Synchronisation von Stamm- und Bewegungsdaten mittels externer IDs
Zielsetzung
Für die Verdichtung und Synchronisation von Extraktionsergebnissen in Squeeze Extract müssen Stamm- und Bewegungsdaten effizient und konsistent bereitgestellt werden. Insbesondere bei großen Datenmengen ist es nicht sinnvoll, komplette Datenbestände regelmäßig neu zu importieren.
Stattdessen empfiehlt sich folgendes Vorgehen:
- Einmaliger Initialimport aller relevanten Daten.
- Anschließende Synchronisation über gezielte CRUD-Operationen (Create, Read, Update, Delete).
- Verwendung einer kundenseitigen Primärschlüsselreferenz über die Spalte externalid.
Dadurch können Datensätze eindeutig identifiziert und effizient aktualisiert oder gelöscht werden.
Verwendung einer externen ID
Standardmäßig verwendet Squeeze Extract die interne Spalte id als Primärschlüssel für API-Operationen.
Für Integrationsszenarien empfiehlt es sich jedoch, eine zusätzliche Spalte namens externalid anzulegen. Diese enthält den Primärschlüssel des Quellsystems und ermöglicht eine stabile Zuordnung zwischen externem System und Squeeze Extract.
Einrichtung der Spalte
- Öffnen Sie die Administration -> Stammdaten
- Öffnen Sie Tabelle, die Sie auf die Verwendung eines externen Primärschlüssels umstellen wollen
- In den Bereich Spalten wechseln.
- Eine neue Spalte mit dem Namen externalid (ausschließlich Kleinbuchstaben) anlegen.
- Die Tabelle über „Tabelle anlegen / zurücksetzen“ erneut initialisieren (die bisher enthaltenen Daten werden dabei entfernt)
Nach der Initialisierung wird die Primärschlüssellogik angepasst:
- Die Eindeutigkeitsprüfung erfolgt über die Spalte externalid.
- Die Spalte externalid muss für jeden Datensatz eindeutig sein.
- Die Spalte wird automatisch auf die Bedingungen UNIQUE und NOT NULL geprüft.
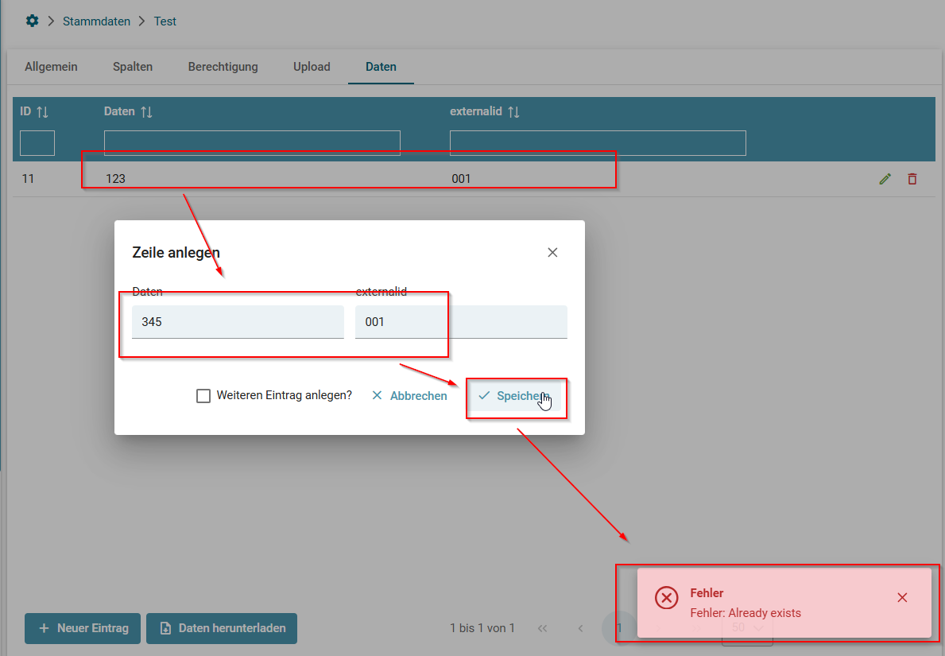
Beispiel
Existiert bereits ein Datensatz mit der externen ID 001, kann kein weiterer Datensatz mit derselben externen ID angelegt werden.
Initialer Datenimport
Nach Einrichtung der externen ID sollte ein vollständiger Import aller Stammdaten über den Master-Data-Endpunkt durchgeführt werden.
Empfohlener Endpunkt
/rows/batchAlternativ kann der Import auch initial über einen CSV Upload in der Squeeze Oberfläche durchgeführt werden.
Anforderungen
- Jeder Datensatz muss eine gültige
externalidenthalten. - Die
externalidmuss eindeutig sein. - Die
externaliddarf nicht leer sein.
Der Batch-Import dient ausschließlich zur initialen Befüllung des Datenbestands.
Laufende Synchronisation
Nach dem Initialimport sollten Änderungen ausschließlich über einzelne Transaktionen verarbeitet werden.
Folgende Operationen werden unterstützt:
- Insert (Anlegen)
- Update (Ändern)
- Delete (Löschen)
Dadurch können auch sehr große Datenbestände effizient synchronisiert werden, ohne regelmäßig komplette Tabellen neu zu übertragen.
Nutzung der API mit externer ID
Für Lookup-, Update- und Delete-Operationen muss der Parameter
useExternalId=trueübergeben werden.
Funktionsweise
Mit diesem Parameter wird der übergebene Wert in rowId gegen die Spalte externalid geprüft.
Beispiel:
...?rowId=4711&useExternalId=trueIn diesem Fall sucht die API nach einem Datensatz mit:
externalid = 4711Standardverhalten
Wird der Parameter nicht übergeben,
...?rowId=4711prüft die API weiterhin gegen die interne Spalte:
id = 4711Best Practices
- Große Datenmengen nicht regelmäßig vollständig neu importieren.
- Initialen Datenbestand einmalig per Batch bereitstellen.
- Für alle Folgesynchronisationen CRUD-Operationen verwenden.
- Externe Primärschlüssel konsequent über die Spalte
externalidabbilden. - Für Lookup-, Update- und Delete-Aufrufe immer
useExternalId=trueverwenden.
Nutzen für Integrationen
Durch die Verwendung einer externen ID wird die Synchronisation zwischen Quellsystem und Squeeze Extract deutlich vereinfacht. Änderungen können gezielt auf einzelne Datensätze angewendet werden, wodurch Netzwerkverkehr, Verarbeitungszeit und Systemlast erheblich reduziert werden. Gleichzeitig bleibt die Zuordnung zwischen Quellsystem und Squeeze Extract dauerhaft konsistent.
No comments to display
No comments to display