Formulare trainieren
Inhaltsverzeichnis auf der Linken Seite!
seit SQUEEZE Version 2.14
Beim Formulartraining werden Formulare in Bereiche (Regionen) aufgeteilt. Jeder Bereich enthält spezifische Informationen (Felder). Das System wird trainiert, diese Bereiche und die darin enthaltenen Informationen zu erkennen, indem es nach bestimmten Schlüsselwörtern und Mustern sucht.
Das Grundprinzip funktioniert wie folgt:
- Einteilung in Regionen:
Formulare werden in verschiedene Abschnitte (Regionen) unterteilt.
Regionen haben Anker (die Schlüsselworte) um eine Region zu identifizieren. - Identifizierung von Feldern:
Zu jeder Region (bzw. zu jedem Regionsanker) werden die einzelnen Informationen (Felder) festgelegt.
Die Felder werden in Relation zum Regionsanker trainiert. - Suchen nach Schlüsselwörtern (Regionsanker):
Das System sucht nach bestimmten Wörtern oder Phrasen (Schlüsselwörter), um eine Region zu identifizieren.
Dazu wird der zuvor (trainierte) markierte Bereich herangezogen. - Suchen nach Werten von Feldern zu Regionen:
Das System sucht nach Werten und Mustern in Relation zum gefundenen Schlüsselwort der Region (Regionsanker).
Die gefundenen Feldwerte werden in die trainierten Felder geschrieben.
Ziel des Trainings:
Durch diesen Prozess wird das System trainiert, sich gleichende Formulare automatisch zu analysieren und die relevanten Informationen zu extrahieren.
Die Dokumente müssen sich vom Aufbau gleichen, damit das Training gut funktioniert.
Das bedeutet, dass die Regionen wie trainiert erwartet werden können.
Abweichungen beeinträchtigen das Auslese-Ergebnis.
Bei Positionen muss darauf geachtet werden, dass die trainierten Regionen auf der Längsseite (X-Achse) im gleichen Bereich befindlich sind. Sie sollten also in der gleichen Spalte stehen.
Dynamische Höhen der Positionen werden automatisch berücksichtigt.
Mehr dazu im Kapitel "Positionstraining"
Kopffeldtraining
Um die Kopffelder zu identifizieren, muss zunächst die Region in der die Felder zu extrahieren sind trainiert werden.
Die Trainingsfunktion sucht zuerst die Regionsanker und richtet daran die markierten Bereiche der trainierten Felder aus.
Regionsanker konfigurieren
Der Regionsanker stellt einen Anker auf dem Formular dar.
Wenn dieser gefunden wurde, können die (in Relation) zur Region trainierten Felder ermittelt werden.
Es kann mehr als einen Regionsanker geben und zu jedem Anker (einer Region) bis zu n Felder trainiert werden.
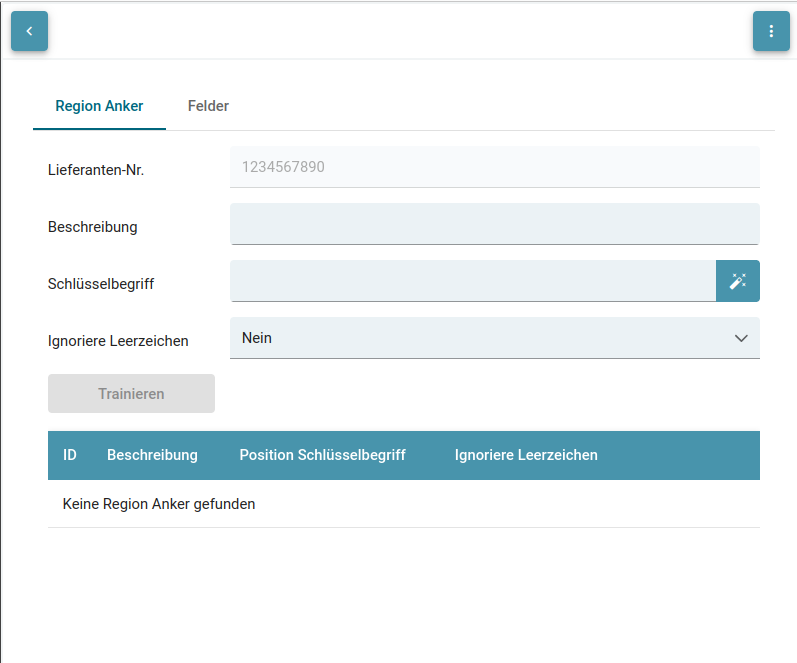
| Attribut | Beschreibung |
| Lieferanten-Nr. | Stellt den Trainingsschlüssel dar, an dem das Training geknüpft wird. Bisher ist es das Feld "CreditorId". |
| Beschreibung | Beschreibung der Region. Erleichtert die Auswahl der Region bei den Feldtrainings. |
| Schlüsselbegriff | RegEx, um die Region zu identifizieren. Enthält auch den gezogenen Bereich (Bounding Box) in dem das Schlüsselwort gesucht wird. |
| Ignoriere Leerzeichen | Auswahlliste um bei der Ermittlung des Schlüsselwortes die Leerzeichen zu ignorieren. Kann den RegEx für Schlüsselbegriffe erleichtern, da Leerzeichen nicht gematched werden müssen. |
Vorgehen
- Beschreibung der Region
- Markieren des Schlüsselbegriffes (Anker)
- Festlegung ob Leerzeichen ignoriert werden sollen
- "Trainieren" Button betätigen um den Regionsanker zu speichern
Dabei wird aus dem markierten Schlüsselwort automatisch ein RegEx generiert.
Beispiel - Ausfuhrbegleitdokument
Umtrainieren
Trainierte Regionen werden in der Tabelle aufgelistet.
Durch einen Klick auf den Stift kann der RegEx des Schlüsselwortes geändert werden - ebenso ob Leerzeichen ignoriert werden
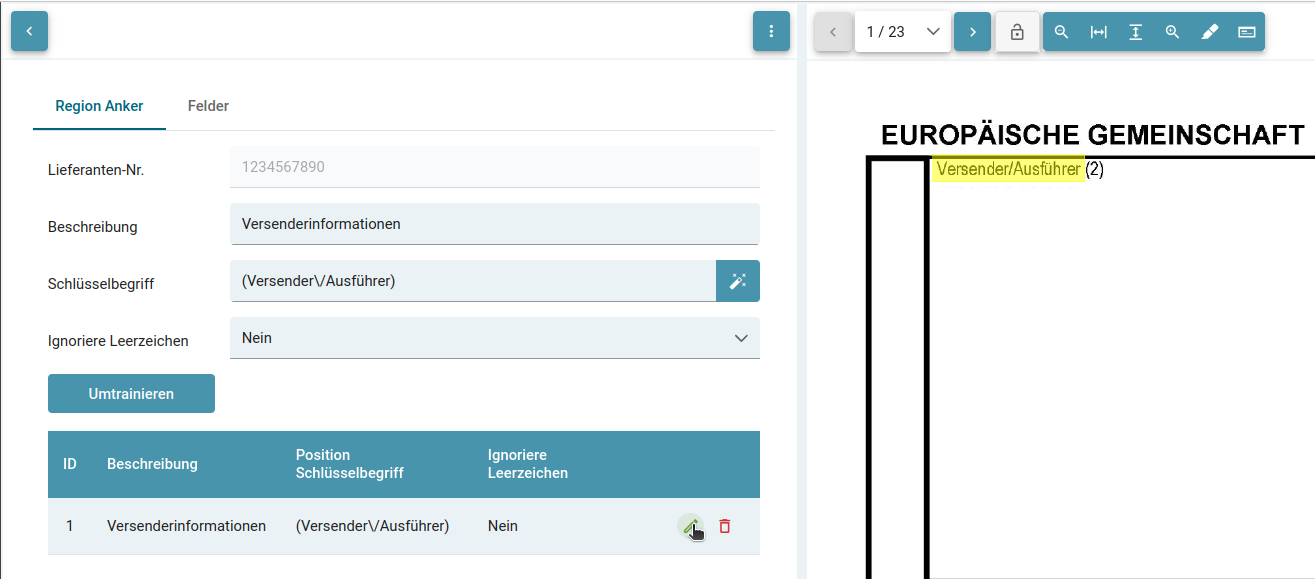
Mit betätigen des "Umtrainieren" Buttons werden die Änderungen übertragen.
Beim Umtrainieren wird aus dem Feldinhalt kein RegEx generiert, sondern lediglich überprüft.
Felder trainieren
Für jede trainierte Region können nun Kopffelder aus der SQUEEZE Dokumentenklasse dieses Dokumentes trainiert werden.
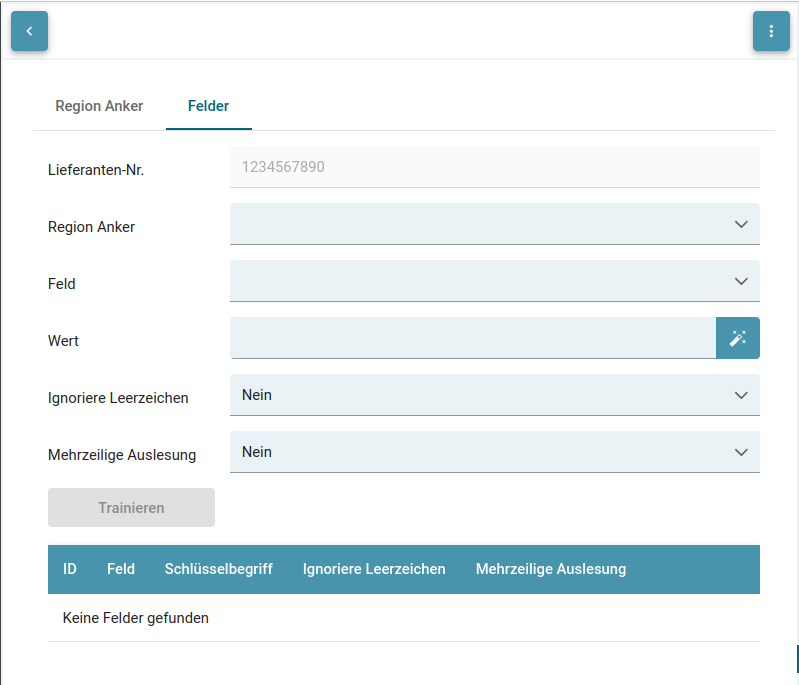
| Attribut | Beschreibung |
| Lieferanten-Nr. | Stellt den Trainingsschlüssel dar, an dem das Training geknüpft wird. Bisher ist es das Feld "CreditorId". |
| Region Anker | Auswahl des trainierten Region-Ankers. Die Felder werden in Relation zum Regionsanker trainiert. Daher sollte hier ein Anker ausgewählt werden, bei dem die Relation zum Feld ungefähr gleichbleibend ist. |
| Feld | Auswahl des Kopffeldes aus der Dokumentenklasse des Dokuments. Das Ergebnis bei der Extraktion des Trainings wird in das hier ausgewählte Feld geschrieben. |
| Wert | RegEx, um den Feldwert zu extrahieren. Enthält auch den gezogenen Bereich (Bounding Box) in dem der Wert in Relation zum Regionsanker gesucht wird. |
| Ignoriere Leerzeichen | Auswahlliste um bei der Ermittlung des Wertes die Leerzeichen zu ignorieren. Kann den RegEx für Werte erleichtern, da Leerzeichen nicht gematched werden müssen. |
| Mehrzeilige Auslesung | Auswahl, um alle gefundenen Werte aus der Region genutzt werden sollen (ja) oder nur der Erste (nein). |
Beim Anlegen des Trainings wird aus dem Feldinhalt ("Wert") initial ein Regex generiert.
Bitte geben Sie erst beim Umtrainieren, einen eigenen Regex an.
Vorgehen
- Regionsanker an dem das Feldtraining ausgerichtet werden soll auswählen.
- Dokumentenklassenfeld des Dokumentes auswählen in der das Ergebnis des Trainings bei der Extraktion geschrieben werden soll.
- Markierung des Wertes. Es wird die gesamte Markierung zur Suche und Extraktion des Feldwertes herangezogen.
- Festlegung, ob Leerzeichen ignoriert werden sollen - dies kann in einigen Fällen für den Wert nützlich sein.
- Festlegung, ob mehrzeilig in der gesamten Markierung oder nur der erste Treffer in einer Zeile ausgelesen werden sollen.
- "Trainieren" Button betätigen, um das Feldtraining in Abhängigkeit zur Region zu speichern bzw. zu trainieren.
Beispiel Ausfuhrbegleitdokument
Mehrzeilige Auslesung
Bei der Mehrzeiligen Auslesung werden alle Treffer des angegebenen Musters im gesamten markierten Bereich zurückgegeben.
In diesem Beispiel würde auch ein Wert ausgelesen werden, der innerhalb der Markierung an der Stelle des Mauszeigers ist:
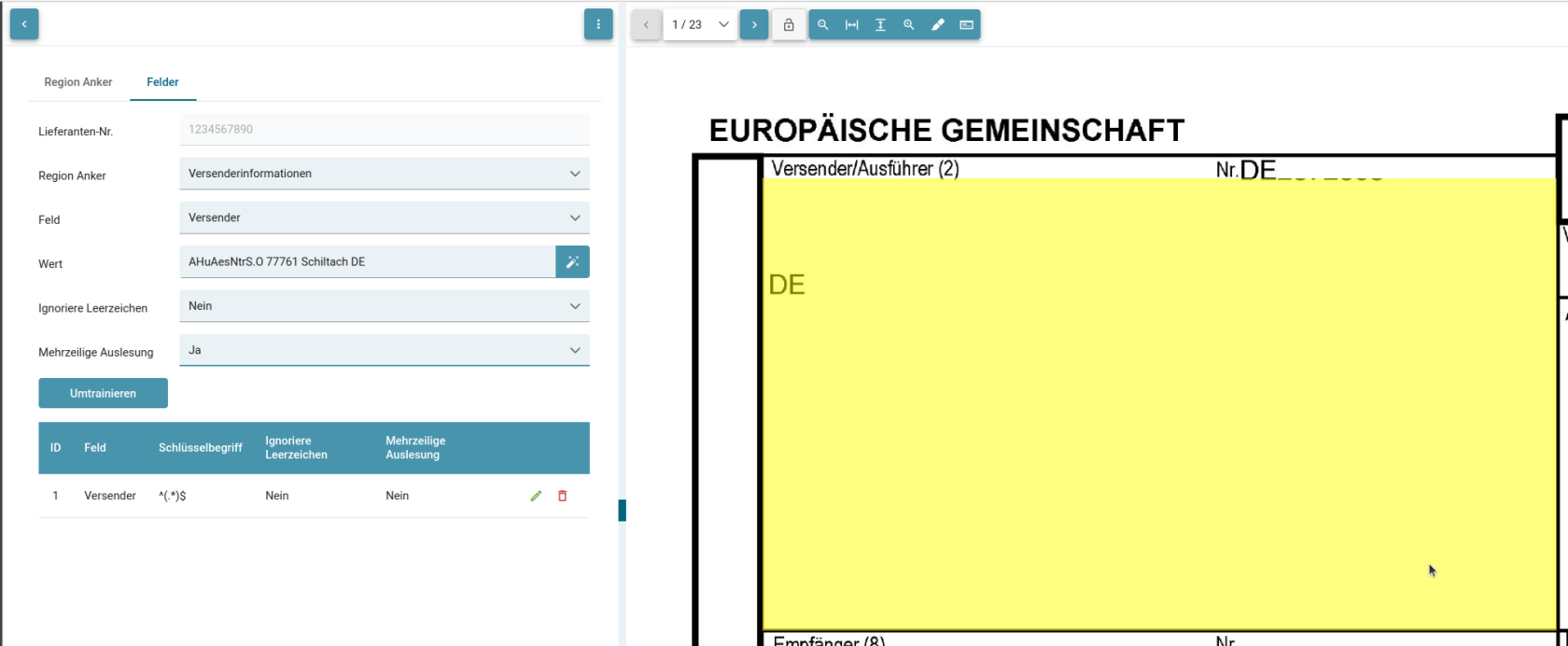
Umtrainieren
Trainerte Felder werden in der Tabelle aufgelistet.
Durch einen Klick auf den Stift kann der RegEx des Wertes geändert werden - ebenso, ob Leerzeichen ignoriert oder mehrzeilig ausgelesen werden soll.
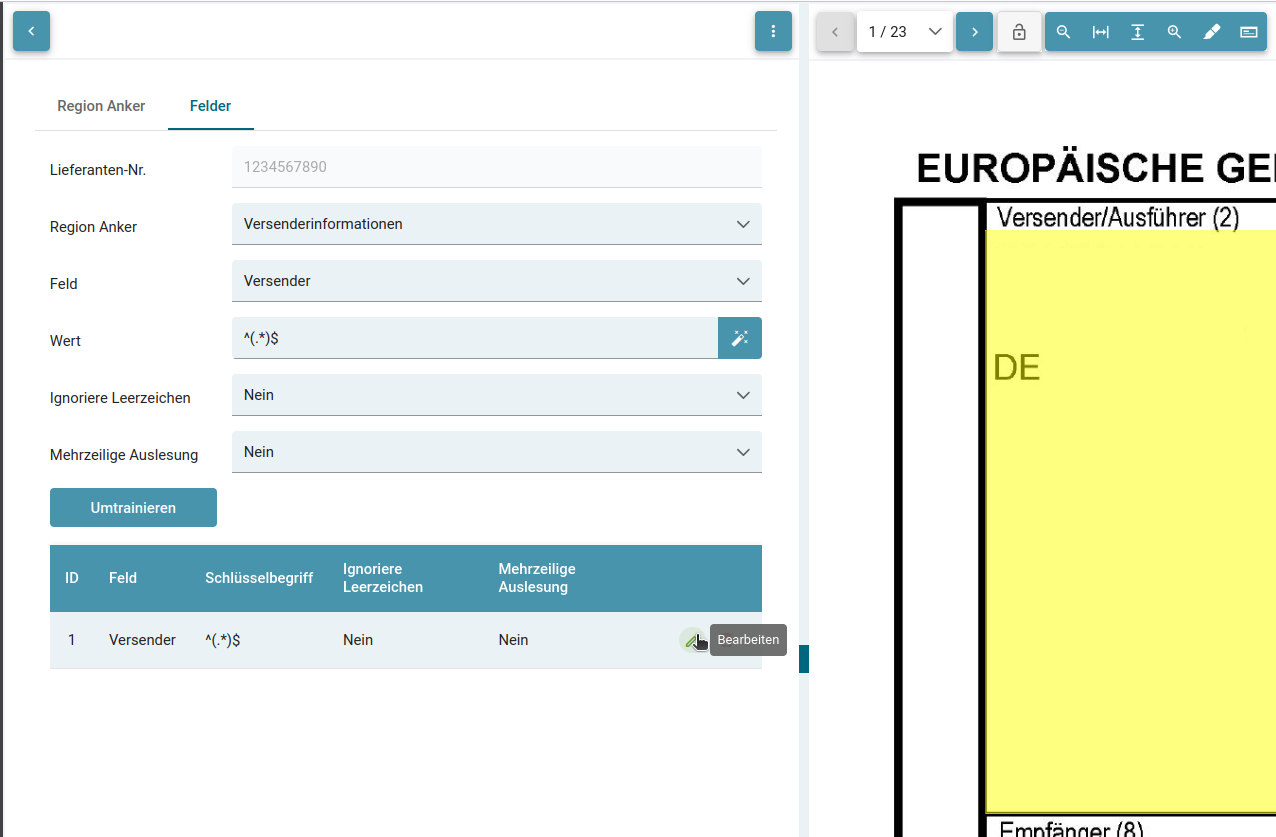
Mit betätigen des "Umtrainieren" Buttons werden die Änderungen übertragen.
Beim Umtrainieren wird aus dem Feldinhalt kein RegEx generiert, sondern lediglich überprüft.
Beispiel - Ausfuhrbegleitdokument
In diesem Beispiel wollen wir die Versenderdetails trainieren.
Regionsanker trainieren
Um dies zu tun, ermitteln wir erst einen Regionsanker, von dem aus das System in Relation die im Nachgang trainierten Felder extrahieren soll. Dafür müssen wir ein Schlüsselwort definieren und die Region markieren.
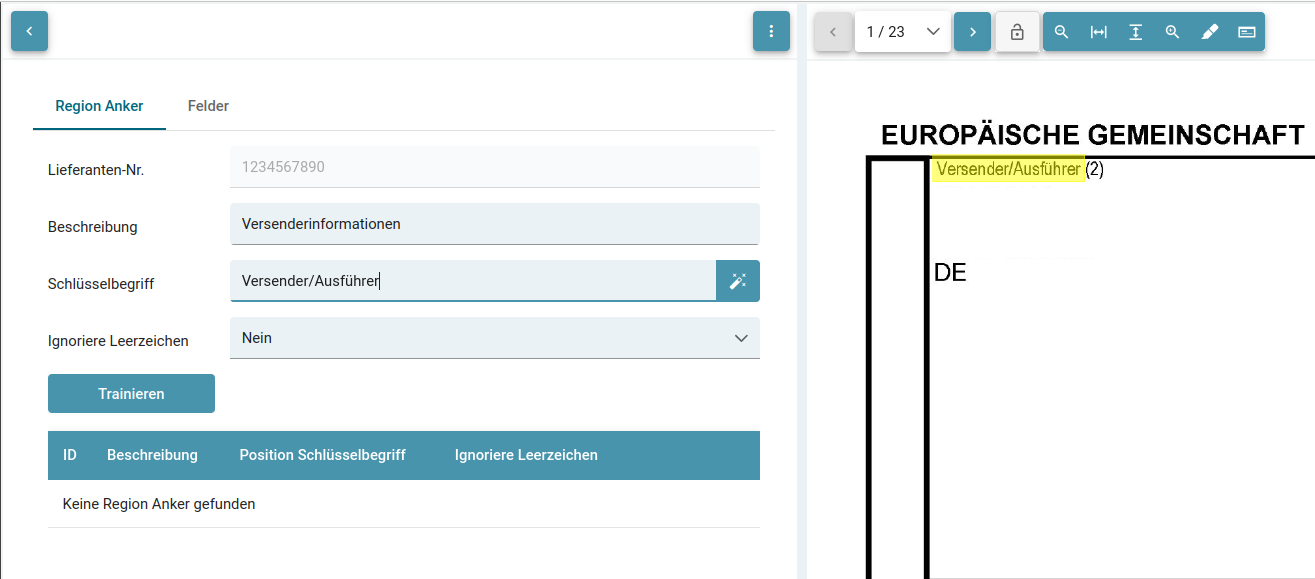
Mit einem Klick in das Feld "Schlüsselbegriff" ist das Feld im Fokus. Danach kann die Region und der Wert des Schlüsselbegriffs (hier Versender/Ausführer) mit gedrückter rechten Maustaste als Markierung in das Feld übertragen werden.
Der RegEx des Schlüsselwortes wird beim Trainieren (also bei der Anlage) eines Schlüsselwortes über den Button "Trainieren" automatisch generiert. Dieser kann durch das Umtrainieren geändert werden.
Felder trainieren
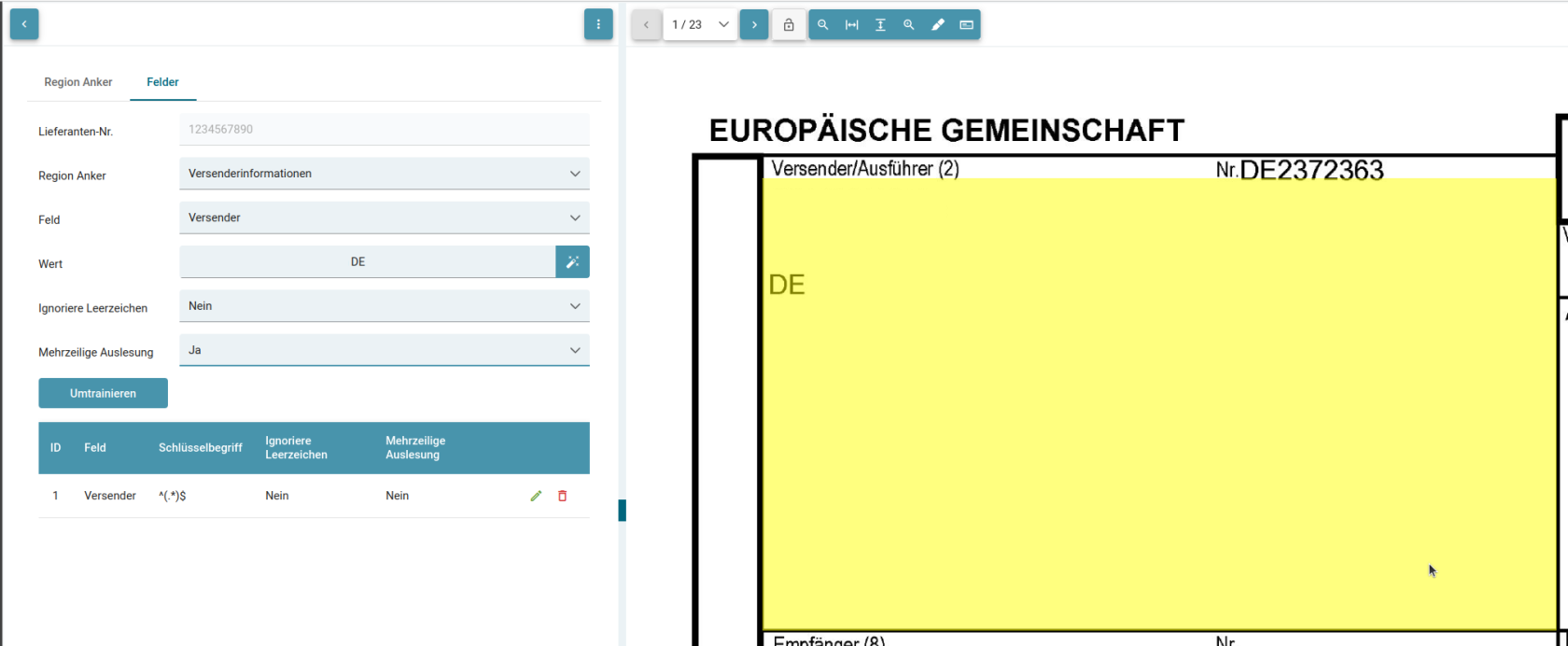
Nun wollen wir die Felder "Versender", "Straße", "Postleitzahl" und "Ort" trainieren, die sich an dem gefundenen Schlüsselwort des Regionsanker "Versendeinformationen" orientieren.

Dazu ist es ratsam den generierten RegEx zu bearbeiten, sodass alle erwünschten Werte erkannt werden können.
In diesem Beispiel wurde für das Feld "Versender" der Regex ([a-z]{9}) generiert.
Dieses Muster mag für den Wert DEXPRO zutreffend sein, alle anderen Versendernamen die bspw. ein Leerzeichen enthalten oder aus mehr als 9 Zeichen bestehen würden jedoch nicht ausgelesen werden.
Daher wurde das Muster umtrainiert zu ^(.*)$, welches also alle Zeichen matcht solange es in einer Zeile steht.
So kann mit allen weiteren auszulesenden Feldern aus der Region verfahren werden.
Mehrzeilige Auslesung
Alternativ kann man auch einfach den gesamten Versender Block für ein Feld auslesen. Dafür den gesamten Bereich markieren und die "Mehrzeilige Auslesung" auf "Ja" stellen, beim Training.
Positionstraining
Beim Positionstraining müssen die Positionen zunächst identifiziert werden. Da sich diese in ihrer Größe durch die Auflistung des Inhaltes dynamisch verhalten, wird der Anfang einer jeden Positionszeile (Indikator) trainiert.
Das System sucht bei der Extraktion dann nach dem nächsten Indikator und ermittelt so die maximale Größe der Positionszeile.
Anhand des Indikators werden dann die Regionen in der Positionszeile durch das Schlüsselwort des Regionsanker ermittelt.
Anhand des Regionsanker werden dann die in der Region trainierten Informationen (Felder) mittels Muster Suche extrahiert.
Indikator trainieren
Da sich Positionszeilen in ihrer Höhe und damit Größe dynamisch ändern, werden Indikatoren trainiert.
Diese geben an, woran man den Start einer Positionszeile erkennen kann.
Bei der Extraktion mit dem Training wird die Größe einer Positionszeile von dem aktuell gefundenen Indikator bis zum nächsten Indikator festgelegt.
Der zu trainierende Wert muss auf der X-Achse immer im gleichen Bereich aufzufinden sein.
Außerdem sollte der Wert auf der Y-Achse an oberster Stelle der Position zu finden sein.
Hier ein Beispiel: Die Positionsnummer steht auf der X-Achse immer im gleichen Bereich und ist auf der Y-Achse an oberster Stelle der Position.
Daher eignet sich diese perfekt als Indikator einer Position:

Beim Training des Indikators darauf achten, dass man auf der ersten Seite der Positionen trainiert.
Der markierte Bereich des Indikators enthält die Seite auf dem der Bereich markiert wurde.
Das Positionstraining beginnt die Extraktion erst auf der Seite des trainierten Indikators!
Hier die Konfigurationseinstellungen:
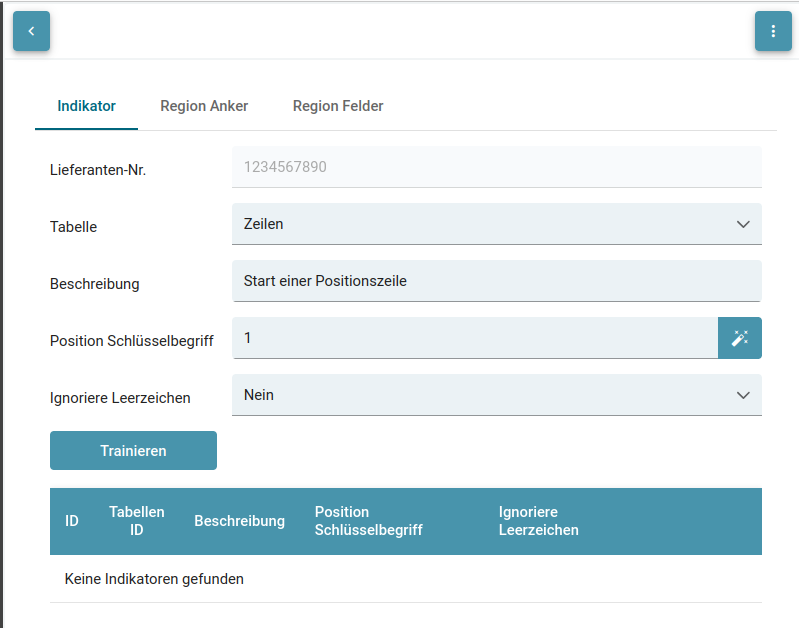
| Attribut | Beschreibung |
| Lieferanten-Nr. | Stellt den Trainingsschlüssel dar, an dem das Training geknüpft wird. Bisher ist es das Feld "CreditorId". |
| Tabelle | Auswahl des Tabellenfeld der Dokumentenklasse, für welches die Positionen trainiert und extrahiert werden sollen. |
| Beschreibung | Beschreibung des Indikators. Erleichtert die Auswahl des Indikators beim Training der Regionsanker. |
| Position Schlüsselbegriff | RegEx, um den Indikator zu identifizieren. Enthält auch den gezogenen Bereich (Bounding Box) in dem das Schlüsselwort gesucht wird. |
| Ignoriere Leerzeichen | Auswahlliste um bei der Ermittlung des Schlüsselbegriffes die Leerzeichen zu ignorieren. Kann den RegEx für Werte erleichtern, da Leerzeichen nicht gematched werden müssen. |
Vorgehen
- Tabelle auswählen, dessen Positionen trainiert werden sollen.
Diese bestimmt die Auswahl der trainierbaren Felder (Spalten) für die Positionsdaten. - Beschreibung für den Indikator einer Positionszeile hinterlegen.
- Feld "Position Schlüsselbegriff" mit einem Klick fokussieren und mit gedrückter rechten Maustaste den Schlüsselbegriff markieren.
- Angeben, ob die Leerzeichen ignoriert werden sollen.
Bei der Markierung des Indikators beachten, dass der größt-mögliche Bereich für den Indikator gezogen wird.
Befindet sich ein Wert außerhalb der Markierung wird er nicht zur Erkennung herangezogen.
Regionsanker trainieren
Beim Regionsanker wird ein Bereich und ein Schlüsselwort markiert, der in etwa den gleichen Abstand zum auszulesenden Bereich der auszulesenden Felder besitzt (siehe Verständnis für gute und schlechte Regionsanker).
Beim betätigen des "Trainieren" Buttons wird automatisch ein Regex generiert, dieser kann beim Umtrainieren
Verständnis für gute und schlechte Regionsanker
Der Regionsanker sollte immer in etwa den gleichen Abstand zum auszulesenden Bereich des Wertes haben (X- und Y-Achse).
Durch das Training ist der Abstand zwischen dem Regionsanker und den Feldern einer Region bekannt (trainiert).
Beim Auslesen eines anderen Dokumentes mit dem gleichen Aufbau, können die zu einer Region trainierten Felder also ausgelesen werden, weil die Region im gleichen Abstand wie beim Training zu finden sind.
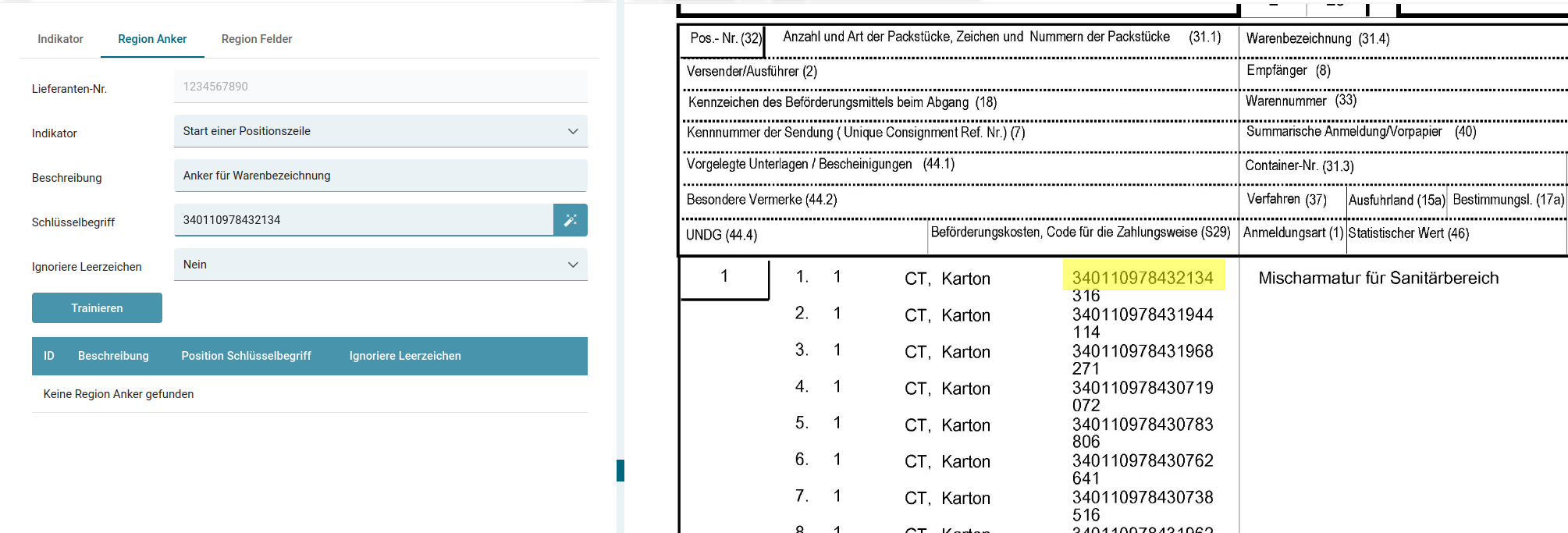
In diesem Beispiel wollen wir einen Regionsanker für die Warenbezeichnung "Mischarmatur für Sanitärbereich" trainieren.
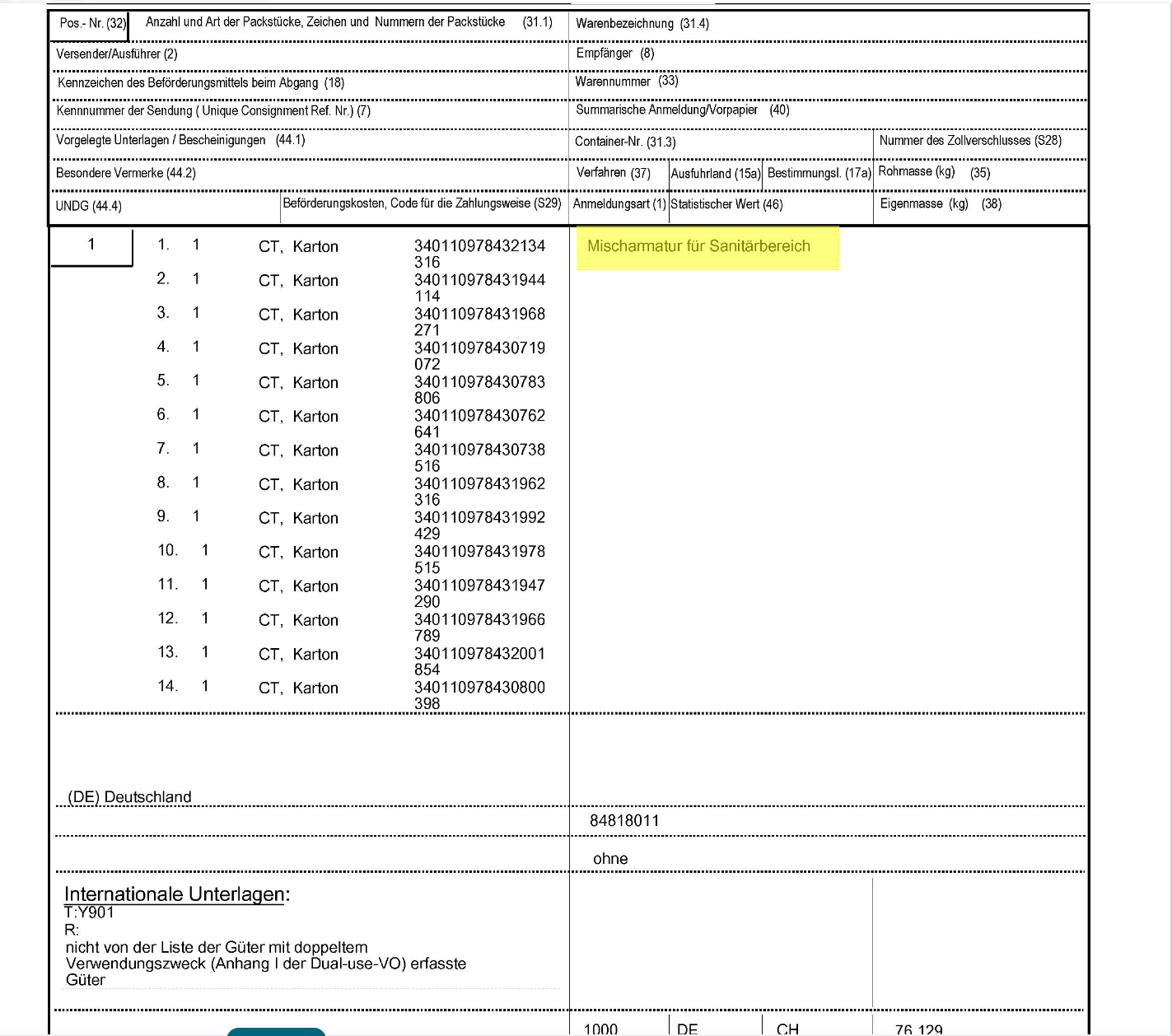
Regionsanker "Warennummer" (84818011)
Da die Liste der Packstücke auf der linken Seite die Höhe und damit den Abstand zwischen der Warennummer und dem eigentlichen Bereich des Feldes verändert, ist dies kein guter Regionsanker. Die Volatilität lässt eine Bestimmung durch den Abstand nicht zu.

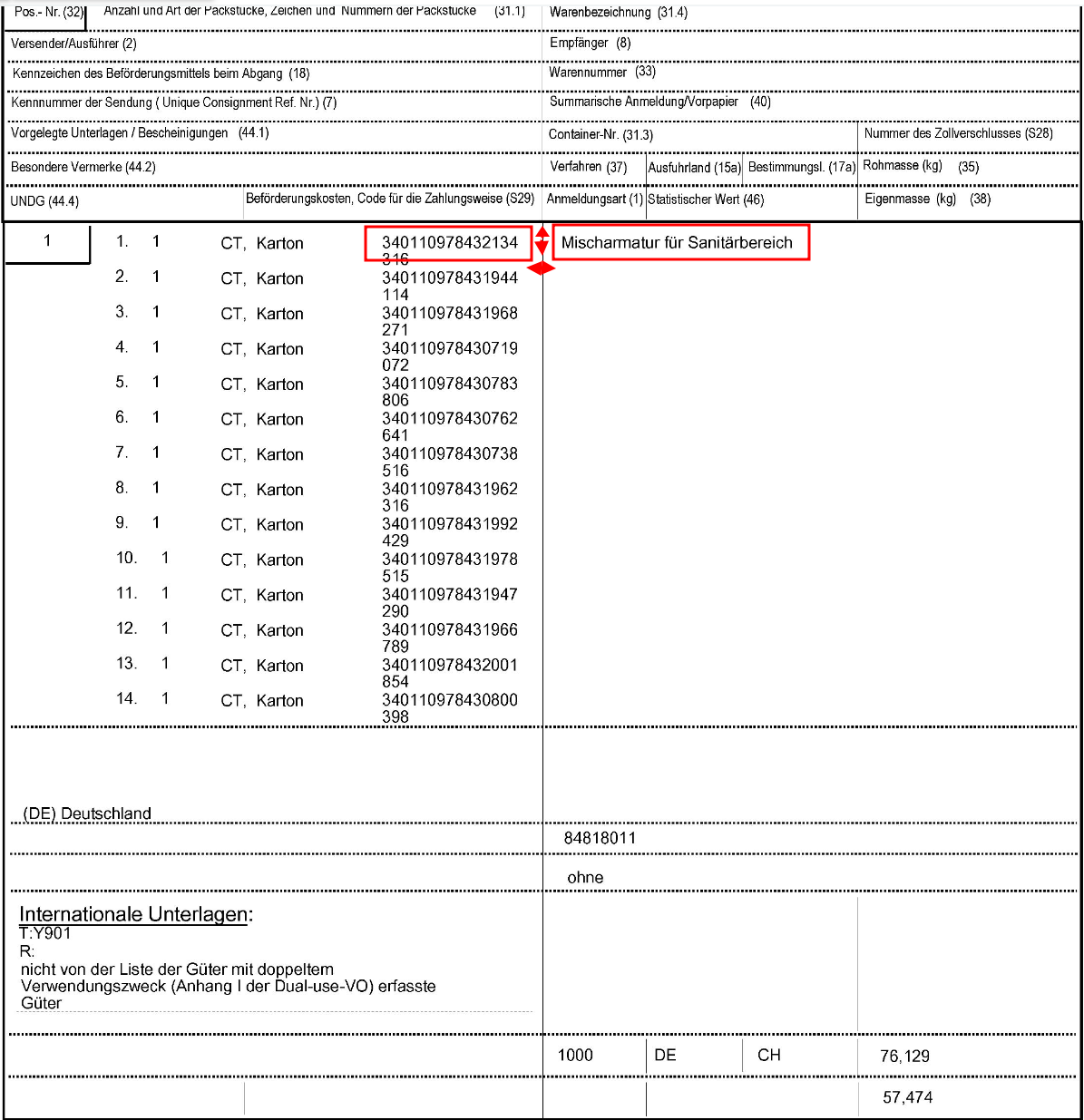
Regionsanker "Nummer der Packstücke" (340110978432134)
Die oberste Nummer des Packstücks ist vom Bereich her immer auf der gleichen Höhe, wie die Warenbezeichnung. Der einzige Unterschied ist auf der Längsseite (X-Achse): Die Warenbezeichnung findet sich weiter rechts.
Nun das wichtigste: Der Abstand von der Nummer des Packstücks auf der X-Achse ist fast immer gleich.
Dadurch eignet sich die Nummer des Packstücks perfekt als Regionsanker.
Felder trainieren
Nun wollen wir das Feld "Bezeichnung" trainieren, die sich an dem gefundenen Schlüsselwort des Regionsanker "Anker für Warenbezeichnung" orientieren.
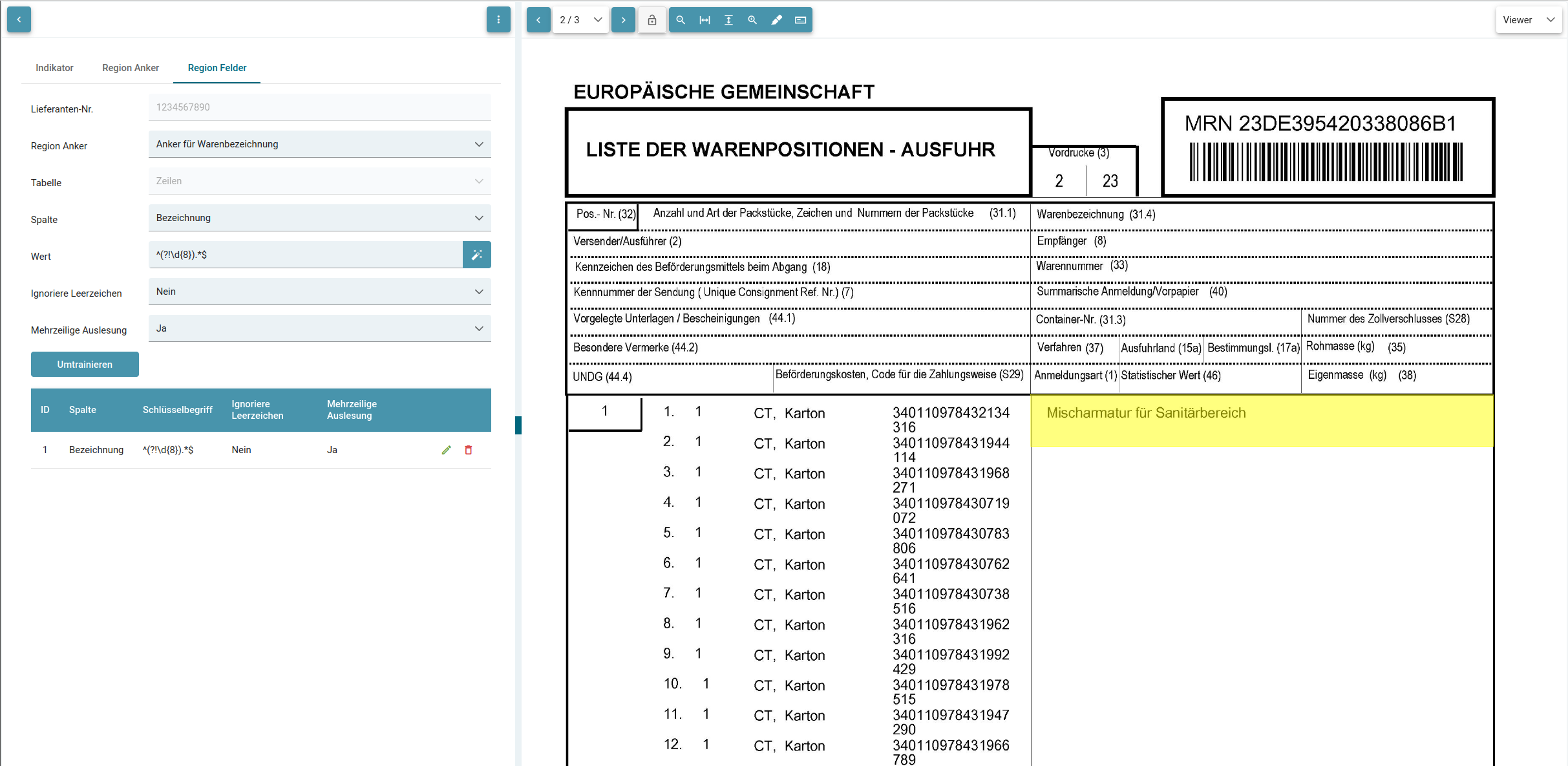
Dazu ist es ratsam den generierten RegEx zu bearbeiten, sodass alle erwünschten Werte erkannt werden können.
In diesem Beispiel wurde für das Feld "Bezeichnung" der Regex ([a-z]{12}\s[a-z]{1}ü[a-z]{1}\s[a-z]{5}ä[a-z]{8}) generiert.
Dieses Muster mag für den Wert Mischarmatur für Sanitärbereich zutreffend sein, alle anderen Warenbezeichnungen jedoch nicht. Daher sollte dieser RegEx umtrainert werden. Vor allem mit der Mehrzeiligen Auslesung können damit gute Muster erstellt werden (siehe Mehrzeilige Auslesung).
Zu einem Anker können auch mehrere Felder trainiert werden, etwa bei Adresszeilen, die immer den gleichen Geometrischen Bezug zum Anker aufweisen.
Mehrzeilige Auslesung
Damit auch mehrzeilige Warenbezeichnungen in dem gesamten Feld gelesen werden können, bietet sich die "Mehrzeiligen Auslesung" an. Diese liest alle weiteren Zeilen in der Markierung und ggfs. bis zum Ende der Position ein und prüft diese gegen den RegEx.
In dem Beispiel lohnt sich hier also ein Negative Lookahead.
Dazu wird der generierte RegEx mit ^(?!\d{8}).$ umtrainiert, der alles matcht außer das Muster für die Warennummer. Diese ist im Formular nach der Warenbezeichnung zu finden.

No comments to display
No comments to display