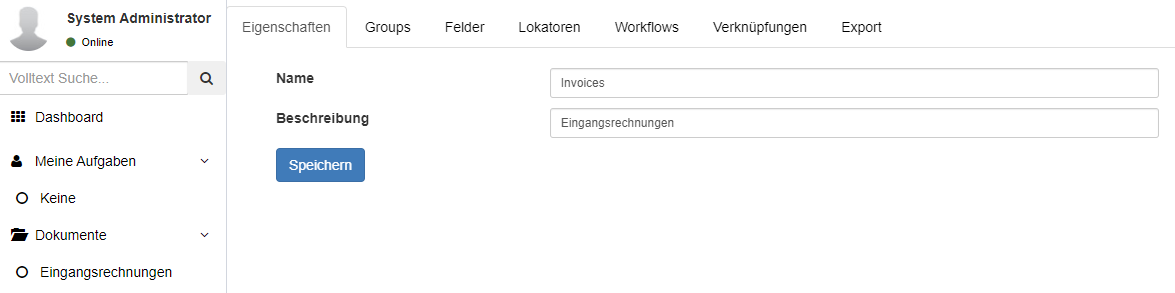
Die Konfiguration der Reiter für unterschiedliche Feldgruppen kann mit einem Klick auf Groups geöffnet werden.
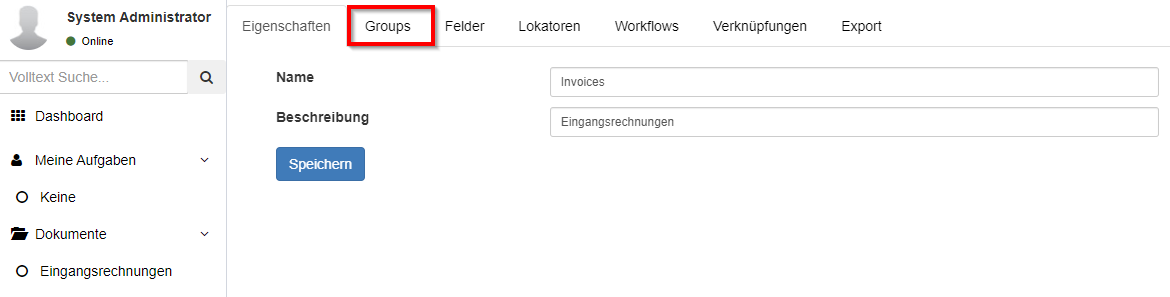
Hier wird eine Liste aller bereits angelegten Gruppen angezeigt.

Neue Gruppen können mit dem + Symbol hinzugefügt werden.
Bereits bestehende Gruppen können per Doppelklick auf den Eintrag in der Liste konfiguriert werden.
Dokumentenfelder
Dokumentenfelder
Dokumentenfelder werden in Squeeze für unterschiedliche Funktionen benötigt:
- Informationen aus der Extraktion aufnehmen
- Informationen aus der Extraktion im Webclient von Squeeze darstellen
- Informationen aus der Extraktion für die Weiterverarbeitung in den Exportschnittstellen bereitstellen
In Squeeze werden verschiedene Arten von Dokumentenfeldtypen bereitgestellt:
| Feld-Typ | Bedeutung |
| Text | Textfeld |
| Date | Datumsfeld |
| Amount | Betragsfeld (numerisch, 2 Nachkommastellen |
| Table | Tabellenfeld |
Es gibt verschiedene Feldeigenschaften die für die Dokumentenfelder konfiguriert werden können:
| Feld-Eigenschaft | Bedeutung |
| Pflichtfeld | leere Felder werden im Webclient rot dargestellt, die Validierung ist nicht möglich solange das Feld nicht gefüllt ist |
| Nur Lesen | Im Webclient kann das Feld nicht bearbeitet werden, Lokatoren können das Feld im Hintergrund füllen |
| Versteckt | das Feld wird im Webclient nicht dargestellt |
| Bestätigen | das Feld wird im Webclient blau dargestellt und muss vor der Validierung mit Enter bestätigt werden |
Weitere Feldkonfigurationen:
| Feld-Konfiguration | Bedeutung |
| Name | technischer Feldname |
| Beschreibung | Anzeigenamen des Feldes |
| Lokator | Auswahlfeld für bereits konfigurierte Lokatoren, die dem Feld zugewiesen werden können |
| Subfield | relevant für die Endbeträge bei Eingangsrechnungen (NetAmount, TaxAmount, TotalAmount, TaxRate) |
| Gruppe | Auswahlfeld mit den Gruppen dieser Dokumentenklasse (Feldgruppen -> Groups) |
| Name im Zielsystem | technischer Name für die Exportschnittstelle für dieses Feld |
Dokumentenfelder anlegen / konfigurieren
Innerhalb der Konfiguration für eine Dokumentenklasse können Felder mit einen Klick auf den Reiter Felder angelegt werden.
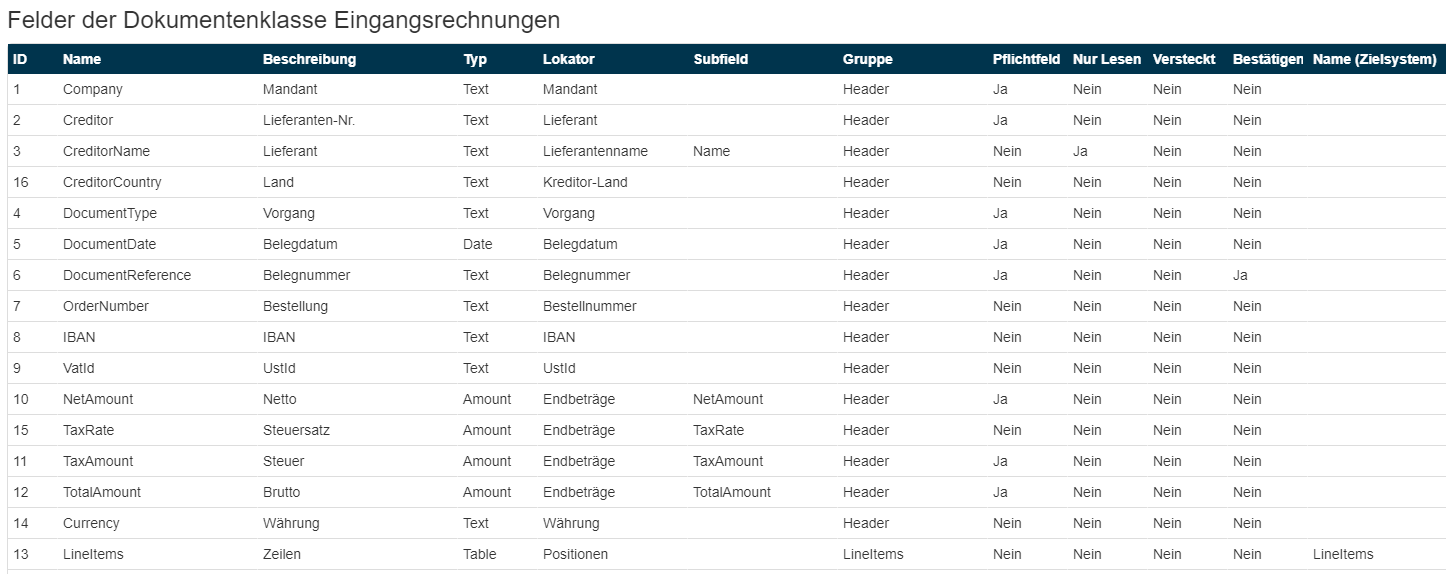
In diesem Dialog sind alle bereits für diese Dokumentenklasse angelegten Felder zu sehen.
Beispiel für die Dokumentenklasse Eingangsrechnungen.
Mit einem Doppelklick auf einen Eintrag in der Liste öffnet sich der Konfigurationsdialoag für das betreffende Feld.
Beispiel für das Feld Creditor:
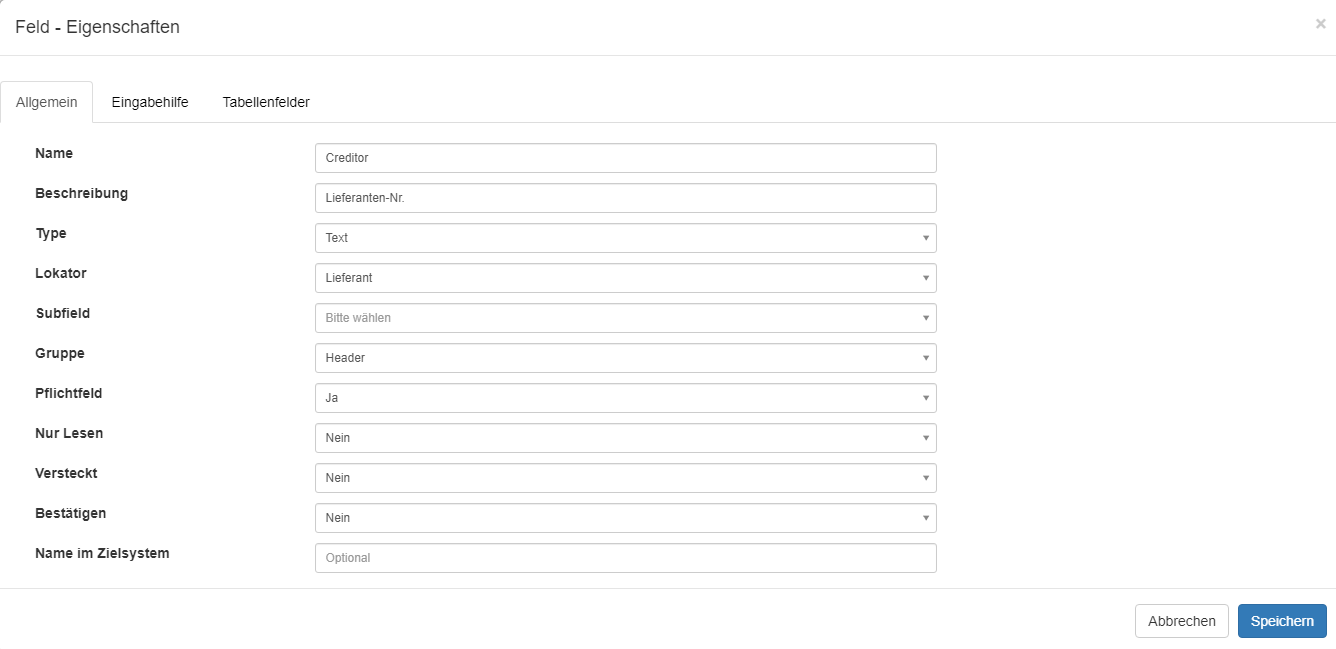
Mit dem+ Symbol in der unteren Leiste können neue Felder angelegt werden.
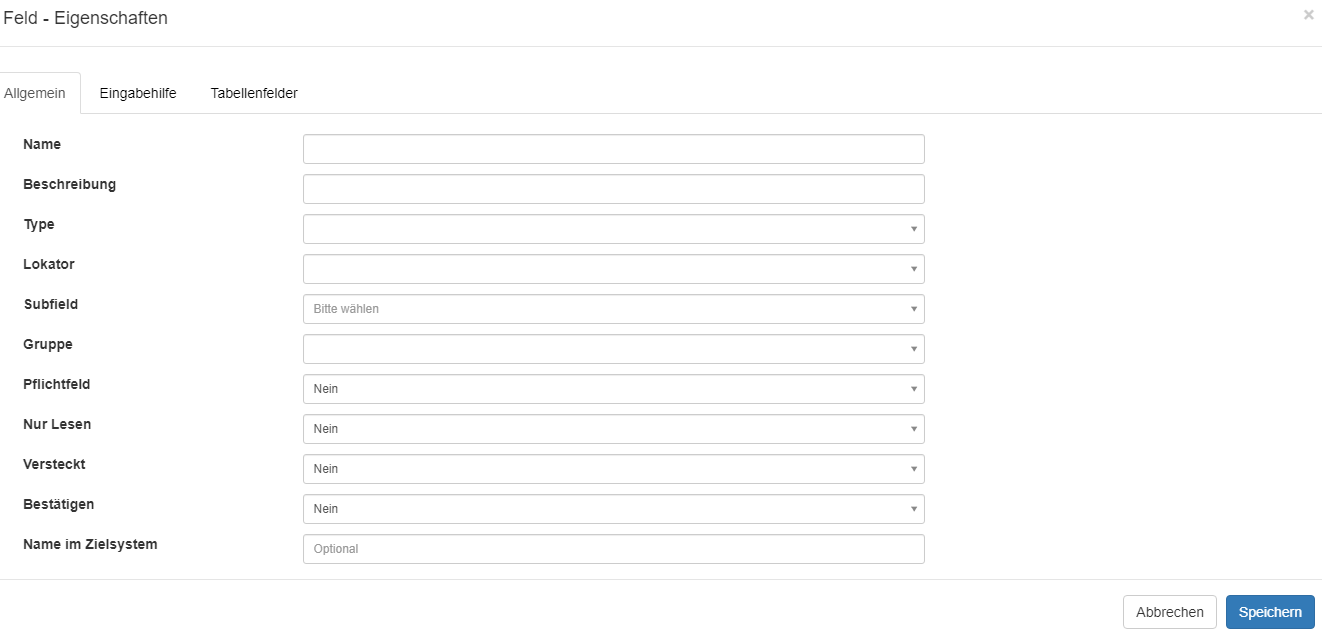
Neu angelegte Felder sind im Webclient nach Aktualisierung der Webseite (F5) sofort zu sehen.
Die Reihenfolge der dargestellten Felder im Webclient lässt sich in der Feldliste per Drag & Drop einfach ändern.
Lokatoren
Lokatoren
Lokatoren sind in Squeeze Werkzeuge mit deren Hilfe Textinformationen aus Dokumenten ermittelt werden.
Lokatoren können in Squeeze Feldern zugewiesen werden, in diesem Fall wird das Lokatorergebnis in das jeweilige Dokumentenfeld übernommen.
In Squeeze sind verschiedene Lokatorentypen verfügbar:
| Lokatortyp | Bedeutung |
| Regular Expression | Lokator für reguläre Ausdrücke |
| KeyWord | Lokator für Schlüsselbegriffe |
| Invoice Amounts | Lokator für Endbeträge und Steuersatz einer Rechnung (Nettobetrag, Bruttobetrag, Steuerbetrag und Steuersatz) |
| Document Date | Lokator für Datumsangaben |
| Keyword to Value | Lokator für Werte (reguläre Ausdrücke) die auf einen Schlüsselbegriff umgesetzt werden |
| Value next to Keyword | Lokator für Werte (reguläre Ausdrücke) die in der Nähe eines bestimmten Schlüsselbegriffes |
| Search for line items | Lokator für die Positionszeilenfindung |
| Search for DB linked data | Lokator für Datenbanksuche (andere Lokatoren können als Source-Lokator angegeben werden) |
| Barcode | Lokator für Barcodeerkennung |
| Value from Regular Expression | Datenbanklokator für reguläre Ausdrücke (regex, result) |
Lokatoreigenschaften:
| Eigenschaft | Bedeutung |
| Name | technischer Lokatorname |
| Beschreibung | Anzeigenamen für den Lokator |
| Lokator Typ | Auswahlfeld für Lokatortypen |
| Wert | Auswahlfeld für Lokatorwerte (Text, Date, Amount) |
| Seiten | Auswahlfeld für welche Seiten des Dokumentes der Lokator ausgeführt werden soll (Jede Seite, Erste Seite, Letzte Seite) |
| ggf. Quelle | Auswahlfeld für Lokatoren, deren Ergebnismenge für diesen Lokator genutzt werden soll |
| Aktiv | Auswahlfeld für die Aktivierung des Lokators (ja, nein) |
| ignoriere Leerzeichen | das Suchmuster des Lokators ignoriert Leerzeichen |
Wichtig: Lokatoren können Ihr Suchmuster nur pro Textzeile finden, es gibt keine Möglichkeit mit Zeilenumbrüchen zu arbeiten.
Mit dem Squeeze Invoice Template werden bereits verschiedene Lokatoren ausgeliefert:
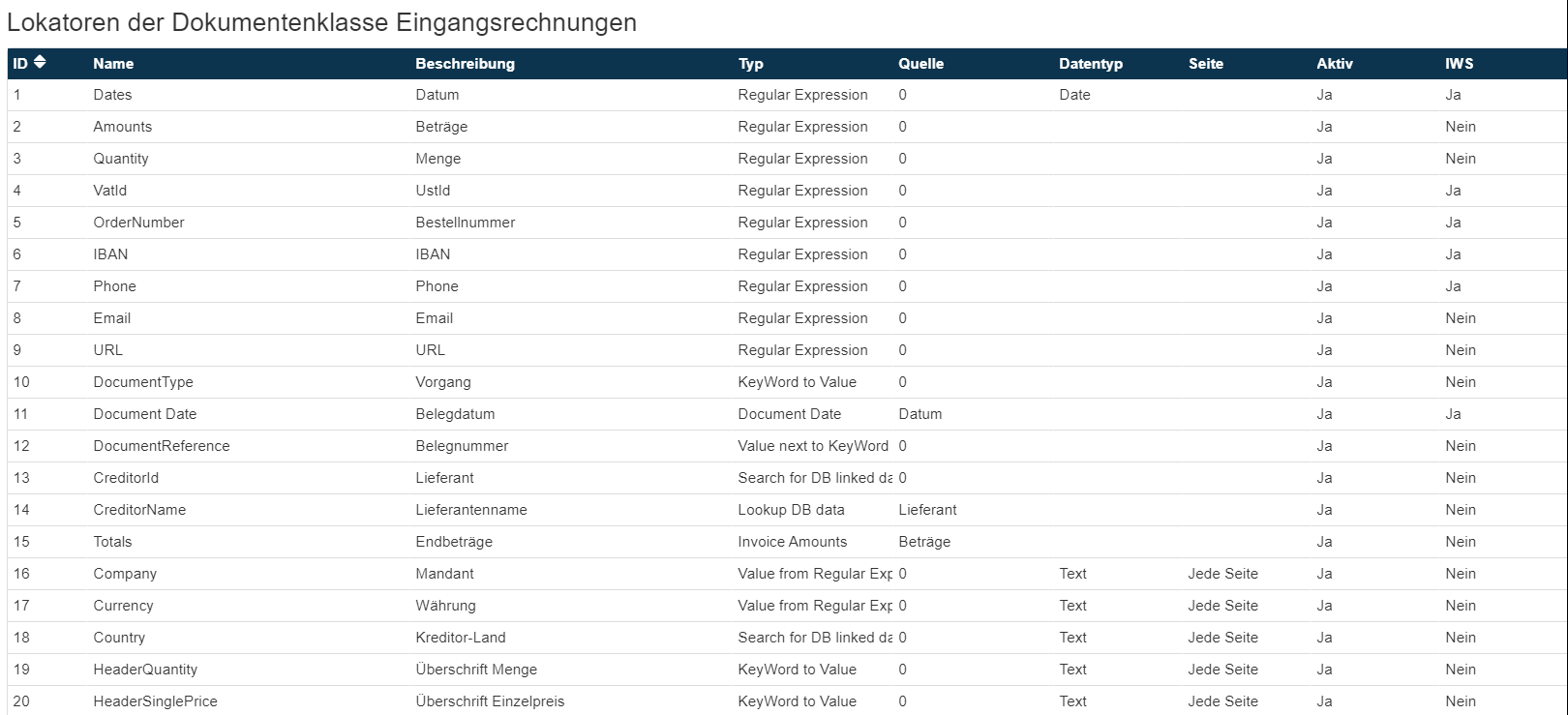
Wichtig: Diese Lokatoren können in jeder anderen Dokumentenklasse genutzt werden.
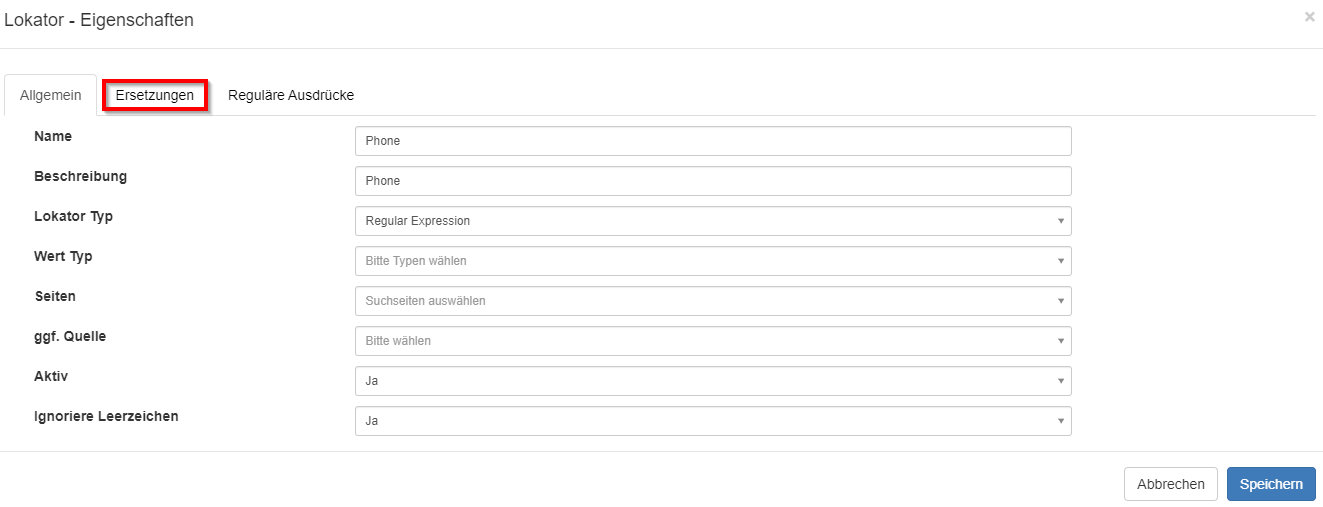
Für jeden Lokator können entsprechende Ersetzungen konfiguriert werden:
Beispiele für Ersetzungen im Phone (Telefonnummer) - Lokator:
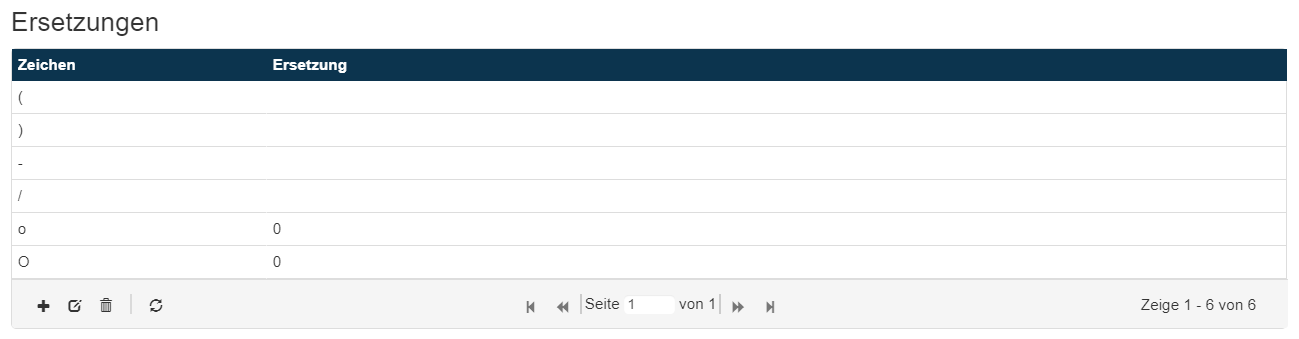
Wichtig: Ersetzungen können immer nur für die Ersetzung eines Zeichens durch ein oder kein Zeichen konfiguriert werden.
Testmodus für Lokatoren
Lokatoren können mit Squeeze auf Dokumenten getestet werden. Der Squeeze - Webclient kann dafür in den "Test-Modus" umgeschaltet werden. Einfach hinter die bestehende URL im Browser folgenden Text einfügen: &debug=1.
Diese Einstellung wird für Administratoren im Squeeze-Webclient in der aktuellen Browser-Session gespeichert. Nach der Umstellung auf den Testmodus stehen dem Benutzer während der Validierung von Dokumenten weitere Reiter zur Verfügung:
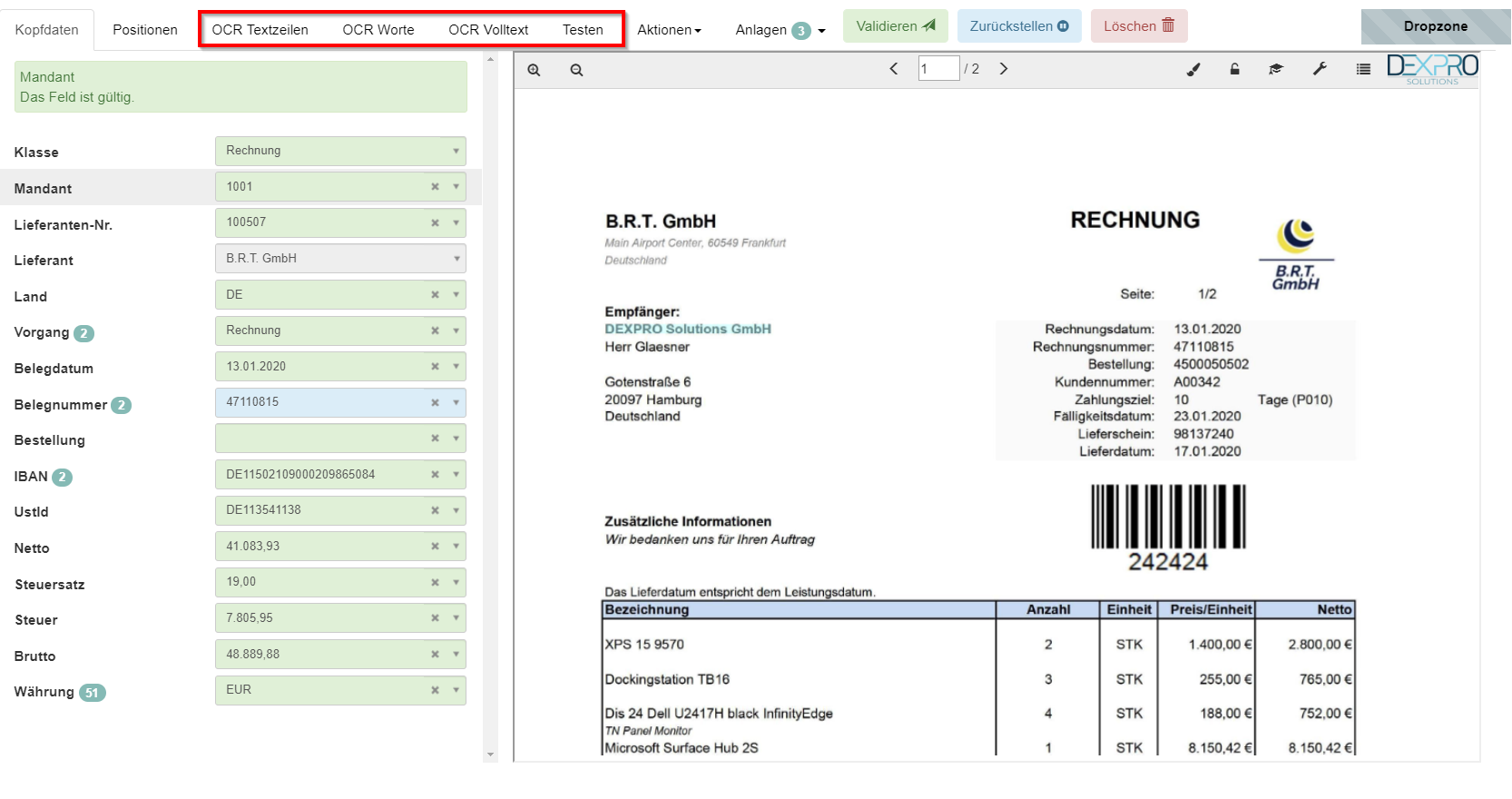
Mit einem Klick auf den Reiter Testen öffnet sich der Testmodus.
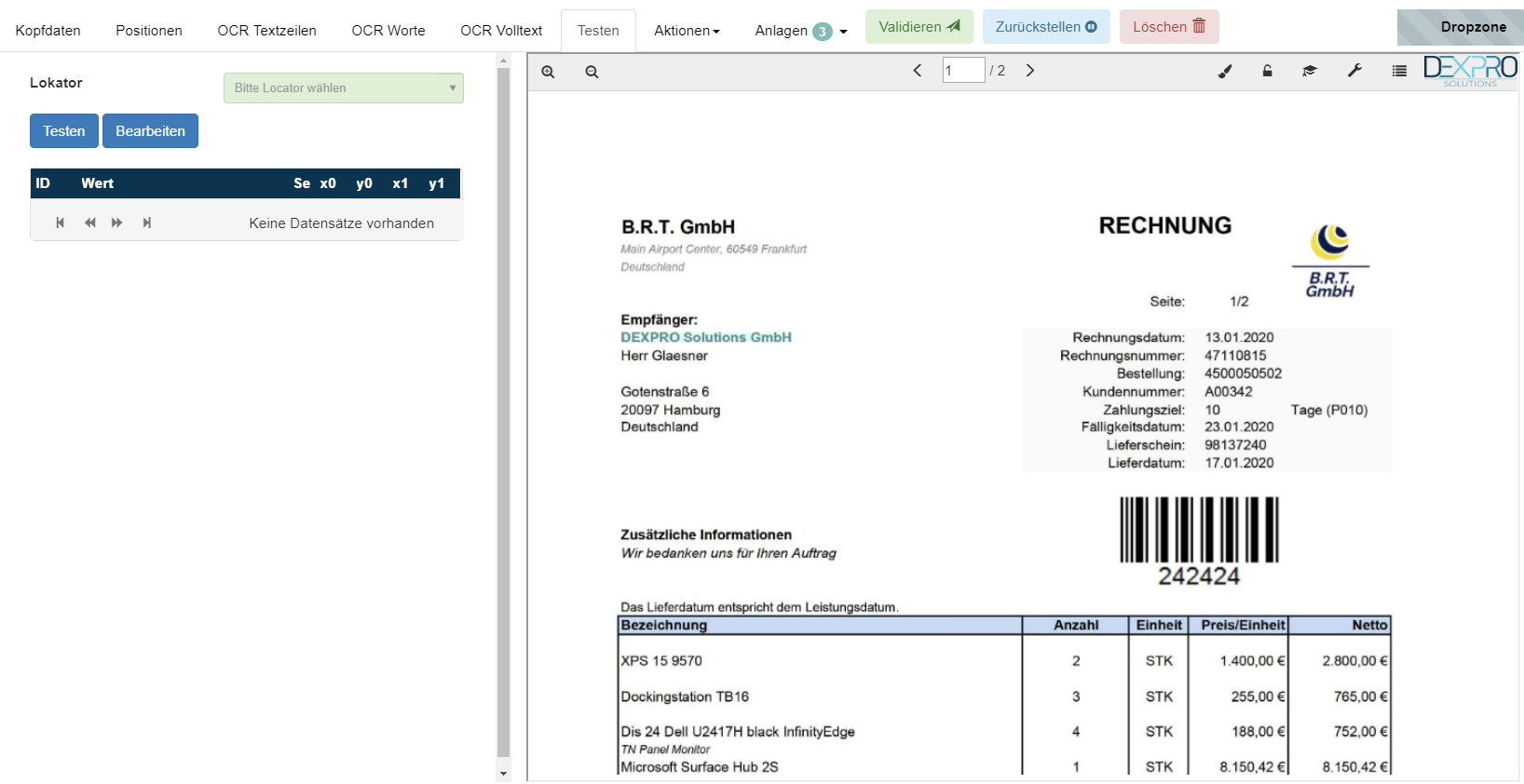
In dem grünen Auswahlfenster kann der Lokator den der Benutzer testen möchte ausgewählt werden:
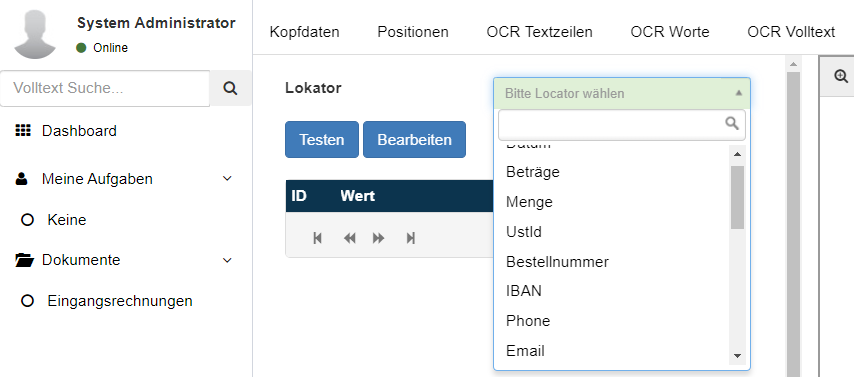
Nach dem der Lokator ausgewählt wurde, ändert sich die Anzeige. Auf der linken Seite wird der Testmodus für den Lokator dargestellt, auf der rechten Seite erscheint nicht mehr das Bild sondern der Konfigurationsdialog des ausgewählten Lokators.
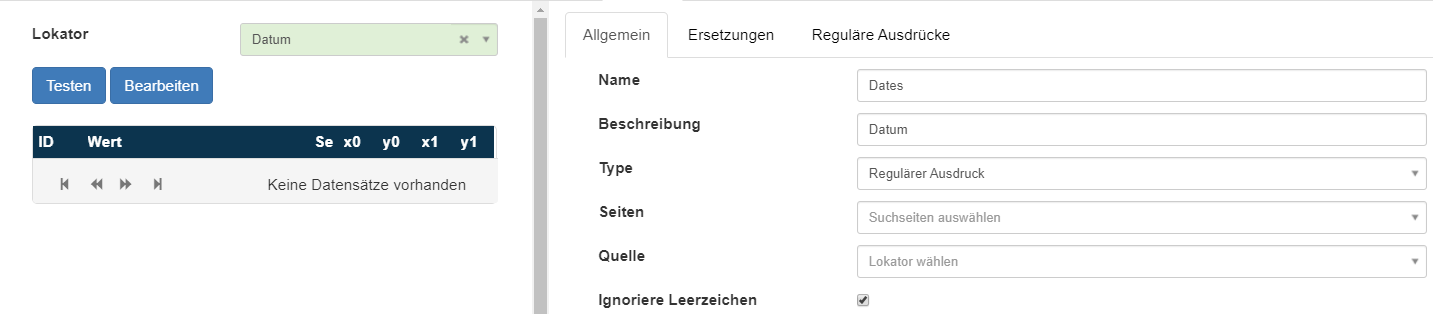
Beim Klick auf den Button Testen wird der ausgewählte Lokator ausgeführt. Nach dem die Ausführung des Lokators beendet ist erscheint ein zusätzliches Browserfenster mit Logausgaben. (das Log-Fenster kann einfach geschlossen werden)
Auf der linken Seite werden jetzt die erkannten Werte in einer Liste dargestellt. Auf der rechten Seite ist wieder das Dokument zu sehen. Wenn der Benutzer nun mit der Maus über einen der Werte zeigt, wird auf der rechten Seite die Fundstelle dieses Wertes markiert.
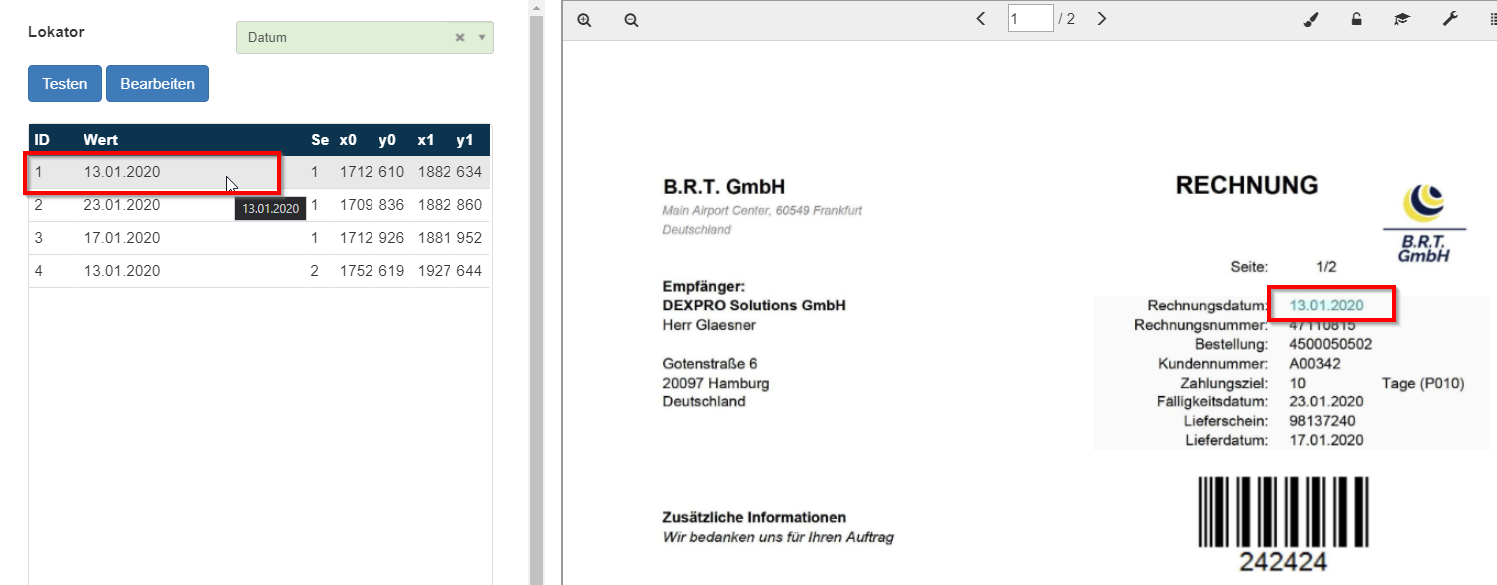
Der Benutzer kann nun wahlweise den Button Bearbeiten klicken, dann erscheint wieder der Konfigurationsdialog für den Lokator, hier kann die Konfiguration angepasst werden und der Test erneut ausgeführt werden.
Besonders bei der Konfiguration eines Lokators für reguläre Ausdrücke, Schlüsselworte oder auch Positionen ist der Testmodus empfehlenswert.
Darüber hinaus gibt es im Testmodus die Möglichkeit die OCR-Textzeilen und die OCR Worte des Dokumentes anzuzeigen.
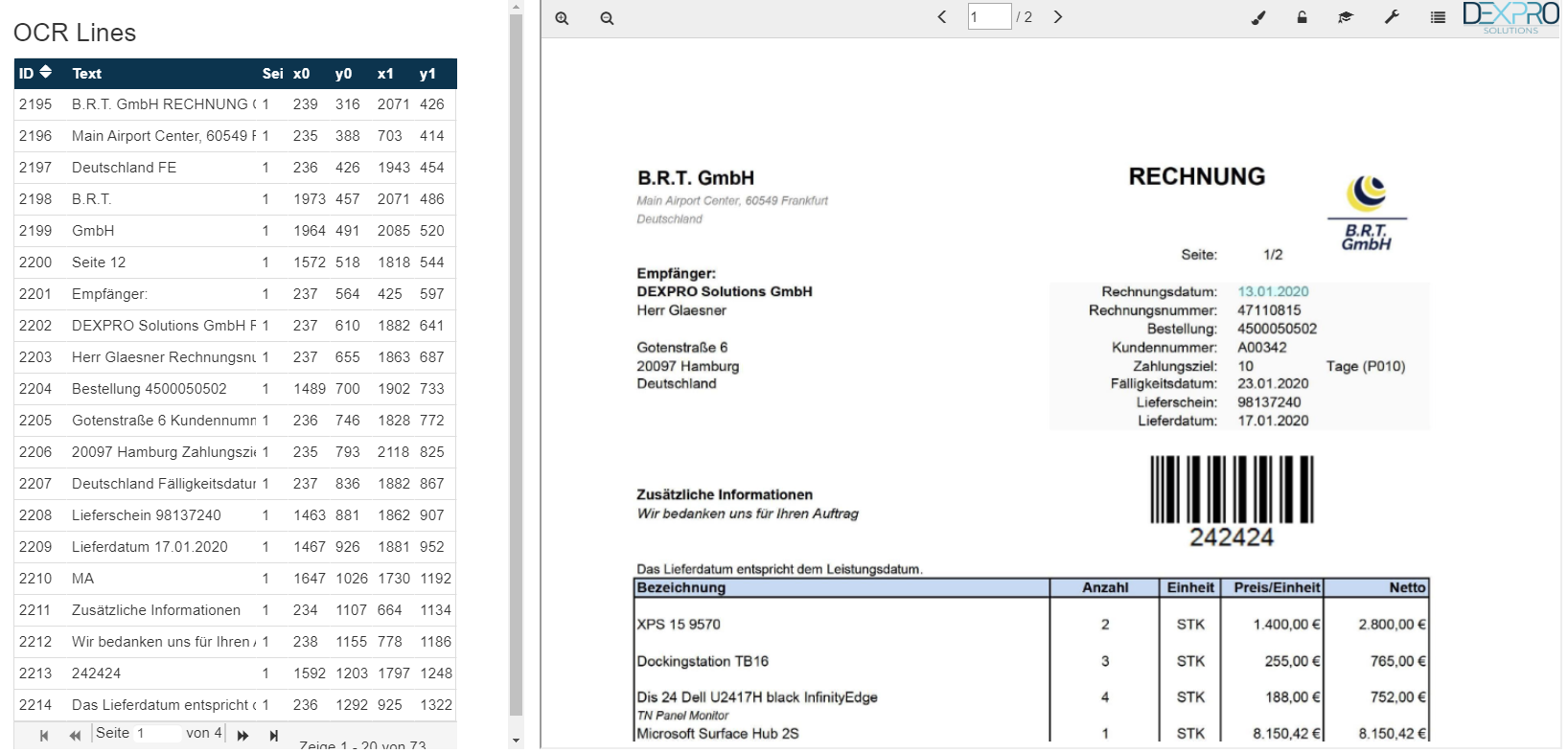
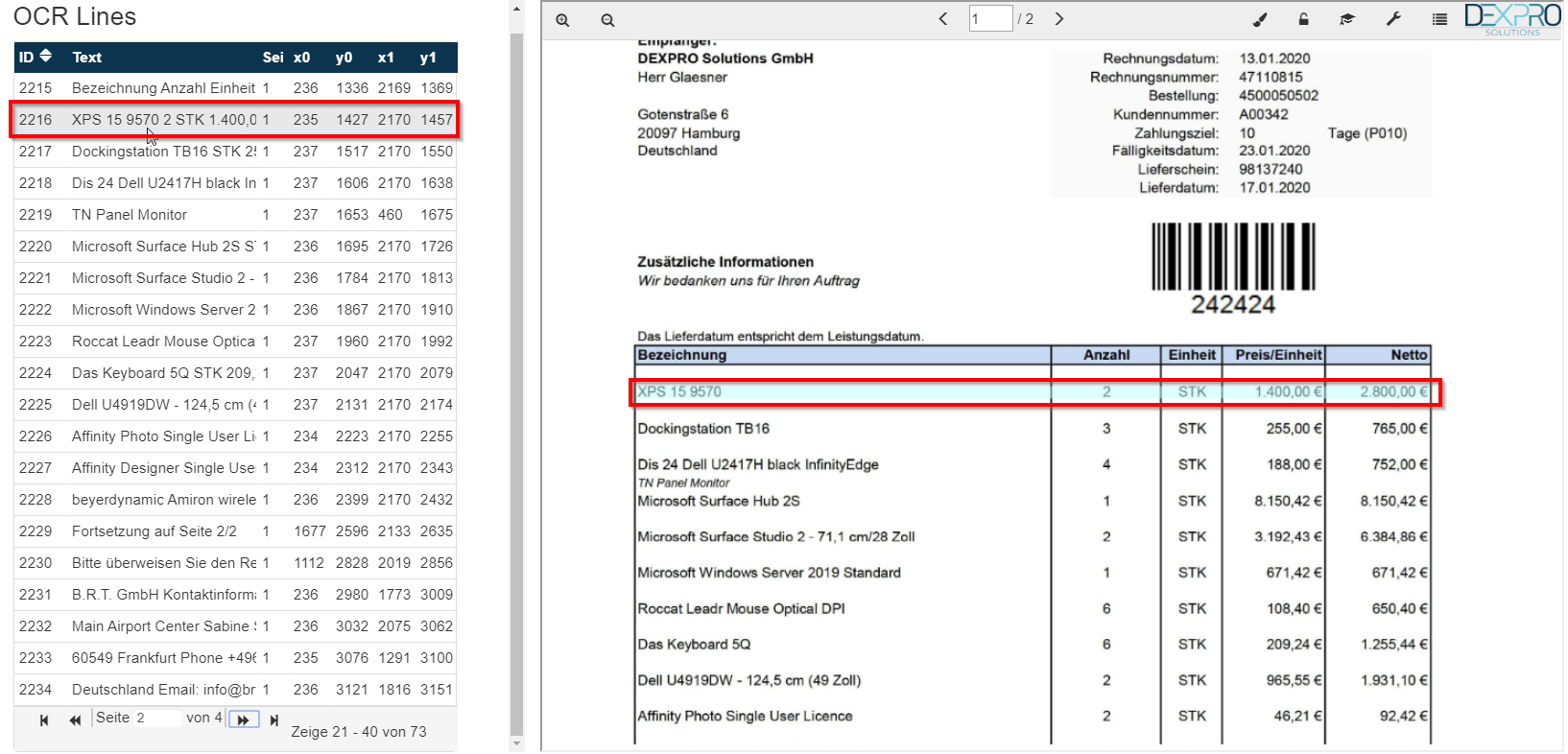
Mit der Maus kann jetzt wieder auf die Textzeilen gezeigt werden, dabei wird die entsprechende OCR-Textzeile auf dem Dokument markiert.
Nachdem der Benutzer einen neuen Lokator erfolgreich getestet hat, kann über den Reiter Aktionen und den Menüpunkt Ergebnis neu erstellen, das Dokument erneut verarbeitet werden, dabei wird nur die Lokatoren-Konfiguration mit den aktuellen Einstellungen angewendet.
Hinweis: Bei Ergebnis neu erstellen, wird keine neue OCR-Erkennung durchgeführt, es wird lediglich die Lokatoren-Logik auf das OCR-Ergebnis neu angewendet.
Lokator: Regular Expression
Der Lokator Regular Expression findet reguläre Ausdrücke in den OCR-Textzeilen des Dokumentes.
Das Ergebnis dieses Lokators ist das gefundene Suchmuster.
Wie reguläre Ausdrücke funktionieren, ist nicht Bestandteil dieser Dokumentation, dafür gibt es im Internet sehr viele gute Beispiele und Möglichkeiten zum Testen von regulären Ausdrücken, z.B. https://regex101.com/
Wichtig: Es können beliebig viele reguläre Ausdrücke konfiguriert werden, diese werden dann automatisch oder verknüpft gesucht.
Wichtig: reguläre Ausdrücke werden in Squeeze case insensitive gesucht, das bedeutet, Groß-Klein Schreibung muss nicht extra berücksichtigt werden.
Wichtig: Die regulären Ausdrücke werden in der Reihenfolge in der diese angelegt sind gesucht, das bedeutet für einen regulären Ausdruck der bereits gefunden wurde, kann kein weiterer, in der Liste nachfolgender regulärer Ausdruck gefunden werden.
Klassische Beispiele für den Einsatz von Lokatoren für reguläre Ausdrücke:
Wichtig: für einige dieser regulären Ausdrücke müssen Ersetzungen konfiguriert werden
| Beispiel | Wert | regulärer Ausdruck | Leerzeichen ignorieren |
| IBAN | DExx xxxx xxxx xxxx xxxx xx | (DE\d{20}) | ja |
| Ust-ID | DE xxxxxxxx | ((DE)([1-9]\d{8})) | ja |
| Beträge | 100,00 oder 1.000,00 | ([-\+]?[0-9]{1,3}([ ]?[,\.]?[ ]?[0-9]{3})*[ ]?[,\.][ ]?[0-9]{2}[-\+]?(?![0-9.,])) | nein |
| Datum | 01.01.2020 | ([0-9]{1,2}\.[0-9]{1,2}\.[0-9]{4})|([0-9]{1,2}\.[0-9]{1,2}\.[0-9]{2}) | ja |
| Namen | Achim Redmann | (Achim Redmann) | nein |
| Telefonnr. |
+4940359840001 |
([+]?[0-9]{8,15}) | ja |
| Emailadresse | info@dexpro-solutions.de | ([a-zA-Z0-9_\-.]{2,30}@[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3}) | nein |
| URL | www.dexpro-solutions.de | (www\.[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3}) | nein |
beispielhafte Einrichtung eines neuen Lokators zur Erkennung einer Bestellnummer anhand eines regulären Ausdrucks
Im folgenden Beispiel soll eine auf dem Dokument befindliche 10-stellige numerische Bestellnummer erkannt werden.
Dazu bietet sich der Lokator für reguläre Ausdrücke sehr gut an.
Im Konfigurationsdialog einer Dokumentenklasse auf den Reiter Lokatoren klicken.

In der unteren Bildschirmleiste das + Symbol Klicken um einen neuen Lokator anzulegen.

Im sich daraufhin öffnenden Fenster den technischen Namen und den Anzeige-Namen des neuen Lokators angeben und auf den Button Speichern klicken.
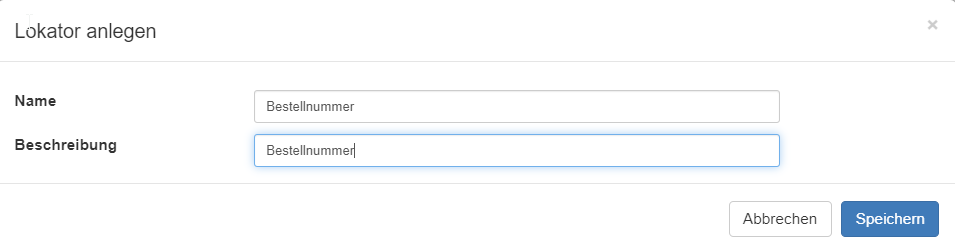
Der neue Lokator erscheint nun in der Liste der Lokatoren. Auf diesen Eintrag Doppelklicken.

Im sich daraufhin öffnenden Dialog den Lokator auf Aktiv setzen. Der Lokator-Typ Regular Expression ist bereits vorausgewählt. Die Erkennung der Bestellnummer soll auf jeder Seite durchgeführt werden und der Wert Typ den wir erkennen wollen ist Text.
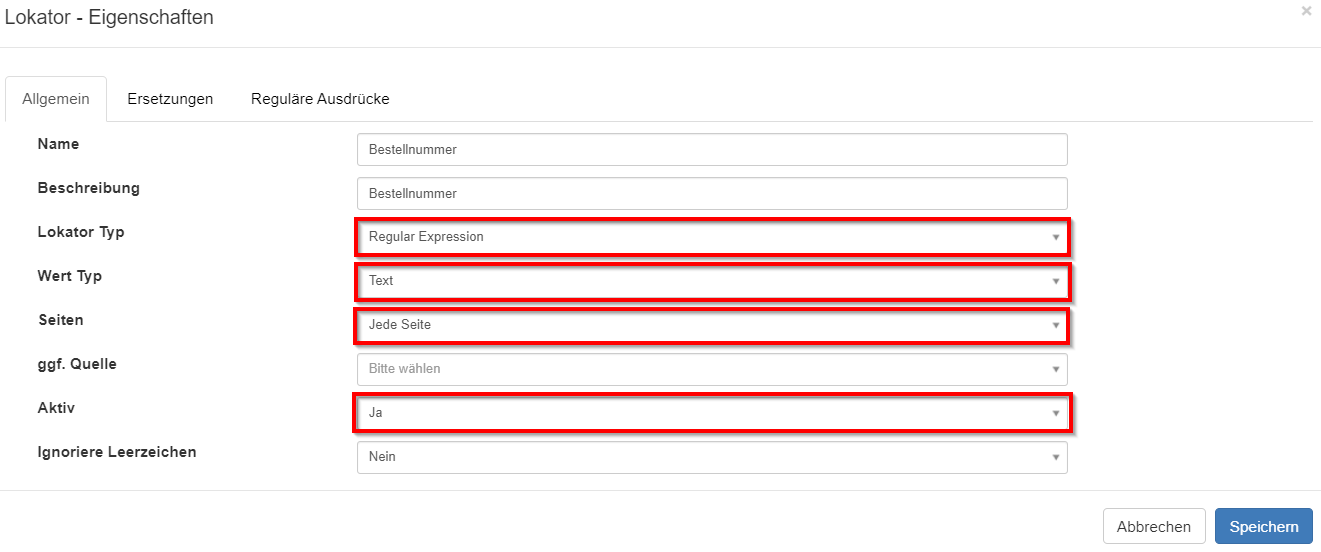
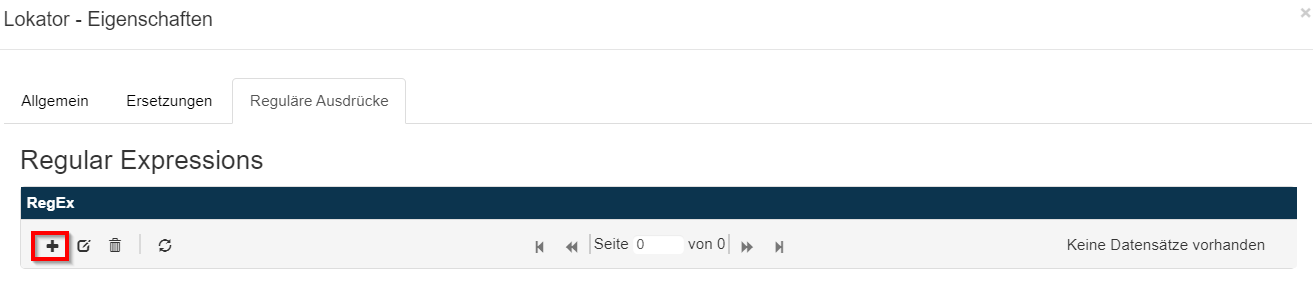
Dann klicken wir auf den Reiter Reguläre Ausdrücke um den Reg-Ex für den Lokator zu konfigurieren. Hier wieder das + Symbol klicken um einen neuen regulären Ausdruck zu konfigurieren.
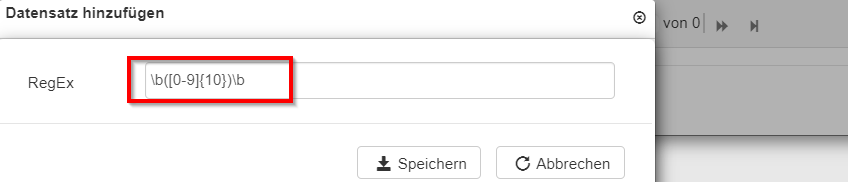
Der reguläre Ausdruck für eine freistehende 10 stellige Nummer könnte folgend konfiguriert werden: \b([0-9]{10})\b
dann auf Speichern klicken.
Der neue Reg-Ex steht jetzt in der Liste der regulären Ausdrücke.

Nachdem der neue Lokator konfiguriert wurde, kann man den Lokator im Testmodus testen. Dazu wird das Dokument mit der Bestellnummer geöffnet und auf den Reiter Testen geklickt. Der neue Lokator kann jetzt in der Liste im Auswahlfenster ausgewählt werden.
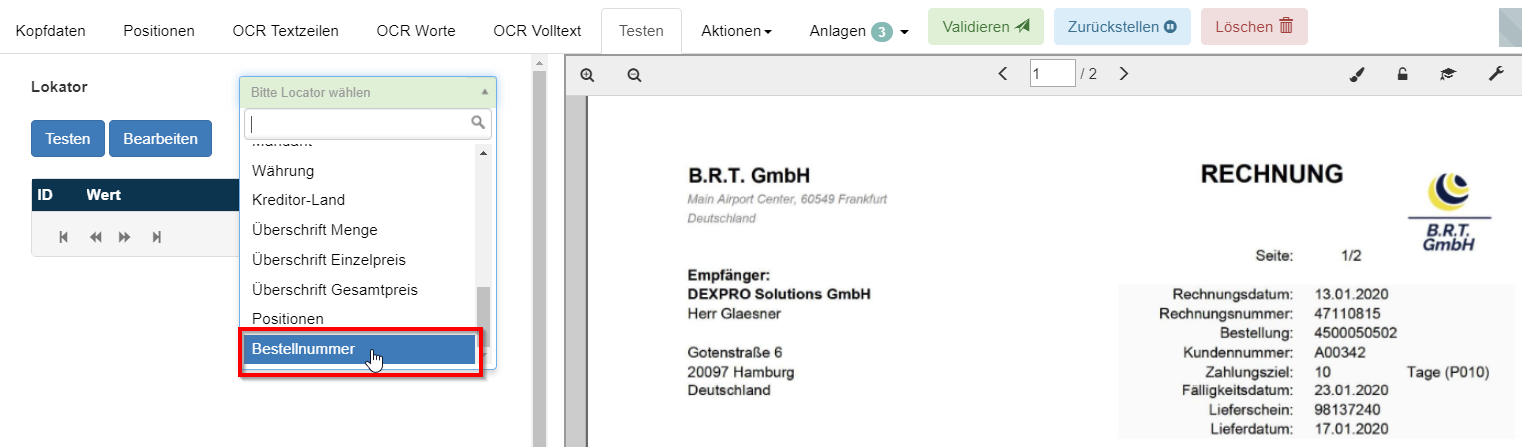
Mit einem Klick auf den Testen Button wird der neue Lokator getestet. Das Ergebnis der Lokatorsuche wird wieder links in der Liste dargestellt, die Fundstelle wird auf dem Dokument markiert.
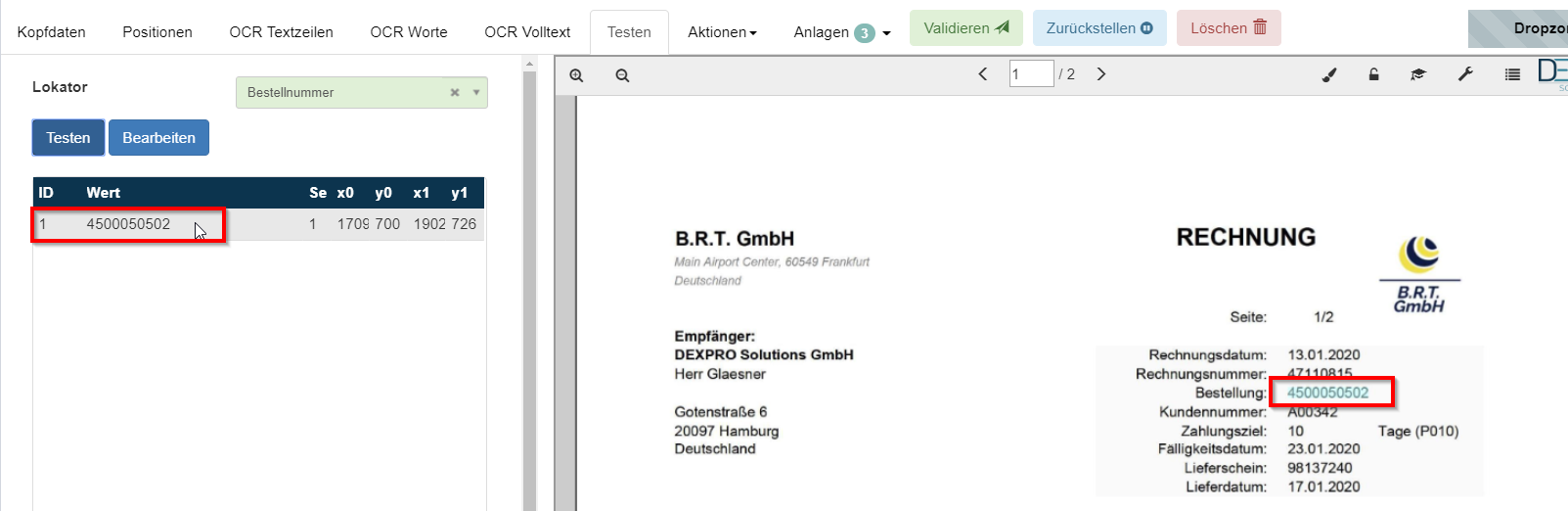
Jetzt müsste der Benutzer den neuen Lokator noch dem jeweiligen Dokumenten-Feld für die Bestellnummer zuweisen. Dies ist im Kapitel Dokumentenfelder beschrieben.
Wie die erkannte Bestellnummer gegen entsprechende Stammdaten plausibilisiert werden kann, ist in der Beschreibung für den Lokator Search for DB Link data beschrieben.
Lokator: KeyWord
Der Lokator KeyWord findet Schlüsselwörter in den OCR-Textzeilen des Dokumentes.
Das Ergebnis dieses Lokators ist das konfigurierte Schlüsselwort.
Wichtig: die Suche nach Schlüsselwörtern berücksichtigt immer nur ein Schlüsselwort.
Wichtig: Es können beliebig viele Schlüsselwörter konfiguriert werden, diese werden dann automatisch oder verknüpft gesucht.
Wichtig: Die Suche nach Schlüsselwörtern berücksichtigt eine gewisse Unschärfe. Im Detail bedeutet unscharf in diesem Lokator, das ein Zeichen des Schlüsselwortes abweichen kann und dennoch zu einem positiven Suchergebnis führen wird.
Wichtig: Schlüsselwörter werden in Squeeze case insensitive gesucht, das bedeutet, Groß-Klein Schreibung muss nicht extra berücksichtigt werden.
Die Anlage eines neuen Lokators für die Suche nach einem neuen Schlüsselwort, funktioniert analog zur Anlage eines regulären Ausdrucks, der Lokator Typ für die Schlüsselwortsuche ist KeyWord.
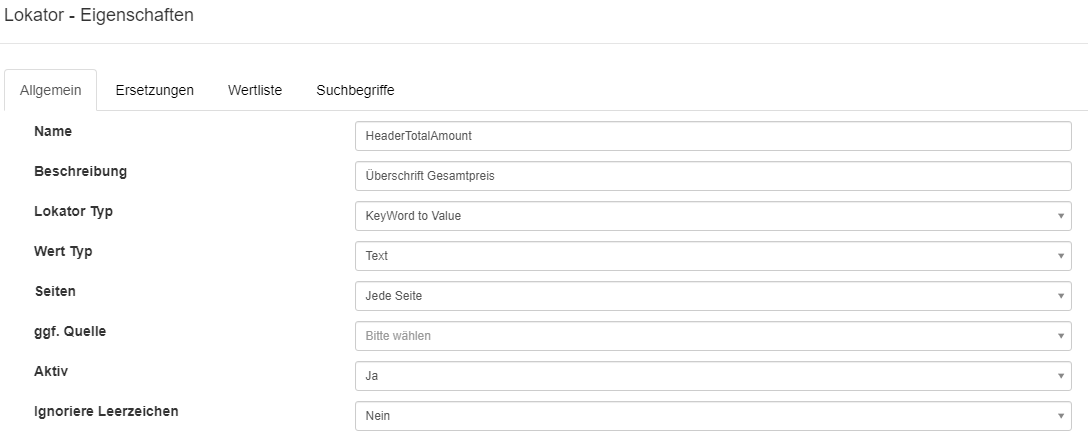
Lokator: KeyWord to Value
Der Lokator KeyWord to Value findet Schlüsselwörter in den OCR-Textzeilen des Dokumentes.
Der Unterschied zum normalen KeyWord Lokator besteht darin, das dem Schlüsselwort ein weiterer konfigurierbarer Wert zugewiesen werden muss.
Das Ergebnis dieses Lokators ist der konfigurierte Wert der dem Schlüsselwort zugeordnet ist.
Darüber hinaus gelten für die KeyWord to Value Suche alle Merkmale der normalen KeyWord Suche (siehe Lokator: KeyWord)
Ein geeignetes Beispiel für die KeyWord to Value Suche ist z.B. die Rechnungsart.
| zugewiesener Wert | mögliche Schlüsselwörter |
| Rechnung | Rechnung, Anzahlungsrechnung, Invoice, Faktura, Dauerrechnung etc. |
| Gutschrift | Gutschrift, Debit Note etc. |
Anlegen eines KeyWord to Value Lokators:
Das Vorgehen zum Anlegen eines KeyWord to Value Lokators ist analog zum KeyWord Lokator.
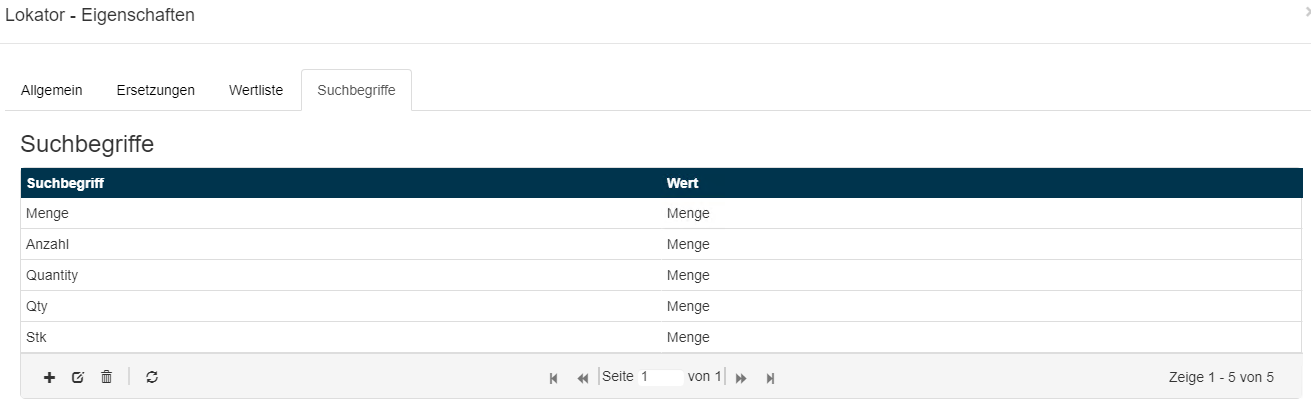
Wenn der Lokator Typ KeyWord to Value ausgewählt wird, erscheint im Konfigurationsdialog neben dem Reiter Suchbegriffe für die Schlüsselwörter, ein weiterer Reiter für die Konfiguration der Werte.
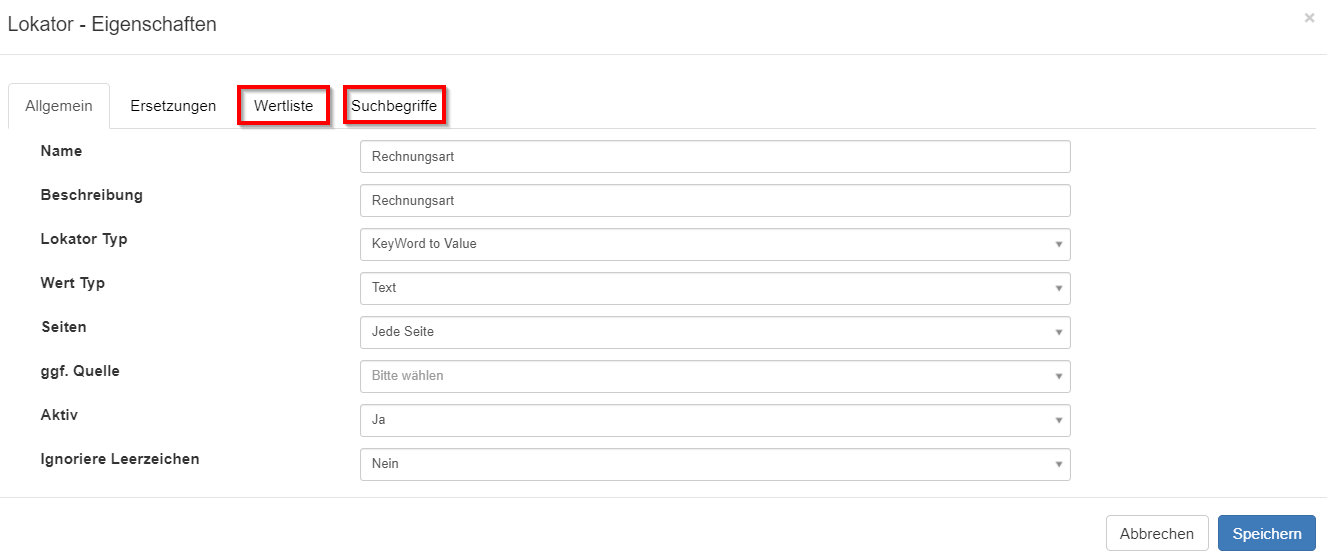
Zuerst konfiguriert man den gewünschten Wert mit einem Klick auf den Reiter Werteliste.
In der unteren Liste wird mit einem Klick auf das + Symbol ein neuer Wert hinzugefügt. Daraufhin öffnet sich ein neues Fenster mit den beiden Feldern Wert und Beschreibung, diese beiden Felder werden im folgenden Beispiel jeweils mit dem Wert Rechnung gefüllt und mit einem Klick auf den Speichern Button bestätigt.
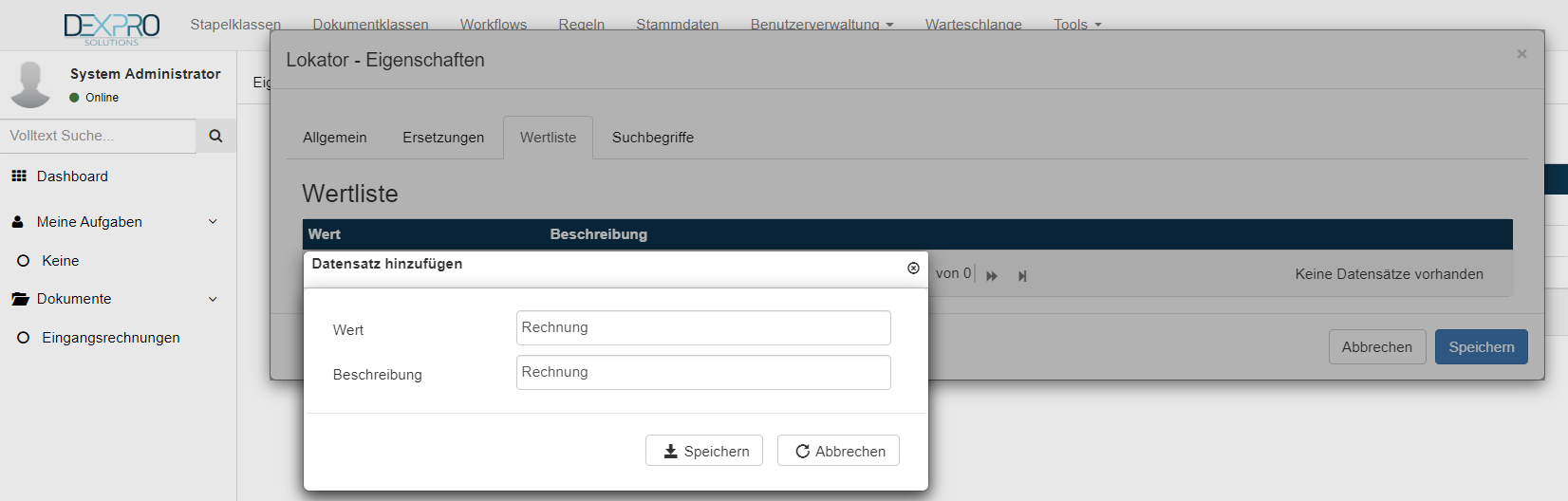
In der Liste der Werte befinden sich nun der neue Wert und dessen Beschreibung.
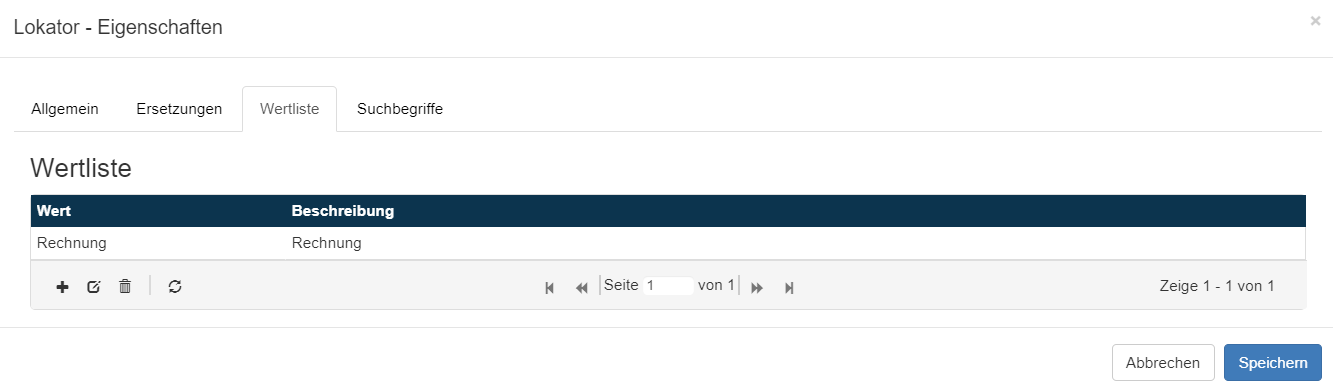
Mit einem Klick auf den Reiter Suchbegriff kann der gewünschte Suchbegriff angelegt werden. dazu wieder das + Symbol klicken.
Daraufhin öffnet sich ein neues Fenster, hier kann der Suchbegriff konfiguriert werden und diesem Suchbegriff kann der gewünschte Wert zu gewiesen werden.
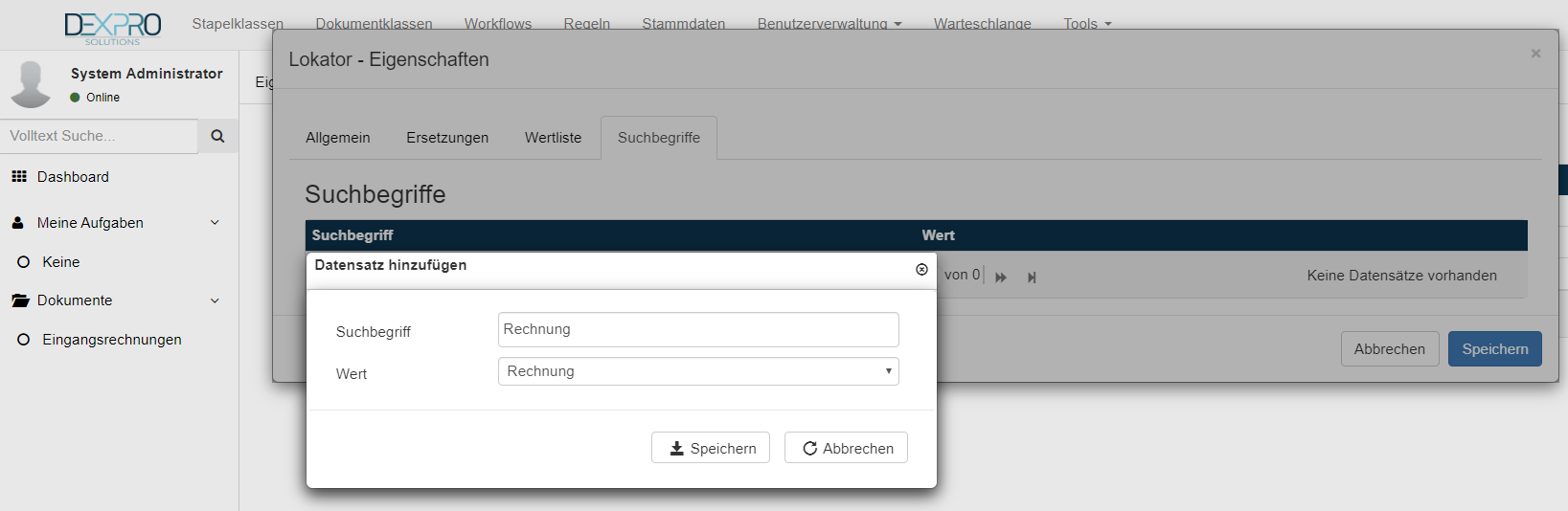
Mit einem Klick auf den Speichern Button, wird die Konfiguration für den Suchbegriff zum entsprechenden Wert gespeichert.
Für dieses Beispiel fügen wir einen weiteren Suchbegriff hinzu. Der Suchbegriff Invoice soll zusätzlich dem Wert Rechnung zugewiesen werden.
Mit einem Klick auf das + Symbol können weitere Suchbegriffe zugewiesen werden, im Feld Feld Wert wird der gewünschte Wert ausgewählt.
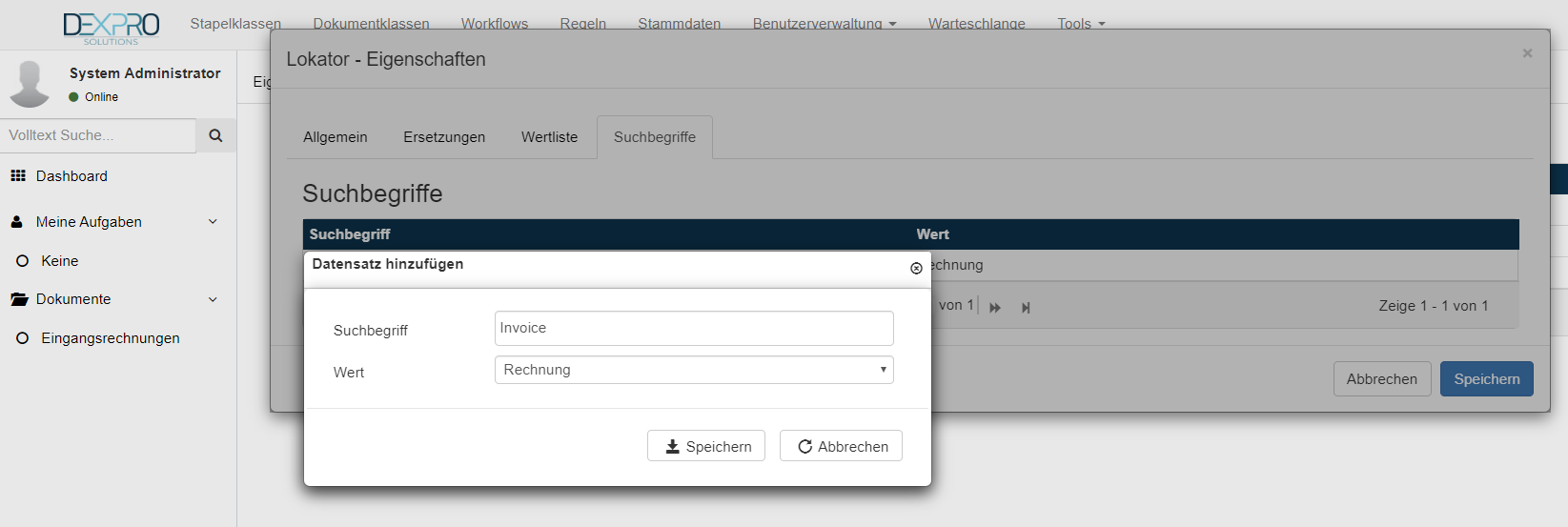
Mit dieser Konfiguration werden die beiden Schlüsselwörter Rechnung oder Invoice auf dem Dokument gesucht und das Ergebnis dieses Lokators ist der Wert Rechnung.
Diese Konfiguration kann beliebig erweitert werden. Zum Beispiel kann ein weiterer Wert Gutschrift hinzugefügt werden.
Diesem Wert können wieder beliebig viele Suchbegriffe zugewiesen werden.
Wichtig: Jedem Suchbegriff sollte ein Wert zugewiesen werden, da andernfalls das Lokator-Ergebnis für den Suchbegriff leer bleibt.
Lokator: Value next to KeyWord
Der Lokator Value next to KeyWord findet Schlüsselwörter und in der Nähe des Schlüsselwortes befindliche Reguläre Ausdrücke.
In der Nähe bedeutet, der Lokator sucht rechts neben dem Schlüsselbegriff und unter dem Schlüsselbegriff nach einem passenden regulären Ausdruck.
Ein klassisches Beispiel für diesen Lokator ist die Suche nach Rechnungsnummern auf einer Rechnung.
In der Konfiguration des Lokators gibt es einen Reiter für die Konfiguration der gewünschten Schlüsselbegriffe und einen Reiter für die regulären Ausdrücke.
Die Konfiguration der der regulären Ausdrücke und der Schlüsselbegriffe ist analog zur Konfiguration der Lokatoren für KeyWords und des Lokators für reguläre Ausdrücke.
Lokator: Invoice Amounts
Der Lokator Invoice Amounts findet die Endbeträge (Nettobetrag, Bruttobetrag und Steuerbetrag) und den Steuersatz einer Rechnung.
Dieser Lokator funktioniert nur in Kombination mit einem Betrags-Lokator der auf Basis regulärer Ausdrücke, numerische Werte mit 2 Nachkommastellen ermittelt. Darüber hinaus werden Stammdateninformationen zum gültigen Steuersatz benötigt.
Die Funktionsweise dieses Lokators kann wie folgt beschrieben werden.
- Mittels des Betrags-Lokators werden zuerst alle Beträge der Rechnung gefunden
- Auf der letzten Seite der Rechnung wird beginnend von unten nach oben der höchste Betrag ermittelt
- In der Stammdaten-Tabelle taxrates (Steuersätze) werden mit dem Invoice Template alle europäischen Steuersätze landesspezifisch ausgeliefert
- In der Stammdaten-Tabelle creditors (Bestandteil des ausgelieferten Invoice Templates) können kreditorspezifische Länderkennzeichen hinterlegt werden
- Mittels des zum ermittelten Kreditor, passenden Länderkennzeichens, werden die für diese Rechnung gültigen Steuersätze ermittelt
- Der Lokator Invoice Amount verwendet diese Informationen um zum höchsten gefundenen Bruttobetrag, mittels der gültigen Steuersätze, entsprechende passende Netto und Steuerbeträge zu finden.
Wichtig: Diese Konfiguration funktioniert nur für einen Steuersatz. Für Rechnungen mit mehreren Steuersätzen wird es in zukünftigen Versionen entsprechende Funktionen geben. Aktuell gibt es für diese Rechnungen die Möglichkeit Endbeträge für mehrere Steuersätze kreditorspezifisch zu trainieren.
Konfiguration des Invoice Amounts Lokators:
Voraussetzung für die Verwendung dieses Lokators ist ein Lokator für die Betragsfindung aufgrund regulärer Ausdrücke. Dieser Lokator wird mit dem Invoice Template ausgeliefert.
weitere Voraussetzungen sind die Stammdatentabellen taxrates und creditors. Beide Stammdatentabellen werden mit dem Invoice Template ausgeliefert.
Im Feld ggf. Quelle wird der konfigurierte Betragslokator hinterlegt.
Alternative Endbetragsermittllung für Rechnungen:
Da es vorkommen kann das einige Rechnungen die für die Endbetrags-Ermittlung notwendigen Werte (Brutto, Netto und Steuerbetrag) nicht enthalten (z.B. Rechnungen im Baugewerbe), kann für diese Rechnungen alternativ, die Endbetrags-Ermittlung nach dem Prinzip der Keyword-Suche konfiguriert werden.
Für diese Konfiguration sind 3 weitere Keyword-Lokatoren (Nettobetrag, Bruttobetrag und Steuerbetrag) anzulegen. Diese Lokatoren sollten die gewünschten Schlüsselworte für die gesuchten Beträge finden.
Diese Lokatoren können dann im Reiter Endbeträge entsprechend hinterlegt werden.
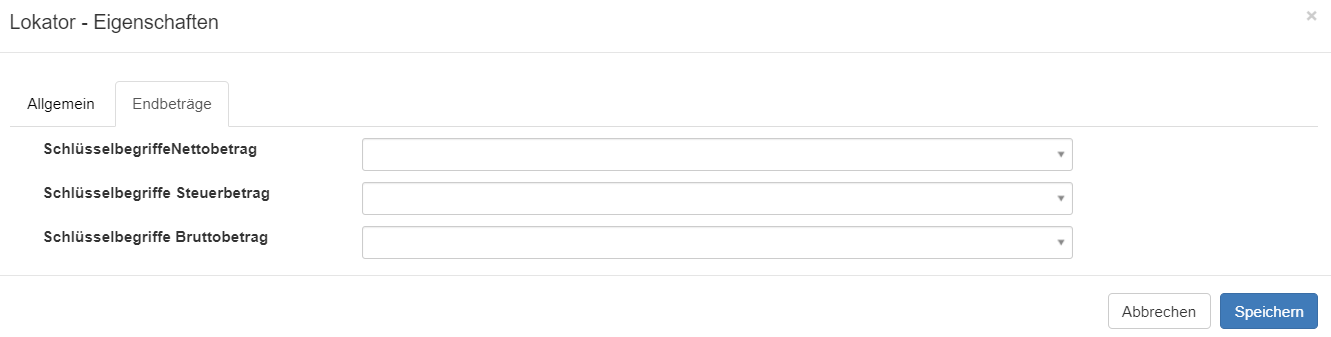
Konfigurierbare Steuersätze je Land
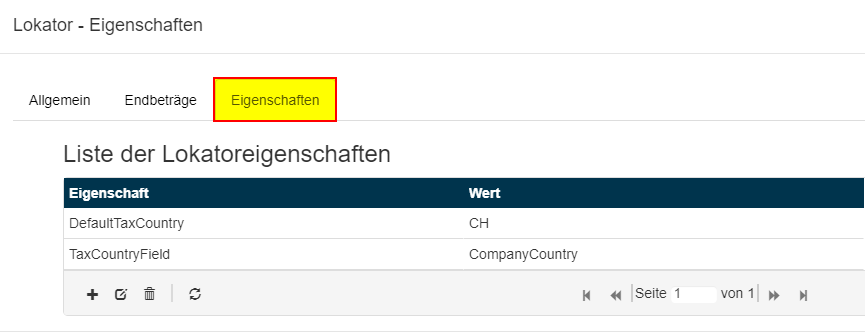
Seit der SQUEEZE Version 1.8.0 existiert eine weitere Möglichkeit zur Konfiguration dieses Lokators. Auf Grund der Mehrwertsteueranpassung zum 01.07.2020 wurde die Möglichkeit geschaffen, die gültigen Mehrwertsteuersätze je Land in der Stammdatentabelle (taxrates) zu hinterlegen.
Hinzu kommt die Möglichkeit, der Betragserkennung mitzugeben, für welches Land gerade eine Betragserkennung durchgeführt werden soll bzw. welche Mehrwertsteuersätze zu nutzen sind. Das Land bzw. die Mehrwertsteuersätze können je Beleg variieren, daher kann unter dem neuen Reiter Einstellungen hinterlegt werden, in welchem Feld (TaxCountryField) das Länderkürzel steht, welches zur Ermittlung der Steuersätze genutzt werden soll.
Sollte kein Land ermittelt worden sein, kann ein Standard Ländercode festgelegt werden (DefaultTaxCountry), welcher verwendet wird, um die Steuersätze zu ermitteln.
Hier ein Beispiel:
Lokator: Document Date
Der Lokator Document Date findet das erste Datum auf einer Dokumentenseite, von oben beginnend.
Dieser Lokator kann nur mittels eines weiteren Lokators basierend auf der Suche nach regulären Ausdrücken genutzt werden. Für diesen Lokator sollten entsprechende reguläre Ausdrücke konfiguriert sein.
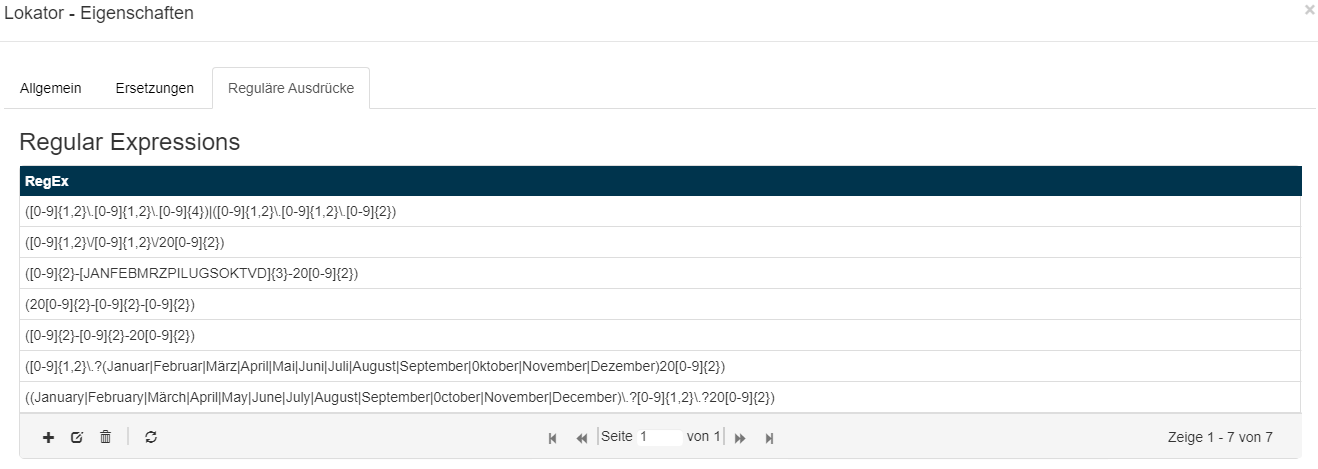
Im Squeeze Invoice-Template wird ein Lokator mit verschiedenen regulären Ausdrücken zur Datums-Suche ausgeliefert.
Dieser Lokator (Dates) wird dann als Quelle für den Beleg-Datums-Lokator genutzt.
Konfiguration des Dates-Lokators:
Allgemeine Eigenschaften:
reguläre Ausdrücke für den Date-Lokator:
Konfiguration des Beleg-Datum-Lokators:
Der Datums-Lokator wird als Quelle für den Beleg-Datums Lokator eingetragen.
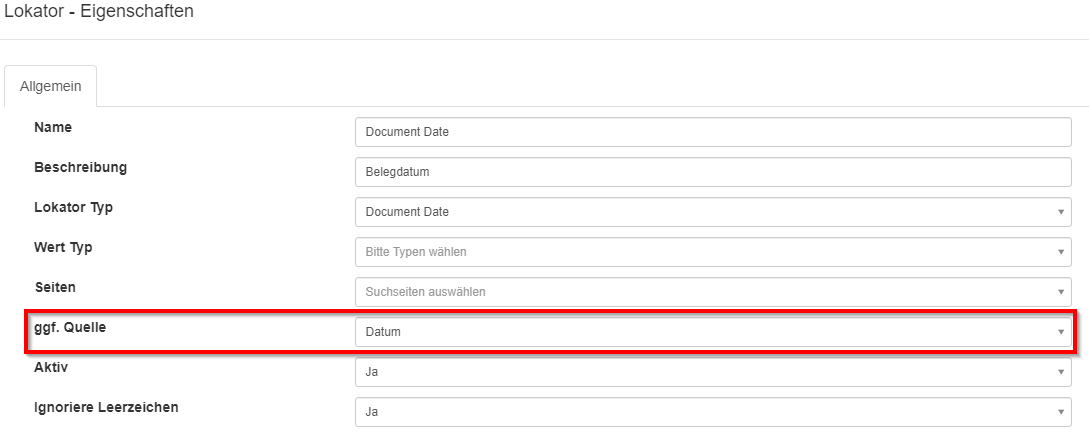
Lokator: Search for DB linked data
Der Lokator Search for DB linked data findet auf Basis weiterer Lokatoren-Ergebnisse, Einträge in Datenbanken.
Ein klassisches Beispiel für die Verwendung dieses Lokators ist die Kreditorsuche bei Eingangsrechnungen.
Mittels entsprechender Lokatoren für die Suche nach IBAN-Nummern, Umsatzsteuer-IDs, Steuernummern, Telefon - und Fax-Nummern, Email-Adressen oder Internet-Adressen wird in einer entsprechenden Datenbank nach passenden Einträgen gesucht und zu diesen Einträgen die Kreditor-Nummer zurückgegeben.
Der Lokator für die Suche nach Kreditoren mittels Datenbanksuche ist Bestandteil des ausgelieferten Invoice Templates.
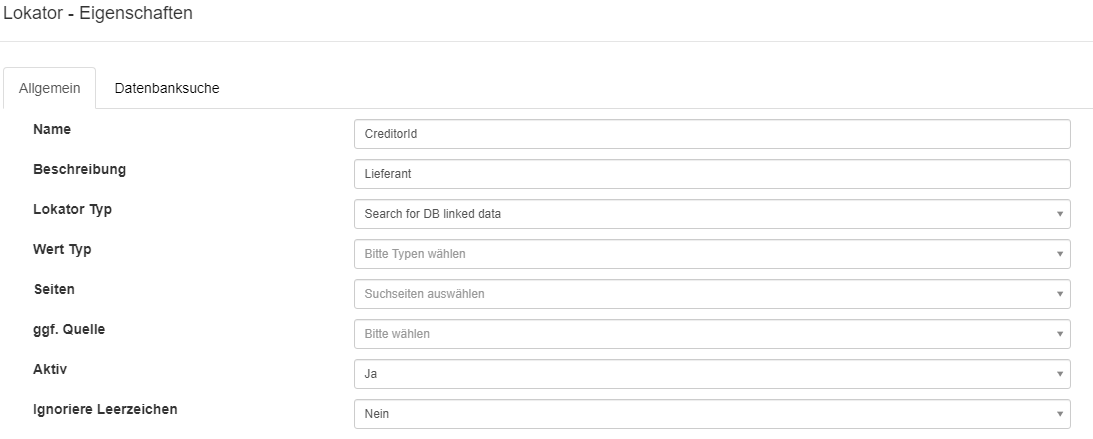
Konfiguration des DB Link Locators
Die Konfiguration wird analog zu allen anderen Lokatoren durchgeführt. Der Lokator Typ für diesen Lokator ist Search for DB linked data.
Unter dem Reiter Datenbanksuche wird die Datenbank-Suche konfiguriert:
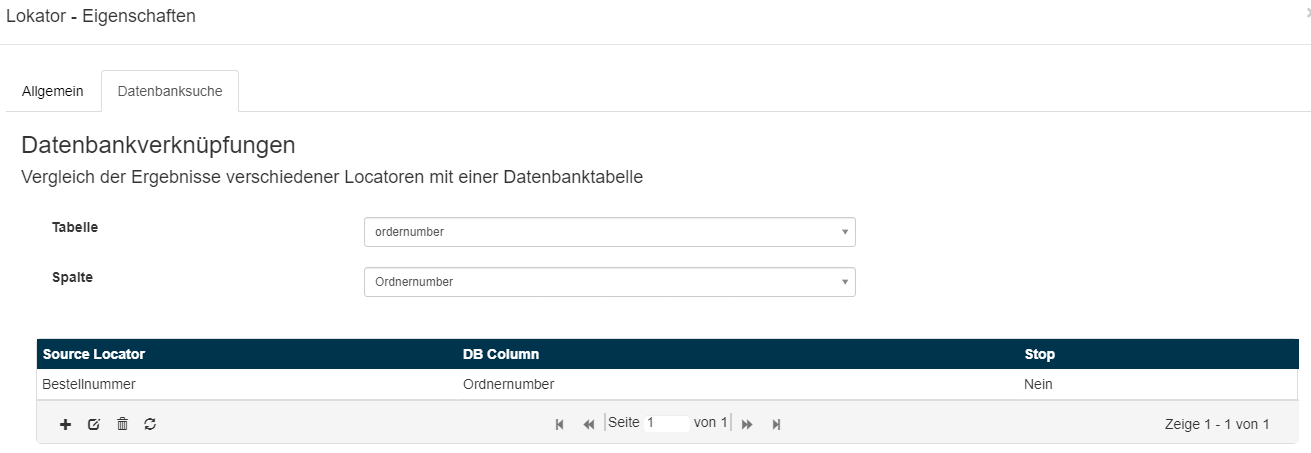
Diese Konfiguration wird am Beispiel der Kreditor-Suche erläutert.
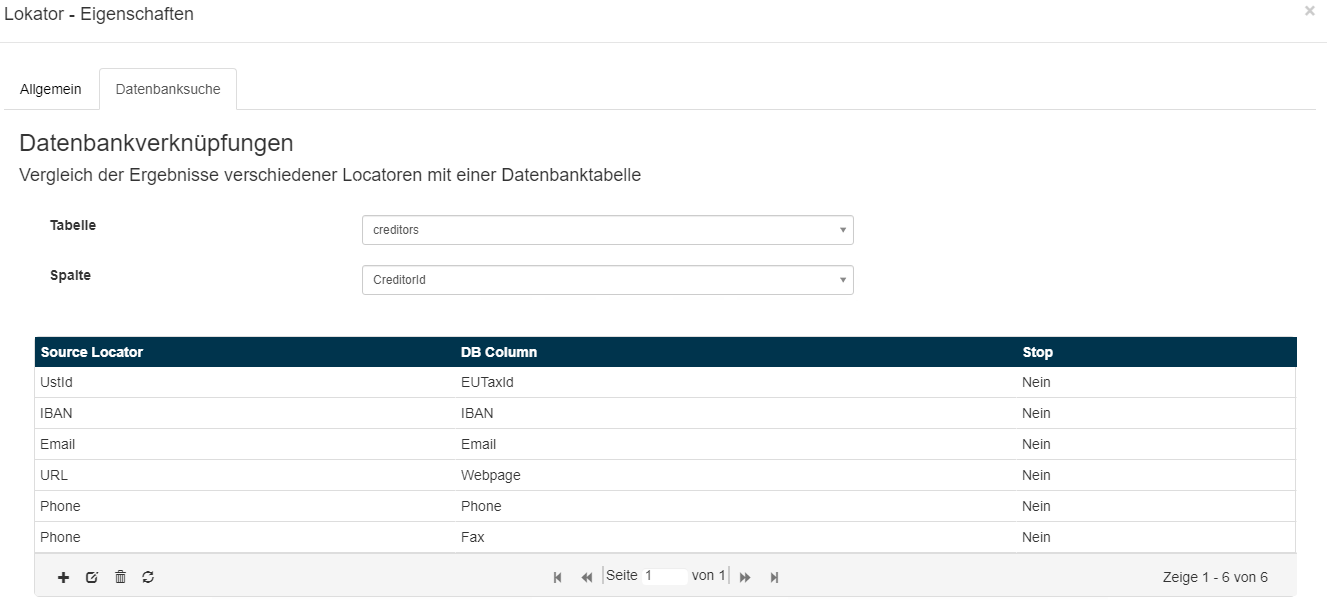
- Im oberen Teil der Konfiguration wird die Stammdaten-Tabelle für Kreditoren im Feld Tabelle ausgewählt.
- Im Feld Spalte kann die Datenbank-Spalte dieser Tabelle für das Ergebnis der Datenbank-Suche ausgewählt werden.
- In diesem Beispiel soll als Lokator-Ergebnis die Kreditor-Nummer zurückgegeben werden.
Im unteren Tabellen-Bereich der Konfiguration werden die Source-Lokatoren für die Kreditor-Suche konfiguriert.
| Source Lokator (Quell-Lokator) | DB-Spalte der ausgewählten DB | Stop-Kennzeichen |
| UstId (Lokator für die Ermittlung von Umsatzsteuer-IDs) | EUTaxId | Nein |
| IBAN (Lokator für die Ermittlung von IBANs) | IBAN | Nein |
| Email (Lokator für die Ermittlung von Emails) | Nein | |
| URL (Lokator für die Ermittlung von URLs) | Webpage | Nein |
| Phone (Lokator für die Ermittlung von Telefonnummern) | Phone | Nein |
| Phone (Lokator für die Ermittlung von Telefaxnummern) | Fax | Nein |
Die Such-Ergebnisse der Source-Lokatoren werden in der DB-Spalte der entsprechenden Datenbank gesucht und der Wert der Ergebnis-Spalte zurückgegeben.
Die Reihenfolge wie die Ergebnisse der Source-Lokatoren in der Datenbank gesucht werden, kann in der Liste via Drag & Drop geändert werden. Der oberste Eintrag wird zuerst gesucht, der unterste Eintrag zuletzt.
Für das Stop-Kennzeichen kann entweder ja oder nein ausgewählt werden. Ja bedeutet, wenn nur ein Ergebnis in der Datenbank gefunden wird, wird der Wert der konfigurierten Ergebnis-Spalte zurückgegeben und die Suche beendet. Nein bedeutet, unabhängig ob es Treffer in der Datenbank gibt, es wird immer mit dem nächsten Lokator in der Liste weiter gesucht.
Für die IBAN bedeutet diese Konfiguration, alle via IBAN-Lokator gefundenen IBANs werden in der Datenbankspalte IBAN gesucht, wenn eine oder mehrere passende IBANs gefunden werden, werden die Kreditor-IDs dieser Zeilen zurückgegeben.
Mit dem + Symbol können weitere Lokatoren die bereits konfiguriert sind, ausgewählt und hinzugefügt werden.

- das Locator Feld ist ein Auswahlfeld mit allen Lokatoren die konfiguriert sind
- das Feld DB Column gibt an in welcher Datenbankspalte das Lokatorergbnis in der Tabelle gesucht werden soll
- für das Feld Stop kann entweder ja oder nein ausgewählt werden.
Eine weitere Verwendungsmöglichkeit dieses Lokators ist die Plausibilisierung entsprechender Lokator-Ergebnisse gegen Datenbankeinträge.
So könnte man zum Beispiel mittels:
- regulärer Ausdrücke
- KeyWords
- Value next to KeyWord-Suche
folgende beispielhafte Merkmale auf dem Dokument ermitteln:
- Bestell-Nummern,
- Lieferschein-Nummern,
- Auftrags-Nummern,
- Mandanten-Namen
und diese dann gegen geeignete Datenbankinformationen plausibilisieren.
Dazu wird das Lokator - Ergebnis in der entsprechenden Datenbanktabelle gesucht und diese Datenbankspalte auch als Ergebnis-Spalte konfiguriert. Mittels dieser Konfiguration werden als Ergebnis nur Einträge die auch in der Datenbank gefunden werden zurückgegeben.
Beispiel für Datenbank-Plausibilisierung
In dem abgebildeten Beispiel, wird die mittels eines regulären Ausdrucks ermittelte Bestellnummer, gegen eine Datenbank mit entsprechenden Bestellnummern plausibilisiert.
Lokator für Erkennung der Bestellnummer (10-stellig numerisch) mittels regulärem Ausdruck:
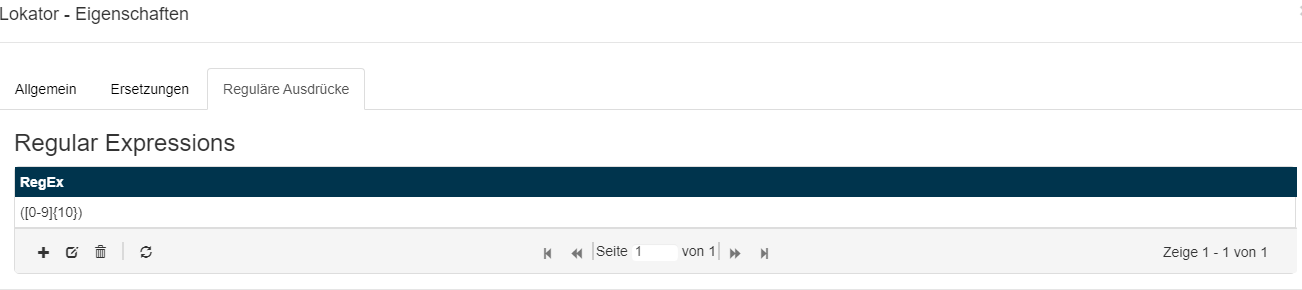
Lokator für die Plausibilisierung der erkannten Bestellnummer gegen eine Datenbank:
Lokator: Search for line items
Der Lokator Search for line items findet Positionszeilen auf Dokumenten anhand entsprechender Spalten-Überschriften und unter diesen Spalten befindlichen Werten.
Die Suche nach Positionen ist im ausgelieferten Invoice-Template bereits konfiguriert.
Die Positions-Suche in Squeeze benötigt entsprechende Lokatoren mit deren Hilfe die Spaltenüberschriften der Positions-Tabelle gefunden werden.
Konfiguration einer Standard-Positions-Suche für Eingangsrechnungen:
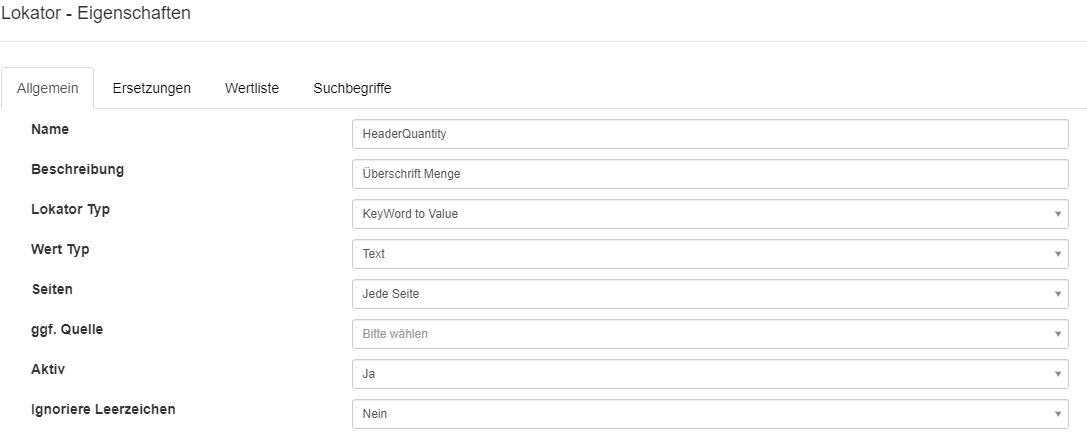
Die Lokatoren für die Suche nach Spaltenüberschriften können als KeyWord to Value konfiguriert werden.
Konfigurations - Beispiel für den Lokator der Spalte Menge:
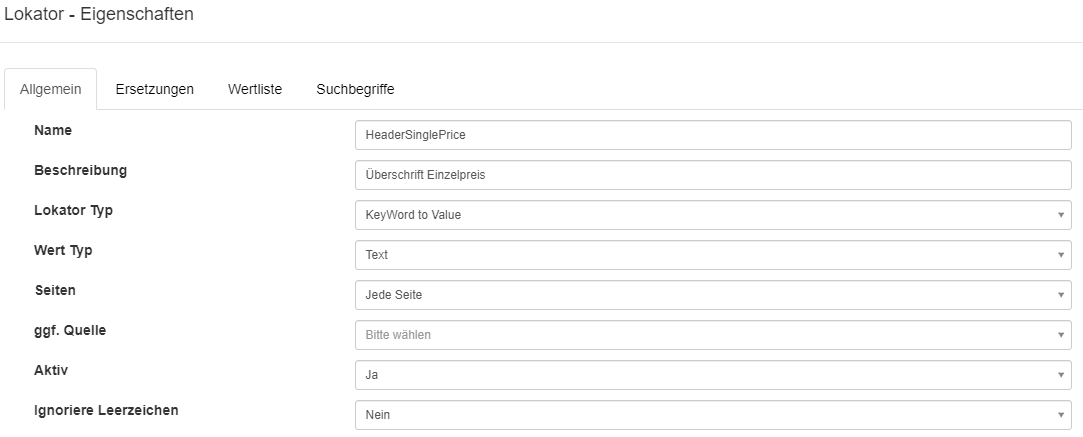
Konfigurations - Beispiel für den Lokator der Spalte Einzelpreis:
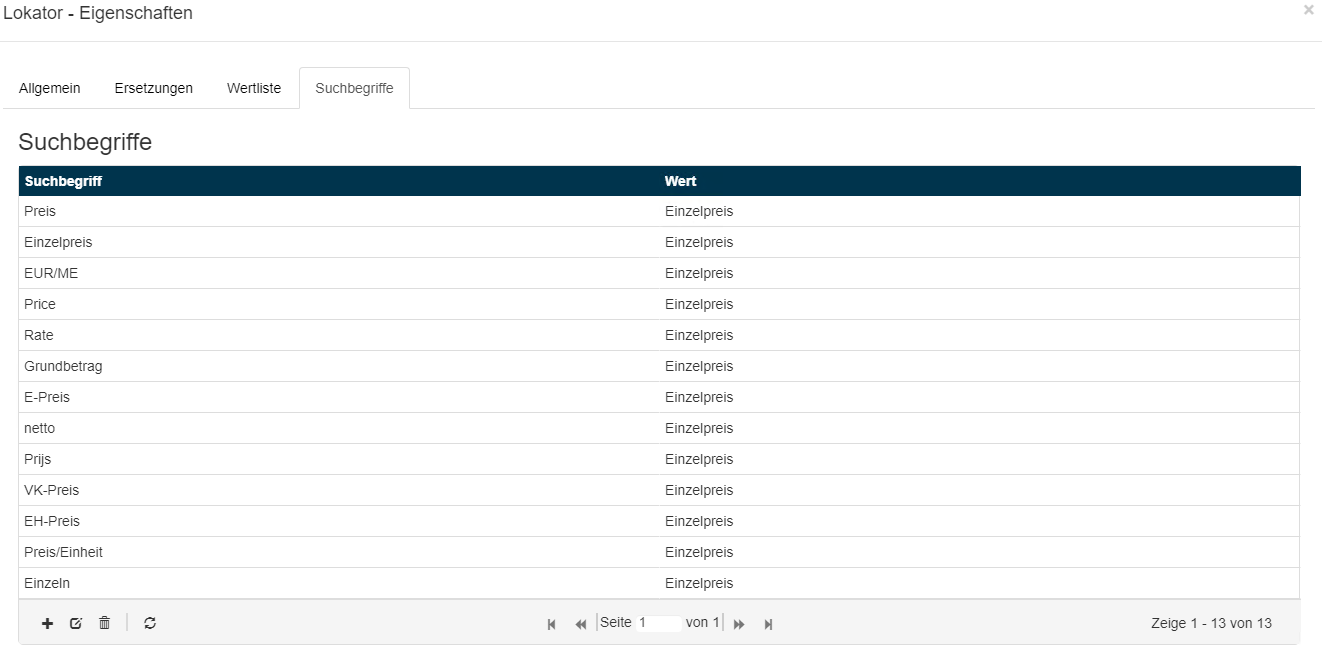
Konfigurations - Beispiel für den Lokator der Spalte Positionsgesamtpreis:
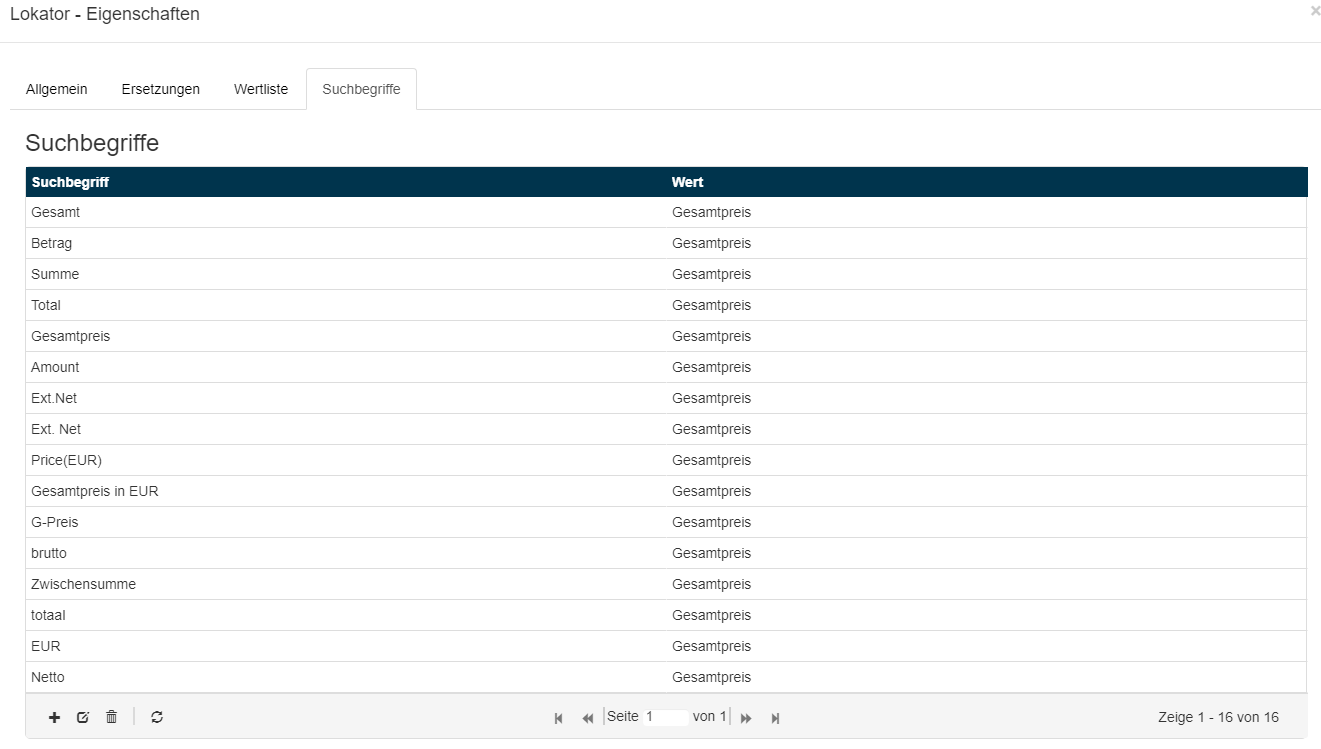
Die konfigurierten Suchbegriffe können je nach Anwendungsfall entsprechend angepasst und/oder erweitert werden.
Diese Lokatoren können in der Konfiguration für das Positions-Tabellenfeld hinterlegt werden.
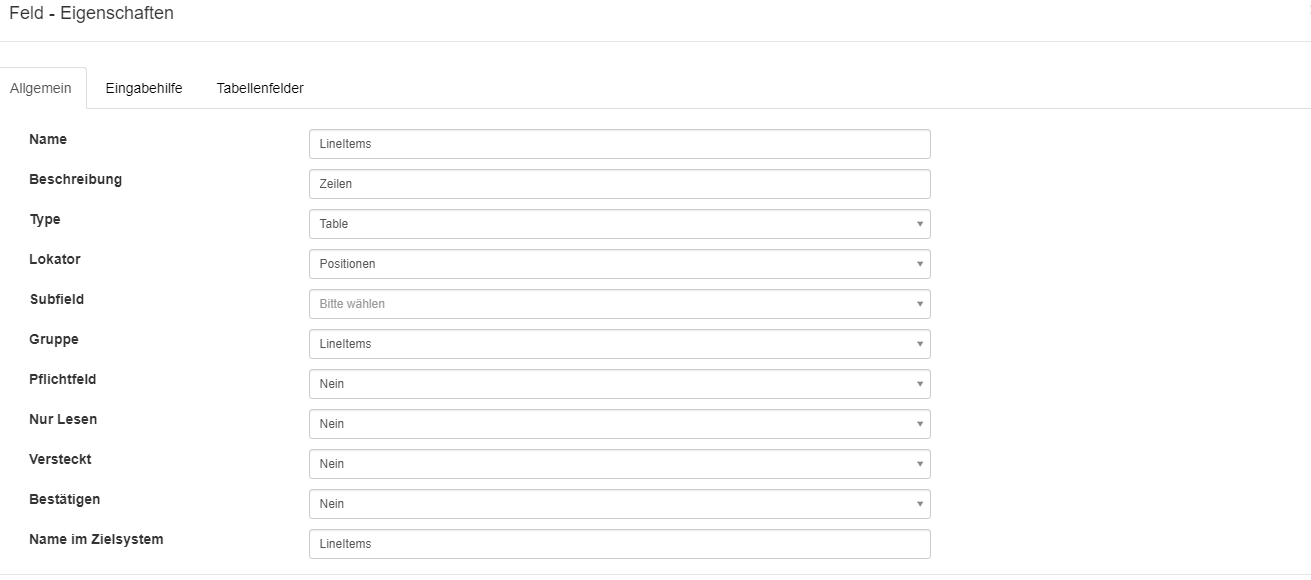
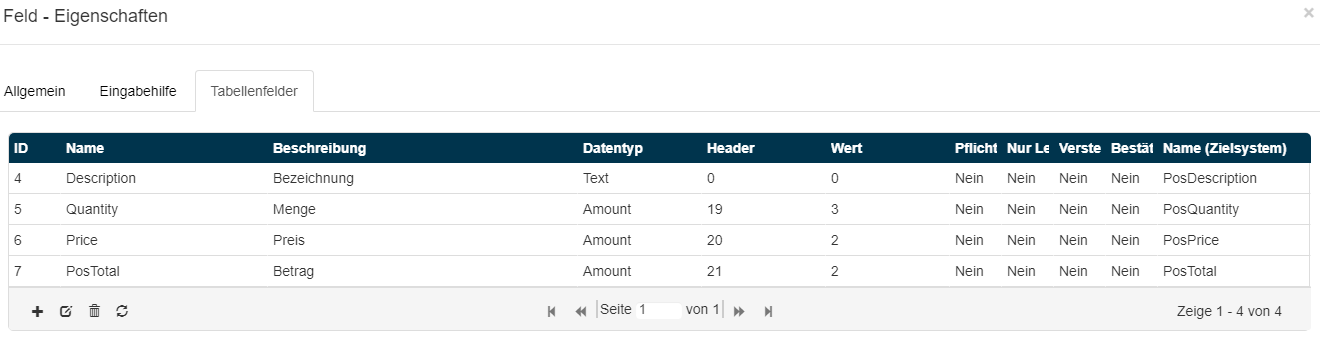
Mit einem Doppelklick auf die Positions-Spalte Quantity (Menge) öffnet sich der Konfigurationsdialog für dieses Spaltenfeld:
In dem Feld Überschriften Lokator wird der entsprechend konfigurierte Lokator für die Erkennung der Mengen-Überschriften hinterlegt.
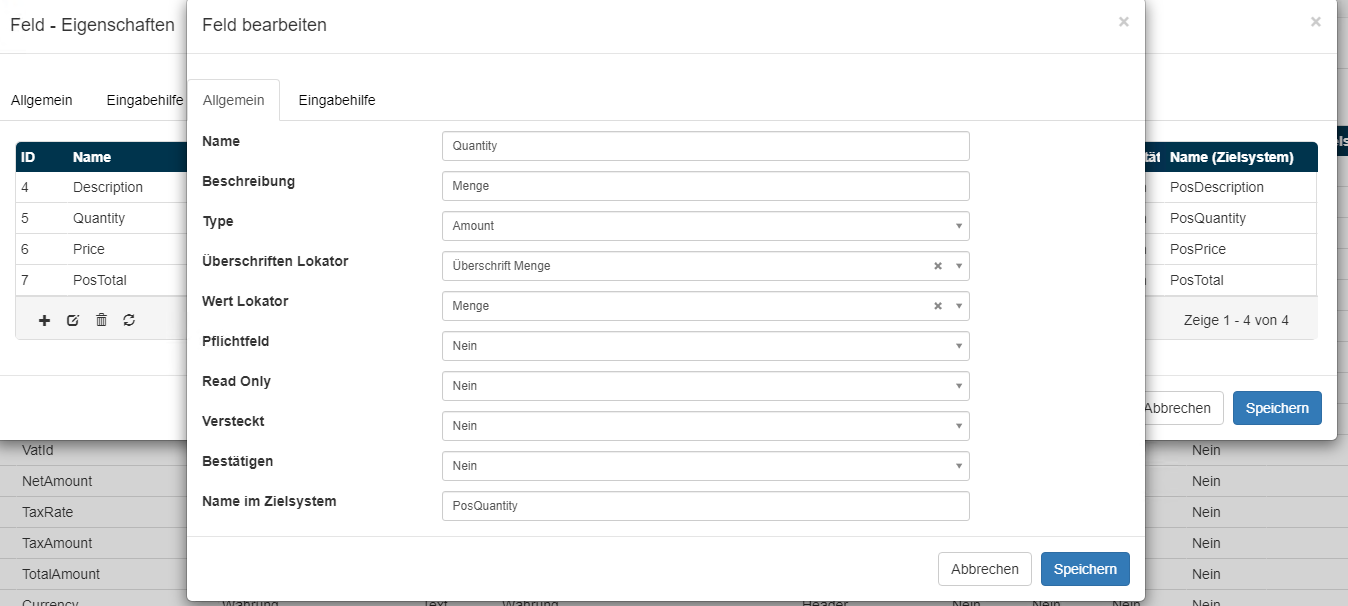
Nachdem für alle Spalten der Positions-Tabelle des Positionsfeldes, der entsprechende Überschriften Lokator konfiguriert worden ist, muss auf dem Reiter Allgemein für das Positionsfeld im Feld Lokator noch der Positions-Lokator konfiguriert werden.
Lokator: Search for line items
Der Lokator Search for line items findet Positionszeilen auf Dokumenten anhand entsprechender Spalten-Überschriften und unter diesen Spalten befindlichen Werten.
Die Suche nach Positionen ist im ausgelieferten Invoice-Template bereits konfiguriert.
Die Positions-Suche in Squeeze benötigt entsprechende Lokatoren mit deren Hilfe die Spaltenüberschriften der Positions-Tabelle gefunden werden.
Konfiguration einer Standard-Positions-Suche für Eingangsrechnungen:
Die Lokatoren für die Suche nach Spaltenüberschriften können als KeyWord to Value konfiguriert werden.
Konfigurations - Beispiel für den Lokator der Spalte Menge:
Konfigurations - Beispiel für den Lokator der Spalte Einzelpreis:
Konfigurations - Beispiel für den Lokator der Spalte Positionsgesamtpreis:
Die konfigurierten Suchbegriffe können je nach Anwendungsfall entsprechend angepasst und/oder erweitert werden.
Diese Lokatoren können in der Konfiguration für das Positions-Tabellenfeld hinterlegt werden.
Mit einem Doppelklick auf die Positions-Spalte Quantity (Menge) öffnet sich der Konfigurationsdialog für dieses Spaltenfeld:
In dem Feld Überschriften Lokator wird der entsprechend konfigurierte Lokator für die Erkennung der Mengen-Überschriften hinterlegt.
Nachdem für alle Spalten der Positions-Tabelle des Positionsfeldes, der entsprechende Überschriften Lokator konfiguriert worden ist, muss auf dem Reiter Allgemein für das Positionsfeld im Feld Lokator noch der Positions-Lokator konfiguriert werden.
Stammdaten
Stammdaten
Stammdaten dienen in Squeeze zur Erkennung und Plausiblisierung von Merkmalen auf den jeweiligen Dokumententypen.
Stammdaten werden in Squeeze in der Datenbank als Tabelle angelegt. Dabei können beliebig viele unterschiedliche Spalten konfiguriert werden.
Es können unbegrenzt viele Stammdatentabellen angelegt werden.
Klassische Beispiele für Stammdatentabellen:
- Kreditoren
- Bestellnummern
- Mandanten
- Auftragsnummern
- Vertragsnummern
- ...
Squeeze kann die auf dem Dokument gefundenen Merkmale in den Stammdaten plausiblisieren und / oder auf zugehörige Werte umsetzen.
Die Stammdaten können auf verschiedene Art und Weise aktualisiert / gepflegt werden:
- intervallgesteuerter CSV-Import
- Webservice
- Datenbankscript
- manuelle Stammdatren-Erweiterung über den Squeeze-Webclient
Anlegen einer neuen Stammdatentabelle im Webclient
das Anlegen einer neuen Stammdatentabelle in Squeeze muss initial via CSV-Upload aus dem Webclient erfolgen.
Beim Klick auf den Reiter Stammdaten öffnet sich der Dialog für die Stammdatenkonfiguration.
Folgende Stammdatentabellen werden aktuell mit dem Invoice Template ausgeliefert.
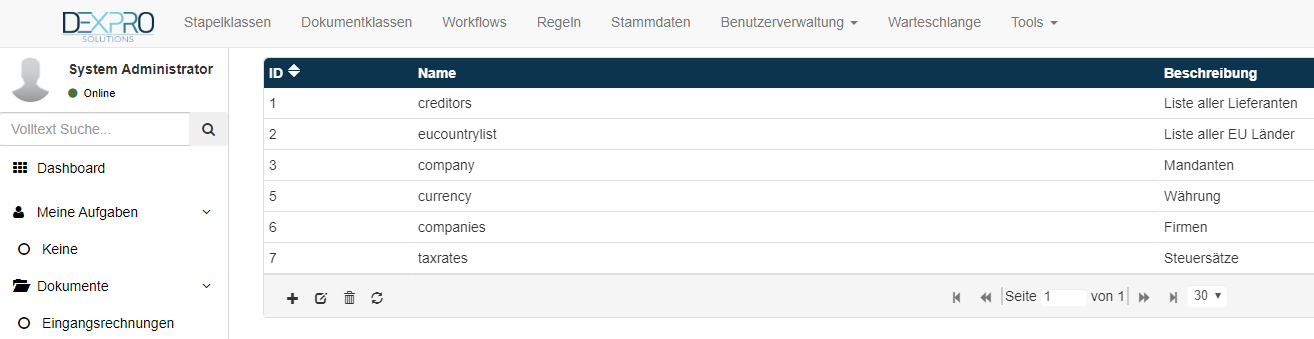
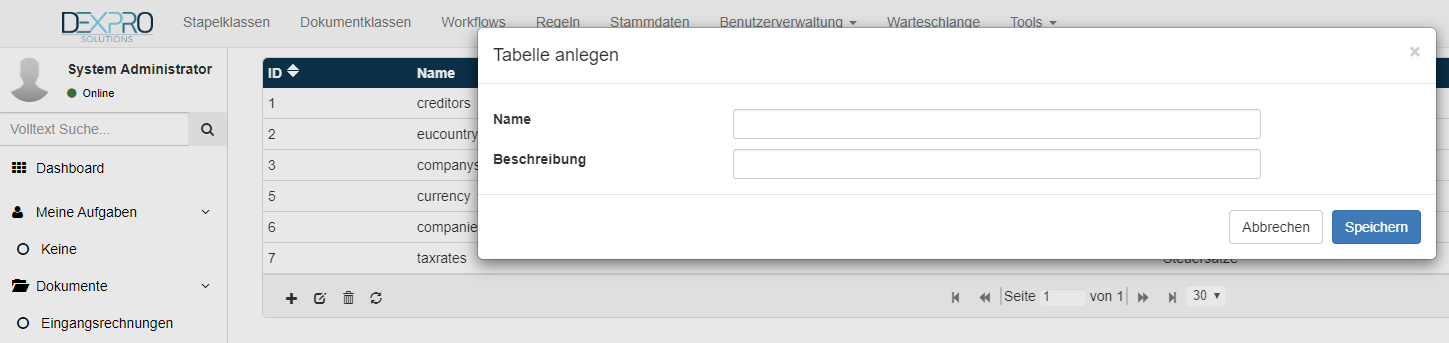
Eine neue Stammdatentabelle wird über das + Symbol angelegt.
Im nächsten Dialog wird der technische Name und der Anzeigenamen angegeben.
Konfiguration und Initialisieren einer neuen Stammdatentabelle via CSV-Upload
Im Webclient wird die Konfiguration der Spalten für diese Stammdatentabelle durchgeführt.
Stammdateneigenschaften
Mit einem Doppelklick auf den Eintrag in der Liste öffnet sich der Konfigurationsdialog für die Stammdatentabelle.
Spaltenkonfiguration
Zuerst werden die Spalten konfiguriert. Beim Klick auf den Reiter Spalten öffnet sich der Dialog zum Konfigurieren der Tabellenspalten.
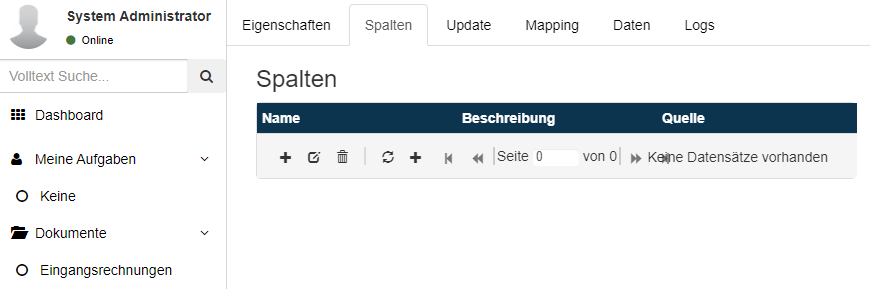
Mit dem + Symbol können neue Spalten hinzugefügt werden.
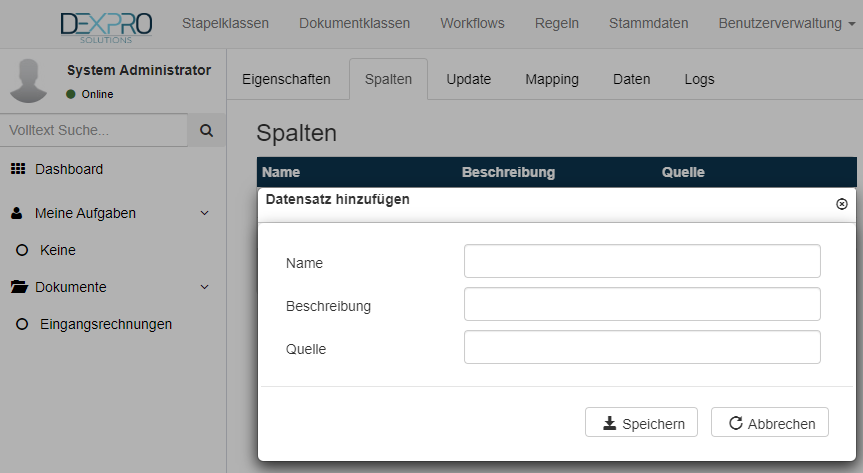
Hier werden folgende Informationen benötigt:
| Eigenschaft | Beschreibung |
| Name | Technischer Name für der Datenbankspalte |
| Beschreibung | Anzeigenamen für der Datenbankspalte |
| Quelle | externer Spaltenname (z.B. die Spaltenüberschrift in einer CSV-Datei) |
Jede Stammdatentabelle in Squeeze benötigt mindestens eine ID-Spalte.
Es können dann beliebig viele eigene Spalten definiert werden.
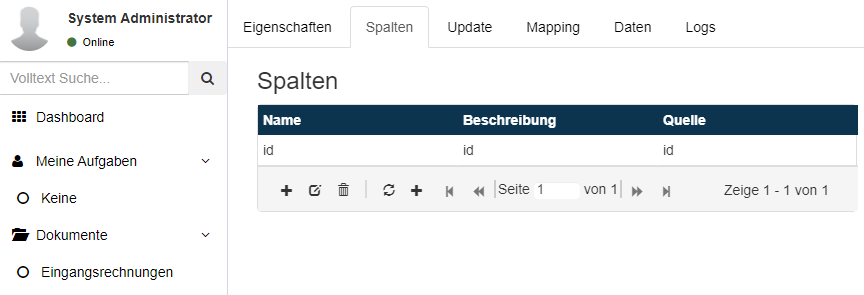
Test-Tabelle mit id-Spalte + 2 weitere Spalten:
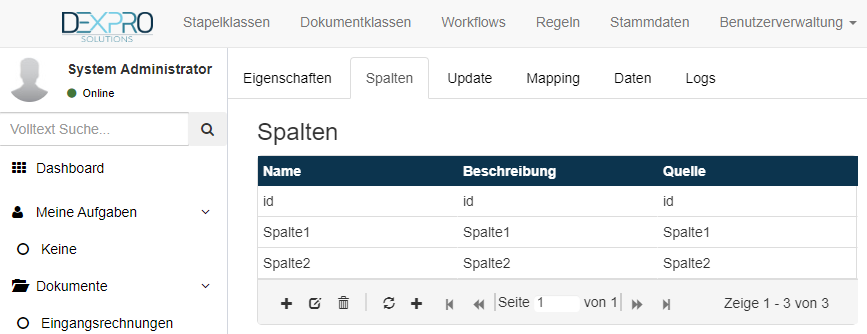
Nachdem die Spalten konfiguriert sind, wird eine CSV-Datei benötigt um die Tabelle auf dem Datenbankserver initial zu erstellen.
Die CSV Datei muss die selben Überschriften enthalten, wie in der Spaltenkonfiguration unter Quelle angegeben worden ist. Die Reihenfolge der Überschriften spielt keine Rolle.
WICHTIG: die Schreibweise der Spaltenüberschriften in der CSV-Datei ist case-sensitive. Das bedeutet Groß-Kleinschreibung ist relevant.
CSV-Datei Beispiel für die obige Tabelle:

Für die Werte-Zeilen müssen keine ID´s angegeben werden. Die ID Spalte ist eine Auto-Inkrement Spalte und erzeugt eigene fortlaufende ID´s beim Upload.
Nachdem die CSV-Datei erstellt wurde kann die Initialisierung der neuen Stammdatentabelle erfolgen mit einem Klick auf den Reiter Update.
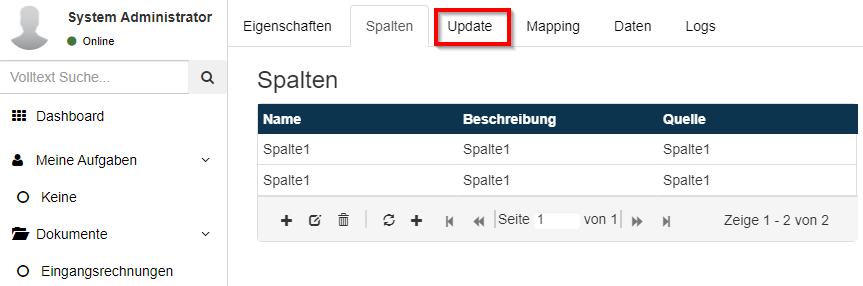
Im sich daraufhin öffnenden Dialog wird der Pfad zur CSV-Datei angeben, der Dateityp und der verwendete Spaltentrenner.
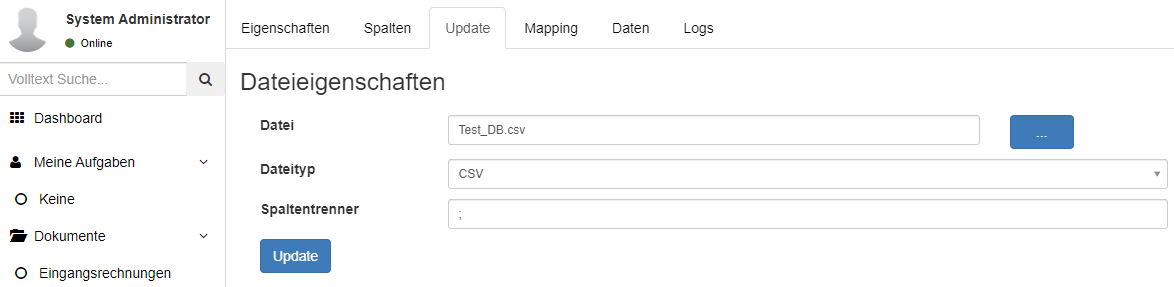
Mit einem Klick auf den Update Button wird die neue Stammdatentabelle angelegt und die Werte aus der CSV-Datei (falls angegeben) werden eingetragen.
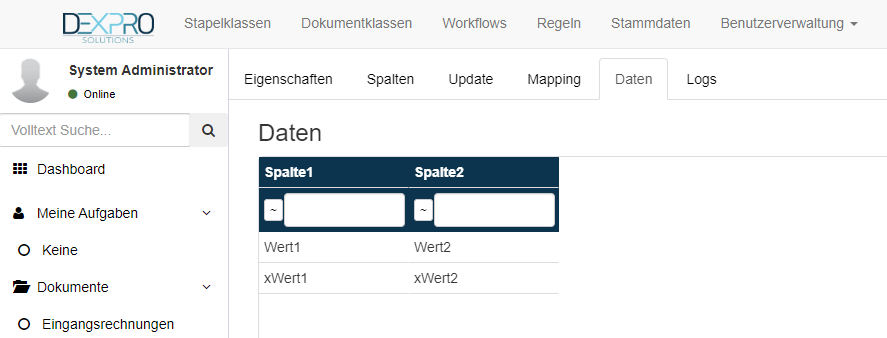
Die übergeben Werte können mit einem Klick auf den Reiter Daten geprüft werden.
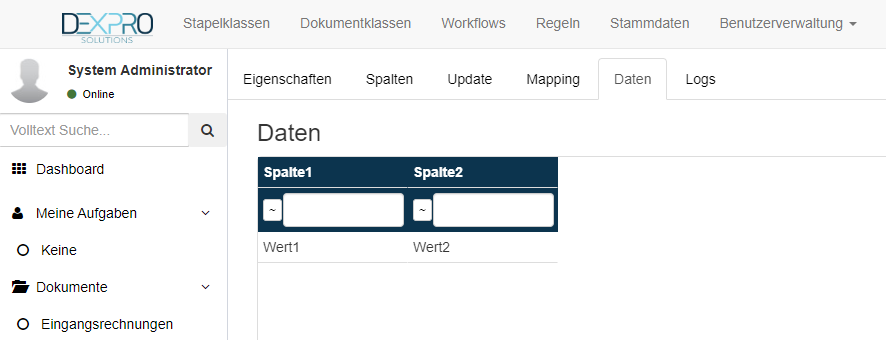
Nach einem Upload werden die Werte nicht sofort angezeigt, in diesem Fall kann man die Aktualisierung über folgendes Symbol in der Symbolleiste am unteren Bildschirmrand ausführen.
Daten hinzufügen
Mit dem Webclient können manuell mit dem + Symbol weitere Werte hinzugefügt werden.
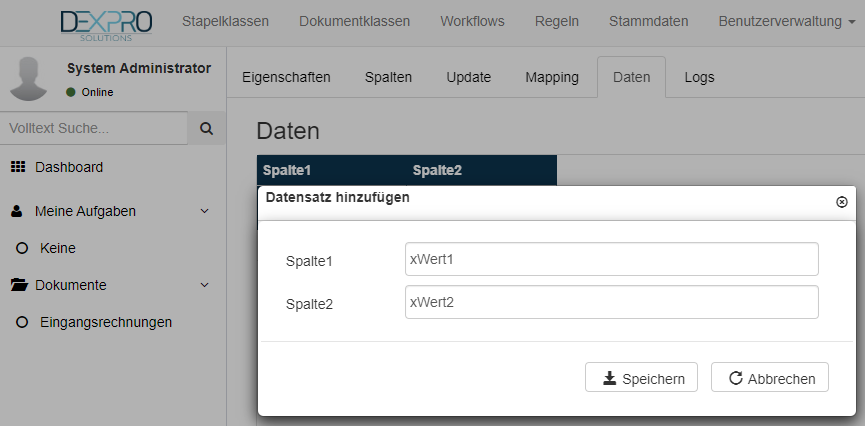
Den neuen Datensatz mit dem Speichern Button bestätigen.
Intervall-gesteuerte Aktualisierung der Stammdaten mittels CSV-Upload
Die Daten in Stammdatentabellen können jederzeit via CSV-Upload upgedatet werden.
Im Hintergrund wird dabei eine neue Stammdatentabelle erstellt wodurch während der Aktualisierung die Ursprungstabelle weiterhin zur Verfügung steht.
Zum Ende der Aktualisierung wird die Ursprungstabelle durch die aktualisierte Tabelle ersetzt.
Jobs
Zeitlich gesteuerte Aufgaben
Email-Verarbeitung
Um regelmäßig auf neue Emails zu prüfen, muss eine geplante Aufgabe eingerichtet werden.
Unter Windows können dafür die geplanten Tasks genutzt werden.
Unter Linux erfolgt die Einrichtung mit Hilfe von cron Jobs.
Einrichtung unter Windows
Unter Windows kann ein geplanter Task zur Regelmäßigen Prüfung der konfigurierten Postfächer genutzt werden.
Um einen neuen Task einzurichten müssen folgende Schritte durchgeführt werden:
1. Aufgabenplanung öffnen
Es kann eine eigener Unterordner für Squeeze aufgaben erstellt werden, wenn dies gewünscht ist
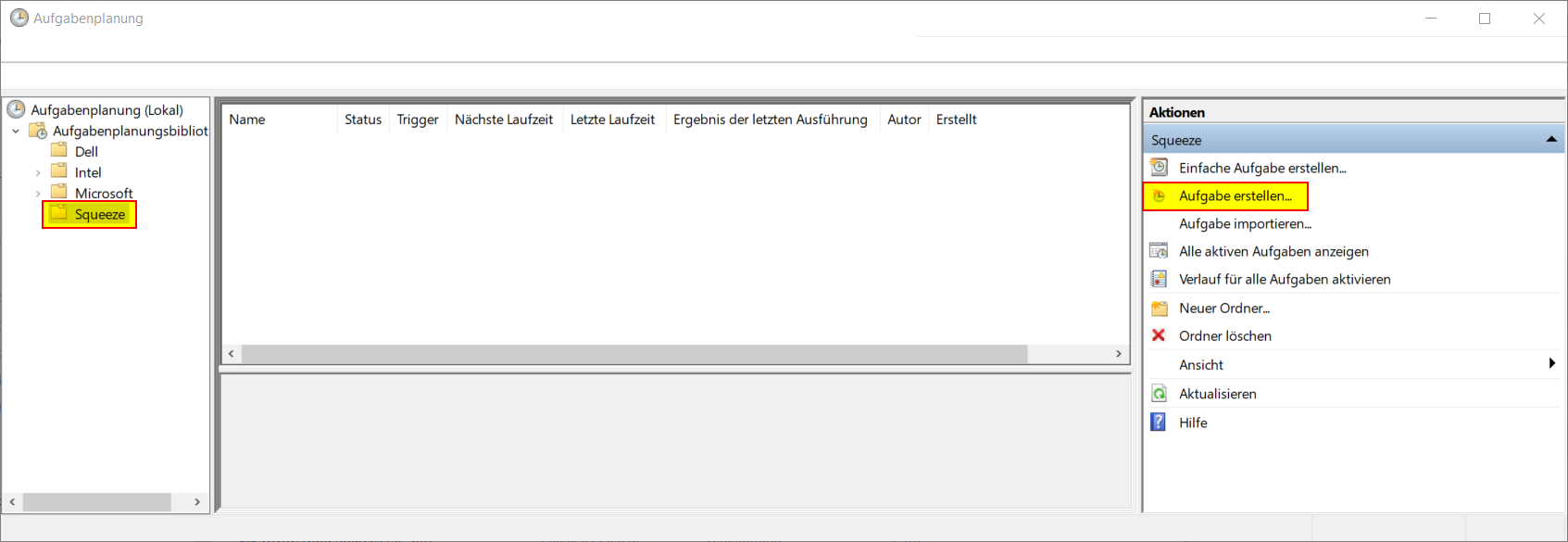
Auf der rechten Seite kann über den Menüpunkt "Aufgabe erstellen..." die Aufgabe für den Import der Emails angelegt werden.
2. Aufgabe erstellen
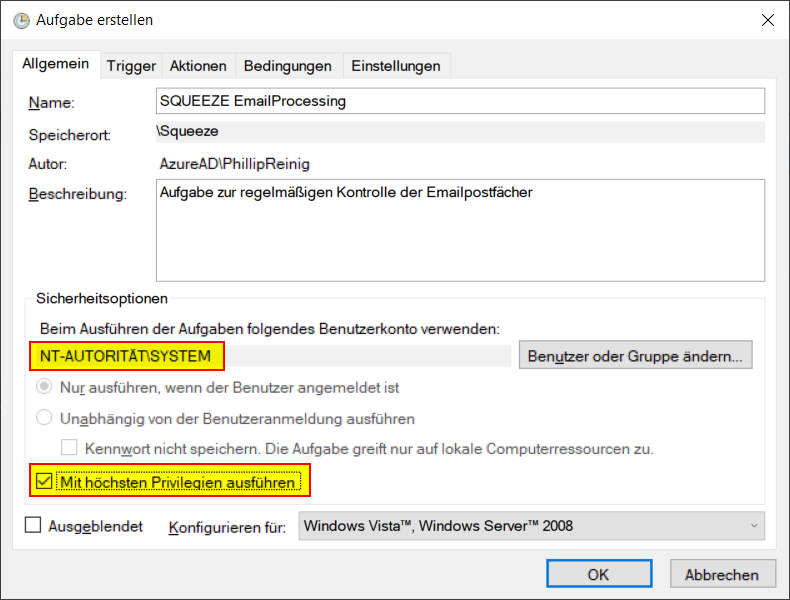
Der Name und die Beschreibung ist natürlich frei wählbar.
Damit die Aufgabe unabhängig von der Anmeldung eines Benutzers ausgeführt wird und auch unabhängig von eventuellen Passwortänderungen ist, hat sich bewährt, das System Konto auszuwählen.
Die Aufgabe "mit höchsten Privilegien" zu starten hat sich ebenfalls bewährt.
3. Trigger/Zeitpunkt festlegen
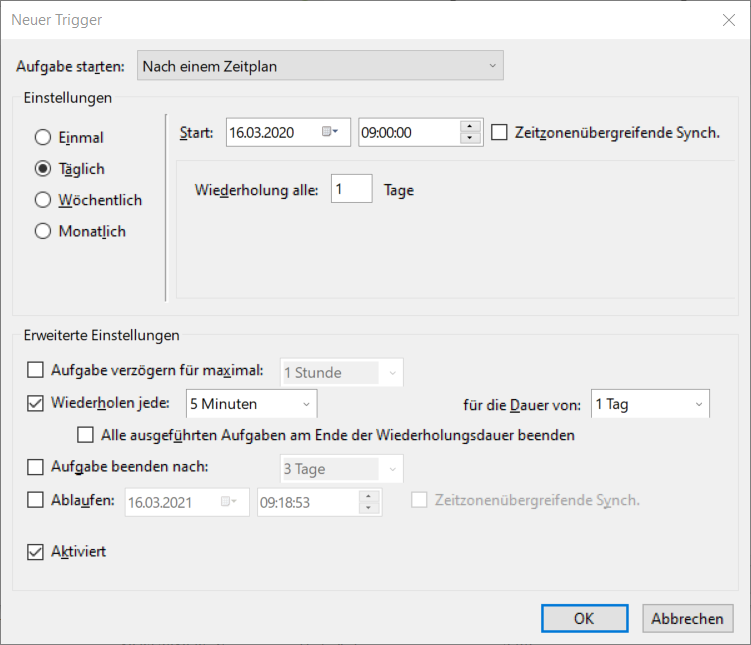
Das Intervall in dem die Emails abgerufen werden sollen ist ebenfalls frei definierbar.
Bewährt hat sich ein Intervall von 5 Minuten im Produktivsystem. Für Testsysteme kann dieser Intervall natürlich auch kleiner gewählt werden, wenn schnell und viel getestet werden soll.
4. Aktion festlegen
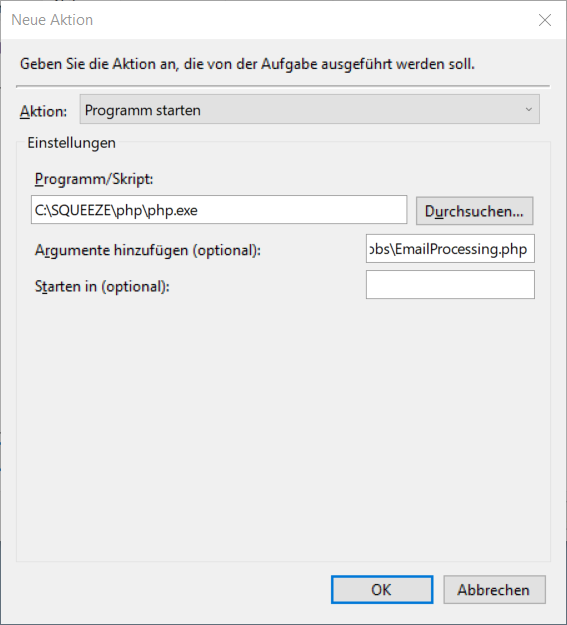
Als Programm muss die php.exe der Squeeze Installation ausgewählt werden.
Als Argumente müssen zwei Werte angegeben werden:
- - Pfad zur EmailProcessing.php z.B. C:\SQUEEZE\htdocs\jobs\EmailProcessing.php
- - Mandant für den die Emails abgerufen werden sollen z.B. client.squeeze.net
Die vollständige Angabe der Argumente lautet also wie folgt:
C:\SQUEEZE\htdocs\jobs\EmailProcessing.php client.squeeze.net
Datenbank Backup und Restore
Backup
Das sichern der SQUEEZE Datenbank(en) ist ein wichtiger Punkt der Administration. Um Sicherzustellen, dass im Fehlerfall nicht alle Daten verloren gehen, muss eine regelmäßiges Backup der Datenbanken durchgeführt werden.
Für MariaDB und MySQL kann folgender Befehl genutzt werden:
D:\SQUEEZE\mariadb\bin\mysqldump.exe --user=root --password="" --host=127.0.0.1 --protocol=tcp --port=3306 --default-character-set=utf8 --routines --events --databases "datenbankname" --result-file="D:\Squeeze\Backup\datenbank.sql"Der Schalter --databases ist nicht nur für die Selektion der Datenbank verantwortlich, sondern steuert ebenfalls, ob ein Create Statement des Schemas in den dump exportiert werden soll. Soll das Create Statement nicht erstellt werden, muss der Schalter --databases entfernt werden.
Backup aller Datenbanken
Um alle Datenbanken eines Servers zu sichern kann der folgende Befehl genutzt werden
mysqldump --user=root --password="" --host=127.0.0.1 --protocol=tcp --port=3306 --default-character-set=utf8 --routines --events --all-databases --result-file="D:\Squeeze\Backup\alle_datenbank.sql"Entscheidend ist der Schalter --all-databases
Dieser Schalter erfordert keine weiteren Parameter.
Die Aufgabe des Backups sollte zeitlich geplant werden. Dazu kann die Aufgabenplanung des Betriebssystems genutzt werden.
Die Parameter sind natürlich entsprechend der Installation anzupassen.
Restore
Um eine Datenbank aus einer Sicherung wiederherzustellen kann dieser Befehl genutzt werden:
Sollte die Datenbank bereits bestehen, werden hiermit alle vorhandenen Daten mit denen des Backups überschrieben.
D:\SQUEEZE\mariadb\bin\mysql.exe -u root -p "datenbankname" < "D:\Squeeze\Backup\datenbank.sql"Da jeder Mandant seine eigene Datenbank hat, ist die Aufgabe je Mandant/Datenbank zu planen.
Exportschnittstellen
Otris Documents SOAP
Eine der wohl am häufigsten genutzten Schnittstellen in Verbindung mit Squeeze ist die Otris Documents SOAP Schnittstelle.
Diese Schnittstelle bietet die Möglichkeit bidirektional mit dem Documents System zu interagieren.
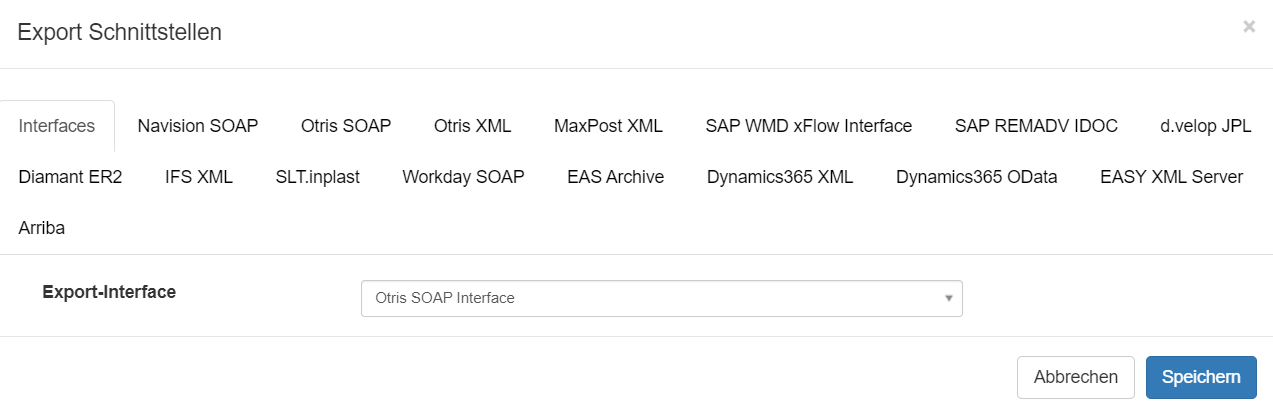
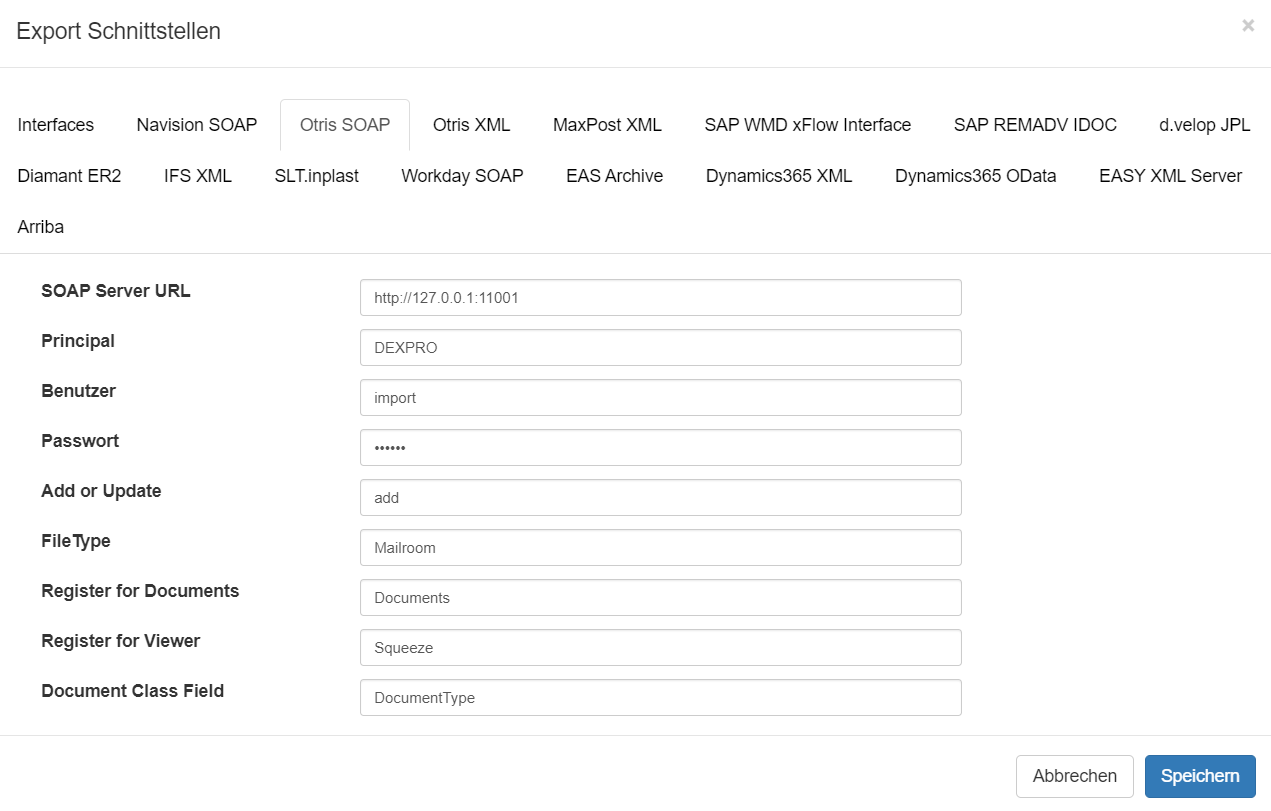
Konfiguration
Um ein Documents System per SOAP anzusprechen und Aktionen auszuführen, muss an der Squeeze Dokumentenklasse ein Export definiert werden:
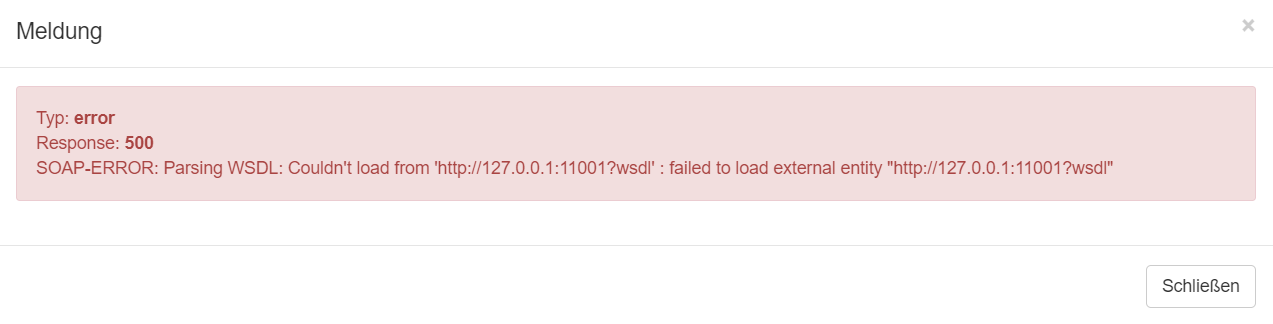
Beim Speichern der Konfiguration wird versucht eine Verbindung zum Server herzustellen. Gelingt dieser Verbindungsaufbau nicht erscheint die Fehlermeldung in einem neuen Dialog, wie hier zu sehen ist:
Wenn die Verbindung jedoch hergestellt werden konnte, wird die Konfiguration zu den definierten Exportschnittstellen hinzugefügt.
Fehler wenn keine Internetverbindung besteht
Die mit Documents ausgelieferte WSDL verweist auf ein Schema, welches bei W3C liegt. Sollte keine Internetverbindung bestehen, führt das zu einem Fehler, da das Schema nicht geladen werden kann. Um diesen Fehler zu umgehen und auf eine Interverbindung verzichten zu können, kann folgender Workaround genutzt werden:
Sicherung der WSDL erstellen
Im Soap Server Verzeichnis von Documents sollte eine Sicherung der Originalen WSDL erstellt werden:
Verweis zum Schema anpassen
in der DOCUMENTS.wsdl muss nun der Verweis so angepasst werden dass auf eine xsd verwiesen wird, die im lokalen netzwerk erreichbar ist. Am einfachsten ist hier, auf den Documents Server selbst zu verweisen (z.B. mittels IP des Documents-Servers)

Die xop.xsd muss nun noch im public root Verzeichnis des Documents Servers abgelegt werden, damit diese auch für Squeeze erreichbar ist.
Sobald diese Schritte erfolgt sind, sollte der Verbindungsaufbau mit Documents möglich sein.
SharePoint API
Diese Schnittstelle bietet die Möglichkeit bidirektional mit dem SharePoint System zu interagieren.
Kompatibilität
Konfiguration
Um ein Sharepoint System per REST/OData anzusprechen und Aktionen auszuführen, muss an der Squeeze Dokumentenklasse ein Export definiert werden:
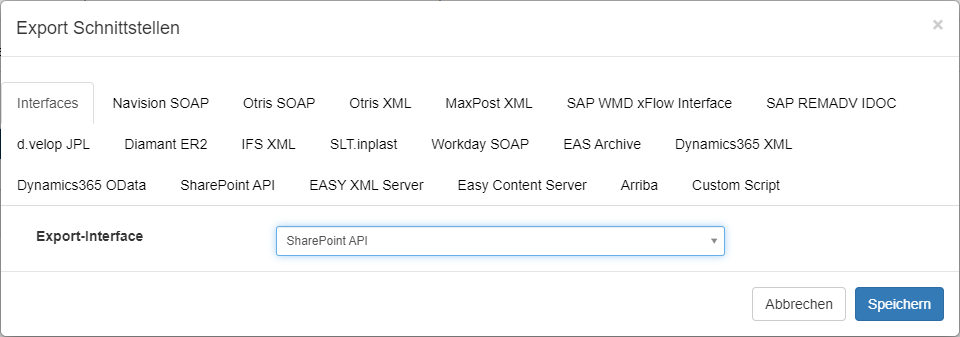
Authentifizierung
Meist wird als Authentifizierungsart die Benutzerauthentifizierung genutzt:
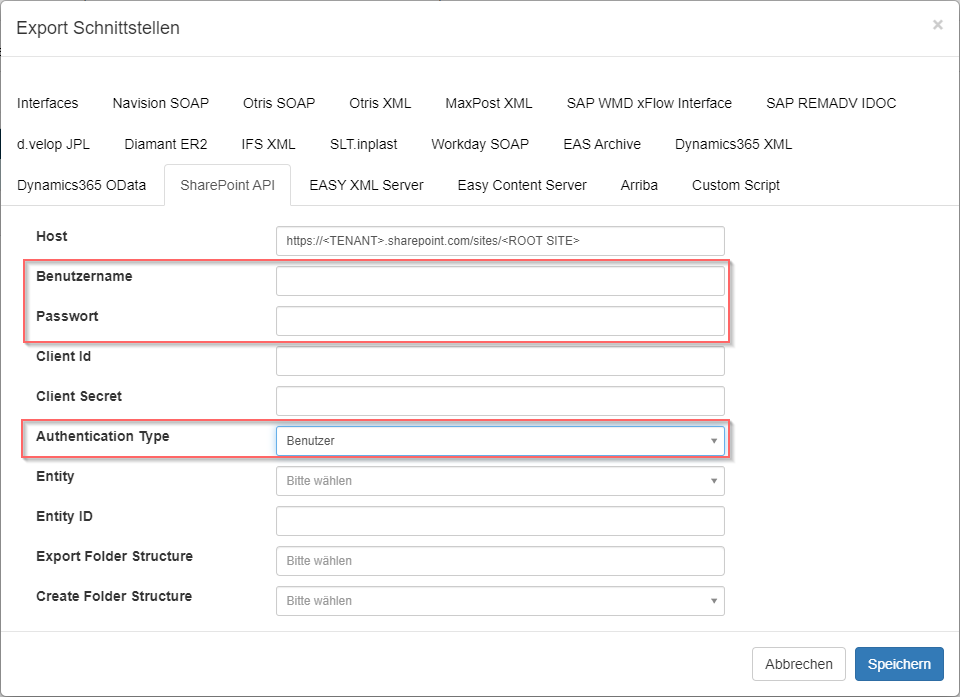
Beim Authentication Type ist "Benutzer" auszuwählen und die Felder "Benutzername" sowie "Passwort", eines Benutzers der dem SharePoint System bekannt ist, auszufüllen.
Die Felder "ClientId" sowie "Client Secret" sind nur bei dem Authentication Type "App" relevant.
Entität
Um in das System zu exportieren, muss zunächst die Entität bestimmt werden, in welche exportiert werden soll:
- Dokumentenbibliothek?
- Liste?
Nachdem dies ausgewählt wurde, kann im Feld "Entity ID" die entsprechende Liste oder Dokumentenbibliothek angegeben werden in der letztendlich der Export stattfindet.
Für Dokumentenbibliotheken muss der technische Name angegeben werden, bei Listen der Anzeigename.
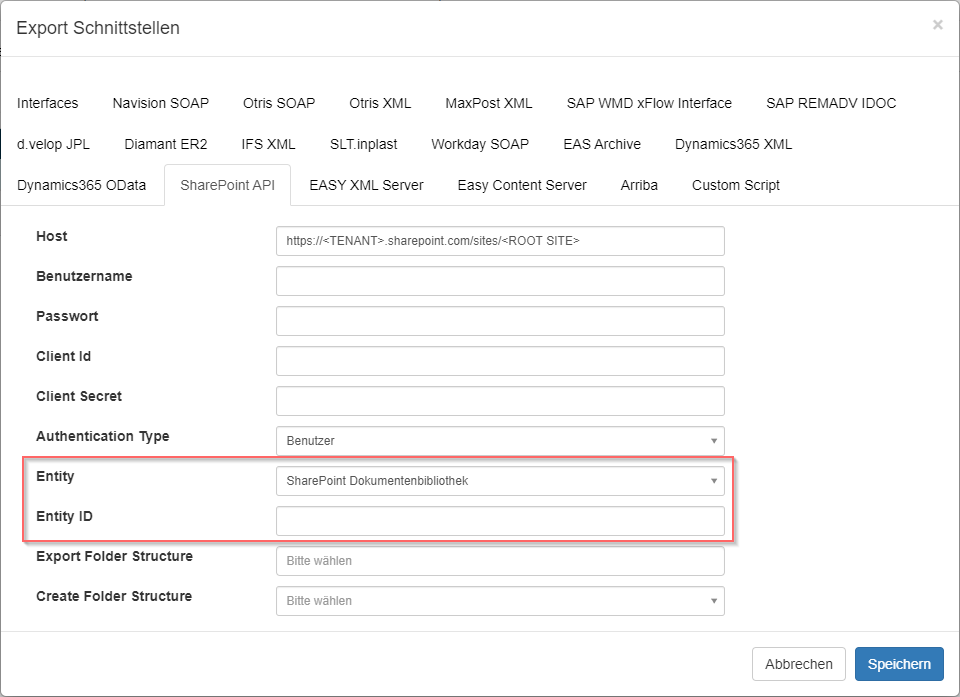
Dokumentenbibilothek
Für die Dokumentenbibliotheken gibt es noch zwei weitere Einstellungen.
Export Folder Structure gibt den Pfad in der Dokumentenbibliothek an, in den exportiert werden soll. Dieser kann dynamisch aus Feldwerten der Felder der jeweiligen Dokumentenklasse angegeben werden. Hierzu in dem Feld den Pfad von links nach rechts mit Feldern der Dokumentenklasse auswählen:
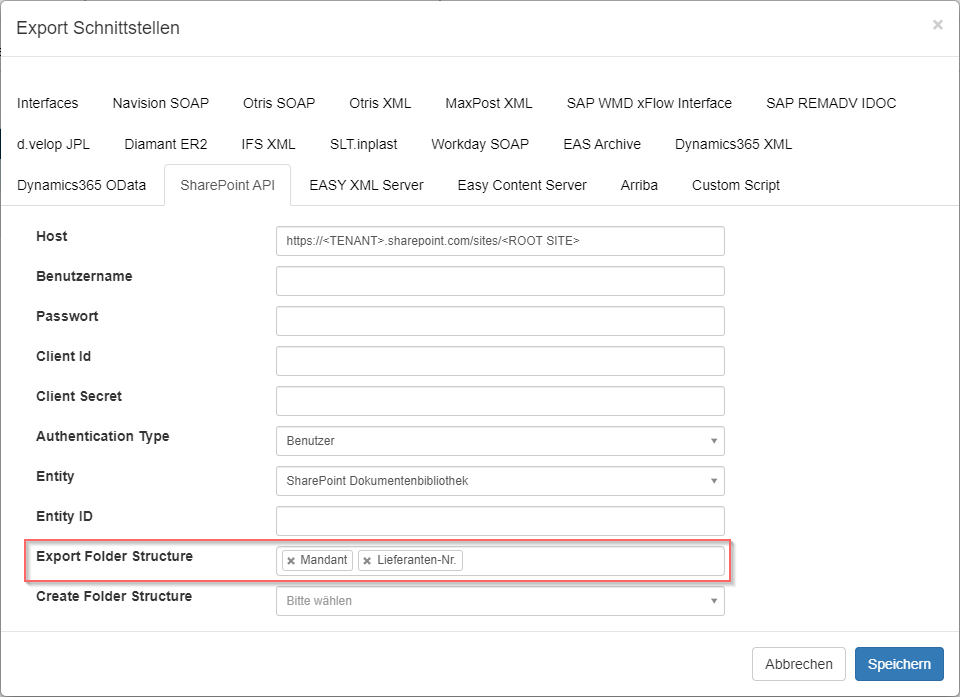
Die letzte Einstellungsmöglichkeit gibt an, ob SQUEEZE den Export-Pfad erstellen soll, falls dieser nicht vorhanden ist.
Ist der Pfad nicht vorhanden und SQUEEZE soll diesen nicht erstellen, wird ein Fehler beim Export eines Vorgangs durch den SharePoint zurückgegeben.
Feldwerte exportieren
Mit den Namen im Zielsystem (externe Feldnamen) können die Spalten eines Listeneintrages bzw. weitere Spalten/Details eines Eintrags einer Dokumentenbibliothek angegeben werden.
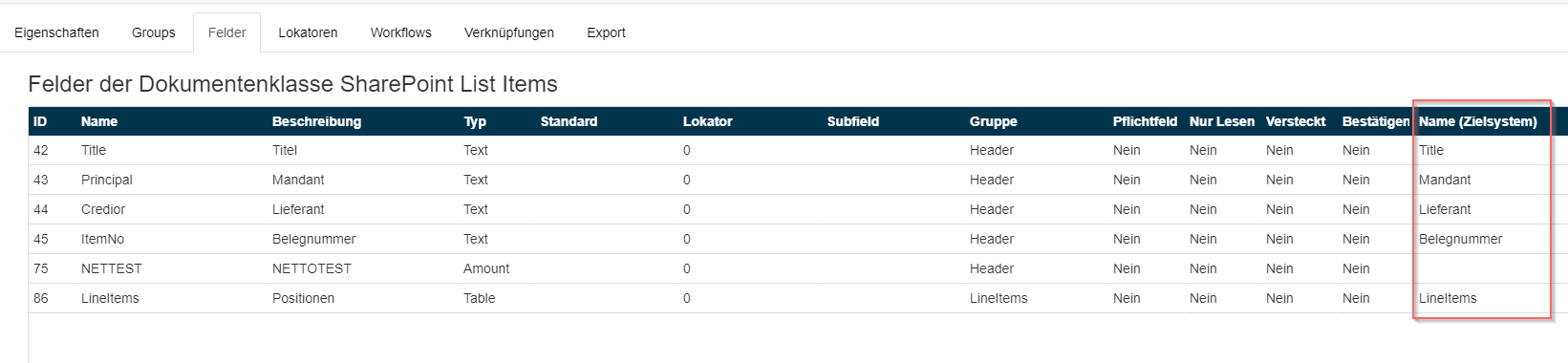
Diese können in der Dokumentenklasse bei den Feldern angegeben werden.
Positionen exportieren
Jedes "Table"-Feld (in dem Beispiel die "LineItems") kann als JSON exportiert werden, wenn ein Zielname definiert wurde.
Dabei muss das Zielfeld mehrzeilig sein.
Reservierte Zielnamen
Der reservierte Zielname "ContentTypeID" gibt das SQUEEZE Feld an, welches den Inhaltstyp des exportierten Vorgangs angibt. Hier reicht es, den Namen anzugeben, SQUEEZE holt sich die ID selbst vom SharePoint.
Hierbei handelt es sich um die globalen Inhaltstypen (Root) des SharePoints.
SharePoint Export via Graph API [ENG]
Mit dieser Schnittstelle kann die offizielle SharePoint Graph API von Microsoft integriert werden, um mit einem SharePoint Verzeichnis zu kommunizieren.
Dafür ist eine registrierte Microsoft Azure Applikation notwendig.
Integrierte Services der Graph API
- Dokumente in ein zuvor definiertes SharePoint Verzeichnis hochladen
Zugangsberechtigungen in Microsoft Azure
Benötigte Applikationen
Erstellen Sie zwei neue Applikationen in Microsoft Azure.
Eine dient zu administrativen Zwecken, die Andere für den Nutzer selbst.
Zur Bewilligung der folgenden Rechte wird ein User mit Administrationsrechten in Microsoft Azure benötigt.
Die Rechte können im Menü "API Permissions" (im deutschen Client: "API-Berechtigungen") hinzugefügt werden:
- Die Admin-Applikation benötigt die API-Berechtigung
Sites.FullControl.All - Die Nutzer-Applikation benötigt die API-Berechtigung
Sites.Selected
In der Admin-Applikation muss ein User im Menü Certificates & secrets erstellt werden.
Dieser User ist nötig, um die Nutzer-Applikation mit den nötigen Rechten auszustatten.
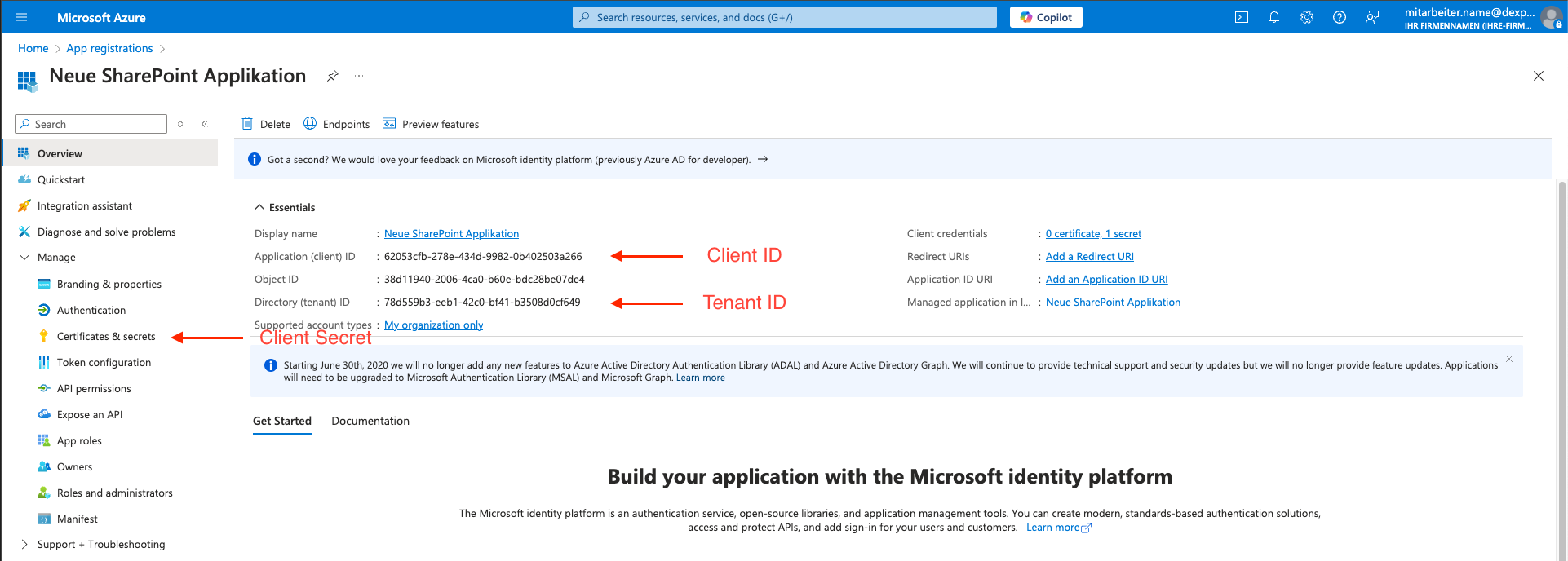 Abbildung - Registrierte Microsoft Applikation "Neue SharePoint Applikation"
Abbildung - Registrierte Microsoft Applikation "Neue SharePoint Applikation"
Rechte für die Nutzer-Applikation
Für diesen Abschnitt benötigen Sie die Daten der zuvor erstellten Admin-Applikation.
Die Nutzer-Applikation muss zwingend die Berechtigungen auf die von Ihnen gewünschte SharePoint Seite erhalten.
Dafür ist die Id der SharePoint-Seite notwendig.
Bedauerlicherweise ist es zum aktuellen Zeitpunkt nicht möglich, die SharePoint Seiten Id über die grafische Oberfläche ausfindig zu machen (Stand März 2025).
Daher wird wie folgt beschrieben, wie die Id der Seite ermittelt und die Erteilung der Berechtigung per curl Requests erteilt werden kann.
Einloggen
Zu erst benötigen Sie einen Bearer Token, um sich an der API zu authentifizieren. Dies erfolgt durch folgenden Request:
- URL: https://login.microsoftonline.com/<TENANT_ID>/oauth2/v2.0/token
- HTTP Methode: POST
- Request Body Typ: form-data
- Request Body:
- client_id:<CLIENT_ID>
- client_secret:<CLIENT_SECRET>
- grant_type:client_credentials
- scope:https://graph.microsoft.com/.default
Statt "<TENANT_ID>", "<CLIENT_ID>" und "<CLIENT_SECRET>" müssen Sie Ihre jeweiligen Daten verwenden.
Wo Sie diese Daten finden steht in den Abschnitten "Feld Tenant Id", "Feld Client Id" und "Feld Client Secret" dieses Artikels.
Anbei der cURL Befehl:
curl --location 'https://login.microsoftonline.com/<TENANT_ID>/oauth2/v2.0/token' \--form 'client_id="<CLIENT_ID>"' \--form 'client_secret="<CLIENT_SECRET>"' \--form 'grant_type="client_credentials"' \--form 'scope="https://graph.microsoft.com/.default"'Site Id erhalten
- URL: https://graph.microsoft.com/v1.0/sites/<TENANT>.sharepoint.com/sites/<NAME>
- HTTP Methode: GET
- Header: "Authorization: Bearer <BEARER_TOKEN>"
Anbei der cURL Befehl:
curl --location 'https://graph.microsoft.com/v1.0/sites/<TENANT>.sharepoint.com:/sites/<NAME>' \--header 'Authorization: Bearer <BEARER_TOKEN>'Die Response dieses Requests ist etwas umständlicher zu lesen, ein Beispiel:
{
"@odata.context": "https://graph.microsoft.com/v1.0/$metadata#sites/$entity",
"createdDateTime": "2025-03-13T00:11:15.033Z",
"description": "TestDescription",
"id": "<TENANT>.sharepoint.com,808dec17-aa6d-4158-a9fe-8caa8d909dff,81f7ad14-65ae-46c2-b0fc-10602e9401cc",
"lastModifiedDateTime": "2025-03-13T07:07:19Z",
"name": "TestName",
"webUrl": "https://<TENANT>.sharepoint.com/sites/<SITE_NAME>",
"displayName": "TestName",
"root": {},
"siteCollection": {
"hostname": "<TENANT>.sharepoint.com"
}
}
Die Site Id in diesem Fall ist der Wert 808dec17-aa6d-4158-a9fe-8caa8d909dff.
Er befindet sich im Index "id" und ist der mittlere der Werte (wenn den Wert an seinen Kommata aufteilt).
Zugriffsrechte erteilen
Für die Zugriffsrechte benötigen sie die Client ID der Nutzer-Applikation und den Namen.
Diese setzen Sie an der Stelle von "<NUTZER_APPLIKATION_CLIENT_ID>" bzw. "<NUTZER_APPLIKATION_NAME>" ein.
Die Rechte zum Schreiben beinhalten auch die Leserechte.
- URL: https://graph.microsoft.com/v1.0/sites/<SITE_ID>/permissions
- HTTP Methode: POST
- Request Body Type: JSON
- Request Body:
-
{
"roles": [
"write"
],
"grantedToIdentities": [
{
"application": {
"id": "<NUTZER_APPLIKATION_CLIENT_ID>",
"displayName": "<NUTZER_APPLIKATION_NAME>"
}
}
]
}
-
Anbei der cURL Befehl:
curl --location 'https://graph.microsoft.com/v1.0/sites/<SITE_ID>/permissions' \
--header 'Authorization: Bearer <BEARER_TOKEN>' \
--header 'Content-Type: application/json' \
--data '{
"roles": ["write"],
"grantedToIdentities": [{
"application": {
"id": "<NUTZER_APPLIKATION_CLIENT_ID>",
"displayName": "<NUTZER_APPLIKATION_NAME>"
}
}]
}'Der Server gibt im Erfolgsfall eine Response mit dem Statuscode 201 zurück.
Da der Statuscode aussagekräftig genug ist, kann der Inhalt der Response vernachlässigt werden.
Konfiguration
Um diese Schnittstelle zu verwenden und Aktionen auszuführen, muss an der Squeeze Dokumentenklasse eine Export-Schnittstelle definiert werden.
Die benötigten Zugangsdaten entnehmen Sie aus der Nutzer-Applikation.
Authentifizierung
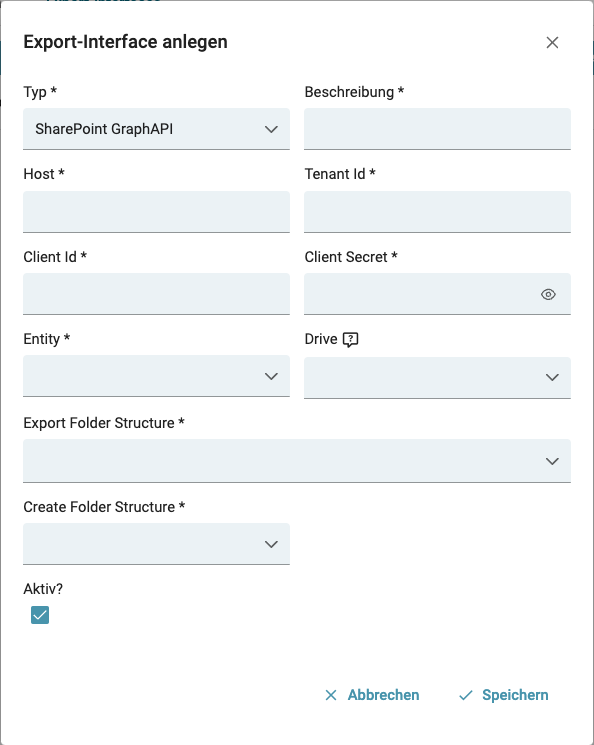
Abbildung - Export Interface SharePoint GraphAPI (WIP)
Feld Beschreibung
Für das Export Interface kann ein Name angegeben werden, im Feld Beschreibung.
Feld Host
In diesem Feld wird die Adresse zur SharePoint Seite hinterlegt. Diese hat folgendes Muster: <TENANT>.sharepoint.com/sites/<NAME>.
Feld Tenant Id
Die Tenant Id befindet sich in der Übersicht einer registrierten App. Eine Auflistung dieser Apps finden sie hier.
Um die Liste zu sehen müssen Sie eingeloggt sein.
Die Tenant Id wird auf der Seite auch "Directory (tenant) ID".
Feld Client Id
Die Tenant Id befindet sich in der Übersicht einer registrierten App. Eine Auflistung dieser Apps finden sie hier.
Um die Liste zu sehen müssen Sie eingeloggt sein.
Hier wird sie auch unter dem Begriff "Application (client) ID" geführt.
Feld Client Secret
Die Tenant Id befindet sich in der Übersicht einer registrierten App. Eine Auflistung dieser Apps finden sie hier.
Um die Liste zu sehen müssen Sie eingeloggt sein.
Das Client Secret wird innerhalb der registrierten App hinterlegt. Das dafür nötige Menü finden Sie in, in der ausgewählten App, unter dem Menü "Certificates & secrets".
Für das Erstellen eines Secrets müssen sie lediglich eine aussagekräftige Beschreibung angeben, und den Zeitraum, in welchem das Secret valide ist.
Das Client Secret wird bei Microsoft unter "Secret Value" geführt. Diese Information wird nur einmalig angezeigt, aus diesem Grund sollte es in einer sicheren Umgebung gespeichert werden.
Verwechseln Sie das Client Secret nicht mit "Secret Value".
Feld Entity
Über die Entity wird der Service ausgewählt, welchen Sie verwenden möchten:
Feld Export Folder Structure
Dateien werden alle in das Home Verzeichnis des SharePoint Verzeichnisses hochgeladen.
Um zu spezifizieren, in welche Verzeichnis Struktur ein Dokument abgelegt werden soll, können in dieser Auswahlliste mehrere Felder ausgewählt werden.
Die Felder werden durch ihre in SQUEEZE erkannten Daten ersetzt. So könnte beispielsweise die Auswahl des Feldes "IBAN" dazu führen, dass ein Dokument in das Verzeichnis der erkannten IBAN abgelegt wird (nicht in einem Verzeichnis mit dem Namen "IBAN").
Feld Drive
Bei der korrekten Eingabe von Host, Tenant ID, Client ID und dem Client Secret, wird im Feld Drive eine Liste von möglichen Verzeichnissen aufgeführt, welches als Home Verzeichnis des SharePoints dienen soll, das Sie auswählen müssen.
Feld Create Folder Structure
Diese Funktion erstellt beim Wert "Ja" ein Pfad Verzeichnis, auch wenn es vorher nicht existiert.
Sollte das Verzeichnis bereits existieren wird kein neues Verzeichnis erstellt.
Der Pfad für das Verzeichnis wird durch das Feld Export Folder Structure bestimmt.
Beim Wert "Nein" wird beim Export an Sharepoint geprüft, ob der Verzeichnis Pfad existiert.
Existiert das Verzeichnis, dann werden die verarbeiteten Dokumente hochgeladen (exportiert).
Existiert das Verzeichnis jedoch nicht, dann wird das Dokument nicht hochgeladen (nicht exportiert).
Es wird beim Export eine entsprechende Fehlermeldung ausgegeben.
Dadurch soll vermieden werden, das unerwartete Verzeichnisse erstellt werden und Dokumente ggf. verschwinden.
Beispiel
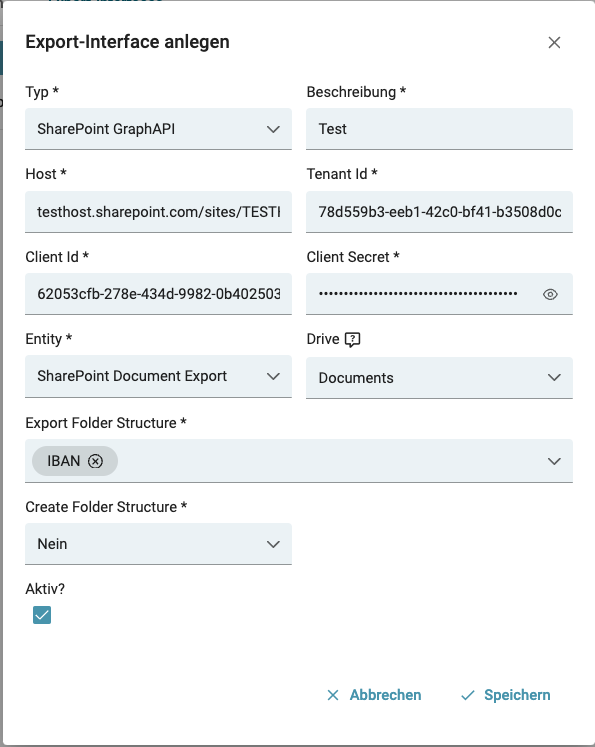
Abbildung - Beispiel ausgefülltes Formular für Export Interface (WIP)
Wenn wir eine neue Applikation in Microsoft Azure erstellt haben, rufen wir diese auf und erhalten folgende Ansicht.
Abbildung - Registrierte Microsoft Applikation "Neue SharePoint Applikation"
Auf dieser Abbildung ist zu sehen was die Client ID ist, sowie wo die Tenant ID zu finden ist.
Bei Auswahl des Menüs "Certificates & secrets" existiert ein kleiner Button mit dem Namen "New client secrets". Nachdem die nötigen Daten angegeben wurden erhalten wir einen neuen Eintrag:

Feldwerte / Metadaten exportieren
Um Feldwerte als Metadaten zu exportieren, beim Upload, müssen diese in der Dokumentenklasse angegeben werden.
Dafür muss das nötige Feld ausgewählt werden, und der entsprechende Wert muss im Feld "Name (Zielsystem)" eingetragen werden.
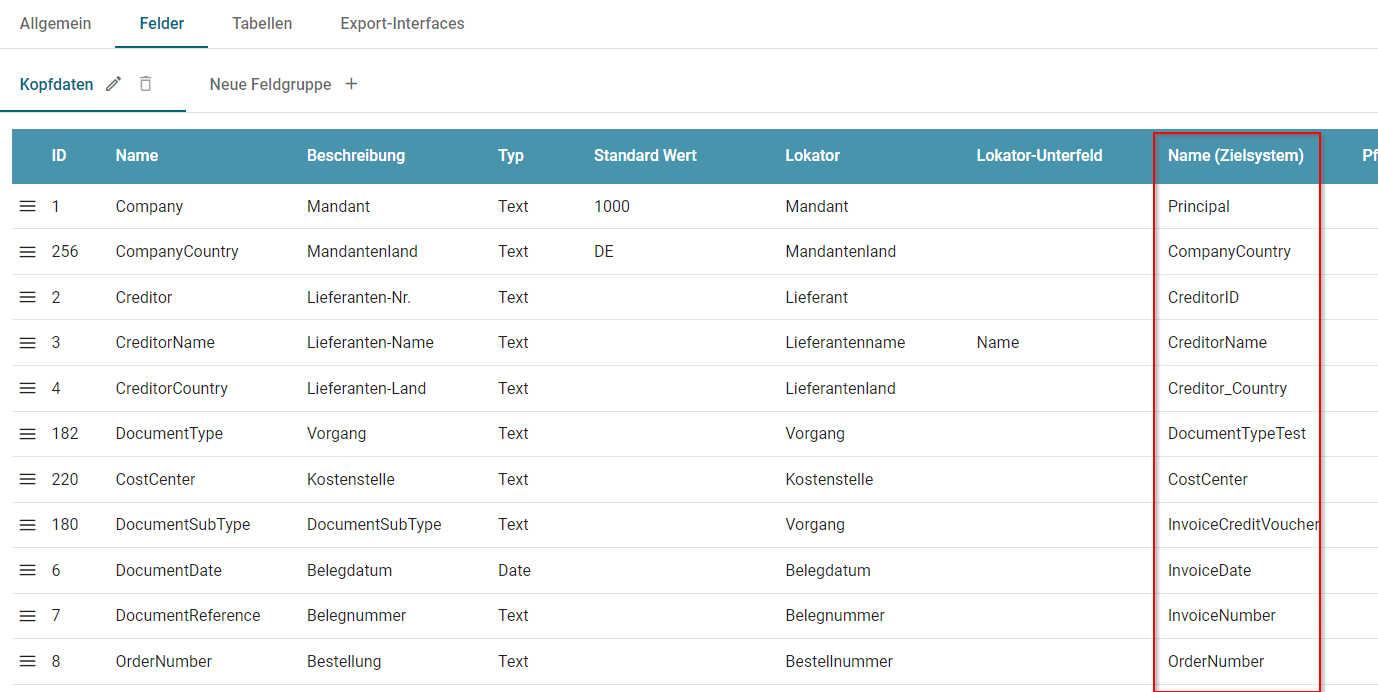 Abbildung - Kopfdaten-Felder der Dokumentenklasse
Abbildung - Kopfdaten-Felder der Dokumentenklasse
Benutzer und Rollen
Rollenfilter & Feldbedingungen
Rollenfilter
Rollenfilter (im Folgenden kurz "Filter") gehören zum Autorisierungskonzept von SQUEEZE und unterstützen bei feldbasierter Authorisierung von Dokumenten.
Mittels Filtern ist es möglich für unterschiedliche Benutzergruppen andere Dokumente (auch innerhalb einer Dokumentenklasse) zu berechtigen.
Konfiguration
Jeder Rolle können beliebig viele Filter hinzugefügt werden.
Ein Filter steht im Bezug zu einer Dokumentenklasse und berechtigt den Zugriff (lesend & schreibend) auf alle Dokumente dieser Klasse.
Auswertung
Rollenfilter werden mit einem logischen Oder ausgewertet. D. h., wenn einer Rolle mehrere Filter zu der selben Dokumentenklasse zugeordnet sind, dann reicht bereits eine positive Auswertung des ersten Filters (und seiner Feldbedingungen) aus, um Zugriff auf das Dokument zu erhalten.
Dieses Verhalten gilt auch dann, wenn ein Benutzer Mitglied mehrerer Rollen mit wiederum diversen Filtern ist.
Zusammengefasst: Ein Benutzer erhält Zugriff auf ein Dokument, sobald mindestens eine seiner Rollen über einen Rollenfilter den Zugriff gewährt.
Feldbedingungen
Soll nur auf eine Teilmenge der Dokumente einer Dokumentenklasse berechtigt werden, können Rollenfilter um Feldbedingungen ergänzt werden. Diese erlauben die Filterung von Dokumenten auf Basis ihrer Feldwerte.
Konfiguration
An einem Filter können beliebig viele Feldbedingungen definiert werden. Eine Bedingung ist zusammengesetzt aus:
- Dem Feld dessen Inhalt geprüft werden soll
- Dem Kompartor, der zur Prüfung genutzt wird
- Dem Vergleichswert (kann von einigen Komparatoren ignoriert werden)
Aktuell können nicht alle konfigurierbaren Filter korrekt ausgewertet werden.
Die Filterung auf ein Textfeld mit einem "Größer als" Komparator (bspw. "Lieferantenname größer als 20") würde zu einem Suchfehler führen.
Die Konfiguration solcher Filter ist zwar (noch) möglich, sollte aber vermieden werden.
SQUEEZE 1 unterstützt mehr Komparatoren als SQUEEZE 2. Sollten Sie einen Komparatoren nutzen, der nicht mehr unterstützt wird, kontaktieren Sie bitte den Support, wenn Sie migrieren möchten.
Auswertung
Feldbedingungen werden anders als Rollenfilter mit einem logischen Und verknüpft ausgewertet.
Es müssen also alle Bedingungen erfüllt sein, damit ein Rollenfilter den Zugriff auf ein Dokument gewährt.
Zusammenspiel mehrerer Rollenfilter
Wenn für einen Benutzer mehrere Rollenfilter (mit wiederum diversen Feldbedingungen) ausgewertet werden, dann spielen Rollenfilter ohne Feldbedingungen keine Rolle mehr und werden ignoriert.
Ein Beispiel:
- Eine Rolle hat zwei Filter. Der erste Filter hat keine Feldbedingungen. Der zweite Filter hat eine Feldbedingung.
- Bei der Auswertung dürfen Nutzer der Rolle nur Dokumente sehen, die durch den zweiten Filter freigegeben werden.
Zusammenspiel mit vererbten Rollen
Ist ein Nutzer Mitglied mehrerer Rollen (durch explizite Zuordnung oder Rollen-Vererbung), so werden Rollenfilter und Feldbedingungen dieser Rollen bei der Auswertung berücksichtigt.
Rollen
Rollen
Rollen können genutzt werden, um den Dokumentenzugriff zu verwalten und die Verwendung von Funktionen wie Benutzerverwaltung zu authorisieren.
Das zugrundeliegende Authorisierungskonzept ist RBAC.
Konfiguration
Es können beliebig viele Rollen angelegt werden. Jede Rolle verfügt über einen Namen und eine Beschreibung.
Außerdem muss jeder Rolle eine Eltern-Rolle zugeordnet werden. Durch diese Zuordnung entsteht eine Rollenhierarchie, welche bspw. genutzt werden kann, um Organisationsstrukturen abzubilden.
Benutzerzuordnung & Vererbung
Ein Benutzer kann zu beliebig vielen Rollen hinzugefügt werden.
Der zugeordnete Benutzer ist implizit Mitglied aller Sub-Rollen der zugeordneten Rolle.
Diese Vererbung forciert, dass Berechtigungen von Sub-Rollen auf die Eltern-Rolle übertragen werden. Mehr dazu im Abschnitt Rollenfilter & Feldbasierte Berechtigung
SQUEEZE Admin FAQ
Wie können alle Dokumente gelöscht werden?
Während einer Testphase kann es nötig sein alle Dokumente eines Systems löschen zu wollen/müssen.
Für diese Anforderung gibt es ab der Version 1.8.0 eine API Funktion:
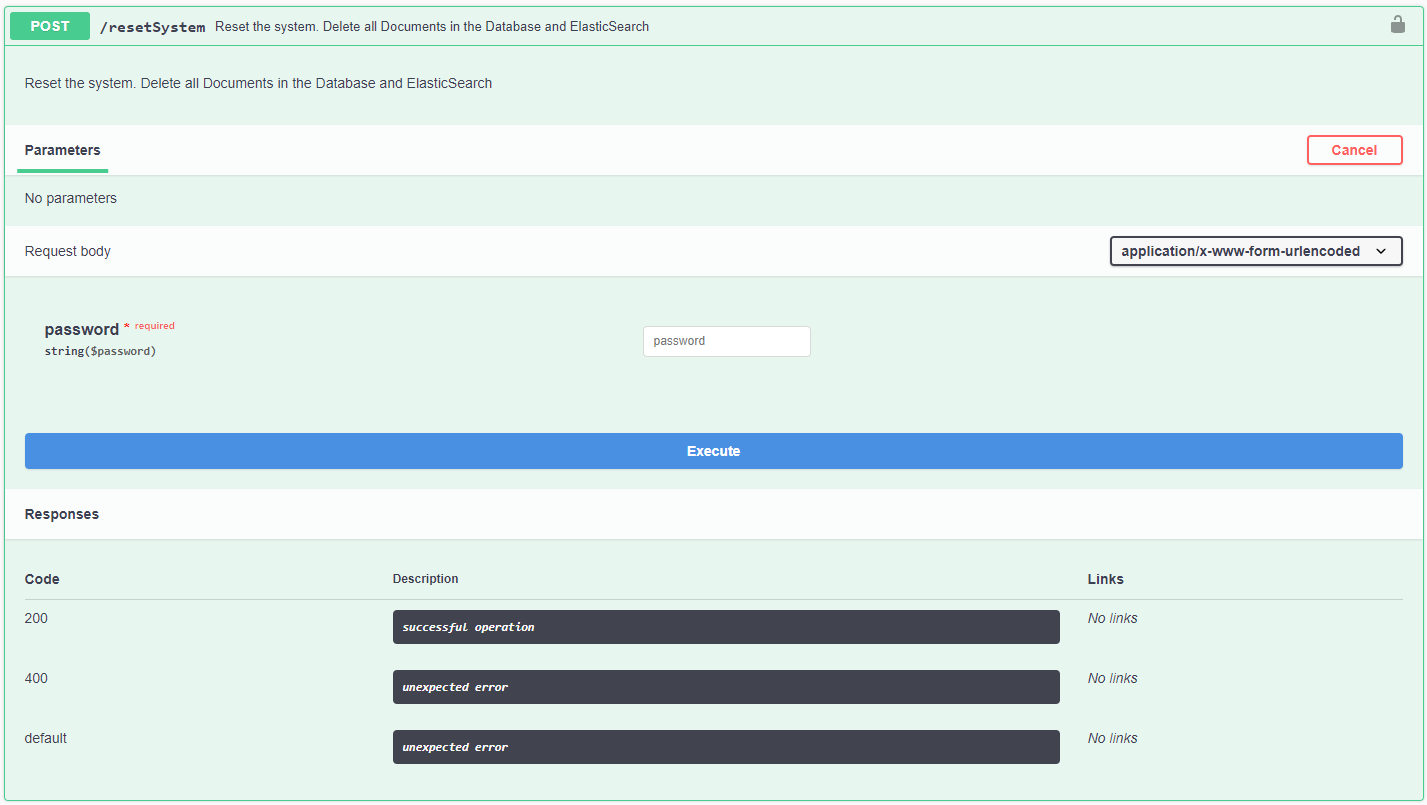
Diese Funktion kann nur von Benutzer der Gruppe root durchgeführt werden.
Des Weiteren wird ein Passwort benötigt, welches beim Support angefragt werden kann.
Aufgabe: Periodischer Worker Neustart
Für einen periodischen Neustart des Workers benötigen wir folgendes Script, welches als ".bat" gespeichert wird.
@echo off set DIENSTNAME1="05_SQUEEZE_Worker" net stop %DIENSTNAME1% 2>nul if errorlevel 2 ( echo Dienst ist bereits gestoppt . . . Starte %DIENSTNAME1% net start %DIENSTNAME1% ) net start %DIENSTNAME1%
1. Aufgabe erstellen
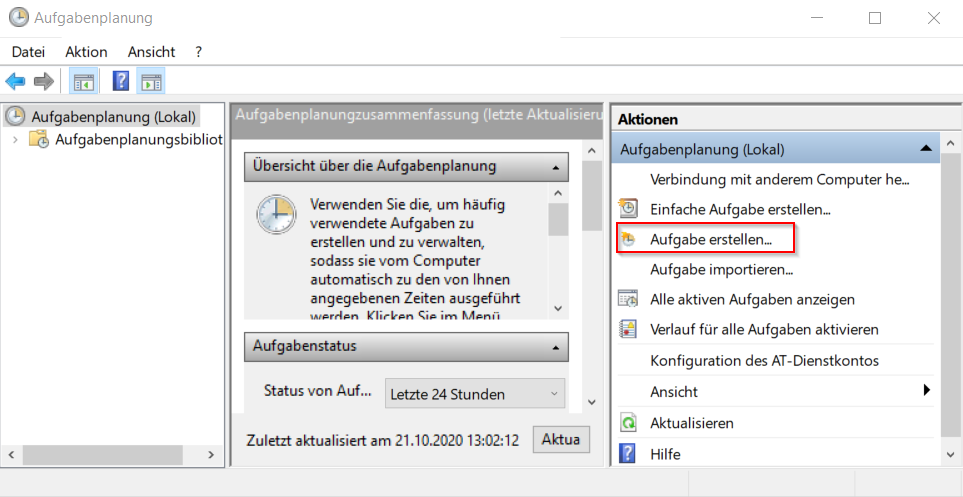
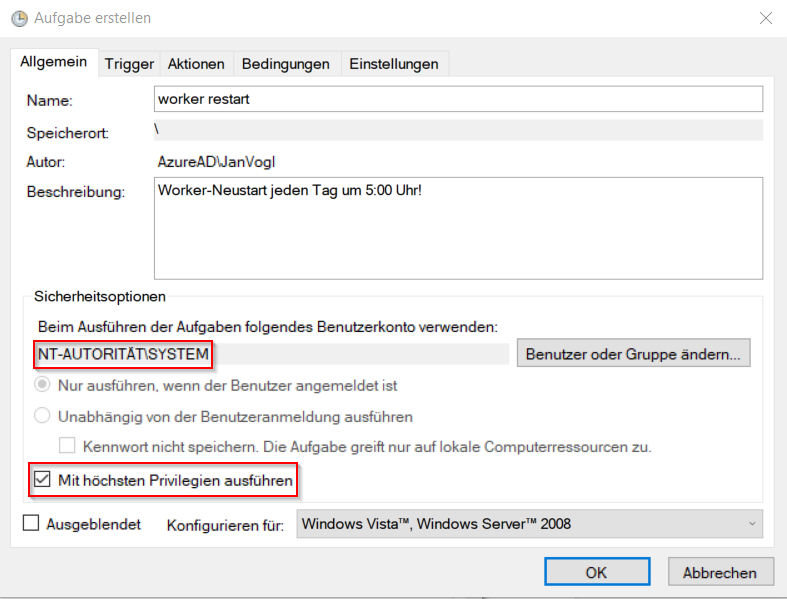
Der Name und die Beschreibung ist natürlich frei wählbar.
Damit die Aufgabe unabhängig von der Anmeldung eines Benutzers ausgeführt wird und auch unabhängig von eventuellen Passwortänderungen ist, hat sich bewährt, das System Konto auszuwählen.
Die Aufgabe "mit höchsten Privilegien" zu starten hat sich ebenfalls bewährt.
2. Trigger/Zeitpunkt festlegen
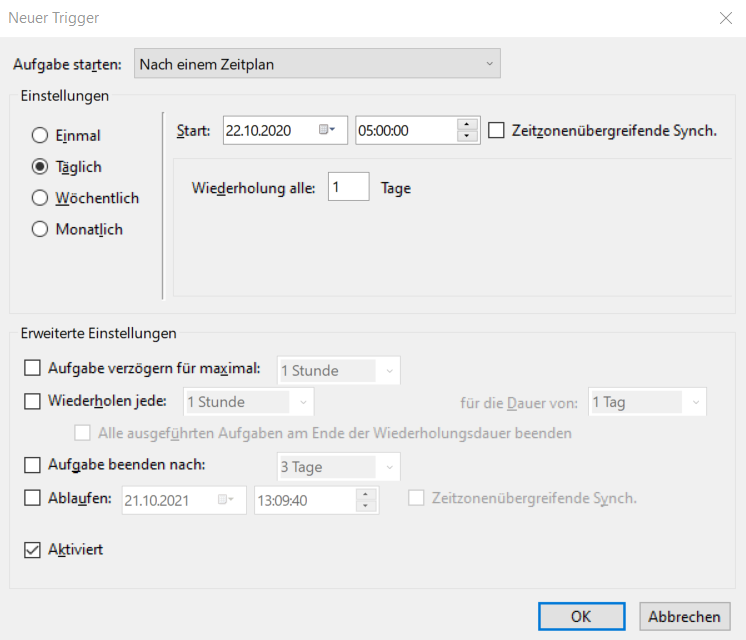
Das Intervall in dem der Worker neu gestartet werden soll ist frei definierbar.
3. Aktion festlegen
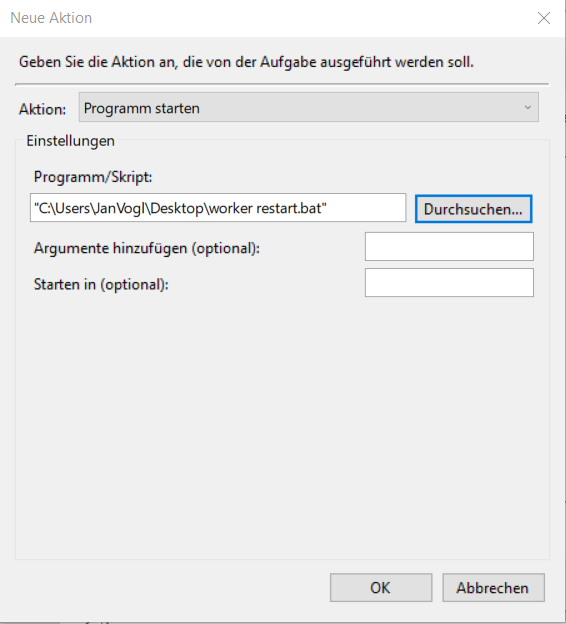
Als Programm wird die Oben erstellte ".bat" (worker restart.bat) ausgewählt.
ElasticSearch Speicher erweitern
Windows
Unter Windows kann eine kleine GUI Anwendung genutzt werden, um die Parameter des ElasticSearch Dienstes anpassen zu können:
C:\SQUEEZE\elasticsearch\bin\elasticsearch-service.bat manager 03_SQUEEZE_SearchEngine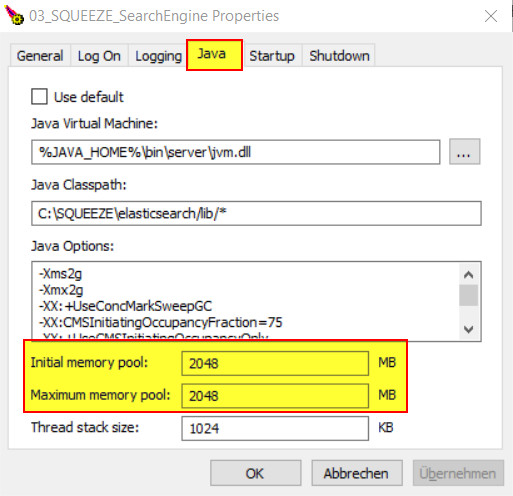
SOAP Server Funktion nutzen ohne Internetverbindung
Fehlerbild / Cause
Funktioniert die Übergabe an SQUEEZE über den SOAP Server nicht? (Session Timeouts / Parsing Schema Fehler)
Hat der SQUEEZE Server keine Internetverbindung?
Kann der SQUEEZE Server die importierten Schemas aus der DOCUMENTS.wsdl aufrufen?
(.../SQUEEZE/htdocs/public/api/DOCUMENTS.wsdl)
Lösung
In der DOCUMENTS.wsdl muss das zu importierende Schema (aktuell: http://www.w3.org/2004/08/xop/include) auf dem Server abgelegt und mittels XML-Tag Attribut "schemaLocation" darauf verwiesen werden.
Dabei ist zu beachten, dass eine Webadresse / IP angegeben werden muss, KEIN Dateipfad.
<import namespace="http://www.w3.org/2004/08/xop/include" schemaLocation="http://<SQUEEZE_SERVER_ADDRESS>/api/xop.xsd"/>In diesem Beispiel wurde die XOP (xsd File) im SOAP Server Verzeichnis abgelegt.
Wenn der DOCUMENTS Server dieses Schema liefert (bei SQZ Export Konfiguration otris SOAP) dann sollte auch die DOCUMENTS.wsdl vom DOCUMENTS Server überprüft werden unter (...\Documents5\soapproxy\DOCUMENTS.wsdl).